解决方案构想
本文是一种解决方案构想。 如果你希望我们在内容中扩充更多信息,例如潜在用例、备用服务、实现注意事项或定价指南,请通过提供 GitHub 反馈来告知我们。
本文为实现指南和示例方案,提供“实现自定义语音转文本”中所述的解决方案的示例部署:
体系结构
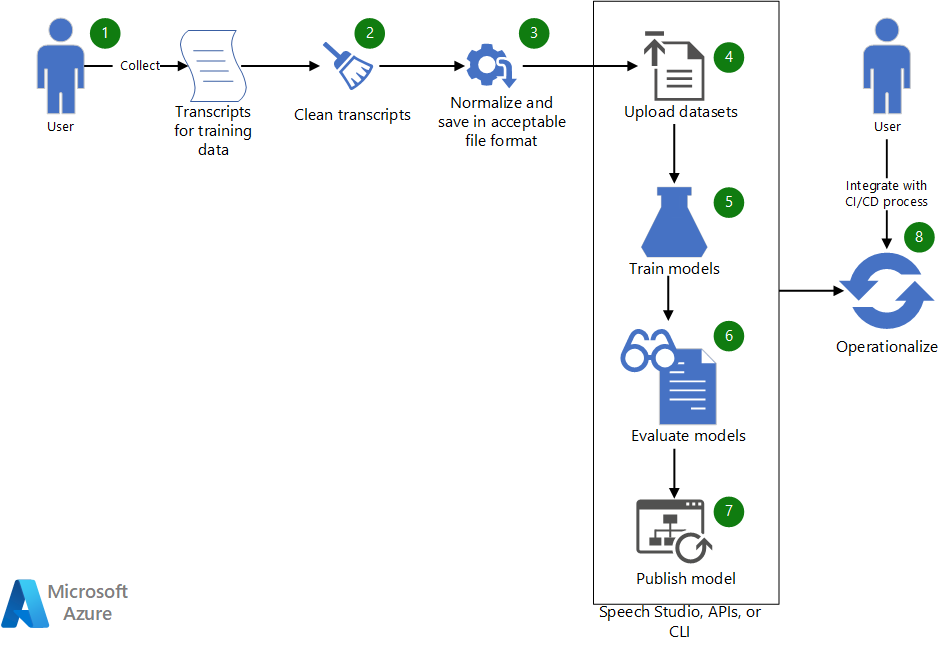
下载此体系结构的 Visio 文件。
工作流
- 收集现有听录用于训练自定义语音模型。
- 如果听录采用 WebVTT 或 SRT 格式,请清理文件,使其仅包含听录的文本部分。
- 通过删除任何标点符号、分隔重复字词并对任何较大的数值进行拼写处理来规范化文本。 可以将多个已清理的听录合并为一个听录,以创建一个数据集。 采用相似方式创建用于测试的数据集。
- 数据集准备就绪后,使用 Speech Studio 上传它们。 或者,如果数据集位于 Blob 存储中,则可以使用 Azure 语音转文本 (STT) API 和语音 CLI。 在 API 和 CLI 中,可以向数据集的 URI 传递输入,以创建用于模型训练和测试的数据集。
- 在 Speech Studio 中或通过 API 或 CLI,使用新数据集来训练自定义语音模型。
- 根据测试数据集评估新训练的模型。
- 如果自定义模型的性能符合质量预期,请发布该模型用于语音听录。 否则,使用 Speech Studio 查看字词错误率 (WER) 和特定错误详细信息,并确定训练需要哪些其他数据。
- 使用 API 和 CLI 帮助实施模型生成、评估和部署过程。
组件
- Azure 机器学习是用于端到端机器学习生命周期的企业级服务。
- Azure AI 服务是一系列 API、SDK 和服务,有助于让应用程序更加智能、更具吸引力和更易被发现。
- Speech Studio 是一系列基于 UI 的工具,用于生成 Azure AI 语音服务中的功能并将它们集成到应用程序中。 在这里,它是训练数据集的一种替代方法。 它还用于查看训练结果。
- 语音转文本 REST API 是一个 API,可用于上传自己的数据、测试和训练自定义模型、比较不同模型的准确度,以及将模型部署到自定义终结点。 还可以使用它来实施模型创建、评估和部署。
- 语音 CLI 是一种命令行工具,用于在不编写任何代码的情况下使用语音服务。 它为创建和训练数据集以及实施流程提供了另一种替代方法。
方案详细信息
本文基于以下虚构方案:
Contoso, Ltd. 是一家广播媒体公司,对奥运会赛事进行播报和解说。 在广播协议中,Contoso 为辅助功能和数据挖掘提供赛事听录。
Contoso 希望使用 Azure 语音服务为奥运会赛事提供实时字幕和音频听录。 Contoso 聘请了来自世界各地有着不同腔调的女性和男性解说员。 此外,每项运动都有特定的术语,可能会使听录变得困难。 本文介绍此方案的应用程序开发过程:为需要提供准确赛事听录的应用程序提供字幕。
Contoso 已具备以下必备组件:
- 历届奥运赛事的人工生成听录。 听录代表不同运动以及不同解说员的解说。
- Azure 认知服务资源。 可以在 Azure 门户创建一个。
开发基于语音的自定义应用程序
基于语音的应用程序使用 Azure 语音 SDK 连接到 Azure 语音服务,以生成基于文本的音频听录。 语音服务支持各种语言和两种流畅模式:对话和听写。 若要开发基于语音的自定义应用程序,通常需要完成以下步骤:
- 使用 Speech Studio、Azure 语音 SDK、语音 CLI 或 REST API 为口述话语和语句生成听录。
- 将生成的听录与人工生成听录进行比较。
- 如果某些域特定的字词听录错误,请考虑为该特定域创建自定义语音模型。
- 查看用于创建自定义模型的各种选项。 确定是一个还是多个自定义模型更加适合。
- 收集训练和测试数据。
- 确保数据采用可接受的格式。
- 训练、测试和评估以及部署模型。
- 使用自定义模型进行听录。
- 实施模型生成、评估和部署过程。
让我们进一步研究一下这些步骤:
1. 使用 Speech Studio、Azure 语音 SDK、语音 CLI 或 REST API 为口述语句和话语生成听录
Azure 语音提供 SDK、CLI 接口和 REST API,用于从音频文件或直接从麦克风输入生成听录。 如果内容位于音频文件中,则需要采用受支持的格式。 在此方案中,Contoso 在 .avi 文件中有以前的赛事记录(音频和视频)。 Contoso 可以使用 FFmpeg 等工具从视频文件中提取音频,并将其保存为 Azure 语音 SDK 支持的格式(如 .wav)。
在以下代码中,标准 PCM 音频编解码器 pcm_s16le 用于提取采样率为 8 千赫兹 (Khz) 的单声道音频。
ffmpeg.exe -i INPUT_FILE.avi -acodec pcm_s16le -ac 1 -ar 8000 OUTPUT_FILE.wav
2. 将生成的听录与人工生成的听录进行比较
为执行比较,Contoso 会对多项运动的解说音频进行采样,并使用 Speech Studio 将人工生成的听录与 Azure 语音服务听录的结果进行比较。 Contoso 人工生成的听录采用 WebVTT 格式。 为了使用这些听录,Contoso 会对其进行清理,并生成一个简单的 .txt 文件,该文件具有规范化文本,没有时间戳信息。
有关使用 Speech Studio 来创建和评估数据集的信息,请参阅训练和测试数据集。
Speech Studio 提供了对人工生成的听录和选择用于比较的模型所生成的听录的并排比较。 测试结果包括模型的 WER,如下所示:
| 建模 | 错误率 | 插入 | 替换 | 删除 |
|---|---|---|---|---|
| 模型 1:20211030 | 14.69% | 6 (2.84%) | 22 (10.43%) | 3 (1.42%) |
| 模型 2:Olympics_Skiing_v6 | 6.16% | 3 (1.42%) | 8 (3.79%) | 2 (0.95%) |
有关 WER 的详细信息,请参阅评估字词错误率。
根据这些结果,自定义模型 (Olympics_Skiing_v6) 优于数据集的基础模型 (20211030)。
请注意“插入率”和“删除率”,这表明音频文件相对干净且背景噪音较低。
3. 如果某些域特定的字词听录错误,请考虑为该特定域创建自定义语音模型
根据上表中的结果,对于基础模型“模型 1:20211030”,大约有 10% 的字词被替换。 在 Speech Studio 中,使用详细的比较功能来识别遗漏的域特定字词。 下表显示了比较的一个部分。
| 人工生成的听录 | 模型 1 | 模型 2 |
|---|---|---|
| olympic champion to go back to back in the downhill since nineteen ninety eight the great katja seizinger of Germany what ninety four and ninety eight | olympic champion to go back to back in the downhill since nineteen ninety eight the great catch a sizing are of Germany what ninety four and ninety eight | olympic champion to go back to back in the downhill since nineteen ninety eight the great katja seizinger of Germany what ninety four and ninety eight |
| 她打败了奥运冠军 goggia | 她打败了奥运冠军 georgia | 她打败了奥运冠军 goggia |
模型 1 无法识别域特定的字词,如运动员的名字“Katia Seizinger”和“Goggia”。但是,当自定义模型使用包含运动员姓名和其他域特定的字词和短语的数据进行训练时,它能够学习和识别它们。
4. 查看用于创建自定义模型的各种选项。 确定是一个还是多个自定义模型更加适合
通过试验各种方法来生成自定义模型,Contoso 发现它们可以通过使用语言和发音模型自定义来提高准确性。 (请参阅本指南中的第一篇文章。)Contoso 还注意到在包含用于生成自定义模型的声学(原始音频)数据时的细微改进。 但是,这些优势还不够显著,并不值得对自定义声学模型进行维护和训练。
Contoso 发现,为每项运动创建单独的自定义语言模型(一种模型用于高山滑雪、一种模型用于无舵雪橇、一种模型用于单板滑雪等)可提供更好的识别结果。 他们还指出,没有必要根据运动类型创建单独的声学模型来增强语言模型。
5. 收集训练结果和测试数据
训练和测试数据集一文详细介绍了如何收集训练自定义模型所需的数据。 Contoso 从不同的解说员那里收集了各种奥运运动的听录,并使用语言模型适应为每个运动类型生成一个模型。 但是,他们为所有自定义模型都使用一个发音文件(每项运动一个)。 由于测试数据和训练数据是分开的,因此在生成自定义模型后,Contoso 使用其听录未包含在训练数据集中的赛事音频进行模型评估。
6. 确保数据采用可接受的格式
如训练和测试数据集中所述,用于创建自定义模型或测试模型的数据集需要采用特定格式。 Contoso 的数据位于 WebVTT 文件中。 他们创建了一些简单的工具来生成文本文件,其中包含用于语言模型适应的规范化文本。
7. 训练、测试和评估以及部署模型
新的赛事记录用于进一步测试和评估经过训练的模型。 可能需要进行多次测试和评估才能优化调整模型。 最后,当模型生成的听录的错误率在可接受范围时,将进行部署(发布)以供 SDK 使用。
8. 使用自定义模型进行听录
部署自定义模型后,可以通过以下 C# 代码在 SDK 中使用该模型进行听录:
String endpoint = "Endpoint ID from Speech Studio";
string locale = "en-US";
SpeechConfig config = SpeechConfig.FromSubscription(subscriptionKey: speechKey, region: region);
SourceLanguageConfig sourceLanguageConfig = SourceLanguageConfig.FromLanguage(locale, endPoint);
recognizer = new SpeechRecognizer(config, sourceLanguageConfig, audioInput);
有关代码的说明:
endpoint是在步骤 7 中部署的自定义模型的终结点 ID。subscriptionKey和region是 Azure AI 服务订阅密钥和区域。 通过前往创建 Azure AI 服务资源的资源组并查看其密钥即可 Azure 门户获取这些值。
9. 实施模型生成、评估和部署过程
发布自定义模型后,需要定期评估该模型,并在添加新词汇时对其进行更新。 业务会不断发展,可能需要更多自定义模型来增加更多域的覆盖范围。 Azure 语音团队还会发布新的基础模型,这些模型会在可用时使用更多数据进行训练。 自动化可以帮助你及时了解这些更改的最新进展。 本文的下一部分提供了有关自动执行上述步骤的更多详细信息。
部署此方案
有关如何使用脚本来简化和自动化创建数据集的整个过程以便训练和测试、生成和评估模型以及根据需要发布新模型的信息,请参阅 GitHub 上的 Custom-speech-STT。
作者
本文由 Microsoft 维护, 它最初是由以下贡献者撰写的。
主要作者:
- Pratyush Mishra | 首席工程经理
其他参与者:
- Mick Alberts | 技术文档撰写人
- Rania Bayoumy | 高级技术项目经理
若要查看非公开的 LinkedIn 个人资料,请登录到 LinkedIn。