Azure HDInsight kullanarak Apache Spark sorunlarını giderme
Apache Ambari'de Apache Spark yükleriyle çalışırken karşılaşılan en önemli sorunlar ve bunların çözümleri hakkında bilgi edinin.
Kümeler üzerinde Apache Ambari kullanarak bir Apache Spark uygulamasını nasıl yapılandırabilirim?
Spark yapılandırma değerleri ayarlanabilir, Apache Spark uygulaması OutofMemoryError özel durumunu önlemeye yardımcı olabilir. Aşağıdaki adımlar Azure HDInsight'ta varsayılan Spark yapılandırma değerlerini gösterir:
Küme kimlik bilgilerinizle Ambari'de
https://CLUSTERNAME.azurehdidnsight.netoturum açın. İlk ekranda bir genel bakış panosu görüntülenir. HDInsight 4.0 arasında hafif kozmetik farklılıklar vardır.Spark2>Yapılandırmaları'na gidin.
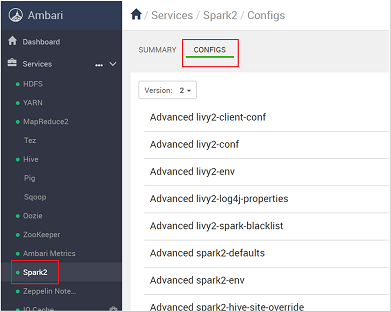
Yapılandırma listesinde Custom-spark2-defaults öğesini seçin ve genişletin.
Spark.executor.memory gibi ayarlamanız gereken değer ayarını arayın. Bu durumda, 9728m değeri çok yüksektir.
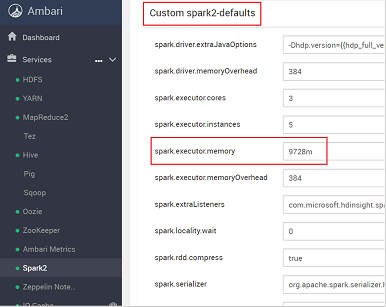
Değeri önerilen ayara ayarlayın. Bu ayar için 2048m değeri önerilir.
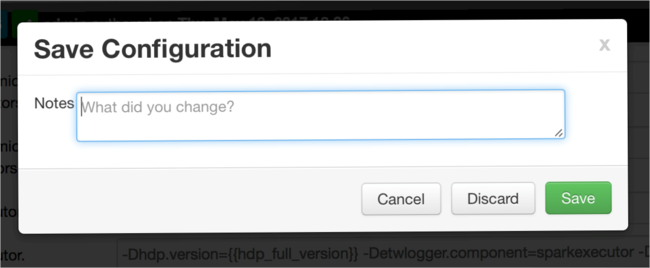
Değeri kaydedin ve ardından yapılandırmayı kaydedin. Kaydet'i seçin.

Yapılandırma değişiklikleri hakkında bir not yazıp Kaydet'i seçin.
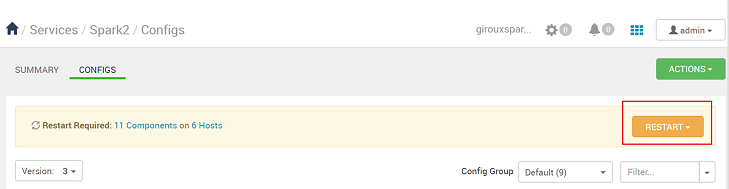
İlgilenilmesi gereken yapılandırmalar varsa size bildirilir. Öğeleri not edin ve yine de Devam Et'i seçin.

Bir yapılandırma kaydedildiğinde, hizmeti yeniden başlatmanız istenir. Yeniden Başlat'ı seçin.
Yeniden başlatmayı onaylayın.
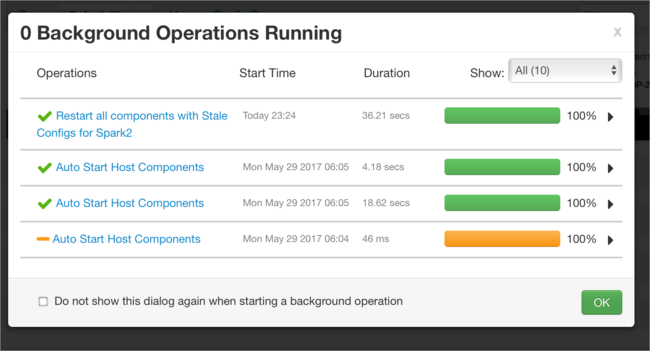
Çalışan işlemleri gözden geçirebilirsiniz.
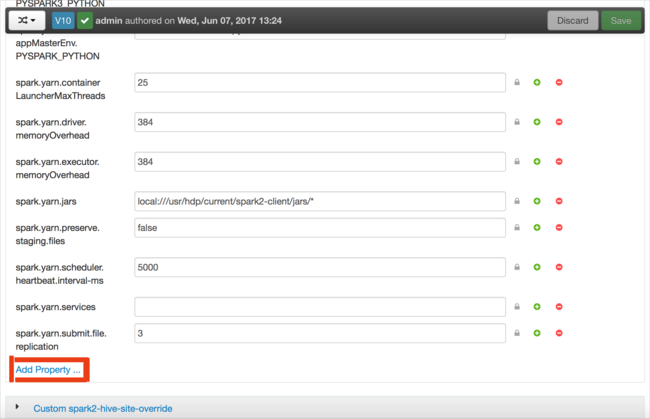
Yapılandırmalar ekleyebilirsiniz. Yapılandırma listesinde Custom-spark2-defaults öğesini ve ardından Özellik Ekle'yi seçin.
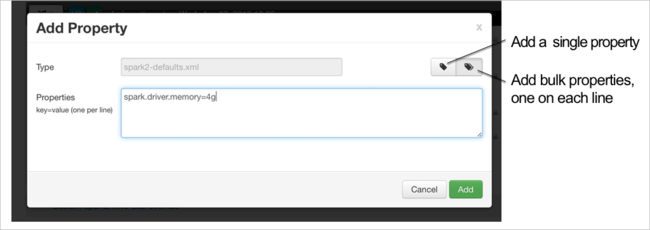
Yeni bir özellik tanımlayın. Veri türü gibi belirli ayarlar için bir iletişim kutusu kullanarak tek bir özellik tanımlayabilirsiniz. Veya satır başına bir tanım kullanarak birden çok özellik tanımlayabilirsiniz.
Bu örnekte spark.driver.memory özelliği 4g değeriyle tanımlanır.
Yapılandırmayı kaydedin ve 6. ve 7. adımlarda açıklandığı gibi hizmeti yeniden başlatın.
Bu değişiklikler küme genelindedir ancak Spark işini gönderdiğinizde geçersiz kılınabilir.
Kümelerde Jupyter Notebook kullanarak Apache Spark uygulamasını Nasıl yaparım? yapılandırabilirsiniz?
Jupyter Notebook'un ilk hücresinde, %%configure yönergesinin ardından Spark yapılandırmalarını geçerli JSON biçiminde belirtin. Gerçek değerleri gerektiği gibi değiştirin:

Kümeler üzerinde Apache Livy kullanarak bir Apache Spark uygulamasını nasıl yapılandırabilirim?
Spark uygulamasını, cURL gibi bir REST istemcisi kullanarak Livy'ye gönderin. Aşağıdakine benzer bir komut kullanın. Gerçek değerleri gerektiği gibi değiştirin:
curl -k --user 'username:password' -v -H 'Content-Type: application/json' -X POST -d '{ "file":"wasb://container@storageaccountname.blob.core.windows.net/example/jars/sparkapplication.jar", "className":"com.microsoft.spark.application", "numExecutors":4, "executorMemory":"4g", "executorCores":2, "driverMemory":"8g", "driverCores":4}'
Kümeler üzerinde spark-submit kullanarak bir Apache Spark uygulamasını nasıl yapılandırabilirim?
Aşağıdakine benzer bir komut kullanarak spark-shell'i başlatın. Yapılandırmaların gerçek değerini gerektiği gibi değiştirin:
spark-submit --master yarn-cluster --class com.microsoft.spark.application --num-executors 4 --executor-memory 4g --executor-cores 2 --driver-memory 8g --driver-cores 4 /home/user/spark/sparkapplication.jar
Ek okuma
HDInsight kümelerinde Apache Spark iş gönderimi
Sonraki adımlar
Sorununuzu görmediyseniz veya sorununuzu çözemiyorsanız daha fazla destek için aşağıdaki kanallardan birini ziyaret edin:
HDInsight kümelerinde Spark uygulamasında hata ayıklama.
Azure Topluluk Desteği aracılığıyla Azure uzmanlarından yanıt alın.
@AzureSupport ile Bağlan - müşteri deneyimini geliştirmeye yönelik resmi Microsoft Azure hesabı. Azure topluluğunun doğru kaynaklara Bağlan: yanıtlar, destek ve uzmanlar.
Daha fazla yardıma ihtiyacınız varsa Azure portalından bir destek isteği gönderebilirsiniz. Menü çubuğundan Destek'i seçin veya Yardım + destek hub'ını açın. Daha ayrıntılı bilgi için bkz. Azure desteği isteği oluşturma. Abonelik Yönetimi’ne ve faturalandırma desteğine erişim Microsoft Azure aboneliğinize dahildir, Teknik Destek ise herhangi bir Azure Destek Planı üzerinden sağlanır.