Azure HDInsight'ta Apache Spark için OutOfMemoryError özel durumları
Bu makalede, Azure HDInsight kümelerinde Apache Spark bileşenlerini kullanırken karşılaşılan sorunlara yönelik sorun giderme adımları ve olası çözümler açıklanmaktadır.
Senaryo: Apache Spark için OutOfMemoryError özel durumu
Sorun
Apache Spark uygulamanız OutOfMemoryError işlenmeyen özel durumla başarısız oldu. Şuna benzer bir hata iletisi alabilirsiniz:
ERROR Executor: Exception in task 7.0 in stage 6.0 (TID 439)
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.grow(Unknown Source)
at java.io.ByteArrayOutputStream.ensureCapacity(Unknown Source)
at java.io.ByteArrayOutputStream.write(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.drain(Unknown Source)
at java.io.ObjectOutputStream$BlockDataOutputStream.setBlockDataMode(Unknown Source)
at java.io.ObjectOutputStream.writeObject0(Unknown Source)
at java.io.ObjectOutputStream.writeObject(Unknown Source)
at org.apache.spark.serializer.JavaSerializationStream.writeObject(JavaSerializer.scala:44)
at org.apache.spark.serializer.JavaSerializerInstance.serialize(JavaSerializer.scala:101)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:239)
at java.util.concurrent.ThreadPoolExecutor.runWorker(Unknown Source)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(Unknown Source)
at java.lang.Thread.run(Unknown Source)
ERROR SparkUncaughtExceptionHandler: Uncaught exception in thread Thread[Executor task launch worker-0,5,main]
java.lang.OutOfMemoryError
at java.io.ByteArrayOutputStream.hugeCapacity(Unknown Source)
...
Neden
Bu özel durumun en olası nedeni Java sanal makinelerine (JVM) yeterli yığın belleği ayrılmamış olmasıdır. Bu JVM'ler Apache Spark uygulamasının bir parçası olarak yürütücü veya sürücü olarak başlatılır.
Çözüm
Spark uygulamasının işlediği verilerin en büyük boyutunu belirleyin. Giriş verileri, giriş verilerinin dönüştürülmesiyle üretilen ara veriler ve ara verilerin de dönüştürülmesiyle üretilen çıkış verileri için boyut üst sınırları temel alınarak bir boyut tahmininde bulunun. İlk tahmin yeterli olmazsa boyutu biraz artırın ve bellek hataları azalana kadar bu işlemi yineleyin.
Kullanılacak HDInsight kümesinin, Spark uygulamasını barındırmak için yeterli kaynağa (bellek ve ayrıca çekirdek olarak) sahip olduğundan emin olun. Bu, Kullanılan Bellek ile Kullanılan Bellek Toplamı ve KullanılanSanal Çekirdekler ile Sanal Çekirdek Toplamı değerlerinin kümenin YARN kullanıcı arabiriminin Küme Ölçümleri bölümü görüntülenerek belirlenebilir.

Aşağıdaki Spark yapılandırmalarını uygun değerlere ayarlayın. Uygulama gereksinimlerini kümedeki kullanılabilir kaynaklarla dengeleyin. Bu değerler YARN tarafından görüntülendiği şekilde kullanılabilir belleğin ve çekirdeklerin %90'ını aşmamalı ve Spark uygulamasının en düşük bellek gereksinimini karşılamalıdır:
spark.executor.instances (Example: 8 for 8 executor count) spark.executor.memory (Example: 4g for 4 GB) spark.yarn.executor.memoryOverhead (Example: 384m for 384 MB) spark.executor.cores (Example: 2 for 2 cores per executor) spark.driver.memory (Example: 8g for 8GB) spark.driver.cores (Example: 4 for 4 cores) spark.yarn.driver.memoryOverhead (Example: 384m for 384MB)Tüm yürütücüler tarafından kullanılan toplam bellek =
spark.executor.instances * (spark.executor.memory + spark.yarn.executor.memoryOverhead)Sürücü tarafından kullanılan toplam bellek =
spark.driver.memory + spark.yarn.driver.memoryOverhead
Senaryo: Apache Spark geçmiş sunucusunu açmaya çalışırken Java yığın alanı hatası
Sorun
Spark Geçmişi sunucusunda olayları açarken aşağıdaki hatayı alıyorsunuz:
scala.MatchError: java.lang.OutOfMemoryError: Java heap space (of class java.lang.OutOfMemoryError)
Neden
Bu sorun genellikle büyük spark-event dosyalarını açarken kaynak eksikliğinden kaynaklanır. Spark yığını boyutu varsayılan olarak 1 GB olarak ayarlanır, ancak büyük Spark olay dosyaları bundan daha fazlasını gerektirebilir.
Yüklemeye çalıştığınız dosyaların boyutunu doğrulamak isterseniz aşağıdaki komutları gerçekleştirebilirsiniz:
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0274_1/
**576.5 M** wasb:///hdp/spark2-events/application_1503957839788_0274_1
hadoop fs -du -s -h wasb:///hdp/spark2-events/application_1503957839788_0264_1/
**2.1 G** wasb:///hdp/spark2-events/application_1503957839788_0264_1
Çözüm
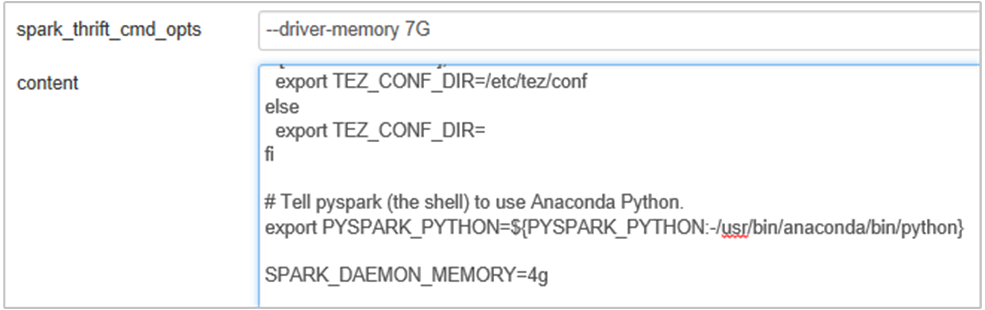
Spark yapılandırmasında özelliğini düzenleyip SPARK_DAEMON_MEMORY tüm hizmetleri yeniden başlatarak Spark Geçmiş Sunucusu belleğini artırabilirsiniz.
Spark2/Config/Advanced spark2-env bölümünü seçerek bunu Ambari tarayıcı kullanıcı arabiriminden yapabilirsiniz.
Spark Geçmiş Sunucusu belleğini 1g'den 4g'ye değiştirmek için aşağıdaki özelliği ekleyin: SPARK_DAEMON_MEMORY=4g.
Ambari'den etkilenen tüm hizmetleri yeniden başlattığınızdan emin olun.
Senaryo: Livy Server Apache Spark kümesinde başlatılamıyor
Sorun
Livy Server bir Apache Spark üzerinde başlatılamıyor [(Linux üzerinde Spark 2.1 (HDI 3.6)]. Yeniden başlatma girişimi, Livy günlüklerinden aşağıdaki hata yığınıyla sonuçlanır:
17/07/27 17:52:50 INFO CuratorFrameworkImpl: Starting
17/07/27 17:52:50 INFO ZooKeeper: Client environment:zookeeper.version=3.4.6-29--1, built on 05/15/2017 17:55 GMT
17/07/27 17:52:50 INFO ZooKeeper: Client environment:host.name=10.0.0.66
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.version=1.8.0_131
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.vendor=Oracle Corporation
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.home=/usr/lib/jvm/java-8-openjdk-amd64/jre
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.class.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.library.path= <DELETED>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.io.tmpdir=/tmp
17/07/27 17:52:50 INFO ZooKeeper: Client environment:java.compiler=<NA>
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.name=Linux
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.arch=amd64
17/07/27 17:52:50 INFO ZooKeeper: Client environment:os.version=4.4.0-81-generic
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.name=livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.home=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Client environment:user.dir=/home/livy
17/07/27 17:52:50 INFO ZooKeeper: Initiating client connection, connectString=<zookeepername1>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername2>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181,<zookeepername3>.cxtzifsbseee1genzixf44zzga.gx.internal.cloudapp.net:2181 sessionTimeout=60000 watcher=org.apache.curator.ConnectionState@25fb8912
17/07/27 17:52:50 INFO StateStore$: Using ZooKeeperStateStore for recovery.
17/07/27 17:52:50 INFO ClientCnxn: Opening socket connection to server 10.0.0.61/10.0.0.61:2181. Will not attempt to authenticate using SASL (unknown error)
17/07/27 17:52:50 INFO ClientCnxn: Socket connection established to 10.0.0.61/10.0.0.61:2181, initiating session
17/07/27 17:52:50 INFO ClientCnxn: Session establishment complete on server 10.0.0.61/10.0.0.61:2181, sessionid = 0x25d666f311d00b3, negotiated timeout = 60000
17/07/27 17:52:50 INFO ConnectionStateManager: State change: CONNECTED
17/07/27 17:52:50 WARN NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/07/27 17:52:50 INFO AHSProxy: Connecting to Application History server at headnodehost/10.0.0.67:10200
Exception in thread "main" java.lang.OutOfMemoryError: unable to create new native thread
at java.lang.Thread.start0(Native Method)
at java.lang.Thread.start(Thread.java:717)
at com.cloudera.livy.Utils$.startDaemonThread(Utils.scala:98)
at com.cloudera.livy.utils.SparkYarnApp.<init>(SparkYarnApp.scala:232)
at com.cloudera.livy.utils.SparkApp$.create(SparkApp.scala:93)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:117)
at com.cloudera.livy.server.batch.BatchSession$$anonfun$recover$2$$anonfun$apply$4.apply(BatchSession.scala:116)
at com.cloudera.livy.server.batch.BatchSession.<init>(BatchSession.scala:137)
at com.cloudera.livy.server.batch.BatchSession$.recover(BatchSession.scala:108)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at com.cloudera.livy.sessions.BatchSessionManager$$anonfun$$init$$1.apply(SessionManager.scala:47)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.TraversableLike$$anonfun$map$1.apply(TraversableLike.scala:244)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at scala.collection.TraversableLike$class.map(TraversableLike.scala:244)
at scala.collection.AbstractTraversable.map(Traversable.scala:105)
at com.cloudera.livy.sessions.SessionManager.com$cloudera$livy$sessions$SessionManager$$recover(SessionManager.scala:150)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at com.cloudera.livy.sessions.SessionManager$$anonfun$1.apply(SessionManager.scala:82)
at scala.Option.getOrElse(Option.scala:120)
at com.cloudera.livy.sessions.SessionManager.<init>(SessionManager.scala:82)
at com.cloudera.livy.sessions.BatchSessionManager.<init>(SessionManager.scala:42)
at com.cloudera.livy.server.LivyServer.start(LivyServer.scala:99)
at com.cloudera.livy.server.LivyServer$.main(LivyServer.scala:302)
at com.cloudera.livy.server.LivyServer.main(LivyServer.scala)
## using "vmstat" found we had enough free memory
Neden
java.lang.OutOfMemoryError: unable to create new native thread vurgular, işletim sistemi JVM'lere daha fazla yerel iş parçacığı atayamaz. Bu Özel Durumun işlem başına iş parçacığı sayısı sınırının ihlalinden kaynaklandığı onaylandı.
Livy Server beklenmedik şekilde sonlandırıldığında Spark Kümelerine yönelik tüm bağlantılar da sonlandırılır ve bu da tüm işlerin ve ilgili verilerin kaybedildiği anlamına gelir. HDP 2.6 oturum kurtarma mekanizması kullanıma sunulduğunda Livy, Livy Server geri döndükten sonra kurtarılacak oturum ayrıntılarını Zookeeper'da depolar.
Livy aracılığıyla çok sayıda iş gönderildiğinde, Livy Server için Yüksek Kullanılabilirlik kapsamında bu oturum durumları ZK'de (HDInsight kümelerinde) depolanır ve Livy hizmeti yeniden başlatıldığında bu oturumları kurtarır. Beklenmeyen sonlandırmadan sonra yeniden başlatıldığında Livy oturum başına bir iş parçacığı oluşturur ve bu, çok fazla iş parçacığı oluşturulmasına neden olan kurtarılacak bazı oturumları biriktirir.
Çözüm
Aşağıdaki adımları kullanarak tüm girişleri silin.
kullanarak zookeeper Düğümlerinin IP adresini alma
grep -R zk /etc/hadoop/confYukarıdaki komut bir küme için tüm zookeeper'ları listelemektedir
/etc/hadoop/conf/core-site.xml: <value><zookeepername1>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername2>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181,<zookeepername3>.lnuwp5akw5ie1j2gi2amtuuimc.dx.internal.cloudapp.net:2181</value>Ping kullanarak zookeeper düğümlerinin tüm IP adresini alın Veya zookeeper adını kullanarak baş düğümden zookeeper'a da bağlanabilirsiniz
/usr/hdp/current/zookeeper-client/bin/zkCli.sh -server <zookeepername1>:2181Bağlandıktan sonra zookeeper'a aşağıdaki komutu yürüterek yeniden başlatmaya çalışılan tüm oturumları listeleyin.
Bu durumların çoğu 8000'den fazla oturum içeren bir liste olabilir ####
ls /livy/v1/batchAşağıdaki komut kurtarılacak tüm oturumları kaldırmaktır. #####
rmr /livy/v1/batch
Yukarıdaki komutun tamamlanmasını bekleyin ve imlecin istemi döndürmesini bekleyin ve ardından Livy hizmetini Ambari'den yeniden başlatın. Bu işlemin başarılı olması gerekir.
Not
DELETE livy oturumunun yürütülmesi tamamlandıktan sonra. Spark uygulaması tamamlandığında Livy toplu iş oturumları otomatik olarak silinmez ve bu da tasarım gereğidir. Livy oturumu, Livy REST sunucusuna yönelik post isteği tarafından oluşturulan bir varlıktır. Bu DELETE varlığı silmek için bir çağrı gerekir. Ya da gc'nin devreye geçmesini beklemeliyiz.
Sonraki adımlar
Sorununuzu görmediyseniz veya sorununuzu çözemiyorsanız daha fazla destek için aşağıdaki kanallardan birini ziyaret edin:
HDInsight kümelerinde Spark uygulamasında hata ayıklama.
Azure Topluluk Desteği aracılığıyla Azure uzmanlarından yanıt alın.
@AzureSupport ile Bağlan - müşteri deneyimini geliştirmeye yönelik resmi Microsoft Azure hesabı. Azure topluluğunun doğru kaynaklara Bağlan: yanıtlar, destek ve uzmanlar.
Daha fazla yardıma ihtiyacınız varsa Azure portalından bir destek isteği gönderebilirsiniz. Menü çubuğundan Destek'i seçin veya Yardım + destek hub'ını açın. Daha ayrıntılı bilgi için bkz. Azure desteği isteği oluşturma. Abonelik Yönetimi’ne ve faturalandırma desteğine erişim Microsoft Azure aboneliğinize dahildir, Teknik Destek ise herhangi bir Azure Destek Planı üzerinden sağlanır.