Apache Spark ayarlarını yapılandırma
HDInsight Spark kümesi, Apache Spark kitaplığının bir yüklemesini içerir. Her HDInsight kümesi, Spark dahil olmak üzere tüm yüklü hizmetleri için varsayılan yapılandırma parametreleri içerir. HDInsight Apache Hadoop kümesini yönetmenin önemli özelliklerinden biri, Spark İşleri de dahil olmak üzere iş yükünü izlemektir. Spark işlerini en iyi şekilde çalıştırmak için, kümenin mantıksal yapılandırmasını belirlerken fiziksel küme yapılandırmasını göz önünde bulundurun.
Varsayılan HDInsight Apache Spark kümesi şu düğümleri içerir: üç Apache ZooKeeper düğümü, iki baş düğüm ve bir veya daha fazla çalışan düğümü:
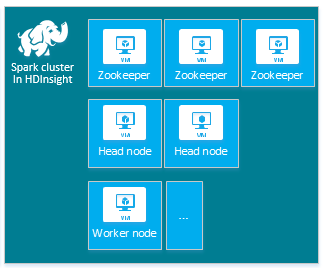
HDInsight kümenizdeki düğümler için VM sayısı ve VM boyutları Spark yapılandırmanızı etkileyebilir. Varsayılan olmayan HDInsight yapılandırma değerleri genellikle varsayılan olmayan Spark yapılandırma değerleri gerektirir. HDInsight Spark kümesi oluşturduğunuzda, bileşenlerin her biri için önerilen VM boyutları gösterilir. Şu anda Azure için Bellek için iyileştirilmiş Linux VM boyutları D12 v2 veya üzeridir.
Apache Spark sürümleri
Kümeniz için en iyi Spark sürümünü kullanın. HDInsight hizmeti hem Spark hem de HDInsight'ın çeşitli sürümlerini içerir. Spark'ın her sürümü bir dizi varsayılan küme ayarı içerir.
Yeni bir küme oluşturduğunuzda, aralarından seçim yapabileceğiniz birden çok Spark sürümü vardır. Tam listeyi görmek için HDInsight Bileşenleri ve Sürümleri.
Not
HDInsight hizmetinde Apache Spark'ın varsayılan sürümü bildirimde bulunmadan değişebilir. Sürüm bağımlılığınız varsa, Microsoft .NET SDK, Azure PowerShell ve Azure Klasik CLI kullanarak küme oluştururken bu sürümü belirtmenizi önerir.
Apache Spark'ın üç sistem yapılandırma konumu vardır:
- Spark özellikleri çoğu uygulama parametresini denetler ve bir
SparkConfnesne kullanılarak veya Java sistem özellikleri aracılığıyla ayarlanabilir. - Ortam değişkenleri, her düğümdeki betik aracılığıyla
conf/spark-env.shIP adresi gibi makine başına ayarları ayarlamak için kullanılabilir. - Günlük, aracılığıyla
log4j.propertiesyapılandırılabilir.
Spark'ın belirli bir sürümünü seçtiğinizde kümeniz varsayılan yapılandırma ayarlarını içerir. Özel bir Spark yapılandırma dosyası kullanarak varsayılan Spark yapılandırma değerlerini değiştirebilirsiniz. Aşağıda bir örnek gösterilmiştir.
spark.hadoop.io.compression.codecs org.apache.hadoop.io.compress.GzipCodec
spark.hadoop.mapreduce.input.fileinputformat.split.minsize 1099511627776
spark.hadoop.parquet.block.size 1099511627776
spark.sql.files.maxPartitionBytes 1099511627776
spark.sql.files.openCostInBytes 1099511627776
Yukarıda gösterilen örnek, beş Spark yapılandırma parametresi için birkaç varsayılan değeri geçersiz kılar. Bu değerler sıkıştırma codec'i, Apache Hadoop MapReduce bölünmüş minimum boyut ve parquet blok boyutlarıdır. Ayrıca Spark SQL bölümü ve açık dosya boyutları varsayılan değerleridir. İlişkili veriler ve işler (bu örnekte genomik veriler) belirli özelliklere sahip olduğundan bu yapılandırma değişiklikleri seçilir. Bu özellikler, bu özel yapılandırma ayarlarını kullanarak daha iyi olacaktır.
Küme yapılandırma ayarlarını görüntüleme
Kümede performans iyileştirmesi gerçekleştirmeden önce geçerli HDInsight kümesi yapılandırma ayarlarını doğrulayın. Spark kümesi bölmesindeki Pano bağlantısına tıklayarak Azure portalından HDInsight Panosu'nu başlatın. Küme yöneticisinin kullanıcı adı ve parolası ile oturum açın.
Apache Ambari Web kullanıcı arabirimi, anahtar kümesi kaynak kullanım ölçümleri panosuyla birlikte görüntülenir. Ambari Panosu size Apache Spark yapılandırmasını ve diğer yüklü hizmetleri gösterir. Pano, Spark dahil olmak üzere yüklü hizmetlerle ilgili bilgileri görüntüleyebileceğiniz bir Yapılandırma Geçmişi sekmesi içerir.
Apache Spark yapılandırma değerlerini görmek için Yapılandırma Geçmişi'ne ve ardından Spark2'ye tıklayın. Yapılandırmalar sekmesini ve ardından hizmet listesinden (veya Spark2sürümünüze bağlı olarak) bağlantısını seçin Spark . Kümeniz için yapılandırma değerlerinin listesini görürsünüz:
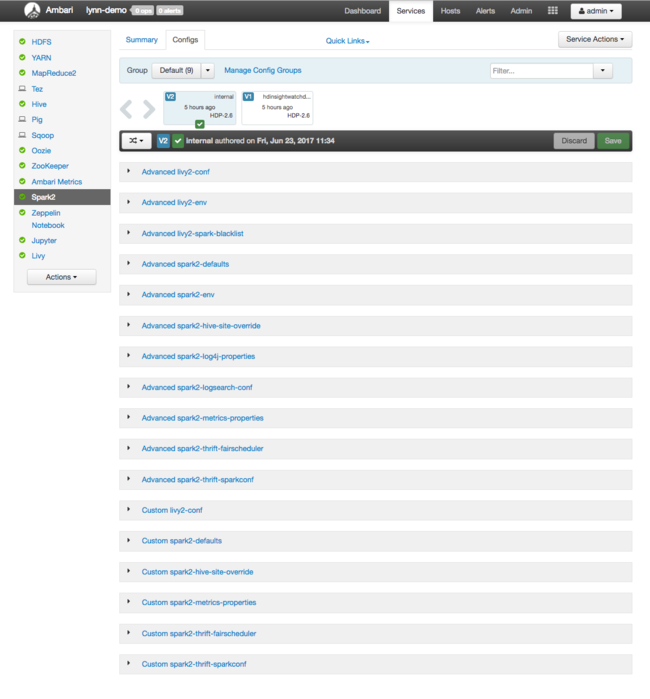
Tek tek Spark yapılandırma değerlerini görmek ve değiştirmek için başlıkta "spark" bulunan herhangi bir bağlantıyı seçin. Spark yapılandırmaları şu kategorilerde hem özel hem de gelişmiş yapılandırma değerlerini içerir:
- Özel Spark2 varsayılanları
- Özel Spark2 ölçüm özellikleri
- Gelişmiş Spark2 varsayılanları
- Gelişmiş Spark2-env
- Gelişmiş spark2-hive-site-override
Varsayılan olmayan bir yapılandırma değerleri kümesi oluşturursanız güncelleştirme geçmişiniz görünür. Bu yapılandırma geçmişi, varsayılan olmayan yapılandırmanın en iyi performansa sahip olduğunu görmek için yararlı olabilir.
Not
Yaygın Spark kümesi yapılandırma ayarlarını görmek ancak değiştirmek değil, üst düzey Spark İşi kullanıcı arabiriminde Ortam sekmesini seçin.
Spark yürütücülerini yapılandırma
Aşağıdaki diyagramda önemli Spark nesneleri gösterilmektedir: sürücü programı ve ilişkili Spark Bağlamı ile küme yöneticisi ve n çalışan düğümleri. Her çalışan düğümü bir Yürütücü, önbellek ve n görev örneği içerir.
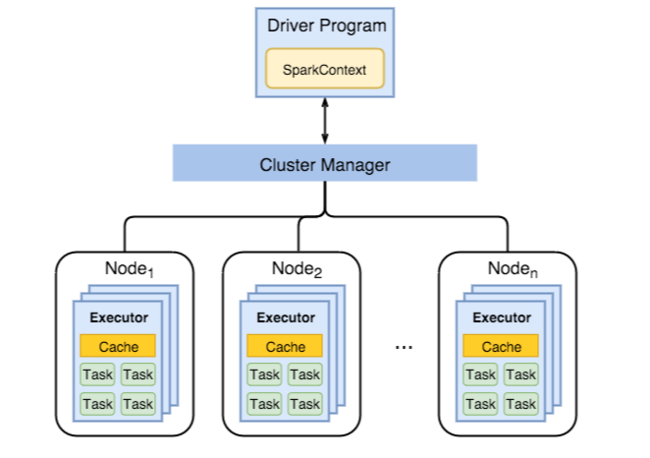
Spark işleri çalışan kaynaklarını, özellikle belleği kullanır, bu nedenle çalışan düğümü Yürütücüleri için Spark yapılandırma değerlerini ayarlamak yaygın bir işlemdir.
Uygulama gereksinimlerini geliştirmek için Spark yapılandırmalarını ayarlamak için genellikle ayarlanan üç önemli parametre : spark.executor.instances, spark.executor.coresve spark.executor.memory. Yürütücü, Spark uygulaması için başlatılan bir işlemdir. Yürütücü çalışan düğümünde çalışır ve uygulamanın görevlerinde sorumludur. Çalışan düğümlerinin sayısı ve çalışan düğümü boyutu, yürütücü sayısını ve yürütücü boyutlarını belirler. Bu değerler içinde küme baş düğümlerinde depolanır spark-defaults.conf . Ambari web kullanıcı arabiriminde Özel spark-defaults'ı seçerek bu değerleri çalışan bir kümede düzenleyebilirsiniz. Değişiklik yaptıktan sonra, kullanıcı arabirimi tarafından etkilenen tüm hizmetleri yeniden başlatmanız istenir.
Not
Bu üç yapılandırma parametresi, küme düzeyinde yapılandırılabilir (kümede çalışan tüm uygulamalar için) ve her bir uygulama için de belirtilebilir.
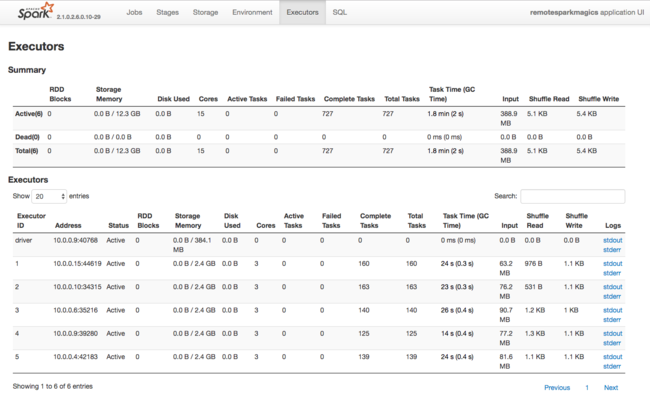
Spark Yürütücüleri tarafından kullanılan kaynaklar hakkında bir diğer bilgi kaynağı da Spark Uygulaması kullanıcı arabirimidir. Kullanıcı arabiriminde Yürütücüler yapılandırma ve tüketilen kaynakların Özet ve Ayrıntı görünümlerini görüntüler. Tüm küme için yürütücü değerlerinin mi yoksa belirli bir iş yürütme kümesinin mi değiştirileceğini belirleyin.
İsterseniz, HDInsight ve Spark kümesi yapılandırma ayarlarını program aracılığıyla doğrulamak için Ambari REST API'sini de kullanabilirsiniz. GitHub'daki Apache Ambari API başvurusunda daha fazla bilgi bulabilirsiniz.
Spark iş yükünüze bağlı olarak, varsayılan dışındaki bir Spark yapılandırmasının daha iyi Spark iş yürütmeleri sağladığına karar verebilirsiniz. Varsayılan olmayan küme yapılandırmalarını doğrulamak için örnek iş yükleriyle karşılaştırma testi yapın. Ayarlamayı düşünebileceğiniz yaygın parametrelerden bazıları:
| Parametre | Açıklama |
|---|---|
| --num-executors | Yürütücü sayısını ayarlar. |
| --yürütücü çekirdekleri | Her yürütücü için çekirdek sayısını ayarlar. Diğer işlemler de kullanılabilir belleğin bir kısmını tükettiğinden orta büyüklükte yürütücüler kullanmanızı öneririz. |
| --executor-memory | Apache Hadoop YARN üzerindeki her yürütücünün bellek boyutunu (yığın boyutu) denetler ve yürütme yükü için biraz bellek bırakmanız gerekir. |
Aşağıda, farklı yapılandırma değerlerine sahip iki çalışan düğümü örneği verilmiştir:

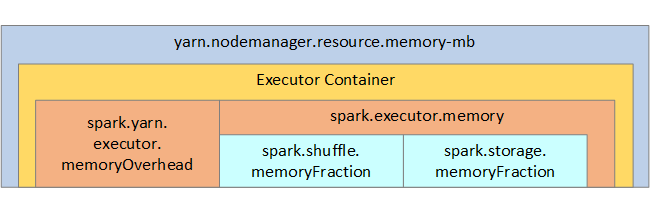
Aşağıdaki listede anahtar Spark yürütücüsü bellek parametreleri gösterilmektedir.
| Parametre | Açıklama |
|---|---|
| spark.executor.memory | Yürütücü için kullanılabilir toplam bellek miktarını tanımlar. |
| spark.storage.memoryFraction | Kalıcı RDD'leri depolamak için kullanılabilir bellek miktarını (%varsayılan ~%60) tanımlar. |
| spark.shuffle.memoryFraction | Karıştırma için ayrılan bellek miktarını (%varsayılan ~%20) tanımlar. |
| spark.storage.unrollFraction ve spark.storage.safetyFraction | (toplam belleğin yaklaşık %30'unun toplamı) - bu değerler Spark tarafından dahili olarak kullanılır ve değiştirilmemelidir. |
YARN, her Spark düğümündeki kapsayıcılar tarafından kullanılan maksimum bellek toplamını denetler. Aşağıdaki diyagramda YARN yapılandırma nesneleri ile Spark nesneleri arasındaki düğüm başına ilişkiler gösterilmektedir.
Jupyter Notebook'ta çalışan bir uygulamanın parametrelerini değiştirme
HDInsight'taki Spark kümeleri varsayılan olarak bir dizi bileşen içerir. Bu bileşenlerin her biri, gerektiğinde geçersiz kılınabilen varsayılan yapılandırma değerlerini içerir.
| Bileşen | Veri Akışı Açıklaması |
|---|---|
| Spark Core | Spark Core, Spark SQL, Spark akış API'leri, GraphX ve Apache Spark MLlib. |
| Anaconda | Python paket yöneticisi. |
| Apache Livy | Uzak işleri bir HDInsight Spark kümesine göndermek için kullanılan Apache Spark REST API'si. |
| Jupyter Not Defterleri ve Apache Zeppelin Not Defterleri | Spark kümenizle etkileşime yönelik etkileşimli tarayıcı tabanlı kullanıcı arabirimi. |
| ODBC sürücüsü | HDInsight'ta Spark kümelerini Microsoft Power BI ve Tableau gibi iş zekası (BI) araçlarına Bağlan. |
Jupyter Not Defteri'nde çalışan uygulamalar için komutunu kullanarak %%configure not defterinin içinden yapılandırma değişiklikleri yapın. Bu yapılandırma değişiklikleri, not defteri örneğinizden çalıştırılacak Spark işlerine uygulanır. İlk kod hücrenizi çalıştırmadan önce uygulamanın başında bu tür değişiklikler yapın. Değiştirilen yapılandırma, livy oturumu oluşturulduğunda uygulanır.
Not
Uygulamanın sonraki bir aşamasında yapılandırmayı değiştirmek için (force) parametresini -f kullanın. Ancak, uygulamadaki tüm ilerlemeler kaybolur.
Aşağıdaki kod, Jupyter Notebook'ta çalışan bir uygulamanın yapılandırmasını nasıl değiştireceğini gösterir.
%%configure
{"executorMemory": "3072M", "executorCores": 4, "numExecutors":10}
Sonuç
Spark işlerinizin tahmin edilebilir ve performanslı bir şekilde çalıştığından emin olmak için temel yapılandırma ayarlarını izleyin. Bu ayarlar, belirli iş yükleriniz için en iyi Spark kümesi yapılandırmasını belirlemeye yardımcı olur. Ayrıca uzun süre çalışan ve veya kaynak kullanan Spark işi yürütmelerini izlemeniz gerekir. En yaygın zorluklar, yanlış boyutlandırılmış yürütücüler gibi yanlış yapılandırmalardan kaynaklanan bellek baskısını ortadan kaldırır. Ayrıca, kartezyen işlemlerine neden olan uzun süre çalışan işlemler ve görevler.