K Ortalamaları Kümeleme
Önemli
Machine Learning Stüdyosu (klasik) desteği 31 Ağustos 2024'te sona erecektir. Bu tarihe kadar Azure Machine Learning'e geçmenizi öneririz.
1 Aralık 2021'den başlayarak artık yeni Machine Learning Stüdyosu (klasik) kaynakları oluşturamayacaksınız. 31 Ağustos 2024'e kadar mevcut Machine Learning Stüdyosu (klasik) kaynaklarını kullanmaya devam edebilirsiniz.
- Makine öğrenmesi projelerini ML Studio'dan (klasik) Azure Machine Learning'e taşıma hakkındaki bilgilere bakın.
- Azure Machine Learning hakkında daha fazla bilgi edinin.
ML Stüdyosu (klasik) belgeleri kullanımdan kaldırılacak ve gelecekte güncelleştirilmeyecektir.
K ortalamalar kümeleme modelini yapılandırıp başlatır
Kategori: Machine Learning / Modeli Başlatma / Kümeleme
Not
Şunlar için geçerlidir: Yalnızca Machine Learning Studio (klasik)
Benzer sürükle ve bırak modülleri Azure Machine Learning tasarımcısında da kullanılabilir.
Modüle genel bakış
Bu makalede, eğitilmemiş bir K ortalamalar kümeleme modeli oluşturmak için Machine Learning Studio'daki (klasik) K-Means Kümeleme modülünün nasıl kullanılacağı açıklanmaktadır.
K ortalamalar, en basit ve en iyi bilinen denetimsiz öğrenme algoritmalarından biridir ve anormal verileri algılama, metin belgelerinin kümelenmesi ve diğer sınıflandırma veya regresyon yöntemlerini kullanmadan önce bir veri kümesinin analizi gibi çeşitli makine öğrenmesi görevleri için kullanılabilir. Kümeleme modeli oluşturmak için bu modülü denemenize ekler, bir veri kümesini bağlar ve beklediğiniz küme sayısı, kümeleri oluştururken kullanılacak uzaklık ölçümü gibi parametreleri ayarlarsınız.
Modülün hiper parametrelerini yapılandırdıktan sonra, sağladığınız giriş verileri üzerinde modeli eğitmek için eğitilmemiş modeli Kümeleme Modelini Eğitme veya Süpür Kümeleme modüllerine bağlayın. K ortalamalar algoritması denetimsiz bir öğrenme yöntemi olduğundan etiket sütunu isteğe bağlıdır.
- Verilerinizde bir etiket varsa, küme seçimine yol göstermek ve modeli iyileştirmek için etiket değerlerini kullanabilirsiniz.
- Verilerinizde etiket yoksa, algoritma yalnızca verileri temel alarak olası kategorileri temsil eden kümeler oluşturur.
İpucu
Eğitim verilerinizde etiketler varsa Machine Learning'de sağlanan denetimli sınıflandırma yöntemlerinden birini kullanmayı göz önünde bulundurun. Örneğin, çok sınıflı karar ağacı algoritmalarından birini kullanırken kümelemenin sonuçlarını sonuçlarla karşılaştırabilirsiniz.
K ortalamalar kümelesini anlama
Genel olarak kümeleme, bir veri kümesindeki durumları benzer özelliklere sahip kümeler halinde gruplandırmak için yinelemeli teknikler kullanır. Bu gruplandırmalar verileri keşfetmek, verilerdeki anomalileri tanımlamak ve sonunda tahminler yapmak için kullanışlıdır. Kümeleme modelleri, göz atarak veya basit bir gözlemle mantıksal olarak türetmeyebileceğiniz bir veri kümesindeki ilişkileri belirlemenize de yardımcı olabilir. Bu nedenlerden dolayı kümeleme genellikle makine öğrenmesi görevlerinin ilk aşamalarında verileri keşfetmek ve beklenmeyen bağıntıları keşfetmek için kullanılır.
Bir kümeleme modelini k-ortalamalar yöntemini kullanarak yapılandırdığınızda, modelde istediğiniz centroid sayısını belirten bir hedef k sayısı belirtmeniz gerekir. Centroid, her kümeyi temsil eden bir noktadır. K ortalamalar algoritması, küme içi kare toplamını en aza indirerek gelen her veri noktasını kümelerden birine atar.
Eğitim verilerini işlerken, K ortalamalar algoritması her küme için başlangıç noktası görevi görecek ve centroidlerin konumlarını yinelemeli olarak daraltmak için Lloyd algoritmasını uygulayan rastgele seçilmiş ilk centroid kümesiyle başlar. K-ortalamalar algoritması, şu koşullardan birini veya daha fazlasını karşıladığında kümeleri derlemeyi ve iyileştirmeyi durdurur:
Merkezroidler dengelenir, yani tek tek noktalar için küme atamaları artık değişmez ve algoritma bir çözüm üzerinde yakınsanır.
Algoritma, belirtilen sayıda yineleme çalıştırarak tamamlandı.
Eğitim aşamasını tamamladıktan sonra, k-ortalamalar algoritması tarafından bulunan kümelerden birine yeni servis talepleri atamak için Kümelere Veri Atama modülünü kullanırsınız. Küme ataması, yeni durumla her kümenin merkezkti arasındaki uzaklık hesaplanarak gerçekleştirilir. Her yeni durum, en yakın centroid ile kümeye atanır.
K-Ortalamalar Kümelemeyi yapılandırma
Denemenize K-Means Kümeleme modülünü ekleyin.
Eğitmen modu oluştur seçeneğini ayarlayarak modelin nasıl eğitileceğini belirtin.
Tek Parametre: Kümeleme modelinde kullanmak istediğiniz parametrelerin tam olarak farkındaysanız, bağımsız değişken olarak belirli bir değer kümesi sağlayabilirsiniz.
Parametre Aralığı: En iyi parametrelerden emin değilseniz, birden çok değer belirterek ve en uygun yapılandırmayı bulmak için Kümelemesi Süpür modülünü kullanarak en uygun parametreleri bulabilirsiniz.
Eğitmen, sağladığınız ayarların birden çok bileşimini yineler ve en uygun kümeleme sonuçlarını üreten değerlerin bileşimini belirler.
Centroid Sayısı için algoritmanın başlamasını istediğiniz küme sayısını yazın.
Modelin tam olarak bu sayıda küme üretmesi garanti değildir. Algorithn bu sayıda veri noktasıyla başlar ve Teknik Notlar bölümünde açıklandığı gibi en uygun yapılandırmayı bulmak için yinelenir.
Parametre süpürme işlemi gerçekleştiriyorsanız, özelliğin adı Centroid Sayısı için Aralık olarak değişir. Aralık Oluşturucusu'nu kullanarak bir aralık belirtebilir veya her modeli başlatırken oluşturulacak farklı küme sayılarını temsil eden bir dizi sayı yazabilirsiniz.
Süpürme içinBaşlatma veya Başlatma özellikleri, ilk küme yapılandırmasını tanımlamak için kullanılan algoritmayı belirtmek için kullanılır.
İlk N: Veri kümesinden bazı ilk veri noktası sayısı seçilir ve ilk araç olarak kullanılır.
Forgy yöntemi olarak da adlandırılır.
Rastgele: Algoritma, bir veri noktasını kümeye rastgele yerleştirir ve ardından ilk ortalamayı kümenin rastgele atanan noktalarının merkezi olacak şekilde hesaplar.
Rastgele bölümleme yöntemi olarak da adlandırılır.
K-Means++: Bu, kümeleri başlatmak için varsayılan yöntemdir.
K-ortalamalar ++ algoritması, 2007 yılında David Arthur ve Sergei Vassilvitskii tarafından standart k ortalamalar algoritması tarafından kötü kümelemeden kaçınmak için önerilmiştir. K-ortalamalar ++ , ilk küme merkezlerini seçmek için farklı bir yöntem kullanarak standart K ortalamalarını geliştirir.
K-Means++Hızlı: Daha hızlı kümeleme için iyileştirilmiş K ortalamalar ++ algoritmasının bir çeşidi.
Eşit: Centroid'ler n veri noktalarının d-Boyutlu alanında birbirlerinden eşit olarak bulunur.
Etiket sütununu kullan: Etiket sütunundaki değerler, centroid seçimine yol göstermek için kullanılır.
Rastgele sayı tohumu için isteğe bağlı olarak küme başlatma için tohum olarak kullanılacak bir değer yazın. Bu değerin küme seçimi üzerinde önemli bir etkisi olabilir.
Parametre süpürme kullanırsanız, en iyi ilk tohum değerini aramak için birden çok ilk çekirdeğin oluşturulmasını belirtebilirsiniz. Süpürecek tohum sayısı için başlangıç noktası olarak kullanılacak rastgele çekirdek değerlerinin toplam sayısını yazın.
Ölçüm için, küme vektörleri arasındaki veya yeni veri noktaları ile rastgele seçilen centroid arasındaki mesafeyi ölçmek için kullanılacak işlevi seçin. Machine Learning aşağıdaki küme uzaklığı ölçümlerini destekler:
Öklid: Öklid uzaklığı genellikle K ortalamaları kümeleme için küme dağılım ölçüsü olarak kullanılır. Noktalar ve merkez merkezler arasındaki ortalama uzaklığı en aza indirdiğinden bu ölçüm tercih edilir.
Kosinüs: Kosinüs işlevi, küme benzerliğini ölçmek için kullanılır. Kosinüs benzerliği, vektör uzunluğuna değil, yalnızca açısına önem vermediğiniz durumlarda yararlıdır.
Yinelemeler için, centroids seçimini sonlandırmadan önce algoritmanın eğitim verileri üzerinde kaç kez yinelenmesi gerektiğini yazın.
Bu parametreyi doğruluk ile eğitim süresini dengelemek için ayarlayabilirsiniz.
Etiket atama modu için, veri kümesinde varsa etiket sütununun nasıl işlendiğini belirten bir seçenek belirleyin.
K ortalamalar kümelemesi denetimsiz bir makine öğrenmesi yöntemi olduğundan, etiketler isteğe bağlıdır. Ancak, veri kümenizin zaten bir etiket sütunu varsa, kümelerin seçimine yol göstermek için bu değerleri kullanabilir veya değerlerin yoksayılacağını belirtebilirsiniz.
Etiket sütununu yoksay: Etiket sütunundaki değerler yoksayılır ve modeli oluştururken kullanılmaz.
Eksik değerleri doldurma: Etiket sütunu değerleri, kümelerin oluşturulmasına yardımcı olmak için özellik olarak kullanılır. Herhangi bir satırda etiket eksikse, değer diğer özellikler kullanılarak eklenir.
En yakın merkezden üzerine yaz: Etiket sütunu değerleri, geçerli centroid'e en yakın noktanın etiketi kullanılarak tahmin edilen etiket değerleriyle değiştirilir.
Modeli eğitin.
Eğitmen modu oluştur'uTek Parametre olarak ayarlarsanız etiketli bir veri kümesi ekleyin ve Kümeleme Modelini Eğitme modülünü kullanarak modeli eğitin.
Eğitmen modu oluştur'uParametre Aralığı olarak ayarlarsanız etiketli bir veri kümesi ekleyin ve Süpür Kümele'yi kullanarak modeli eğitin. Bu parametreleri kullanarak eğitilen modeli kullanabilir veya öğrenciyi yapılandırırken kullanılacak parametre ayarlarını not alabilirsiniz.
Sonuçlar
Modeli yapılandırmayı ve eğitmayı tamamladıktan sonra puan oluşturmak için kullanabileceğiniz bir modeliniz vardır. Ancak modeli eğitmenin birden çok yolu ve sonuçları görüntülemenin ve kullanmanın birden çok yolu vardır:
Çalışma alanınızdaki modelin anlık görüntüsünü yakalama
Kümeleme Modelini Eğit modülü kullandıysanız
- Kümeleme Modelini Eğit modülüne sağ tıklayın.
- Eğitilen model'i seçin ve ardından Eğitilen Model Olarak Kaydet'e tıklayın.
Modeli eğitmek için Süpürme Kümeleme modülünü kullandıysanız
- Kümeleme Süpür modülüne sağ tıklayın.
- En İyi Eğitilen model'i seçin ve ardından Eğitilen Model Olarak Kaydet'e tıklayın.
Kaydedilen model, modeli kaydettiğiniz sırada eğitim verilerini temsil eder. Daha sonra denemede kullanılan eğitim verilerini güncelleştirirseniz, kaydedilen model güncelleştirılmaz.
Modeldeki kümelerin görsel gösterimine bakın
Kümeleme Modelini Eğit modülü kullandıysanız
- Modüle sağ tıklayın ve Sonuçlar veri kümesi'ni seçin.
- Görselleştir'i seçin.
Kümeleme süpürme modülünü kullandıysanız
Kümelere Veri Atama modülünün bir örneğini ekleyin ve En İyi Eğitilen modeli kullanarak puanlar oluşturun.
Kümelere Veri Atama modülüne sağ tıklayın, Sonuçlar veri kümesi'ni ve görselleştir'i seçin.
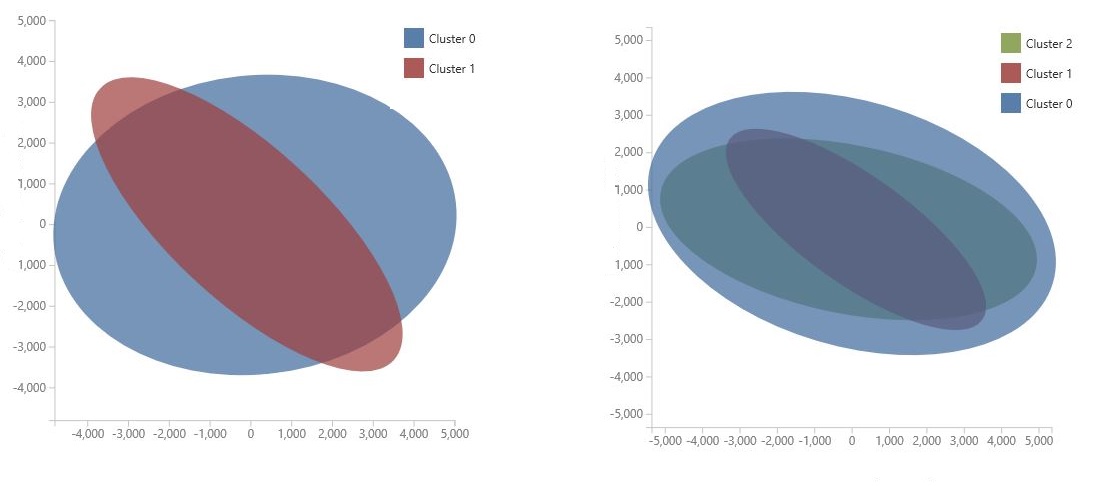
Grafik, veri biliminde modelin özellik alanını sıkıştırmaya yönelik bir teknik olan Temel Bileşen Analizi kullanılarak oluşturulur. Grafik, kümeler arasındaki farkı en iyi şekilde belirleyen, iki boyuta sıkıştırılmış bazı özellikler kümesini gösterir. Her küme için özellik alanının genel boyutunu ve kümelerin ne kadar üst üste bindiği görsel olarak gözden geçirerek modelinizin ne kadar iyi performans gösterebileceği hakkında bir fikir edinebilirsiniz.
Örneğin, aşağıdaki PCA grafikleri aynı veriler kullanılarak eğitilen iki modelin sonuçlarını temsil eder: birincisi iki kümeyi çıkış olarak yapılandırıldı, ikincisi ise üç kümenin çıktısını almak için yapılandırıldı. Bu grafiklerden küme sayısını artırmanın sınıfların ayrılmasını geliştirmediğini görebilirsiniz.
İpucu
Rastgele çekirdek ve başlangıç centroid sayısı dahil olmak üzere en uygun hiper parametre kümesini seçmek için Kümelemeyi Süpür modülünü kullanın.
Veri noktalarının ve ait oldukları kümelerin listesine bakın
Modeli nasıl eğitdiğinize bağlı olarak veri kümesini sonuçlarla görüntülemek için iki seçenek vardır:
Modeli eğitmek için Süpürme Kümeleme modülünü kullandıysanız
- Giriş verilerini sonuçlarla birlikte mi yoksa yalnızca sonuçları mı görmek istediğinizi belirtmek için Kümelemesini Süpürme modülündeki onay kutusunu kullanın.
- Eğitim tamamlandığında modüle sağ tıklayın ve Sonuçlar veri kümesini (çıkış numarası 2) seçin
- Görselleştir'e tıklayın.
Kümeleme Modelini Eğit modülü kullandıysanız
- Kümelere Veri Atama modülünü ekleyin ve eğitilen modeli soldaki girişe bağlayın. Veri kümesini sağ girişe bağlayın.
- Denemenize Veri Kümesine Dönüştürme modülünü ekleyin ve Kümelere Veri Atama'nın çıkışına bağlayın.
- Giriş verilerini sonuçlarla birlikte mi yoksa yalnızca sonuçları mı görmek istediğinizi belirtmek için Kümelere Veri Atama modülündeki onay kutusunu kullanın.
- Denemeyi çalıştırın veya yalnızca Veri Kümesine Dönüştürme modülünü çalıştırın.
- Veri Kümesine Dönüştür'e sağ tıklayın, Sonuçlar veri kümesi'ne tıklayın ve Görselleştir'e tıklayın.
Çıktıda ilk olarak giriş verisi sütunları (bunları dahil ettiyseniz) ve her giriş verisi satırı için aşağıdaki sütunlar bulunur:
Atama: Atama 1 ile n arasında bir değerdir; burada n modeldeki toplam küme sayısıdır. Her veri satırı yalnızca bir kümeye atanabilir.
DistancesToClusterCenter no.n: Bu değer, geçerli veri noktasından kümenin centroidine olan uzaklığı ölçer. Eğitilen modeldeki her küme için çıkışta ayrı bir sütun.
Küme uzaklığı değerleri, küme sonucunu ölçmek için ölçüm seçeneğinde seçtiğiniz uzaklık ölçümünü temel alır. Kümeleme modelinde parametre süpürme işlemi gerçekleştirseniz bile, süpürme sırasında yalnızca bir ölçüm uygulanabilir. Ölçümü değiştirirseniz farklı uzaklık değerleri alabilirsiniz.
Küme içi uzaklıkları görselleştirme
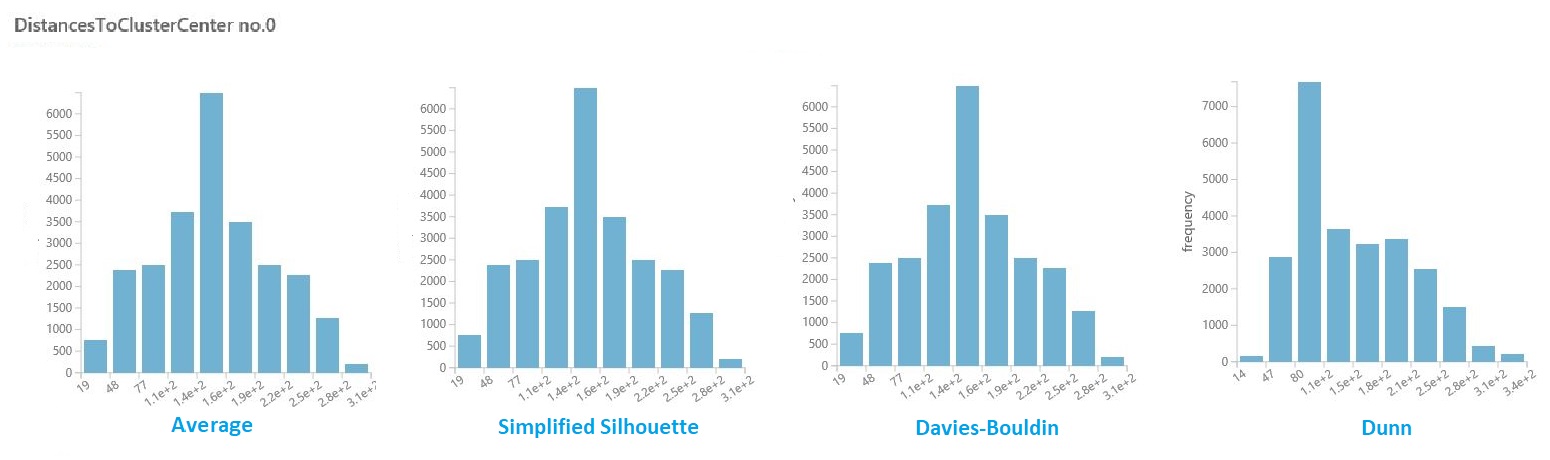
Önceki bölümde yer alan sonuçların veri kümesinde, her küme için uzaklık sütununa tıklayın. Studio (klasik), küme içindeki noktalar için uzaklık dağılımını görselleştiren bir histogram görüntüler.
Örneğin, aşağıdaki histogramlar dört farklı ölçüm kullanarak küme uzaklıklarının aynı denemeden dağılımını gösterir. Parametre süpürme için diğer tüm ayarlar aynıydı. Ölçümün değiştirilmesi, bir modelde farklı sayıda kümeyle sonuçlandı.
Genel olarak, farklı sınıflardaki veri noktaları arasındaki uzaklığı en üst düzeye çıkaran ve sınıf içindeki mesafeleri en aza indiren bir ölçüm seçmelisiniz. Bu kararda size yol göstermek için İstatistikler bölmesindeki önceden derlenmiş araçları ve diğer değerleri kullanabilirsiniz.
İpucu
Machine Learning için PowerShell modülünü kullanarak görselleştirmelerde kullanılan ortalamaları ve diğer değerleri ayıklayabilirsiniz.
Özel bir uzaklık matrisini hesaplamak için R Betiği Yürütme modülünü de kullanabilirsiniz.
En iyi kümeleme modelini oluşturmaya yönelik ipuçları
Kümeleme sırasında kullanılan tohumlama işleminin modeli önemli ölçüde etkileyebileceği bilinmektedir. Tohumlama, noktaların potental centroidlere ilk yerleştirilmesi anlamına gelir.
Örneğin, veri kümesinde çok fazla aykırı değeri varsa ve kümelerin çekirdeğini oluşturmak için aykırı değerler seçilirse, bu kümeye başka hiçbir veri noktası uymaz ve küme tek bir nokta olabilir, yani yalnızca bir noktaya sahip bir küme olabilir.
Bu sorundan kaçınmanın çeşitli yolları vardır:
Centroid sayısını değiştirmek ve birden çok çekirdek değeri denemek için parametre süpürme kullanın.
Ölçümü değiştirerek veya daha fazlasını yineleyerek birden çok model oluşturun.
Kümeleme üzerinde zarar verici etkisi olan değişkenleri bulmak için PCA gibi bir yöntem kullanın. Bu tekniğin gösterimi için Benzer şirketleri bulma örneğine bakın.
Genel olarak, kümeleme modellerinde, belirli bir yapılandırmanın yerel olarak iyileştirilmiş bir küme kümesine neden olması mümkündür. Başka bir deyişle, model tarafından döndürülen küme kümesi yalnızca geçerli veri noktalarına uygundur ve diğer veriler için genelleştirilebilir değildir. Farklı bir ilk yapılandırma kullandıysanız, K-ortalamalar yöntemi farklı, belki de üstün bir yapılandırma bulabilir.
Önemli
Her zaman parametrelerle deneme yapmanızı, birden çok model oluşturmanızı ve sonuçta elde edilen modelleri karşılaştırmanızı öneririz.
Örnekler
K ortalamalar kümelemesinin Machine Learning'de nasıl kullanıldığına ilişkin örnekler için Azure AI Galerisi'ndeki şu denemelere bakın:
Grup iris verileri: Sınıflandırma görevi için K Ortalamalar Kümelemesi ve Çok Sınıflı Lojistik Regresyonun sonuçlarını karşılaştırır.
Renk Niceleme örneği: Optimum görüntü sıkıştırmayı bulmak için farklı parametrelerle birden çok K ortalaması modeli oluşturur.
Kümeleme: Benzer Şirketler: S&P500'de benzer şirket gruplarını bulmak için centroid sayısını değişir.
Teknik notlar
N veri noktalarına sahip bir dizi D boyutlu veri noktası için bulmak üzere belirli sayıda küme (K) verüldüğünde, K ortalamalar algoritması kümeleri aşağıdaki gibi oluşturur:
Modül, bulunan K kümelerini tanımlayan son centroid'lerle bir K-by-D dizisi başlatır.
Varsayılan olarak, modül K kümelerine ilk K veri noktalarını atar.
İlk K centroid kümesinden başlayarak yöntem, centroidlerin konumlarını yinelemeli olarak daraltmak için Lloyd algoritmasını kullanır.
Algoritma, merkez merkezler sabitlendiğinde veya belirtilen sayıda yineleme tamamlandığında sonlandırılır.
Her veri noktasını en yakın kütle merkezine sahip kümeye atamak için bir benzerlik ölçümü (varsayılan olarak Öklid uzaklığı) kullanılır.
Uyarı
- Kümeleme Modelini Eğitmek için bir parametre aralığı geçirirseniz, parametre aralığı listesindeki yalnızca ilk değeri kullanır.
- Kümelemeyi Süpür modülüne tek bir parametre değeri kümesi geçirirseniz, her parametre için bir dizi ayar beklediğinde değerleri yoksayar ve öğrenci için varsayılan değerleri kullanır.
- Parametre Aralığı seçeneğini belirleyip herhangi bir parametre için tek bir değer girerseniz, diğer parametreler bir değer aralığında değişse bile belirttiğiniz tek değer süpürme boyunca kullanılır.
Modül parametreleri
| Name | Aralık | Tür | Varsayılan | Açıklama |
|---|---|---|---|---|
| Centroid sayısı | >=2 | Tamsayı | 2 | Centroid sayısı |
| Ölçüm | Liste (alt küme) | Ölçüm | Öklid | Seçili ölçüm |
| Başlatma | Liste | Centroid başlatma yöntemi | K-Means++ | Başlatma algoritması |
| Yinelemeler | >=1 | Tamsayı | 100 | Yineleme sayısı |
Çıkışlar
| Ad | Tür | Description |
|---|---|---|
| Eğitilmemiş model | ICluster arabirimi | Eğitilmemiş K-Ortalamalar kümeleme modeli |
Özel durumlar
Tüm özel durumların listesi için bkz . Machine Learning Modülü Hata Kodları.
| Özel durum | Description |
|---|---|
| Hata 0003 | Bir veya daha fazla giriş null veya boşsa özel durum oluşur. |
Ayrıca bkz.
Kümeleme
Kümelere Veri Atama
Kümeleme Modelini Eğitme
Kümelemeye Süpür