你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
繁忙前端反模式
在大量后台线程中执行异步工作可能耗尽其他并发前台任务的资源,将响应时间降低到不可接受的水平。
问题描述
资源密集型任务可能增大用户请求的响应时间,使延迟提高。 缩短响应时间的方法之一是将资源密集型任务分配到独立的线程。 此方法可让应用程序保持响应能力,同时可在后台进行处理。 但是,在后台线程中运行的任务仍会占用资源。 如果这些任务过多,可能会耗尽用于处理请求的线程。
注意
术语“资源”涵盖许多指标,例如 CPU 利用率、内存占用率以及网络或磁盘 I/O。
如果应用程序是作为整体性的代码段开发的,其中的业务逻辑合并成为一个与呈现层共享的层,则通常就会发生此问题。
以下示例使用 ASP.NET 来演示该问题。 可在此处找到完整示例。
public class WorkInFrontEndController : ApiController
{
[HttpPost]
[Route("api/workinfrontend")]
public HttpResponseMessage Post()
{
new Thread(() =>
{
//Simulate processing
Thread.SpinWait(Int32.MaxValue / 100);
}).Start();
return Request.CreateResponse(HttpStatusCode.Accepted);
}
}
public class UserProfileController : ApiController
{
[HttpGet]
[Route("api/userprofile/{id}")]
public UserProfile Get(int id)
{
//Simulate processing
return new UserProfile() { FirstName = "Alton", LastName = "Hudgens" };
}
}
WorkInFrontEnd控制器中的Post方法实现 HTTP POST 操作。 此操作模拟一个长时间运行的 CPU 密集型任务。 工作在独立的线程中执行,以尝试使 POST 操作快速完成。UserProfile控制器中的Get方法实现 HTTP GET 操作。 此方法消耗的 CPU 资源要少得多。
Post 方法的资源要求是主要考虑因素。 尽管此方法会将工作放入后台线程,但该工作仍会占用相当多的 CPU 资源。 这些资源与其他并发用户执行的其他操作共享。 如果适度数量的用户同时发送此请求,整体性能可能会受到影响,使所有操作的速度变慢。 例如,用户在运行 Get 方法时可能会遇到明显的延迟。
如何解决问题
将消耗大量资源的进程移到独立的后端。
使用这种方法,前端会将资源密集型任务放入某个消息队列。 后端会拾取这些任务进行异步处理。 该队列还充当负载调控器,可缓冲后端的请求。 如果队列长度过长,你可以配置自动缩放,以横向扩展后端。
下面是上述代码的修改版本。 在此版本中,Post 方法将消息放在服务总线队列中。
public class WorkInBackgroundController : ApiController
{
private static readonly QueueClient QueueClient;
private static readonly string QueueName;
private static readonly ServiceBusQueueHandler ServiceBusQueueHandler;
public WorkInBackgroundController()
{
var serviceBusConnectionString = ...;
QueueName = ...;
ServiceBusQueueHandler = new ServiceBusQueueHandler(serviceBusConnectionString);
QueueClient = ServiceBusQueueHandler.GetQueueClientAsync(QueueName).Result;
}
[HttpPost]
[Route("api/workinbackground")]
public async Task<long> Post()
{
return await ServiceBusQueueHandler.AddWorkLoadToQueueAsync(QueueClient, QueueName, 0);
}
}
后端从服务总线队列中提取消息并执行处理。
public async Task RunAsync(CancellationToken cancellationToken)
{
this._queueClient.OnMessageAsync(
// This lambda is invoked for each message received.
async (receivedMessage) =>
{
try
{
// Simulate processing of message
Thread.SpinWait(Int32.MaxValue / 1000);
await receivedMessage.CompleteAsync();
}
catch
{
receivedMessage.Abandon();
}
});
}
注意事项
- 此方法在一定程度上增大了应用程序的复杂性。 必须安全处理排队和取消排队,以免在发生故障时丢失请求。
- 应用程序依赖于其他服务处理消息队列。
- 处理环境必须有足够高的可伸缩性,可处理预期的工作负荷并满足所需的吞吐量目标。
- 尽管此方法可提高总体响应能力,但移到后端的任务可能需要更长的时间才能完成。
如何检测问题
繁忙前端的症状包括执行资源密集型任务时延迟偏高。 最终用户可能会反映响应时间延长,或服务超时导致失败。这些失败还可能返回 HTTP 500(内部服务器)错误或 HTTP 503(服务不可用)错误。 检查 Web 服务器的事件日志,其中可能包含有关错误原因和情况的更详细信息。
可执行以下步骤来帮助识别此问题:
- 对生产系统执行进程监视,识别响应时间变长的位置。
- 检查在这些位置捕获到的遥测数据,确定所执行的混合操作以及所用的资源。
- 找出响应异常的时间点与在这些时间点上发生操作的数量与组合之间的任何关联。
- 针对每个可疑的操作执行负载测试,确定哪些操作消耗了资源并阻塞了其他操作。
- 检查这些操作的源代码,确定它们导致资源消耗过度的原因。
示例诊断
以下部分将这些步骤应用到前面所述的示例应用程序。
识别速度变慢的位置
检测每个方法,跟踪每个请求的持续时间和消耗的资源。 然后在生产环境中监视应用程序。 这可以提供请求相互争用资源的总体视图。 在受压过程中,运行速度缓慢且大量消耗资源的请求可能会影响其他操作。可以通过监视系统并关注性能下降位置来观察此行为。
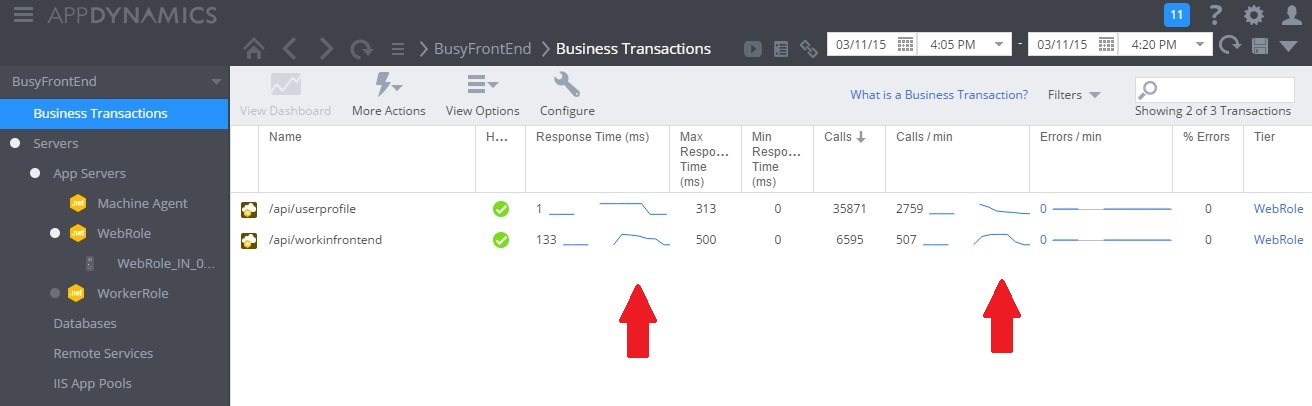
下图显示了监视仪表板。 (我们在测试中使用了 AppDynamics。)系统最初的负载较轻。 然后,用户开始请求 UserProfile GET 方法。 在其他用户开始对 WorkInFrontEnd POST 方法发出请求之前,性能一直相当良好。 此后,响应时间急剧增大(第一个箭头)。 只有在对 WorkInFrontEnd 控制器的请求量下降之后,响应时间才有改善(第二个箭头)。
检查遥测数据并找出关联
下图显示了所收集的、用于监视同一时间间隔内资源利用率的指标。 一开始,只有少量的用户访问系统。 随着越来越多的用户建立连接,CPU 利用率变得极高 (100%)。 另请注意,网络 I/O 速率最初是根据 CPU 使用率的提高而上升。 但是,一旦 CPU 使用率达到峰值,网络 I/O 实际上会下降。 这是因为,一旦 CPU 达到容量限制,系统就只能处理相对较小数量的请求。 随着用户断开连接,CPU 负载逐渐降低。
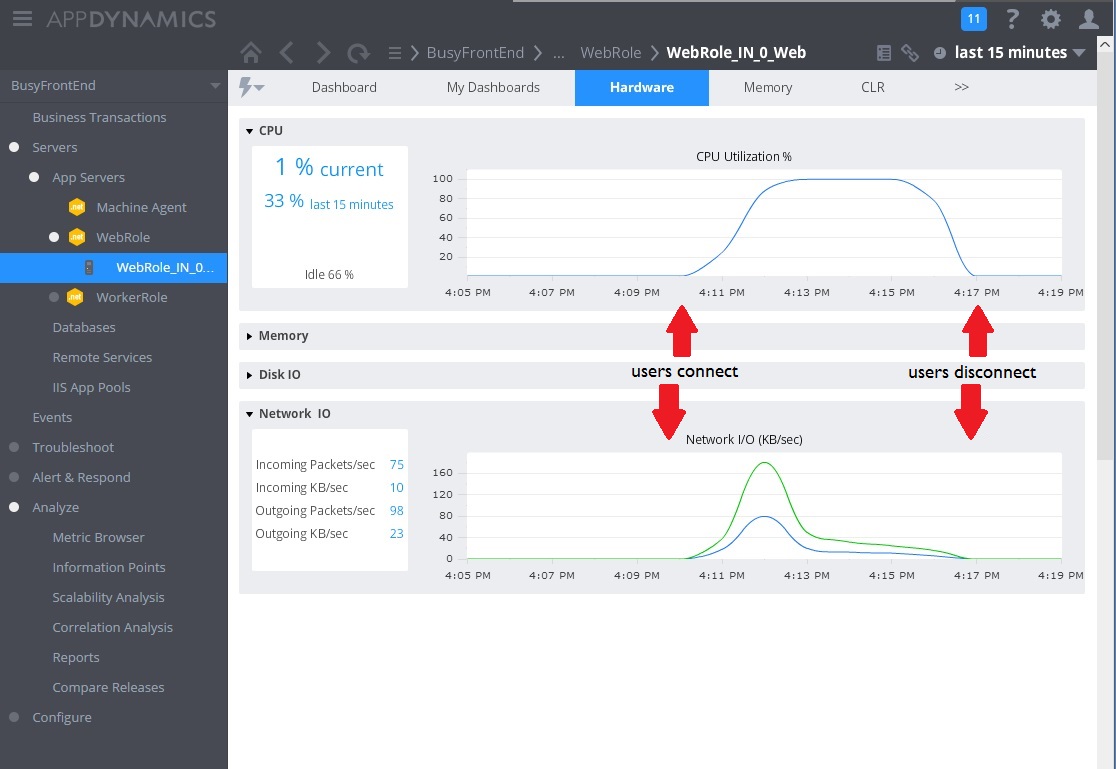
此时,WorkInFrontEnd 控制器中的 Post 方法似乎就成了可供密切检查的首要候选项。 需要在受控环境中开展更多的工作,以确认假设条件。
执行负载测试
下一步是在受控环境中执行测试。 例如,轮流运行一系列包含然后省略每个请求的负载测试,以查看影响。
下图显示了针对上述测试中使用的相同云服务部署执行的负载测试结果。 该测试使用了一个常量负载,其中包含 500 个在 UserProfile 控制器中执行 Get 操作的用户;另外还使用了一个阶跃负载,其中包含在 WorkInFrontEnd 控制器中执行 Post 操作的用户。

最初,阶跃负载为 0,因此,只有活动的用户在执行 UserProfile 请求。 系统每秒大约能够响应 500 个请求。 60 秒后,包含 100 个附加用户的负载开始向 WorkInFrontEnd 控制器发送 POST 请求。 几乎在同一时刻,发送到 UserProfile 控制器的工作负荷下降到每秒大约 150 个请求。 这种情况是负载测试运行程序的运行方式造成的。 它会在等到获取响应后再发送下一个请求,因此,它收到响应所花费的时间越长,请求速率就越低。
随着越来越多的用户向 WorkInFrontEnd 控制器发送 POST 请求,UserProfile 控制器的响应速率会持续下降。 但请注意,WorkInFrontEnd 控制器处理的请求数量保持相对稳定。 随着两种请求的总速率倾向于稳定但又偏低的限制,系统的饱和度一目了然。
检查源代码
最后一步是查看源代码。 开发团队已了解到,Post 方法可能需要花费相当长的时间,正因如此,原始实现使用了独立的线程。 这种做法解决了眼下的问题,因为 Post 方法在等待长时间运行的任务完成期间未阻塞。
但是,此方法执行的工作仍会消耗 CPU、内存和其他资源。 让此进程以异步方式运行实际上可能会损害性能,因为用户能够以不受控的方式同时大量触发这些操作。 服务器可以运行的线程数有限制。 如果超过此限制,应用程序在尝试启动新线程时可能发生异常。
注意
这并不意味着应该避免异步操作。 在网络调用中执行异步等待是建议的做法。 (请参阅同步 I/O 反模式。)此处的问题在于,CPU 密集型工作已在另一个线程中衍生。
实施解决方案并验证结果
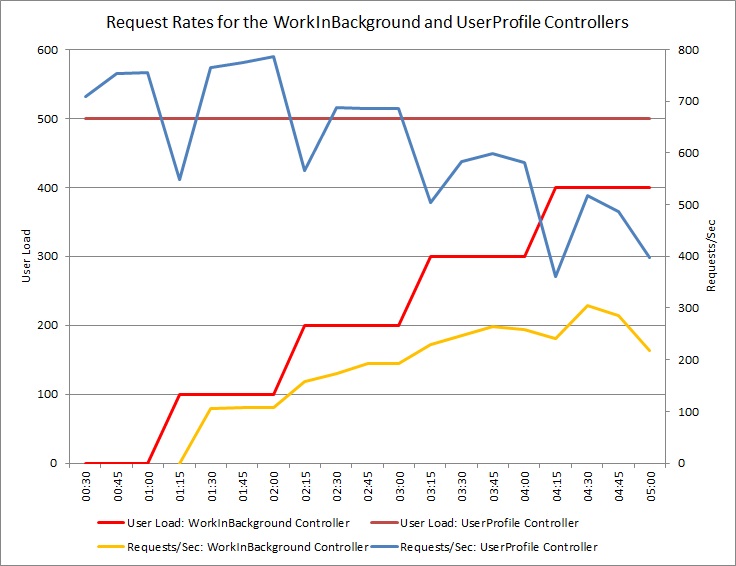
下图显示了实施解决方案后的性能监视。 负载与前面所示的类似,但 UserProfile 控制器的响应时间现在要快得多。 在相同的持续时间内,请求数量已从 2,759 增大到 23,565。
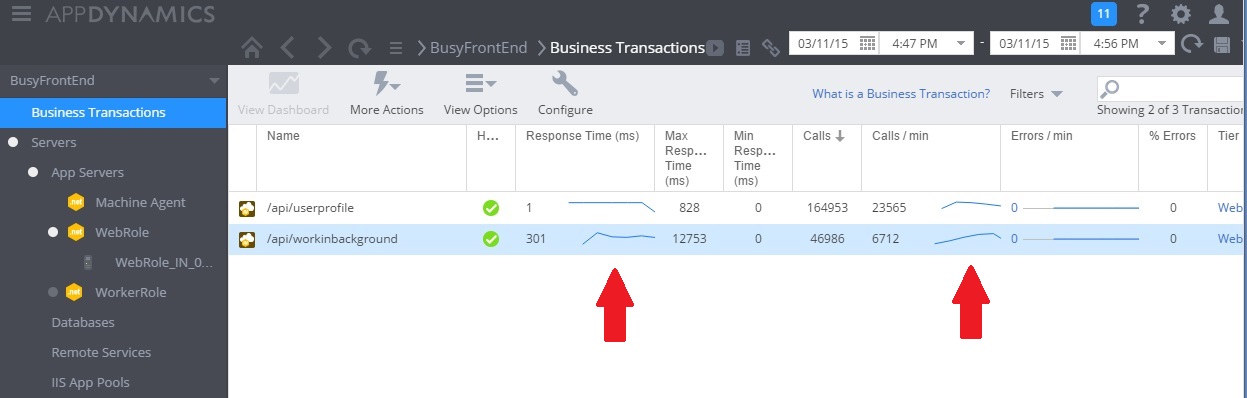
请注意,WorkInBackground 控制器还处理了多得多的请求。 但是,在此情况下无法进行直接的比较,因为在此控制器中执行的工作与原始代码有很大的差别。 新版本只是将请求排队,而没有执行耗时的计算。 要点是,此方法已不再拖累整个承受负载的系统。
CPU 和网络利用率也表明性能有了改进。 CPU 利用率从未达到过 100%,处理的网络请求数量远远超过前面的测试,并且在工作负荷降低之前未曾下降。
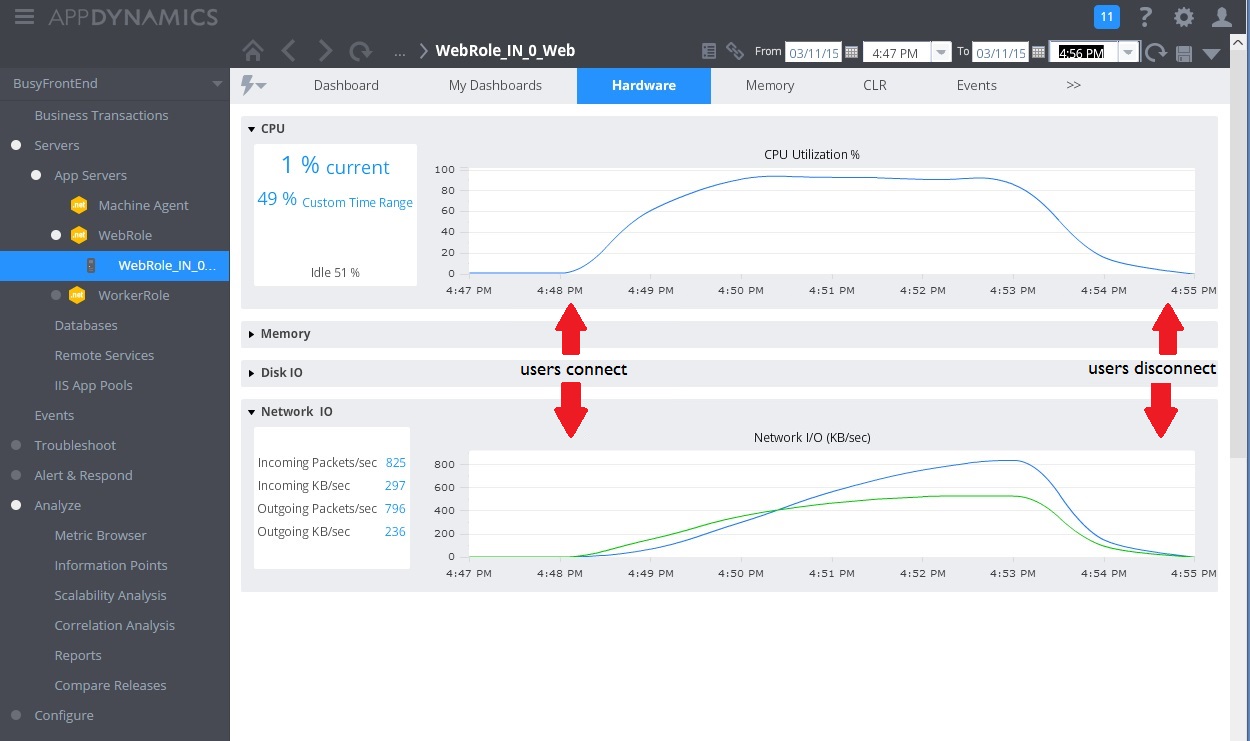
下图显示了负载测试的结果。 与前面的测试相比,所服务的请求总量有了极大的改进。
相关指南
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈