值类别以及对它们的引用
本主题介绍并描述了 C++ 中存在的各种值类别(以及对值的引用):
- 泛左值
- 左值
- 将亡左值
- 纯右值
- 右值
你肯定听说过左值和右值。 但在本主题介绍的术语中,你可能不会想起它们。
C++ 中的每个表达式都会生成一个值,该值属于上面所列的五个类别之一。 C++ 语言及其工具和规则的许多方面都需要正确理解这些值类别以及对它们的引用。 这些方面包括获取值的地址、复制值、移动值、将值转发给另一函数。 本主题不会深入讨论所有这些方面,但会提供基本信息,帮助你深刻理解它们。
本主题的信息结构遵循 Stroustrup 对值类别的分析,即按两种独立的属性(标识和移动性)对值分类 [Stroustrup, 2013]。
左值有标识
值有标识是什么意思? 如果你有(或者可以获取)某个值的内存地址,并且可以安全地使用它,则说明该值有标识。 这样,你除了比较值的内容,还可以执行其他操作:按标识比较或区分它们。
左值有标识。 “lvalue”(左值)中的“l”是“left”(例如,在赋值的 left 侧,即左侧)的缩写,但目前这只具有历史意义。 在 C++ 中,左值可以出现在赋值的左侧,也可以出现在右侧。 因此,并不能根据“lvalue”(左值)中的“l”(左)来了解或确定值的实际位置。 你只需明白,我们称某个值为左值,只是表明该值有标识。
属于左值的表达式的示例包括:命名的变量或常量;返回引用的函数。 不属于左值的表达式的示例包括:临时值;返回值的函数。
int& get_by_ref() { ... }
int get_by_val() { ... }
int main()
{
std::vector<byte> vec{ 99, 98, 97 };
std::vector<byte>* addr1{ &vec }; // ok: vec is an lvalue.
int* addr2{ &get_by_ref() }; // ok: get_by_ref() is an lvalue.
int* addr3{ &(get_by_ref() + 1) }; // Error: get_by_ref() + 1 is not an lvalue.
int* addr4{ &get_by_val() }; // Error: get_by_val() is not an lvalue.
}
现在可以说左值有标识,而将亡值也是这样。 我们稍后会在本主题中探讨到底什么是将亡值。 现在,我们只需知道有一个名为“glvalue”(全称为“generalized lvalue”,即“泛左值”)的值类别。 泛左值集包含左值(也称为“经典左值”)和将亡值的超集。 因此,虽然“左值有标识”这种说法是正确的,但严格说来,应该是泛左值集有标识,如下图所示。
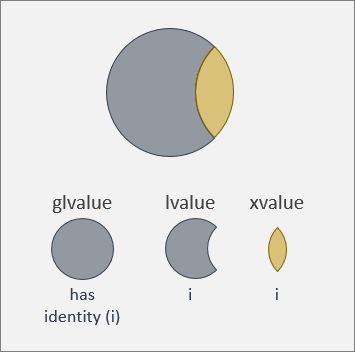
右值可移动,左值不能
但是,有的值不是泛左值。 换句话说,有的值你不能获取其内存地址(或者说,你不能依赖该值获得有效性)。 我们在上面的代码示例中看到过一些这样的值。
没有可靠的内存地址听起来像是一个缺点。 但实际上,此类值的优势是可以移动它(通常开销很低),而不是复制它(通常开销很高)。 移动一个值意味着该值不再在原来的位置。 因此,应避免在原来的位置访问它。 本主题不讨论何时以及如何移动值。 就本主题来说,我们只需知道,可移动的值称为“右值”(或“经典右值”)。
“rvalue”(右值)中的“r”是“right”(例如,在赋值的 right 侧,即右侧)的缩写。 但是,你可以在赋值外部使用右值以及右值的引用。 那么,就不需关注“rvalue”(右值)中的“r”(右)了。 你只需明白,我们称某个值为右值,只是表明该值可移动。
与之相反,左值不可移动,如下图所示。 如果要移动左值,那么就会与左值的定义相矛盾。 对于合理预期能够继续访问左值的代码而言,这可能会产生意外的问题。
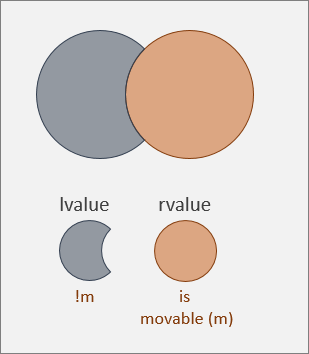
因此,不能移动左值。 但是,有一种泛左值(带标识的值集)是可以移动的,前提是你知道如何操作(例如,注意不要在移动后访问它),这就是将亡值。 我们稍后会在本主题再次遇到此概念,并会对值类别进行汇总。
右值引用以及引用绑定规则
此部分介绍右值引用的语法。 我们需要等到另一个主题来讨论如何对移动和转发进行实质性处理,不过,在这里只需知道右值引用是那些问题的解决方案的必要部分。 但是,在讨论右值引用之前,我们首先需要更清楚地了解 T&,我们以前直接称之为“引用”。 它实际上是“左值(非常量)引用”,引用的是允许引用用户写入的值。
template<typename T> T& get_by_lvalue_ref() { ... } // Get by lvalue (non-const) reference.
template<typename T> void set_by_lvalue_ref(T&) { ... } // Set by lvalue (non-const) reference.
左值引用可以绑定到左值,但不能绑定到右值。
此外还有左值常量引用 (T const&),引用的是不可供引用用户写入的对象(例如常量)。
template<typename T> T const& get_by_lvalue_cref() { ... } // Get by lvalue const reference.
template<typename T> void set_by_lvalue_cref(T const&) { ... } // Set by lvalue const reference.
左值常量引用可以绑定到左值或右值。
类型为 T 的右值引用的语法可以表示为 T&&。 右值引用引用可移动值,即其内容在使用后不需保留的值(例如临时值)。 由于关键是移动(并修改)绑定到右值引用的值,因此不会将 const 和 volatile 限定符(也称 cv 限定符)应用到右值引用。
template<typename T> T&& get_by_rvalue_ref() { ... } // Get by rvalue reference.
struct A { A(A&& other) { ... } }; // A move constructor takes an rvalue reference.
右值引用绑定到右值。 事实上,在进行重载决策时,右值首选绑定到右值引用而不是左值常量引用。 但是,右值引用不能绑定到左值,因为如前所述,右值引用引用的是假定其内容不需保留的值(例如,移动构造函数的参数)。
也可在需要传值参数的情况下,通过复制构造传递右值(或者在右值是将亡值的情况下,通过移动构造来传递)。
泛左值有标识,纯右值没有
目前,我们介绍了什么值有标识。 我们还介绍了什么值可以移动,什么值不能移动。 但是,我们还没有介绍没有标识的值集。 该集称为“prvalue”(全称“pure rvalue”,即“纯右值”)。
int& get_by_ref() { ... }
int get_by_val() { ... }
int main()
{
int* addr3{ &(get_by_ref() + 1) }; // Error: get_by_ref() + 1 is a prvalue.
int* addr4{ &get_by_val() }; // Error: get_by_val() is a prvalue.
}

值类别汇总
现在,我们将上面的信息和图片汇总一下。
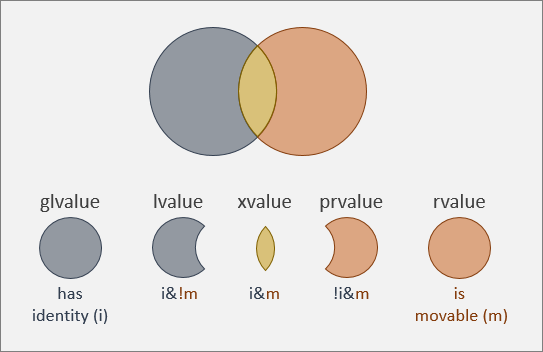
泛左值 (i)
泛左值(即 glvalue,全称为 generalized lvalue)有标识。 我们使用“i”作为“has identity”(有标识)的简写形式。
左值 (i&!m)
左值(一种泛左值)有标识,但不可移动。 这些通常都是可以传递的读-写值,传递方法包括引用传递、常量引用传递、值传递(如果复制的开销很低)。 左值不能绑定到右值引用。
将亡值 (i&m)
将亡值(一种泛左值,但也是一种右值)有标识,但也不可移动。 将亡值可以是以前的某个左值。由于复制开销很高,你已经决定移动此左值,但需注意不要在以后再访问它。 下面演示如何将左值转换为将亡值。
struct A { ... };
A a; // a is an lvalue...
static_cast<A&&>(a); // ...but this expression is an xvalue.
在上述代码示例中,我们还没有移动任何值。 我们只是将左值强制转换为未命名的右值引用,通过这种方式创建了一个将亡值。 该值仍可通过其左值名称进行标识,但作为将亡值,它现在可以移动了。 若要了解移动该值的原因,以及实际上要进行什么样的移动,则需参阅另一主题。 不过,你不妨将“xvalue”(将亡值)中的“x”视为“expert-only”(专家级),暂时跳过该主题。 将左值强制转换为将亡值(请记住,这是一种右值)以后,该值就可以绑定到右值引用了。
下面是两个其他的将亡值示例:一个示例调用可返回未命名右值引用的函数,另一个示例访问将亡值的成员。
struct A { int m; };
A&& f();
f(); // This expression is an xvalue...
f().m; // ...and so is this.
纯右值 (!i&m)
纯右值(即 prvalue,全称为 pure rvalue,一种右值)没有标识,但可移动。 此类值通常为临时值,或者为调用可返回值的函数后的结果,或者为对任何其他不属于泛左值的表达式求值后的结果。
右值 (m)
右值可移动。 我们将使用“m”作为“is movable”(可移动)的简写形式。
右值引用始终引用右值(假定其内容不需保留的值)。
但是,右值引用本身是否为右值? 未命名右值引用(例如在上面的将亡值代码示例中显示的引用)为将亡值,因此属于右值。 它首选绑定到右值引用函数参数,例如移动构造函数的参数。 相反(也许违背直觉),如果右值引用有名称,则包含该名称的表达式为左值。 因此,它不能绑定到右值引用参数。 但是,让它那样做很容易,将它再次强制转换为未命名右值引用(将亡值)即可。
void foo(A&) { ... }
void foo(A&&) { ... }
void bar(A&& a) // a is a named rvalue reference; so it's an lvalue.
{
foo(a); // Calls foo(A&).
foo(static_cast<A&&>(a)); // Calls foo(A&&).
}
A&& get_by_rvalue_ref() { ... } // This unnamed rvalue reference is an xvalue.
!i&!m
没有标识且不可移动的这类值是我们尚未讨论过的一种组合。 不过,我们可以将它忽略,因为该类别在 C++ 语言中属于无用的概念。
引用折叠规则
一个表达式中有多个相同的引用(对左值引用进行左值引用,或者对右值引用进行右值引用)时,会互相取消。
A& &折叠成A&。A&& &&折叠成A&&。
一个表达式中有多个不同的引用时,会折叠成一个左值引用。
A& &&折叠成A&。A&& &折叠成A&。
转发引用
这最后一部分将我们讨论过的右值引用与转发引用的不同概念进行比较。 在“forwarding reference”(转发引用)一词被造出之前,一些人使用“universal reference”(通用引用)一词。
void foo(A&& a) { ... }
A&&为右值引用,如前所述。 常量和易失性不适用于右值引用。foo只接受 A 类型的右值。- 之所以存在右值引用(例如
A&&),是因为这样可以创作一个重载,该重载经过优化,适用于需要传递临时值(或其他右值)的情况。
template <typename _Ty> void bar(_Ty&& ty) { ... }
_Ty&&是转发引用。 类型 _Ty 可以是常量/非常量(独立于易失性/非易失性),具体取决于传递给bar的内容。bar接受任何类型为 _Ty 的左值或右值。- 传递左值会导致转发引用变成
_Ty& &&,后者折叠成左值引用_Ty&。 - 传递右值会导致转发引用变成右值引用
_Ty&&。 - 使用转发引用(例如
_Ty&&)不是为了优化,而是为了获取传递的值并以透明且高效的方式对其进行转发。 只有在编写(或深入研究)库代码时,才可能遇到转发引用,例如,一个在构造函数参数基础上进行转发的工厂函数。
源
- [Stroustrup, 2013] B. Stroustrup:《C++ 程序设计语言》,第四版。 Addison-Wesley。 2013.
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈