你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure Analysis Services 横向扩展
通过横向扩展,客户端查询可分布在查询池的多个查询副本中,从而在高查询工作负载期间缩短响应时间 。 也可将处理与查询池分开,确保客户端查询不受处理操作的负面影响。 可在 Azure 门户中配置横向扩展,也可使用 Analysis Services REST API 进行配置。
标准定价层中的服务器可使用横向扩展。 每个查询副本与服务器的计费费率相同。 将在服务器所在的同一区域中创建所有查询副本。 你可以配置的查询副本数量受服务器所在区域限制。 若要了解详细信息,请参阅可用性(按区域)。 横向扩展不会增加服务器的可用内存量。 要增加内存,需升级计划。
为什么横向扩展?
在典型的服务器部署中,一台服务器同时用作处理服务器和查询服务器。 如果服务器上针对模型的客户端查询数量超过服务器计划的查询处理单元 (QPU),或模型处理与高查询工作负载同时发生,就会导致性能降低。
通过横向扩展,可创建查询池,最多可添加 7 个查询副本资源(包括主服务器在内共 8 个)。 可以缩放查询池中的副本数目以满足关键时刻的 QPU 需求,并且随时可以从查询池中隔离处理服务器。
不论查询池中查询副本的数量如何,处理工作负载都不会分布在查询副本中。 主服务器充当处理服务器。 查询副本仅为针对查询池中主服务器与每个副本之间同步的模型数据库发出的查询提供服务。
横向扩展时,最长可能需要花费五分钟时间来以增量方式将新的查询副本添加到查询池。 所有新的查询副本正常运行后,新的客户端连接将在查询池中的资源之间进行负载均衡。 现有的客户端连接不会从当前连接到的资源更改。 横向缩减时,将终止与正在从查询池中删除的查询池资源的任何现有客户端连接。 客户端可以重新连接到剩余的查询池资源。
工作原理
首次配置横向扩展时,主服务器上的模型数据库将自动与新查询池中的新副本同步。 自动同步只发生一次。 在自动同步期间,主服务器的数据文件(在 Blob 存储中静态加密)将复制到另一个位置,并且也会在 Blob 存储中静态加密。 然后,查询池中的副本将与第二组文件中的数据合成。
只能在首次横向扩展服务器时执行自动同步,不过,也可以执行手动同步。 同步可确保查询池中的副本数据与主服务器的数据相匹配。 处理(刷新)主服务器上的模型时,必须在处理操作完成之后执行同步。 这种同步会将更新的数据从 Blob 存储中的主服务器文件复制到第二组文件。 然后,查询池中的副本将与 Blob 存储中第二组文件内的已更新数据合成。
执行后续的横向扩展操作时(例如,将查询池中的副本数从两个增加到五个),新副本将与 Blob 存储中第二组文件内的数据合成。 不会发生同步。 如果接着在横向扩展后执行同步,则查询池中的新副本将合成两次 - 多余的合成。 执行后续的横向扩展操作时,请务必记住:
先执行同步,再执行横向扩展操作,以免多余地合成添加的副本。 不允许同时执行并行同步和横向扩展操作。
将处理操作和横向扩展操作自动化时,必须先处理主服务器上的数据,再执行同步,然后执行横向扩展操作。 遵循此顺序可确保尽量减轻对 QPU 和内存资源造成的影响。
在横向扩展操作期间,查询池中的所有服务器(包括主服务器)都暂时处于脱机状态。
即使查询池中没有副本,也允许同步。 如果在主服务器上通过处理操作将包含新数据的副本数从零个横向扩展为一个或多个,请先在查询池中不包含任何副本的情况下执行同步,然后再横向扩展。在横向扩展之前执行同步可以避免多余地合成新添加的副本。
从主服务器中删除模型(数据库)时,不会自动从查询池中的副本内删除该数据库。 必须使用 Sync-AzAnalysisServicesInstance PowerShell 命令执行同步操作。该命令会从副本的共享 Blob 存储位置删除该数据库的文件,然后删除查询池中的副本内的模型数据库。 若要确定某个模型数据库是否存在于查询池中的副本上,但不存在于主服务器上,请确保“从查询池分离处理服务器”设置为“是”。 然后,通过 SQL Server Management Studio (SSMS) 使用
:rw限定符连接到主服务器,看看该数据库是否存在。 然后,在没有:rw限定符的情况下连接到查询池中的副本,看同一数据库是否还存在。 如果该数据库存在于查询池中的副本上,但不存在于主服务器上,请运行同步操作。重命名主服务器上的数据库时,需要执行另一个步骤来确保数据库正确同步到所有副本。 重命名后,使用 Sync-AzAnalysisServicesInstance 并使用旧数据库名称指定
-Database参数,来执行同步。 这种同步会从所有副本中删除使用旧名称的数据库和文件。 然后,使用新数据库名称指定-Database参数,来执行另一次同步。 第二次同步会将新命名的数据库复制到第二组文件,并合成所有副本。 无法在门户中使用“同步模型”命令执行这些同步。
同步模式
默认情况下,查询副本会完全解除冻结,而不是以增量方式解除冻结。 解除冻结分阶段进行。 它们一次两个(假设至少有三个副本)地进行分离和附加,确保在任何给定时间进行查询都至少有一个副本保持联机状态。 某些情况下,当此过程正在进行时,客户端可能需要重新连接到其中一个联机副本。 使用 ReplicaSyncMode 设置,现在就可以指定以并行方式进行查询副本同步。 并行同步有以下优势:
- 大大减少了同步时间。
- 跨副本数据更可能在同步过程中保持一致。
- 所有副本上的数据库在整个同步过程中都保持联机状态,因此客户端无需重新连接。
- 内存中缓存通过增量方式进行更新时,仅更新已更改的数据,这可能比完全解冻模型更快。
设置 ReplicaSyncMode
使用 SSMS 在“高级属性”中设置 ReplicaSyncMode。 可能的值为:
1(默认值):将副本数据库分阶段(以增量方式)完全解除冻结。2:并行方式的优化同步。

设置 ReplicaSyncMode=2 时,查询副本可能会消耗更多的内存,具体取决于多少缓存需要更新。 为了使数据库始终处于联机状态并可供查询使用,该操作在极端情况下可能需要在副本上将内存加倍(具体取决于数据的更改量),因为旧段和新段同时保存在内存中。 副本节点与主节点有相同的内存分配,而主节点上通常有额外的内存用于刷新操作,因此,副本不太可能用尽内存。 另外,数据库通常在主节点上进行增量更新,因此通常不会要求内存加倍。 如果同步操作遇到内存不足错误,则会使用默认方法(一次两个副本地进行附加/分离)重试。
从查询池分离处理操作
为了最大限度地提高处理和查询操作的性能,可以选择将处理服务器与查询池分开。 分离后,新的客户端连接仅会分配给查询池中的查询副本。 如果处理操作仅占用一小段时间,则可以选择将处理服务器与查询池分开仅执行处理和同步操作所需的时间,然后将其包含回查询池中。 将处理服务器从查询池分离时,或者将其添加回查询池中时,可能需要长达五分钟的时间来完成操作。
监视 QPU 使用情况
若要确定服务器是否必须进行横向扩展,请在 Azure 门户中监视服务器指标。 如果 QPU 经常超过上限,则表示针对模型的查询数量超出了计划的 QPU 限制。 查询线程池队列中的查询数量超过可用的 QPU 时,查询池作业队列长度指标也会增加。
可监视的另一个很好指标是按 ServerResourceType 列出的平均 QPU。 此指标将主服务器的平均 QPU 与查询池的进行比较。
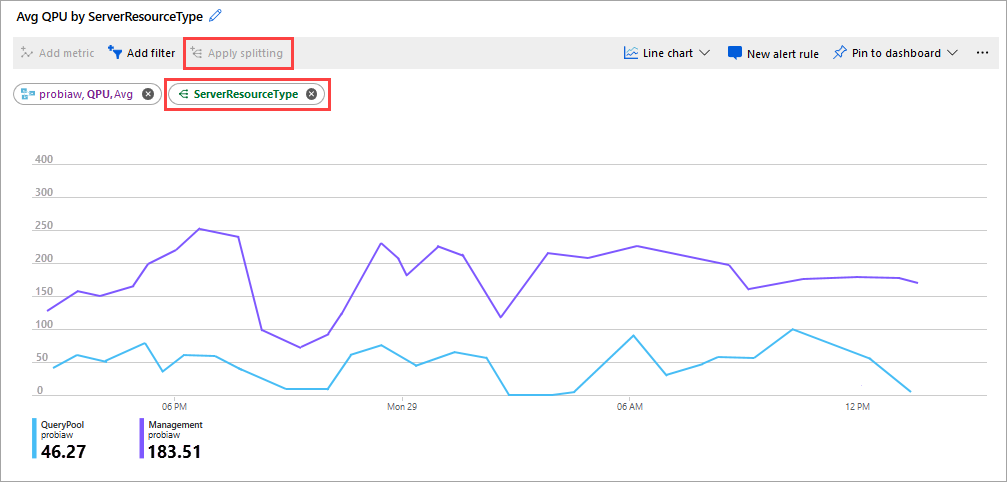
按 ServerResourceType 配置 QPU
- 在“指标”折线图中,单击“添加指标”。
- 在“资源”中选择你的服务器,在“指标命名空间”中选择“Analysis Services 标准指标”,在“指标”中选择“QPU”,然后在“聚合”中选择“平均”。
- 单击“应用拆分”。
- 在“值”中选择“ServerResourceType”。
详细的诊断日志记录
使用 Azure Monitor 日志更详细地诊断横向扩展的服务器资源。 借助日志,你可以使用 Log Analytics 查询按服务器和副本细分 QPU 和内存。 有关详细信息,请参阅 分析 Log Analytics 工作区中的日志。 有关示例查询,请参阅 Kusto 查询示例。
配置横向扩展
在 Azure 门户中配置
在门户中,单击“横向扩展”。使用滑块选择查询副本服务器的数量。 选择的副本数量不包括现有的服务器。
在“从查询池分离处理服务器”中,选择“是”以将处理服务器和查询服务器分开。 使用默认连接字符串(不带
:rw)的客户端连接将重定向到查询池中的副本。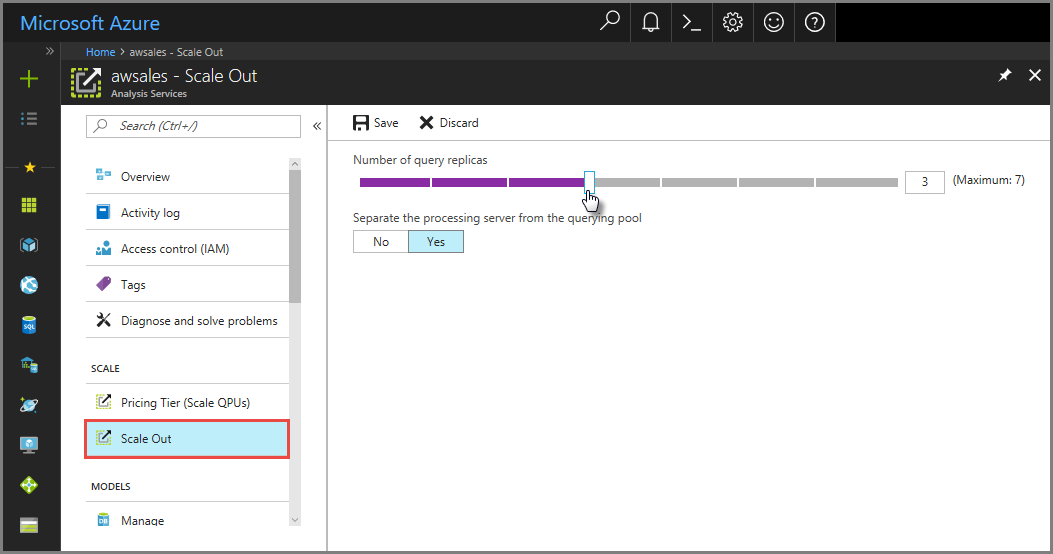
单击“保存”以预配新的查询副本服务器。
首次配置服务器的横向扩展时,主服务器上的模型将自动与查询池中的副本同步。 自动同步只发生一次,即,首次配置横向扩展为一个或多个副本时。 以后对同一台服务器上的副本数进行更改不会再次触发自动同步。 即使将服务器设置为零个副本,然后再次横向扩展为任意数目的副本,也不会再次发生自动同步。
同步
必须手动或使用 REST API 执行同步操作。
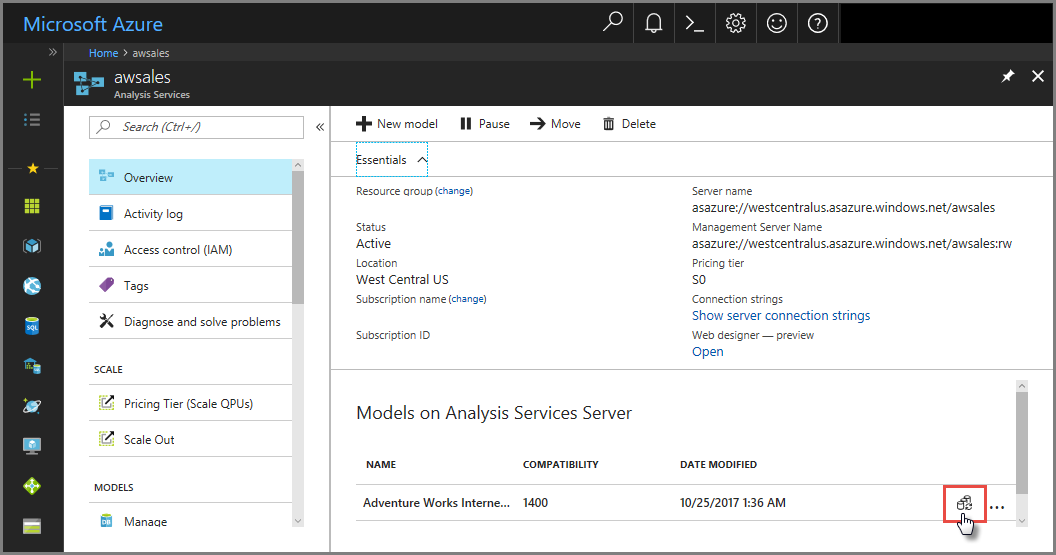
在 Azure 门户中配置
在“概述”>“模型”>“同步模型”中操作。
REST API
使用同步操作。
同步模型
POST https://<region>.asazure.windows.net/servers/<servername>:rw/models/<modelname>/sync
获取同步状态
GET https://<region>.asazure.windows.net/servers/<servername>/models/<modelname>/sync
返回状态代码:
| 代码 | 说明 |
|---|---|
| -1 | 无效 |
| 0 | 正在复制 |
| 1 | 正在解冻 |
| 2 | 已完成 |
| 3 | Failed |
| 4 | 正在完成 |
PowerShell
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 请参阅安装 Azure PowerShell 以开始使用。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
在使用 PowerShell 之前,请安装或更新最新的 Azure PowerShell 模块。
若要运行同步,请使用 Sync-AzAnalysisServicesInstance。
若要设置查询副本数,请使用 Set-AzAnalysisServicesServer。 指定可选的 -ReadonlyReplicaCount 参数。
若要从查询池隔离处理服务器,请使用 Set-AzAnalysisServicesServer。 将 -DefaultConnectionMode 可选参数指定为使用 Readonly。
若要了解详细信息,请参阅将服务主体与 Az.AnalysisServices 模块配合使用。
连接
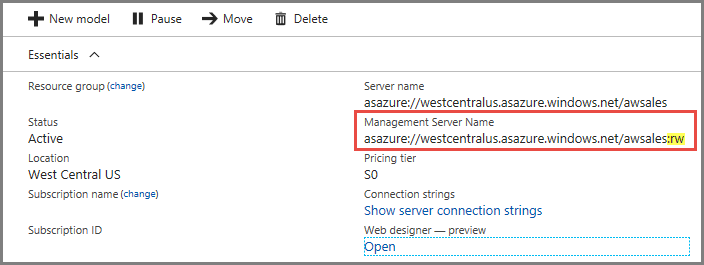
服务器的“概述”页上有两个服务器名称。 如果尚未对服务器配置横向扩展,则这两个服务器名称的工作方式相同。 为服务器配置横向扩展之后,需要根据连接类型指定适当的服务器名称。
对于最终用户客户端连接(如 Power BI Desktop、Excel 和自定义应用),请使用“服务器名称”。
对于 PowerShell 中的 SSMS、Visual Studio 和连接字符串、Azure 函数应用以及 AMO,请使用“管理服务器名称”。 管理服务器名称包含特殊限定符 :rw(读取-写入)。 所有处理操作均在管理服务器(主服务器)上发生。
纵向扩展、纵向缩减与横向扩展
可以在具有多个副本的服务器上更改定价层。 同一定价层适用于所有副本。 缩放操作将首先同时关闭所有副本,然后在新的定价层上启动所有副本。
疑难解答
问题:用户收到错误“在连接模式‘ReadOnly’下找不到服务器‘服务器名称’实例。”<>
解决方案: 选择“从查询池隔离处理服务器”选项时,使用默认连接字符串(不带 :rw)的客户端连接将重定向到查询池副本。 如果查询池中的副本因尚未完成同步而尚未联机,则重定向的客户端连接可能会失败。 若要防止连接失败,执行同步时查询池中必须至少有两个服务器。 每个服务器单独同步,而其他服务器保持联机。 如果在处理期间选择在查询池中没有处理服务器,则可以选择将其从池中删除以进行处理,然后在处理完成后但在同步之前将其添加回池中。 可以使用内存和 QPU 指标来监视同步状态。