优化 Azure Data Lake Storage Gen1 以提高性能
Data Lake Storage Gen1 支持在高吞吐量情况下进行 I/O 密集型分析和数据移动。 在 Data Lake Storage Gen1 中,使用所有可用的吞吐量(每秒可读取或写入的数据量)对于获取最佳性能非常重要。 可通过尽可能多地执行并行读取和写入来实现这一点。
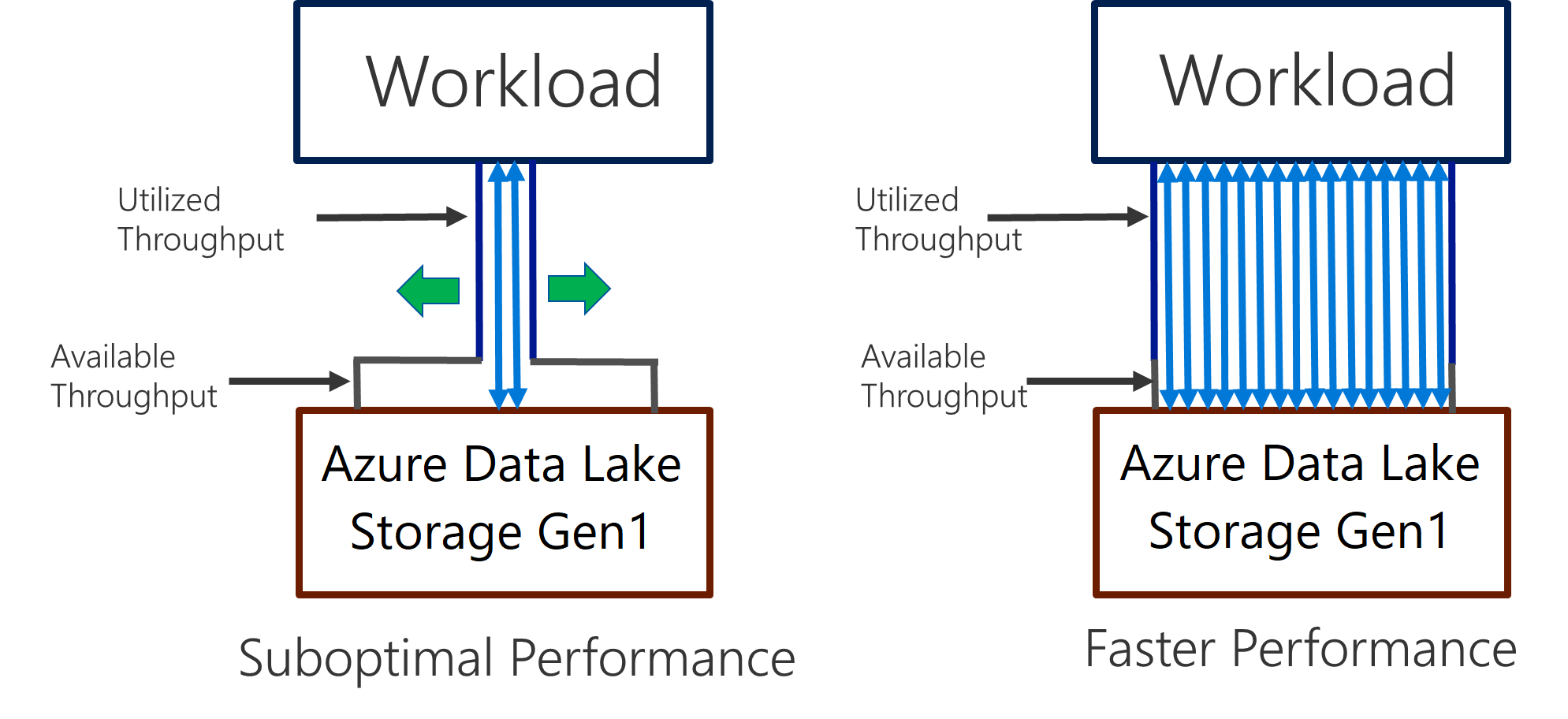
Data Lake Storage Gen1 可进行缩放,以便为所有分析方案提供必要的吞吐量。 默认情况下,Data Lake Storage Gen1 帐户自动提供足够的吞吐量来满足广泛用例的需求。 对于客户达到默认限制的情况,可联系 Microsoft 支持部门配置 Data Lake Storage Gen1 帐户,以获得更多吞吐量。
数据引入
在将数据从源系统引入 Data Lake Storage Gen1 时,源硬件、源网络硬件以及到 Data Lake Storage Gen1 的网络连接可能会成为瓶颈,请务必考虑到这一点。
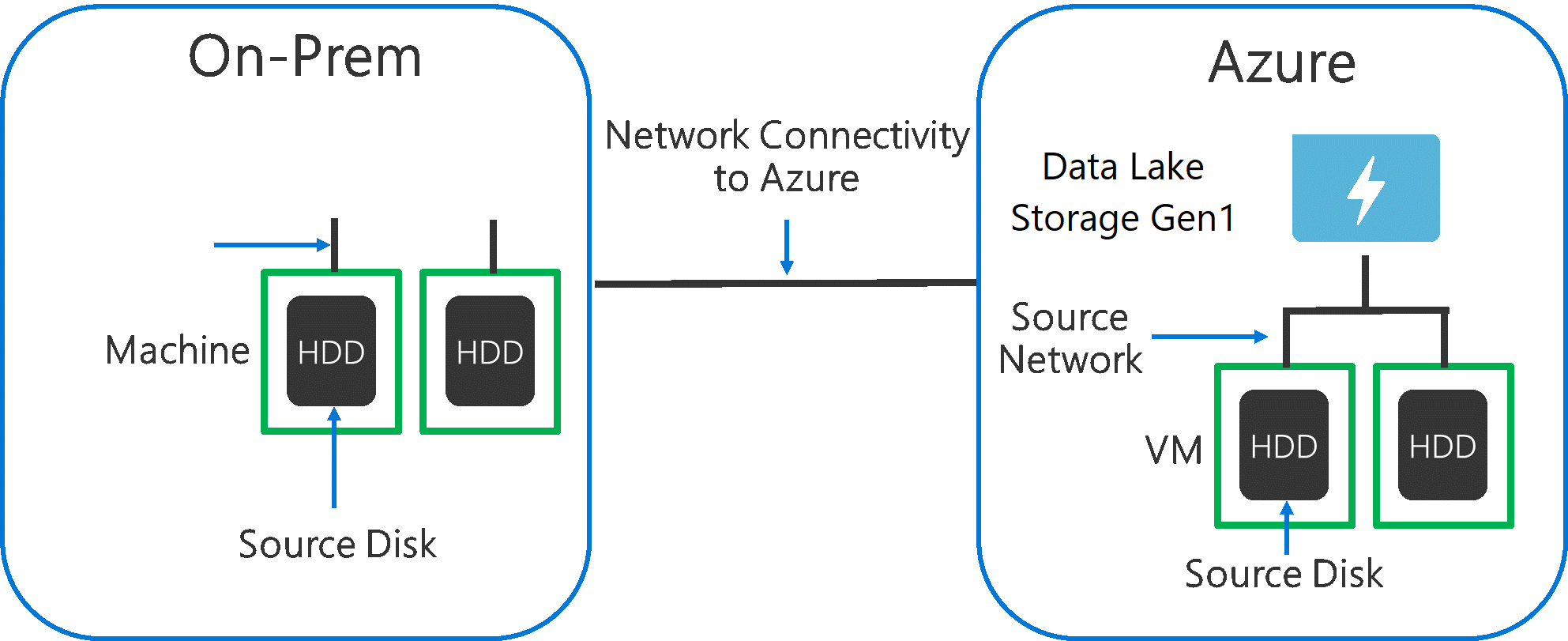
请务必确保这些因素不会影响数据移动。
源硬件
无论使用本地计算机还是 Azure 中的 VM,都应仔细选择合适的硬件。 对于源磁盘硬件,最好使用 SSD(而不是 HDD)并选取主轴转速更快的磁盘硬件。 对于源网络硬件,请尽可能使用最快的 NIC。 在 Azure 上,建议使用 Azure D14 VM,该虚拟机具有性能适当的磁盘和网络硬件。
到 Data Lake Storage Gen1 的网络连接
源数据和 Data Lake Storage Gen1 之间的网络连接有时可能成为瓶颈。 如果源数据位于本地,请考虑使用 Azure ExpressRoute 的专用链接。 如果源数据在 Azure 中,当数据与 Data Lake Storage Gen1 帐户位于同一 Azure 区域时,可获得最佳性能。
配置数据引入工具,实现最大并行化
在解决了源硬件和网络连接方面的瓶颈后,即可开始配置引入工具。 下表概述了几种常用引入工具的关键设置,并提供了关于这些工具的详尽性能优化文章。 若要深入了解方案应使用何种工具,请参阅这篇文章。
| 工具 | 设置 | 更多详细信息 |
|---|---|---|
| PowerShell | PerFileThreadCount、ConcurrentFileCount | 链接 |
| AdlCopy | Azure Data Lake Analytics 单元 | 链接 |
| DistCp | -m (mapper) | 链接 |
| Azure 数据工厂 | parallelCopies | 链接 |
| Sqoop | fs.azure.block.size, -m (mapper) | 链接 |
调整数据集结构
当数据存储在 Data Lake Storage Gen1 中时,文件大小、文件数量和文件夹结构都会影响性能。 以下部分介绍了这些方面的最佳做法。
文件大小
通常,HDInsight 和 Azure Data Lake Analytics 等分析引擎的每个文件都存在开销。 如果将数据存储为多个小文件,这可能会对性能产生负面影响。
通常可将数据组织到较大文件中,以获得更佳性能。 根据经验,请将数据集组织到 256 MB 或更大的文件中。 对于图像和二进制数据等情况,不能并行处理它们。 在这些情况下,建议将单个文件保持在 2GB 以下。
有时,数据管道对于包含大量小文件的原始数据的控制有限。 建议执行“烹调”过程来生成更大的文件,以供下游应用程序使用。
在文件夹中组织时序数据
对于 Hive 和 ADLA 工作负荷,对时序数据进行分区修剪会有助于某些查询只读取一部分数据,从而提高性能。
那些引入时序数据的管道在放置其文件时通常会以结构化方式命名文件和文件夹。 下面是数据按日期进行结构化组织的常见示例:\DataSet\YYYY\MM\DD\datafile_YYYY_MM_DD.tsv。
请注意,日期/时间信息同时显示为文件夹和文件名。
对于日期和时间,以下是常见模式:\DataSet\YYYY\MM\DD\HH\mm\datafile_YYYY_MM_DD_HH_mm.tsv。
同样,选择的文件夹和文件组织方式应针对更大的文件大小和每个文件夹中合理的文件数进行优化。
在 HDInsight 上优化 Hadoop 和 Spark 工作负荷中的 I/O 密集型作业
作业属于以下三个类别之一:
- CPU 密集型。 这些作业的计算时间长,I/O 时间最短。 例如,机器学习作业和自然语言处理作业。
- 内存密集型。 这些作业占用大量内存。 例如,PageRank 作业和实时分析作业。
- I/O 密集型。 这些作业大部分时间都在执行 I/O。 例如,只执行读取和写入操作的复制作业是很常见的。 其他示例包括数据准备作业,这些作业会读取大量数据,执行一些数据转换,然后将数据写回存储。
以下指南仅适用于 I/O 密集型作业。
HDInsight 群集的一般注意事项
- HDInsight 版本。 为获得最佳性能,请使用最新版 HDInsight。
- 区域。 将 Data Lake Storage Gen1 和 HDInsight 群集放置在同一区域。
HDInsight 群集由两个头节点和一些辅助角色节点组成。 每个辅助角色节点提供特定数量的核心和内存,具体取决于 VM 类型。 运行作业时,YARN 充当资源协商者,负责分配可用的内存和核心以创建容器。 每个容器运行完成作业所需的任务。 容器可并行运行以快速处理任务。 因此,通过并行运行尽可能多的容器可以提高性能。
可优化 HDInsight 群集中的以下 3 层,以增加容器数和使用所有可用的吞吐量。
- 物理层
- YARN 层
- 工作负荷层
物理层
运行具有更多节点和/或更大 VM 的群集。 更大的群集可运行更多 YARN 容器,如下图所示。

使用具有更多网络带宽的 VM。 如果网络带宽低于 Data Lake Storage Gen1 吞吐量,则网络带宽量可能成为瓶颈。 网络带宽大小因不同 VM 而异。 请选择具有可能的最大网络带宽的 VM 类型。
YARN 层
使用较小的 YARN 容器。 缩减每个 YARN 容器的大小,创建更多包含相同数量资源的容器。
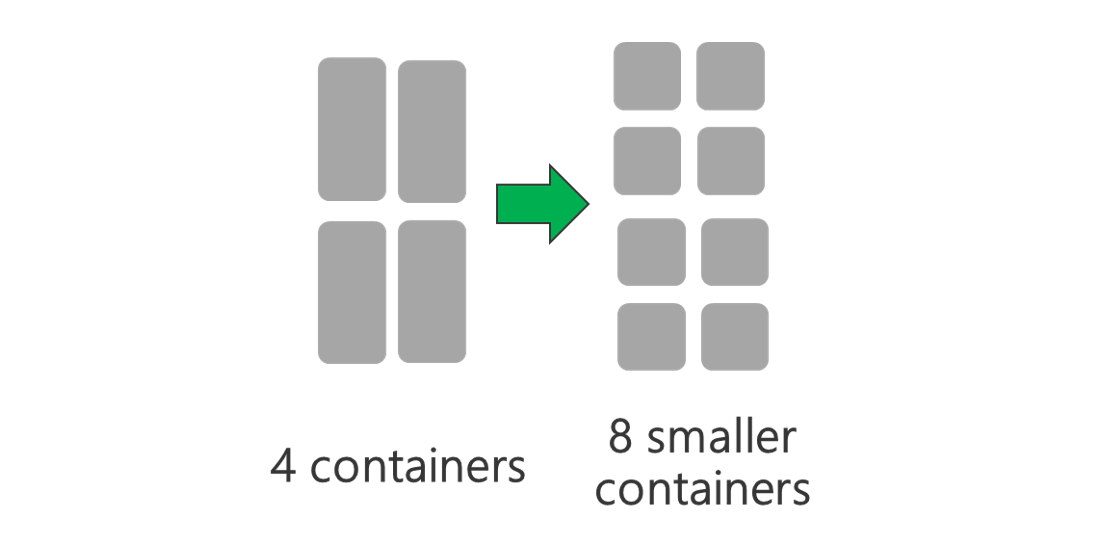
始终需要最小的 YARN 容器,具体取决于工作负荷。 如果选取的容器太小,作业会出现内存不足的问题。 通常,YARN 容器不应小于 1 GB。 YARN 容器一般为 3 GB。 对于某些工作负荷,可能需要更大的 YARN 容器。
增加每个 YARN 容器的核心数。 增加分配给每个容器的核心数,以提高每个容器中运行的并行任务数。 此做法适用于每个容器运行多个任务的应用程序,例如 Spark。 对于在每个容器中运行一个线程的应用程序(如 Hive),最好分配多个容器,而不是为每个容器分配多个核心。
工作负荷层
使用所有可用的容器。 将任务数设置为等于或大于可用容器数,以便使用所有资源。
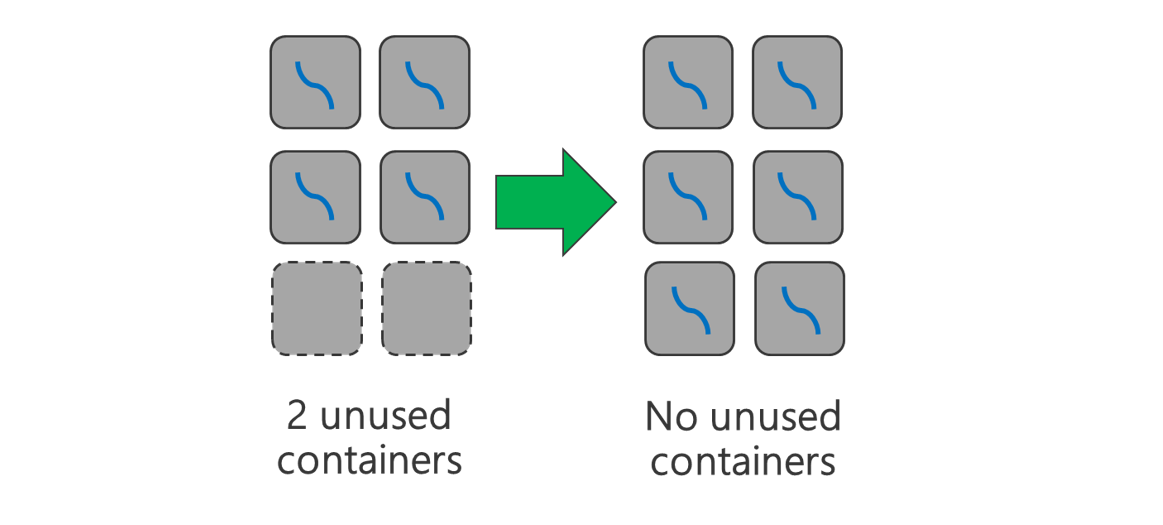
失败的任务成本高昂。 如果每项任务都有大量数据需要处理,那么任务失败就会导致以高成本重试任务。 因此,最好创建多个任务,其中每个任务都处理少量数据。
除上述常规准则外,每个应用程序都有不同的参数,可用于优化该特定应用程序。 下表列出了一些参数和链接,有助于开始对每个应用程序执行性能优化。
| 工作负载 | 用于设置任务数的参数 |
|---|---|
| HDInsight 上的 Spark |
|
| Hive on HDInsight |
|
| MapReduce on HDInsight |
|
| Storm on HDInsight |
|