Bulutta yerel veri desenleri
İpucu
Bu içerik, .NET Docs'ta veya çevrimdışı olarak okunabilen ücretsiz indirilebilir bir PDF olarak sağlanan Azure için Buluta Özel .NET Uygulamaları Tasarlama adlı e-Kitap'tan bir alıntıdır.

Bu kitapta gördüğümüz gibi buluta özel bir yaklaşım, uygulamaları tasarlama, dağıtma ve yönetme yönteminizi değiştiriyor. Ayrıca verileri yönetme ve depolama şeklinizi de değiştirir.
Şekil 5-1 arasındaki farklar karşıttır.
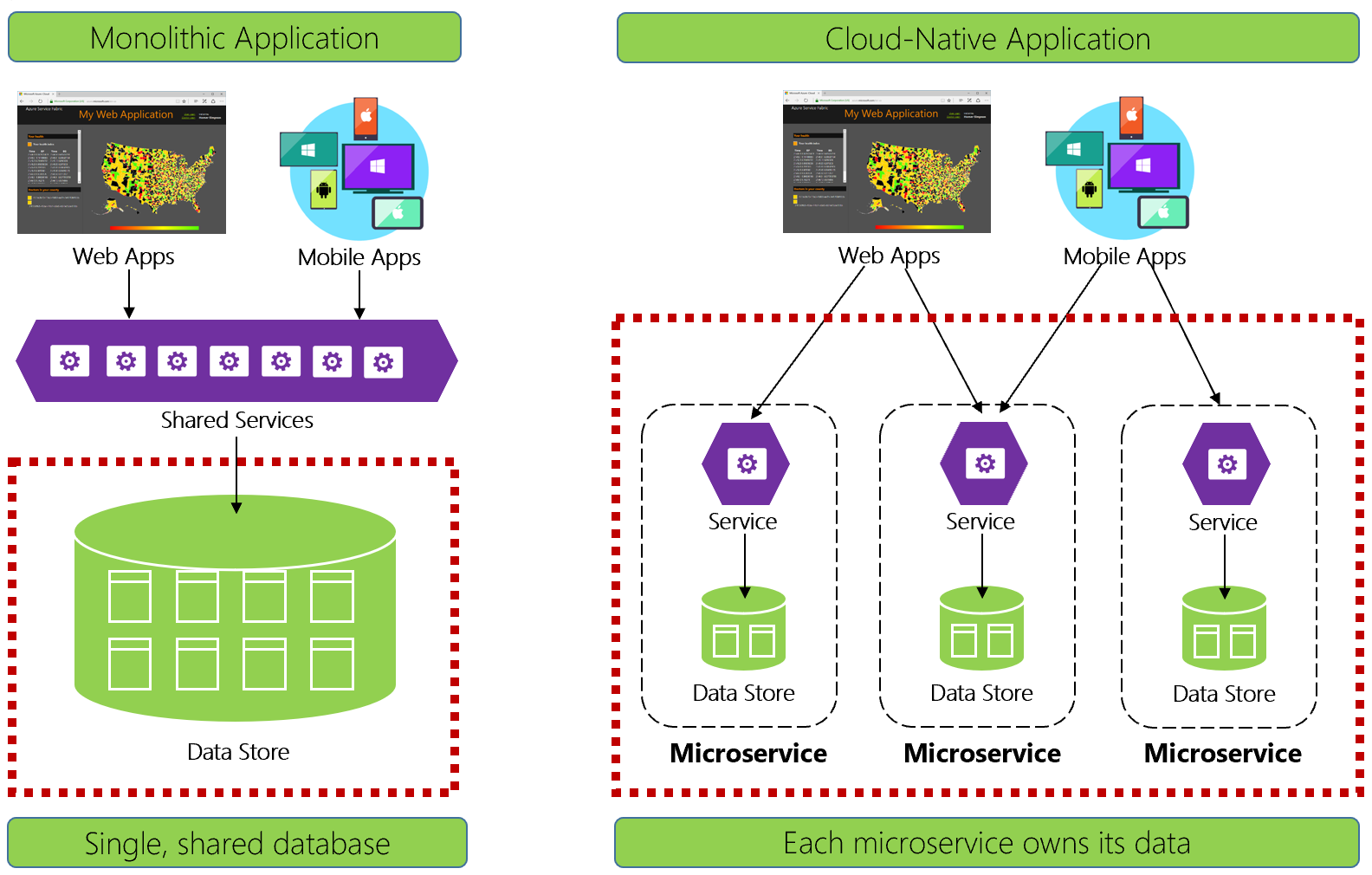
Şekil 5-1. Bulutta yerel uygulamalarda veri yönetimi
Deneyimli geliştiriciler, şekil 5-1'in sol tarafındaki mimariyi kolayca tanıyacak. Bu monolitik uygulamada, iş hizmeti bileşenleri paylaşılan hizmetler katmanında birlikte bir araya geliyor ve tek bir ilişkisel veritabanından veri paylaşıyor.
Birçok yönden, tek bir veritabanı veri yönetimini basit tutar. Verileri birden çok tablo arasında sorgulamak kolaydır. Verilerde yapılan değişiklikler birlikte güncelleştirilir veya hepsi geri alınır. ACID işlemleri güçlü ve anında tutarlılığı garanti eder .
Bulutta yerel olarak tasarlarken farklı bir yaklaşım benimsiyoruz. Şekil 5-1'in sağ tarafında, iş işlevlerinin küçük, bağımsız mikro hizmetlere nasıl ayrılmış olduğunu unutmayın. Her mikro hizmet belirli bir iş özelliğini ve kendi verilerini kapsüller. Monolitik veritabanı, her birinin mikro hizmetle uyumlu olduğu çok daha küçük veritabanlarıyla dağıtılmış bir veri modeline ayrılır. Duman temizlendiğinde, mikro hizmet başına bir veritabanını kullanıma sunan bir tasarımla ortaya çıkıyoruz.
Mikro hizmet başına veritabanı, neden?
Mikro hizmet başına bu veritabanı, özellikle hızlı bir şekilde gelişmesi ve büyük ölçeği desteklemesi gereken sistemler için birçok avantaj sağlar. Bu modelle...
- Etki alanı verileri hizmet içinde kapsüllenmiş
- Veri şeması diğer hizmetleri doğrudan etkilemeden gelişebilir
- Her veri deposu bağımsız olarak ölçeklendirilebilir
- Bir hizmetteki veri deposu hatası diğer hizmetleri doğrudan etkilemez
Verileri ayrıştırmak, her mikro hizmetin iş yükü, depolama gereksinimleri ve okuma/yazma desenleri için en iyi duruma getirilmiş veri deposu türünü uygulamasına da olanak tanır. Seçenekler arasında ilişkisel, belge, anahtar-değer ve hatta graf tabanlı veri depoları bulunur.
Şekil 5-2, bulutta yerel bir sistemde çok yönlü kalıcılık ilkesini gösterir.
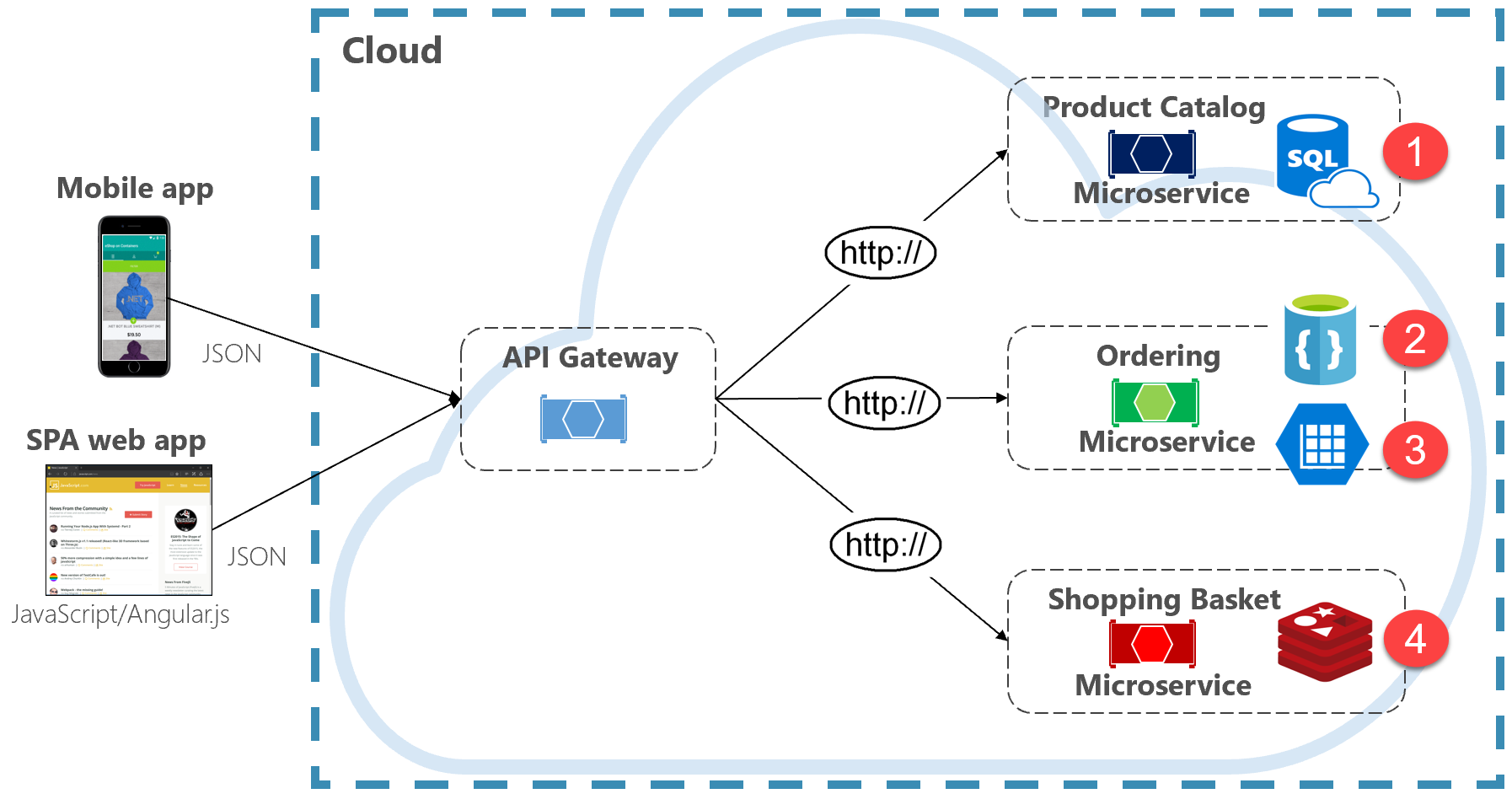
Şekil 5-2. Çok teknolojili veri kalıcılığı
Önceki şekilde, her mikro hizmetin farklı bir veri deposu türünü nasıl desteklediğine dikkat edin.
- Ürün kataloğu mikro hizmeti, temel alınan verilerin zengin ilişkisel yapısını barındırmak için ilişkisel bir veritabanı kullanır.
- Alışveriş sepeti mikro hizmeti, basit, anahtar-değer veri deposunu destekleyen dağıtılmış bir önbellek tüketir.
- Sipariş mikro hizmeti, yüksek hacimli okuma işlemlerini karşılamak için hem yazma işlemleri için bir NoSql belge veritabanını hem de yüksek oranda normalleştirilmiş anahtar/değer deposu kullanır.
İlişkisel veritabanları karmaşık verilerle mikro hizmetler için uygun olmaya devam ederken, NoSQL veritabanları önemli ölçüde popülerlik kazanmıştır. Bunlar yüksek ölçek ve yüksek kullanılabilirlik sağlar. Bunların şemasız yapısı, geliştiricilerin değişikliği pahalı ve zaman alan türemiş veri sınıfları ve ORM'lerden oluşan bir mimariden uzaklaşmasını sağlar. Bu bölümün devamında NoSQL veritabanlarını ele alacağız.
Verileri ayrı mikro hizmetler halinde kapsüllemek çevikliği, performansı ve ölçeklenebilirliği artırabilirken, birçok zorluk da sunar. Sonraki bölümde, bu zorlukların üstesinden gelmeye yardımcı olacak desenler ve uygulamalarla birlikte ele aacağız.
Hizmetler arası sorgular
Mikro hizmetler bağımsızdır ve envanter, sevkiyat veya sipariş gibi belirli işlevsel özelliklere odaklanırken, sıklıkla diğer mikro hizmetlerle tümleştirme gerektirir. Tümleştirme genellikle bir mikro hizmetin veri için başka bir mikro hizmet sorgulamasını içerir. Şekil 5-3'de senaryo gösterilmektedir.
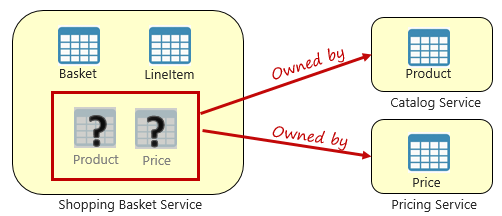
Şekil 5-3. Mikro hizmetler arasında sorgulama
Yukarıdaki şekilde, kullanıcının alışveriş sepetine öğe ekleyen bir alışveriş sepeti mikro hizmeti görüyoruz. Bu mikro hizmetin veri deposunda sepet ve satır öğesi verileri olsa da ürün veya fiyatlandırma verilerini korumaz. Bunun yerine, bu veri öğeleri kataloğa ve fiyatlandırma mikro hizmetlerine aittir. Bu özellik bir sorun oluşturur. Alışveriş sepeti mikro hizmeti, veritabanında ürün veya fiyatlandırma verileri olmadığında kullanıcının alışveriş sepetine nasıl ürün ekleyebilir?
Bölüm 4'te ele alınan seçeneklerden biri, alışveriş sepetinden kataloğa doğrudan HTTP çağrısı ve fiyatlandırma mikro hizmetleridir. Ancak 4. bölümde, zaman uyumlu HTTP çağrılarının mikro hizmetleri birbirine bağlayarak özerkliklerini azalttıklarını ve mimari yararlarını azalttıklarını söyledik.
Ayrıca her hizmet için ayrı gelen ve giden kuyrukları olan bir istek-yanıt deseni de uygulayabiliriz. Ancak, bu düzen karmaşıktır ve istek ve yanıt iletilerini ilişkilendirmek için tesisat gerektirir. Arka uç mikro hizmet çağrılarını ayrıştırsa da, çağrı hizmetinin hala zaman uyumlu bir şekilde çağrının tamamlanmasını beklemesi gerekir. Ağ tıkanıklığı, geçici hatalar veya aşırı yüklenmiş bir mikro hizmet, uzun süre çalışan ve hatta başarısız işlemlere neden olabilir.
Bunun yerine, hizmetler arası bağımlılıkları kaldırmak için yaygın olarak kabul edilen bir desen, Şekil 5-4'te gösterilen Gerçekleştirilmiş Görünüm Deseni'dir.
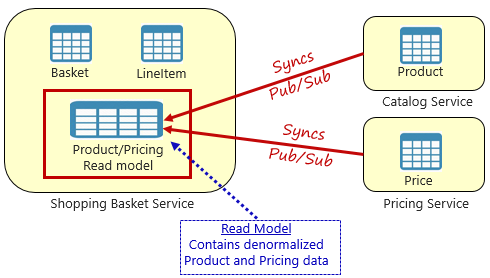
Şekil 5-4. Gerçekleştirilmiş Görünüm Düzeni
Bu desenle, alışveriş sepeti hizmetine yerel bir veri tablosu (okuma modeli olarak bilinir) yerleştirirsiniz. Bu tablo, ürün ve fiyatlandırma mikro hizmetlerinden gereken verilerin normalleştirilmiş bir kopyasını içerir. Verileri doğrudan alışveriş sepeti mikro hizmetine kopyalamak, pahalı hizmetler arası arama ihtiyacını ortadan kaldırır. Yerel hizmet verileriyle hizmetin yanıt süresini ve güvenilirliğini geliştirirsiniz. Ayrıca, verilerin kendi kopyasına sahip olmak, alışveriş sepeti hizmetini daha dayanıklı hale getirir. Katalog hizmeti kullanılamaz duruma gelirse, alışveriş sepeti hizmetini doğrudan etkilemez. Alışveriş sepeti, kendi mağazasındaki verilerle çalışmaya devam edebilir.
Bu yaklaşımın yakalaması, artık sisteminizde yinelenen verilere sahip olmanızdır. Ancak, verileri buluta özel sistemlerde stratejik olarak çoğaltmak yerleşik bir uygulamadır ve desen karşıtı veya kötü bir uygulama olarak kabul edilmez. Bir ve yalnızca bir hizmetin bir veri kümesine sahip olabileceğini ve bu veri kümesi üzerinde yetki sahibi olabileceğini unutmayın. Kayıt sistemi güncelleştirildiğinde okuma modellerini eşitlemeniz gerekir. Eşitleme genellikle Şekil 5.4'te gösterildiği gibi yayımlama/abone olma deseniyle zaman uyumsuz mesajlaşma yoluyla uygulanır.
Dağıtılmış işlemler
Mikro hizmetler arasında verileri sorgulamak zor olsa da, birkaç mikro hizmette işlem uygulamak daha da karmaşıktır. Farklı mikro hizmetlerde bağımsız veri kaynakları arasında veri tutarlılığını korumanın doğası gereği zorluğu fazla abartılamaz. Bulutta yerel uygulamalarda dağıtılmış işlemlerin olmaması, dağıtılmış işlemleri program aracılığıyla yönetmeniz gerektiği anlamına gelir. Anında tutarlılık dünyasından nihai tutarlılığa geçersiniz.
Şekil 5-5'de sorun gösterilmektedir.
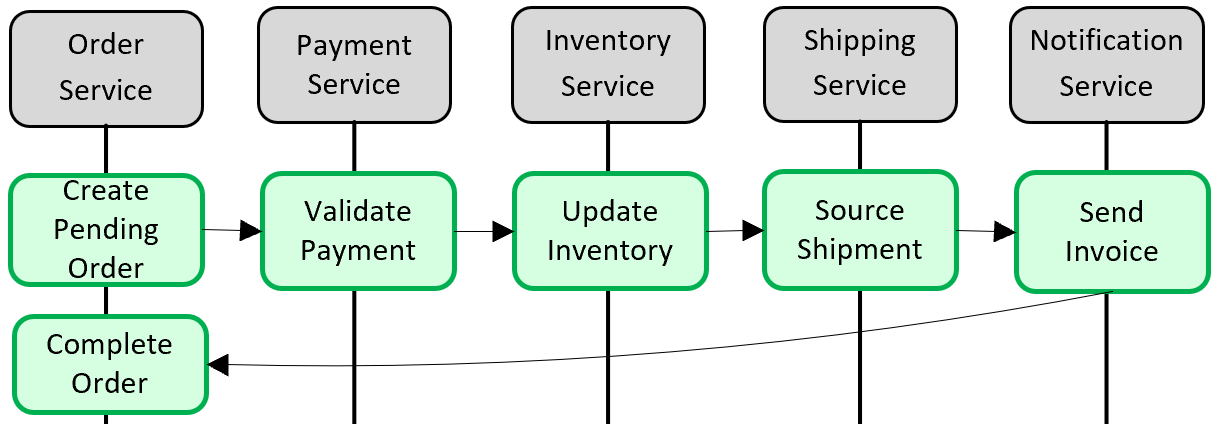
Şekil 5-5. Mikro hizmetler arasında işlem uygulama
Yukarıdaki şekilde, beş bağımsız mikro hizmet sipariş oluşturan dağıtılmış bir işleme katılır. Her mikro hizmet kendi veri deposunu tutar ve deposu için yerel bir işlem uygular. Siparişi oluşturmak için, her bir mikro hizmet için yerel işlemin başarılı olması veya tümünün işlemi durdurup geri alması gerekir. Mikro hizmetlerin her birinde yerleşik işlem desteği olsa da, verilerin tutarlı olmasını sağlamak için beş hizmete de yayılacak dağıtılmış işlem desteği yoktur.
Bunun yerine, bu dağıtılmış işlemi program aracılığıyla oluşturmanız gerekir.
Dağıtılmış işlem desteği eklemek için popüler bir desen Saga desenidir. Yerel işlemleri program aracılığıyla birlikte gruplandırarak ve her birini sırayla çağırarak uygulanır. Yerel işlemlerden herhangi biri başarısız olursa, Saga işlemi durdurur ve bir telafi işlemleri kümesi çağırır. Telafi işlemleri, önceki yerel işlemler tarafından yapılan değişiklikleri geri alır ve veri tutarlılığını geri yükler. Şekil 5-6'da Saga deseniyle başarısız olan bir işlem gösterilmektedir.
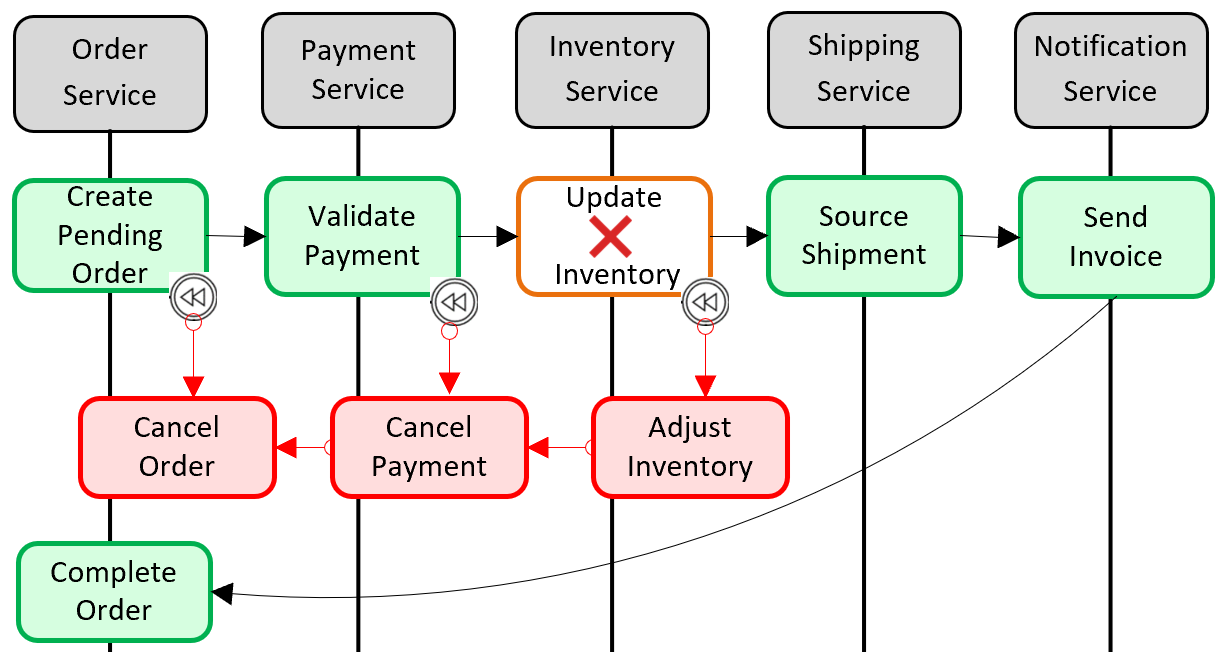
Şekil 5-6. bir işlemi geri döndürme
Önceki şekilde Stok Mikro Hizmeti'nde Envanteri Güncelleştir işlemi başarısız oldu. Saga, envanter sayılarını ayarlamak, ödemeyi ve siparişi iptal etmek ve her mikro hizmetin verilerini tutarlı bir duruma geri döndürmek için bir telafi işlemleri (kırmızı) kümesi çağırır.
Saga desenleri genellikle bir dizi ilgili olay olarak koreografik veya bir dizi ilgili komut olarak düzenlenir. 4. Bölümde, bir destan uygulamasının temelini oluşturacak hizmet toplayıcı desenini ele aldık. Ayrıca, koreografik bir destan uygulaması için temel oluşturacak Azure Service Bus ve Azure Event Grid konularının yanı sıra olaylama konularını da ele aldık.
Yüksek hacimli veriler
Buluta özel büyük uygulamalar genellikle yüksek hacimli veri gereksinimlerini destekler. Bu senaryolarda geleneksel veri depolama teknikleri performans sorunlarına neden olabilir. Büyük ölçekte dağıtan karmaşık sistemler için hem Komut hem de Sorgu Sorumluluğu Ayrım (CQRS) ve Olay Kaynağını Belirleme uygulama performansını artırabilir.
CQRS
CQRS, performansı, ölçeklenebilirliği ve güvenliği en üst düzeye çıkarmaya yardımcı olabilecek bir mimari desendir. Desen, verileri okuyan işlemleri veri yazan işlemlerden ayırır.
Normal senaryolarda, hem okuma hem de yazma işlemleri için aynı varlık modeli ve veri deposu nesnesi kullanılır.
Ancak yüksek hacimli bir veri senaryosu, okuma ve yazma işlemleri için ayrı modellerden ve veri tablolarından yararlanabilir. Performansı artırmak için okuma işlemi, pahalı yinelenen tablo birleşimlerini ve tablo kilitlerini önlemek için verilerin yüksek oranda normalleştirilmiş gösterimine karşı sorgu yapabilir. Komut olarak bilinen yazma işlemi, tutarlılığı garanti edecek verilerin tamamen normalleştirilmiş bir gösterimine karşı güncelleştirilir. Ardından her iki gösterimi de eşitlenmiş durumda tutmak için bir mekanizma uygulamanız gerekir. Genellikle, yazma tablosu her değiştirildiğinde, değişiklikleri okuma tablosuna çoğaltan bir olay yayımlar.
Şekil 5-7'de CQRS deseninin bir uygulaması gösterilmektedir.
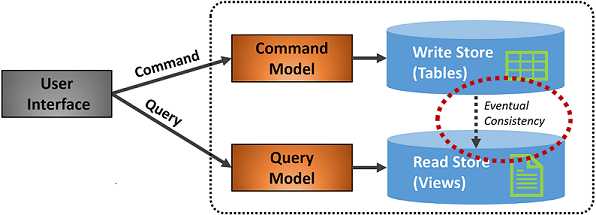
Şekil 5-7. CQRS uygulaması
Önceki şekilde, ayrı komut ve sorgu modelleri uygulanır. Her veri yazma işlemi yazma deposuna kaydedilir ve ardından okuma deposuna yayılır. Veri yayma işleminin nihai tutarlılık ilkesine göre nasıl çalıştığına çok dikkat edin. Okuma modeli sonunda yazma modeliyle eşitlenir, ancak işlemde bazı gecikmeler olabilir. Sonraki bölümde nihai tutarlılığı ele aacağız.
Bu ayrım, okuma ve yazmaların bağımsız olarak ölçeklendirilmesini sağlar. Okuma işlemleri sorgular için iyileştirilmiş bir şema kullanırken, yazma işlemleri güncelleştirmeler için iyileştirilmiş bir şema kullanır. Okuma sorguları normalleştirilmiş verilere karşı kullanılırken yazma modeline karmaşık iş mantığı uygulanabilir. Ayrıca, yazma işlemlerine okumaları ortaya koyanlardan daha sıkı güvenlik uygulayabilirsiniz.
CQRS'nin uygulanması, bulutta yerel hizmetler için uygulama performansını geliştirebilir. Ancak, daha karmaşık bir tasarıma neden olur. Bu ilkeyi, buluta özel uygulamanızın bundan yararlanacak bölümlerine dikkatli ve stratejik bir şekilde uygulayın. CQRS hakkında daha fazla bilgi için bkz. .NET Microservices: Architecture for Containerized .NET Applications (Kapsayıcılı .NET Uygulamaları için Mimari) adlı Microsoft kitabı.
Olay kaynağını belirleme
Yüksek hacimli veri senaryolarını iyileştirmeye yönelik bir diğer yaklaşım da Olay Kaynağını Belirleme'yi içerir.
Sistem genellikle bir veri varlığının geçerli durumunu depolar. Örneğin bir kullanıcı telefon numarasını değiştirirse, müşteri kaydı yeni numarayla güncelleştirilir. Bir veri varlığının geçerli durumunu her zaman biliyoruz, ancak her güncelleştirme önceki durumun üzerine yazar.
Çoğu durumda bu model düzgün çalışır. Ancak yüksek hacimli sistemlerde işlem kilitleme ve sık güncelleştirme işlemlerinin ek yükü veritabanı performansını, yanıt hızını ve ölçeklenebilirliği sınırlayabilir.
Olay Kaynağını Belirleme, verileri yakalamak için farklı bir yaklaşım benimser. Verileri etkileyen her işlem bir olay deposunda kalıcı hale gelir. Veri kaydının durumunu güncelleştirmek yerine, her değişikliği bir muhasebecinin kayıt defterine benzer şekilde geçmiş olayların sıralı listesine ekleriz. Olay Deposu, verilerin kayıt sistemi haline gelir. Mikro hizmetin sınırlanmış bağlamında çeşitli gerçekleştirilmiş görünümleri yaymak için kullanılır. Şekil 5.8'de desen gösterilmektedir.
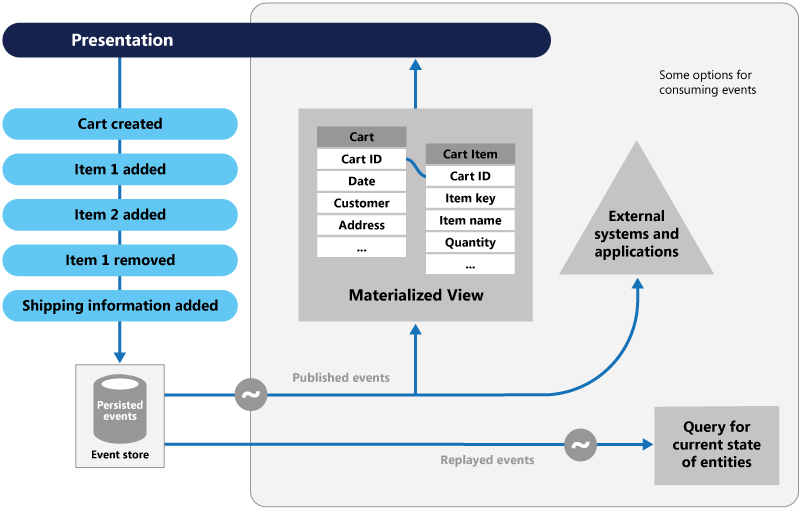
Şekil 5-8. Olay Kaynağını Belirleme
Önceki şekilde, kullanıcının alışveriş sepetine ait her girişin (mavi) temel alınan bir olay deposuna nasıl eklendiğine dikkat edin. Bitişik gerçekleştirilmiş görünümde sistem, her alışveriş sepetiyle ilişkili tüm olayları yeniden yürüterek geçerli durumu projeler. Bu görünüm veya okuma modeli daha sonra kullanıcı arabirimine geri sunulur. Olaylar dış sistem ve uygulamalarla tümleştirilebilir veya varlığın geçerli durumunu belirlemek için sorgulanabilir. Bu yaklaşımla geçmişi korursunuz. Bir varlığın yalnızca geçerli durumunu değil, aynı zamanda bu duruma nasıl ulaştığınızı da biliyorsunuz.
Mekanik olarak bakıldığında, olay kaynağını belirleme yazma modelini basitleştirir. Güncelleştirme veya silme yok. Her veri girişini sabit bir olay olarak eklemek ilişkisel veritabanlarıyla ilişkili çekişme, kilitleme ve eşzamanlılık çakışmalarını en aza indirir. Gerçekleştirilmiş görünüm deseniyle okuma modelleri oluşturmak, görünümü yazma modelinden ayırmanıza ve uygulama kullanıcı arabiriminizin gereksinimlerini iyileştirmek için en iyi veri deposunu seçmenize olanak tanır.
Bu düzen için olay kaynağını doğrudan destekleyen bir veri deposu düşünün. Azure Cosmos DB, MongoDB, Cassandra, CouchDB ve RavenDB iyi adaylardır.
Tüm desenlerde ve teknolojilerde olduğu gibi, stratejik olarak ve gerektiğinde uygulayın. Olay kaynağını belirleme daha yüksek performans ve ölçeklenebilirlik sağlasa da, karmaşıklık ve öğrenme eğrisi maliyetinden kaynaklanabilir.
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin