本文介绍了一种数据仓库项目的替代方法,称为探索性数据分析 (EDA)。 此方法可以减少提取、转换、加载 (ETL) 操作的困难。 这种方法的重点是生成业务见解,然后再解决建模和 ETL 任务。
体系结构

下载此体系结构的 Visio 文件。
对于 EDA,你只需关心图右侧的内容。 Azure Synapse SQL 无服务器用作数据湖文件的计算引擎。
要实现 EDA:
- T-SQL 查询直接在 Azure Synapse SQL 无服务器或 Azure Synapse Spark 中运行。
- 查询从图形查询工具(如 Power BI 或 Azure Data Studio)运行。
建议使用 Parquet 或 Delta 来保存所有数据湖数据。
可以使用任何提取、加载、转换 (ELT) 工具来实现关系图左侧的任务(数据引入)。 它对 EDA 没有影响。
组件
Azure Synapse Analytics 将数据集成、企业数据仓库和基于湖屋的大数据分析集于一身。 本解决方案的内容:
- Azure Synapse 工作区促进数据工程师、数据科学家、数据分析师和商业智能与 BI 专业人员协作,以完成 EDA 任务。
- Azure Synapse 无服务器 SQL 池使用标准 T-SQL 分析 Azure Data Lake Storage 中的非结构化和半结构化数据。
- Azure Synapse 无服务器 Apache Spark 池使用 Spark SQL、PySpark 和 Scala 等 Spark 语言在 Data Lake Storage 中执行代码第一探索。
Azure Data Lake Storage 为数据提供存储,然后由 Azure Synapse 无服务器 SQL 池进行分析数据。
Azure 机器学习向 Azure Synapse Spark 提供数据。
此解决方案中使用 Power BI 查询数据以完成 EDA。
备选方法
可以用 Synapse SQL 无服务器池来取代 Azure Databricks 或作为补充。
可以直接使用 Azure Synapse 专用 SQL 池来存储企业数据,而无需将数据湖模型与 Synapse SQL 无服务器池结合使用。 查看本文中的用例和注意事项和相关资源以决定要使用的技术。
方案详细信息
此解决方案演示了数据仓库项目中的 EDA 方法实现。 此方法可以减少 ETL 操作的困难。 这种方法的重点是生成业务见解,然后再解决建模和 ETL 任务。
可能的用例
能够从这种分析模式中获益的其他方案:
规范性分析。 思考有关数据的问题,例如“下一步最佳行动”,或者“我们下一步该做什么?”,使用数据来实现由数据驱动,而不是由直觉驱动。 数据可能是非结构化的,并且来自许多不同质量的外部来源。 你可能希望尽快使用数据来评估业务策略,而无需实际将数据加载到数据仓库中。 回答问题后,你可能会处理数据。
自助服务 ETL。 在执行数据沙盒 (EDA) 活动时执行 ETL/ELT。 转换数据并让数据产生价值。 这样做可以提高 ETL 开发人员的规模。
关于探索性数据分析
在我们更仔细地研究 EDA 的工作原理之前,值得总结一下数据仓库项目的传统方法。 传统方法如下所示:
需求收集。 记录如何处理数据。
数据建模。 确定如何将数值和属性数据建模为事实数据表和维度表。 按照传统方法,你需要在获取新数据之前执行此步骤。
ETL。 获取数据并将其转换为数据仓库的数据模型。
这些步骤可能需要数周甚至数月。 然后才能开始查询数据并解决业务问题。 只有在创建报表后,用户才能看到值。 解决方案体系结构通常类似于以下内容:
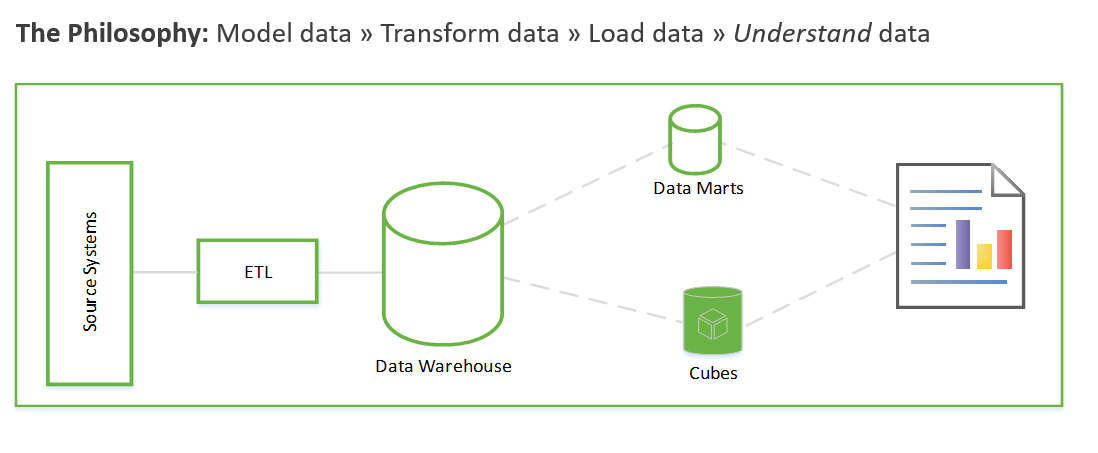
可以通过另一种方式来实现此目的,这种方式的重点是生成业务见解,然后再解决建模和 ETL 任务。 此过程类似于数据科学过程。 如下所示:
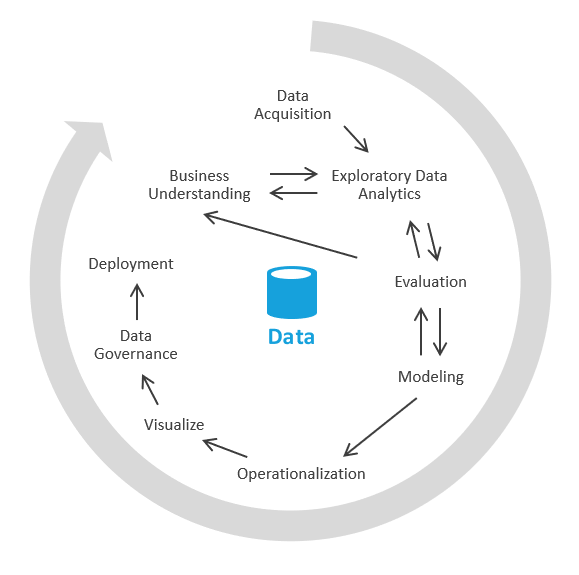
在业内中,此过程称为探索数据分析(简称 EDA)。
步骤如下:
数据采集。 首先,需要确定需要哪些数据源引入到数据湖/沙盒中。 然后,需要将这些数据引入到数据湖的登陆区。 Azure 提供了 Azure 数据工厂和 Azure 逻辑应用等工具,可以快速引入数据。
数据沙盒。 最初,业务分析师和工程师擅长通过 Azure Synapse Analytics 进行无服务器或基本 SQL 进行探索性数据分析。 在此阶段,他们尝试会使用新数据来发现业务洞察力。 EDA 是一个迭代过程。 可能需要引入更多数据、与中小企业沟通、提出更多问题或生成可视化效果。
评估。 找到业务见解后,需要评估如何处理数据。 可能希望将数据保存到数据仓库中(因此转到建模阶段)。 在其他情况下,你可能决定将数据保留在数据湖/湖中,并将其用于预测分析(机器学习算法)。 还有一些其他情况,你可能会决定使用新的见解回填记录系统。 根据这些决定,你可以更好地了解下一步需要做什么。 你可能不需要执行 ETL。
这些方法是真正的自助服务分析的核心。 通过使用数据湖和理解数据湖查询模式的查询工具(如 Azure Synapse 无服务器),可以将数据资产交给略懂 SQL 的业务人员来处理。 使用此方法可以从根本上缩短实现价值的时间,并消除与公司数据计划相关的一些风险。
注意事项
这些注意事项实施 Azure 架构良好的框架的支柱原则,即一套可用于改善工作负载质量的指导原则。 有关详细信息,请参阅 Microsoft Azure 架构良好的框架。
可用性
Azure Synapse SQL 无服务器池是一种平台即服务 (PaaS) 功能,可以满足高可用性 (HA) 和灾难恢复 (DR) 要求。
无服务器池可按需使用。 无服务器池不需要纵向扩展、纵向缩减、横向扩展、横向缩减,也不需要任何类型的管理。 无服务器池使用按查询付费模型,因此任何时候都不会有任何未使用的容量。 无服务器池适用于:
- T-SQL 的特设数据科学探索。
- 针对数据仓库实体的早期原型设计。
- 定义使用者可以使用的视图,例如,在 Power BI 中,适用于可容忍性能滞后的情况。
- 探索性数据分析
操作
Synapse SQL 无服务器使用标准的 T-SQL 进行查询和操作。 可以使用 Synapse 工作区 UI、Azure Data Studio 或 SQL Server Management Studio 作为 T-SQL 工具。
成本优化
成本优化是关于寻找减少不必要的费用和提高运营效率的方法。 有关详细信息,请参阅成本优化支柱概述。
Data Lake Storage 定价取决于存储的数据量以及使用数据的频率。 示例定价包括存储的 1 TB 数据,以及进一步的事务假设。 1 TB 是指数据湖的大小,而不是原始的旧数据库大小。
Azure Synapse Spark 池基于节点大小、实例数和运行时间的定价。 该示例假定一个小型计算节点,其利用率介于每周 5 小时到每月 40 小时之间。
Azure Synapse 无服务器 SQL 池基于处理的数据的 TB 价格定价。 该示例假定每月处理了 50 个 TB。 这个数字是指数据湖的大小,而不是原始的旧数据库大小。
作者
本文由 Microsoft 更新和维护。 它最初是由以下贡献者撰写的。
主要作者:
- Dave Wentzel | MTC 首席技术架构师
后续步骤
- 数据工程师学习路径
- 教程:Azure Synapse Analytics 入门
- 在 Azure SQL 数据库中创建单一数据库
- Azure Synapse SQL 体系结构
- 为 Azure Data Lake Storage 创建存储帐户
- Azure 事件中心快速入门 - 使用 Azure 门户创建事件中心
- 快速入门 - 使用 Azure 门户创建流分析作业
- 快速入门:Azure 机器学习入门