你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:利用无服务器 SQL 池探索和分析数据湖
本教程介绍如何执行探索性数据分析。 你将使用无服务器 SQL 池组合不同的 Azure 开放数据集。 然后,在 Synapse Studio for Azure Synapse Analytics 中将结果可视化。
OPENROWSET(BULK...) 函数可用于访问 Azure 存储中的文件。 [OPENROWSET](develop-openrowset.md) 读取远程数据源(例如文件)的内容,并将内容作为行集返回。
自动架构推理
由于数据以 Parquet 文件格式存储,因此可以使用自动架构推理。 无需列出文件中所有列的数据类型即可查询数据。 还可以使用虚拟列机制和 filepath 函数筛选出特定的文件子集。
注意
默认排序规则为 SQL_Latin1_General_CP1_CI_ASIf。 对于非默认排序规则,请考虑到区分大小写。
如果使用区分大小写的排序规则创建数据库,则在指定列时,请确保使用列的正确名称。
列名 tpepPickupDateTime 是正确的,而 tpeppickupdatetime 在非默认排序规则中不起作用。
本教程使用关于纽约市 (NYC) 出租车的数据集:
- 上车/下车日期和时间
- 上车/下车地点
- 行程距离
- 费用明细
- 费率类型
- 支付类型
- 驾驶员报告的乘客计数
要熟悉 NYC 出租车数据,请运行以下查询:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
同样,你可以通过使用以下查询来查询公共节假日数据集:
SELECT TOP 100 * FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
还可以使用以下查询来查询天气数据数据集:
SELECT
TOP 100 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
可以在数据集的说明中详细了解各个列的含义:
时序、季节性和离群值分析
可通过使用以下查询汇总每年的出租车搭乘次数:
SELECT
YEAR(tpepPickupDateTime) AS current_year,
COUNT(*) AS rides_per_year
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) >= '2009' AND nyc.filepath(1) <= '2019'
GROUP BY YEAR(tpepPickupDateTime)
ORDER BY 1 ASC
以下片段显示了每年出租车搭乘次数的结果:
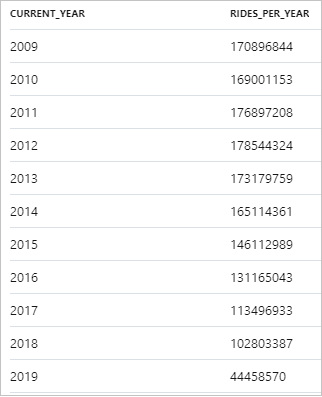
在 Synapse Studio 中,可以通过从“表”视图切换到“图表”视图来可视化数据 。 可以在不同的图表类型(如面积图、条形图、柱形图、折线图、饼图和散点图)之间进行选择 。 在本例中,请在“类别”列设置为“current_year”的情况下绘制柱形图 :
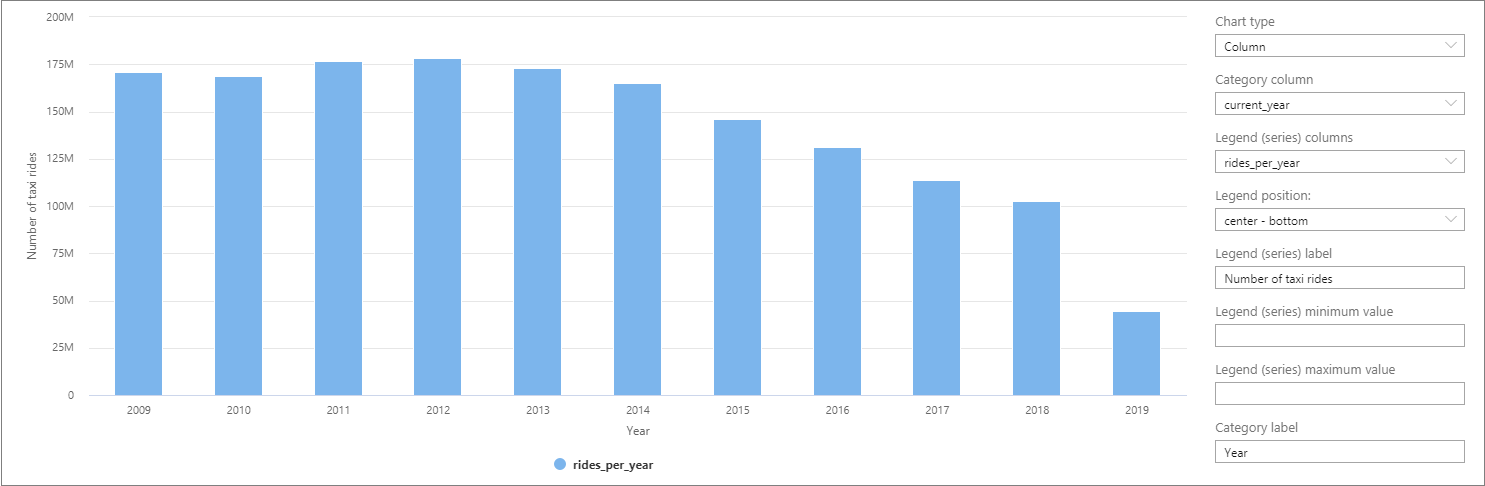
在此可视化效果中,你可以看到这些年来搭乘次数呈下降趋势。 这种下降可能是由于近年来拼车公司越来越受到欢迎所导致的。
注意
编写本教程时,2019 年的数据尚不完整。 因此,这一年的搭乘次数大幅下降。
你可以专注于分析某个年份,例如 2016 年。 以下查询返回该年份的每日搭乘次数:
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
ORDER BY 1 ASC
以下片段显示了此查询的结果:
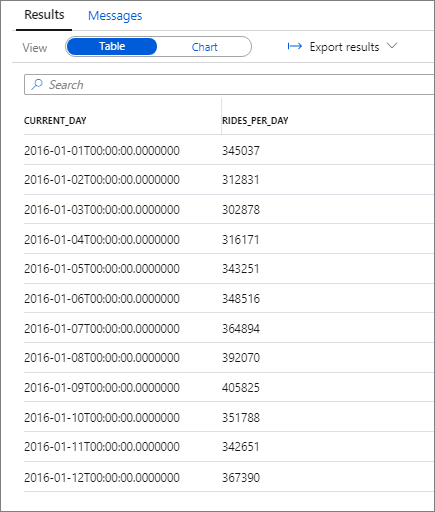
同样,你可以在“类别”列设置为“current_day”以及“图例(系列)”列设置为“rides_per_day”的情况下绘制柱形图,以将数据可视化。
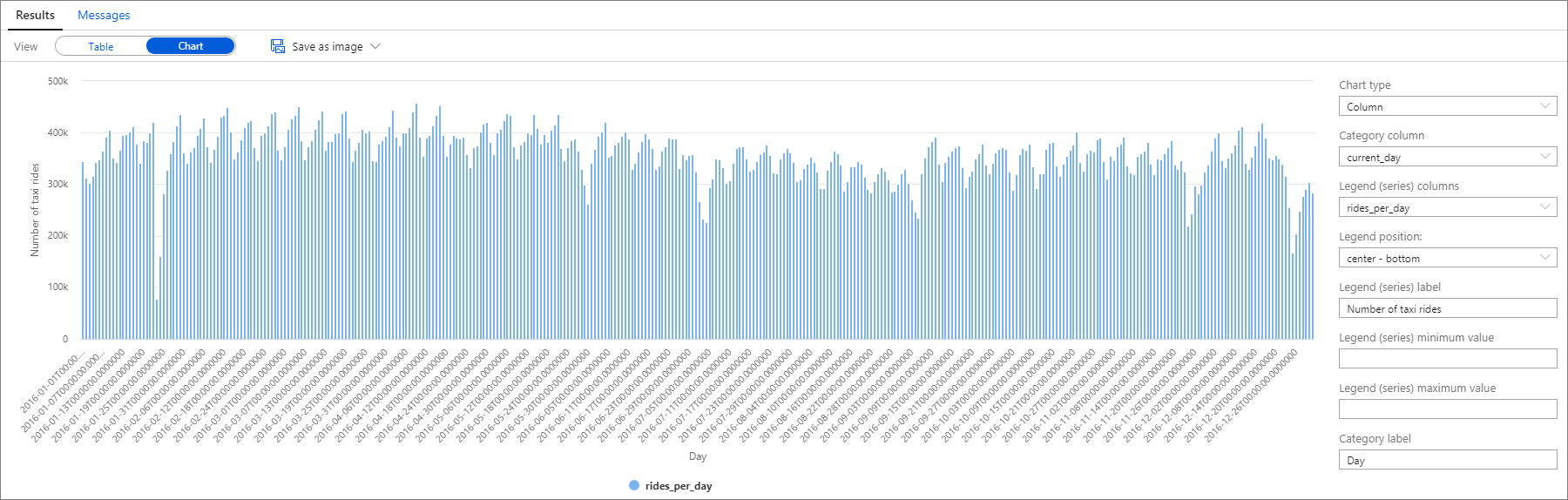
在绘图图表中,有一个每周走势,其中星期六为高峰日。 在夏季的几个月份,由于出现了长假,出租车搭乘次数较少。 出租车搭乘次数还出现了几次明显的下降,而且没有明确的模式解释发生这种情况的时间和原因。
接下来,看看搭乘次数的下降是否与公共节假日相关联。 通过将 NYC 出租车搭乘数据集与公共假日数据集相联接,检查这两者是否存在相关性:
WITH taxi_rides AS (
SELECT
CAST([tpepPickupDateTime] AS DATE) AS [current_day],
COUNT(*) as rides_per_day
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/nyctlc/yellow/puYear=*/puMonth=*/*.parquet',
FORMAT='PARQUET'
) AS [nyc]
WHERE nyc.filepath(1) = '2016'
GROUP BY CAST([tpepPickupDateTime] AS DATE)
),
public_holidays AS (
SELECT
holidayname as holiday,
date
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/holidaydatacontainer/Processed/*.parquet',
FORMAT='PARQUET'
) AS [holidays]
WHERE countryorregion = 'United States' AND YEAR(date) = 2016
),
joined_data AS (
SELECT
*
FROM taxi_rides t
LEFT OUTER JOIN public_holidays p on t.current_day = p.date
)
SELECT
*,
holiday_rides =
CASE
WHEN holiday is null THEN 0
WHEN holiday is not null THEN rides_per_day
END
FROM joined_data
ORDER BY current_day ASC
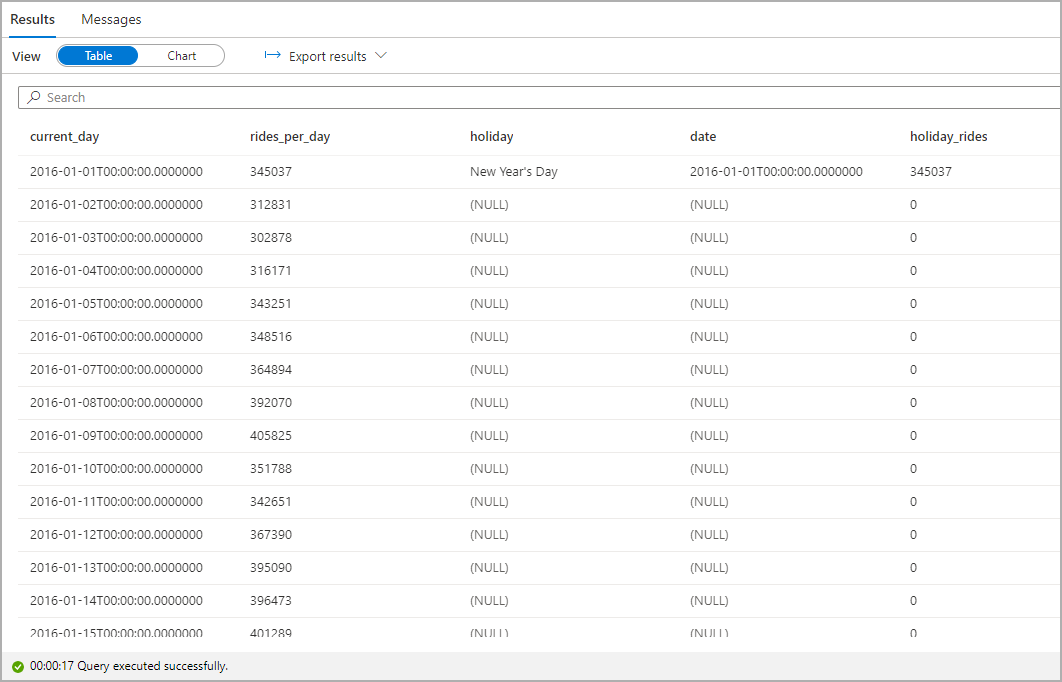
突出显示公共节假日期间出租车搭乘次数。 为此,请为“类别”列选择“current_day”,对“图例(系列)”列选择“rides_per_day”和“holiday_rides”。
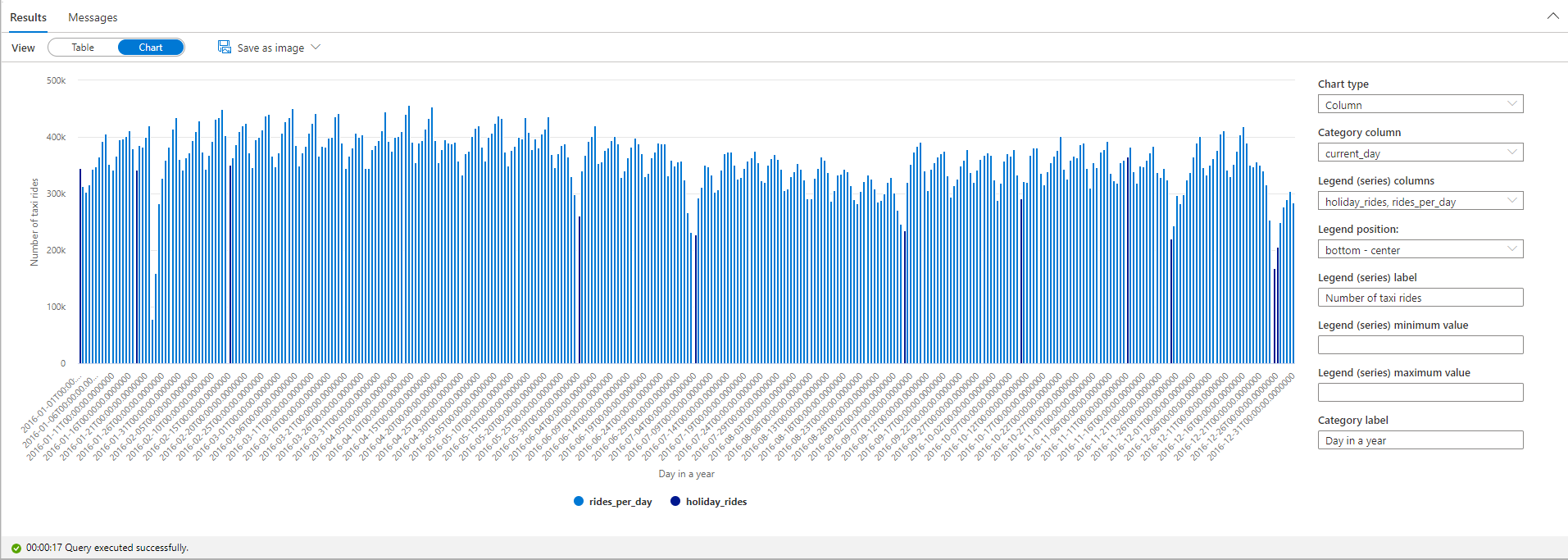
从绘图图表中可以看出,在公共节假日期间,出租车搭乘次数较少。 1 月 23 日仍然出现了一次原因不明的大幅下降。 让我们通过查询天气数据数据集来检查 NYC 在那一天的天气:
SELECT
AVG(windspeed) AS avg_windspeed,
MIN(windspeed) AS min_windspeed,
MAX(windspeed) AS max_windspeed,
AVG(temperature) AS avg_temperature,
MIN(temperature) AS min_temperature,
MAX(temperature) AS max_temperature,
AVG(sealvlpressure) AS avg_sealvlpressure,
MIN(sealvlpressure) AS min_sealvlpressure,
MAX(sealvlpressure) AS max_sealvlpressure,
AVG(precipdepth) AS avg_precipdepth,
MIN(precipdepth) AS min_precipdepth,
MAX(precipdepth) AS max_precipdepth,
AVG(snowdepth) AS avg_snowdepth,
MIN(snowdepth) AS min_snowdepth,
MAX(snowdepth) AS max_snowdepth
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/isdweatherdatacontainer/ISDWeather/year=*/month=*/*.parquet',
FORMAT='PARQUET'
) AS [weather]
WHERE countryorregion = 'US' AND CAST([datetime] AS DATE) = '2016-01-23' AND stationname = 'JOHN F KENNEDY INTERNATIONAL AIRPORT'

查询结果表明,以下原因导致出租车搭乘次数下降:
- NYC 在那一天出现暴风雪天气,雪非常厚(约有 30 厘米)。
- 天气非常寒冷(温度低于零摄氏度)。
- 风非常大(风速大约 10 米/秒)。
本教程展示了数据分析师如何快速执行探索性数据分析。 可以使用无服务器 SQL 池组合不同的数据集,并使用 Azure Synapse Studio 可视化结果。
后续步骤
若要了解如何将无服务器 SQL 池连接到 Power BI Desktop 并创建报表,请参阅将无服务器 SQL 池连接到 Power BI Desktop 并创建报表。
若要了解如何在无服务器 SQL 池中使用外部表,请参阅通过 Synapse SQL 使用外部表