许多服务使用限制模式来控制其消耗的资源,从而限制其他应用程序或服务访问它们的速率。 可以使用速率限制模式来帮助避免或尽量减少与这些限制相关的限制错误,并帮助更准确地预测吞吐量。
速率限制模式适用于许多方案,但对于批处理等大规模重复性自动化任务特别有用。
上下文和问题
使用受限制服务执行大量操作可能导致流量和吞吐量增大,因为需要跟踪被拒绝的请求,然后重试这些操作。 随着操作数量的增加,限制措施可能要求多次重新发送数据,从而导致更严重的性能影响。
例如,假设在将数据引入 Azure Cosmos DB 的过程中出错时按如下方式进行简单的重试:
- 应用程序需要将 10,000 条记录引入 Azure Cosmos DB。 引入每条记录需要消耗 10 个请求单位 (RU),因此总共需要 100,000 个 RU 才能完成该作业。
- Azure Cosmos DB 实例具有 20,000 个 RU 的预配容量。
- 将所有 10,000 条记录发送到 Azure Cosmos DB。2,000 条记录写入成功,8,000 条记录被拒绝。
- 将剩余的 8,000 条记录发送到 Azure Cosmos DB。2,000 条记录写入成功,6,000 条记录被拒绝。
- 将剩余的 6,000 条记录发送到 Azure Cosmos DB。2,000 条记录写入成功,4,000 条记录被拒绝。
- 将剩余的 4,000 条记录发送到 Azure Cosmos DB。2,000 条记录写入成功,2,000 条记录被拒绝。
- 将剩余的 2,000 条记录发送到 Azure Cosmos DB。 所有记录写入成功。
引入作业已成功完成,但即使整个数据集仅包含 10,000 条记录,该作业也只能在将 30,000 条记录发送到 Azure Cosmos DB 之后才成功。
在以上示例中,还需要考虑一些额外的因素:
- 大量的错误还可能导致记录这些错误和处理生成的日志数据需要付出额外的工作。 这种欠妥的方法已处理 20,000 个错误,记录这些错误可能会造成处理、内存或存储资源成本。
- 由于不知道引入服务的限制,欠妥的方法无法对数据处理需要多长时间设定预期。 速率限制允许计算引入过程所需的时间。
解决方案
速率限制可以减少流量,并可能会通过减少在给定时间段内发送到服务的记录数量来提高吞吐量。
在一段时间后,服务可以根据不同的指标进行限制,例如:
- 操作数量(例如,每秒 20 个请求)。
- 数据量(例如,每分钟 2 GiB)。
- 相对操作成本(例如,每秒 20,000 RU)。
无论用于限制的指标如何,速率限制实施都涉及到控制在特定时间段内发送到服务的操作数量和/或大小,优化服务的使用,同时不超过其限制容量。
在 API 处理请求的速度比任何受限制引入服务允许的速度更快的情况下,需要处理好使用该服务的速度。 但是,仅将限制视为数据速率不匹配问题并简单地将引入请求缓冲到受限制服务能够赶上进度为止是有风险的。 如果应用程序在这种情况下崩溃,可能会丢失任何缓冲的数据。
为避免这种风险,请考虑将记录发送到一个可以处理完全引入速率的持久消息传递系统。 (Azure 事件中心等服务每秒可以处理数百万次操作)。 然后,可以使用一个或多个作业处理器以受限制服务的限制范围的受控速率从消息传递系统读取记录。 将记录提交到消息传递系统可以仅将在给定时间间隔内能够处理的记录取消排队,从而节省内部内存。
Azure 提供多种可与此模式配合使用的持久消息传递服务,包括:
- Azure 服务总线
- Azure 队列存储
- Azure 事件中心

发送记录时,用于释放记录的时间段的粒度可能比服务限制的时间段更精细。 系统通常根据你可以轻松理解和使用的时间跨度来设置限制。 但是,对于运行服务的计算机而言,与它处理信息的速度相比,这些时间范围可能很长。 例如,系统可能按每秒或分钟进行限制,但代码通常按照纳秒或毫秒级的粒度进行处理。
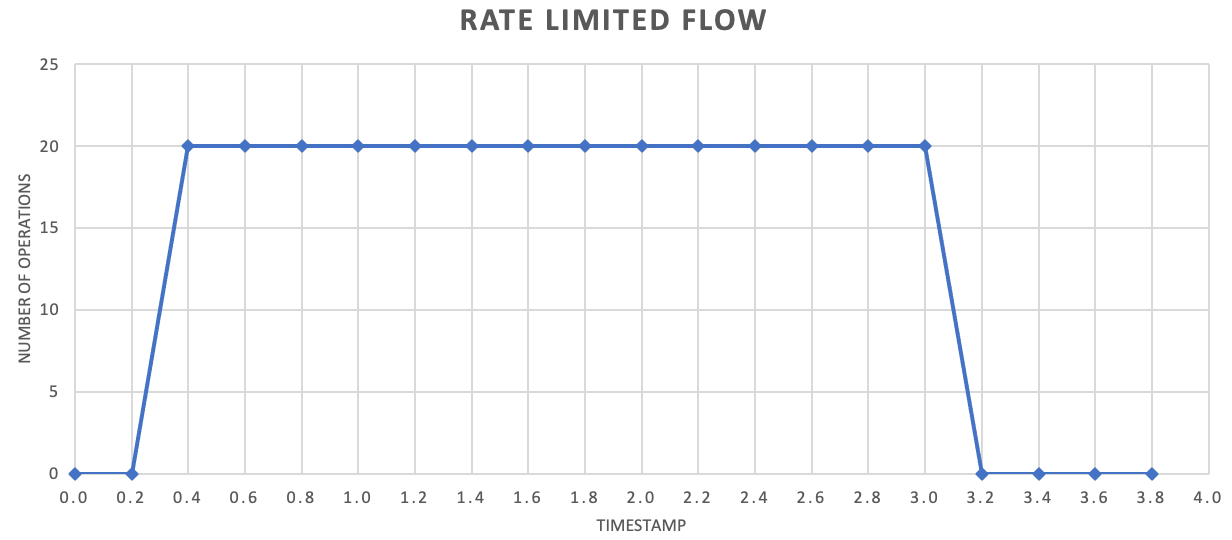
虽然不要求这样做,但我们通常建议以更高的频率发送更少量的记录,以提高吞吐量。 因此,最好不要按照每秒或每分钟释放一次的频率批处理操作,而可以采用更高的粒度来使资源消耗量(内存、CPU、网络等)以更均匀的速率波动,防止由于请求突发而导致的潜在瓶颈。 例如,如果服务允许每秒 100 次操作,则速率限制器的实施可能会通过每 200 毫秒释放 20 次操作来平衡请求,如下图所示。
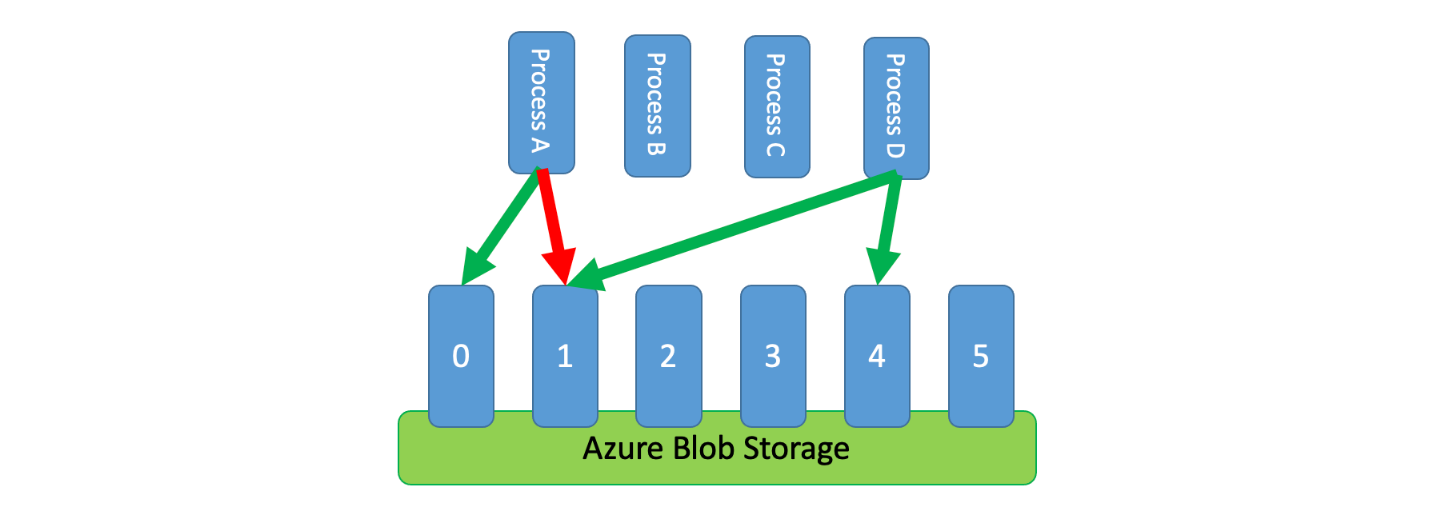
此外,有时多个未协调的进程需要共享一个受限制服务。 若要在这种情况下实施速率限制,可以对服务的容量进行逻辑分区,然后使用分布式互斥系统来管理这些分区上的排他锁。 然后,每当未协调的进程需要容量时,可以竞争这些分区上的锁。 对于进程在其上持有锁的每个分区,将为其授予一定的容量。
例如,如果受限制系统允许每秒处理 500 个请求,则你可以创建 20 个分区,每个分区每秒可以处理 25 个请求。 如果某个进程需要发出 100 个请求,它可以向分布式互斥系统请求四个分区。 系统可以授予两个分区 10 秒。 然后,该进程将速率限制为每秒 50 个请求,在两秒内完成任务,然后释放锁。
实现此模式的一种方法是使用 Azure 存储。 在这种情况下,你将为容器中的每个逻辑分区创建一个 0 字节 Blob。 然后,应用程序可以直接针对这些 Blob 获取独占租约并短时间(例如 15 秒)占有它。 为应用程序授予的每个租约可以使用该分区本有的容量。 然后,应用程序需要跟踪租用时间,以便在租用时间过期时,它可以停止使用为它授予的容量。 实现此模式时,每个进程通常会在需要容量时尝试租用随机分区。
为了进一步降低延迟,可为每个进程分配少量的独占容量。 然后,只有在需要超出其预留容量时,进程才会寻求获取共享容量的租约。
作为 Azure 存储的替代方案,还可以使用 Zookeeper、Consul、etcd、Redis/Redsync 等技术来实现这种租约管理系统。
问题和注意事项
在决定如何实现此模式时,请考虑以下几点:
- 虽然速率限制模式可以减少限制错误的数量,但应用程序仍需要正确处理可能发生的任何限制错误。
- 如果应用程序有多个工作流访问同一个受限制服务,你需要将所有这些工作流集成到速率限制策略中。 例如,你可能支持将记录批量加载到数据库中,但同时支持查询该数据库中的记录。 确保通过同一速率限制机制控制所有工作流即可管理容量。 或者,可为每个工作流保留不同的容量池。
- 可以在多个应用程序中使用受限制服务。 在某些(但不是所有)情况下,可以协调这种用法(如上所示)。 如果你发现限制错误超过了预期数量,这可能表明访问服务的应用程序之间发生了争用。 如果是这样,可能需要考虑暂时降低速率限制机制实施的吞吐量,直到其他应用程序的使用量降低。
何时使用此模式
使用此模式可以:
- 减少受限制服务引发的限制错误。
- 减少流量(相较于欠妥的错误重试方法)。
- 仅在有容量可以处理记录时才将记录取消排队,从而减少内存消耗。
工作负载设计
架构师应评估如何在其工作负载的设计中使用“速率限制模式”,以解决 Azure Well-Architected Framework 支柱中涵盖的目标和原则。 例如:
| 支柱 | 此模式如何支持支柱目标 |
|---|---|
| 可靠性设计决策有助于工作负荷在发生故障后复原,并确保它在发生故障后恢复到正常运行状态。 | 当服务希望避免过度使用时,这种策略通过确认并遵守与服务通信的限制和成本来保护客户端。 - RE:07 自我保护 |
与任何设计决策一样,请考虑对可能采用此模式引入的其他支柱的目标进行权衡。
示例
以下示例应用程序允许用户向 API 提交各种类型的记录。 每种记录类型都有一个执行以下步骤的独特作业处理器:
- 验证
- 扩充
- 将记录插入数据库
应用程序的所有组件(API、作业处理器 A 和作业处理器 B)都是可以独立缩放的单独进程。 这些进程不直接相互通信。
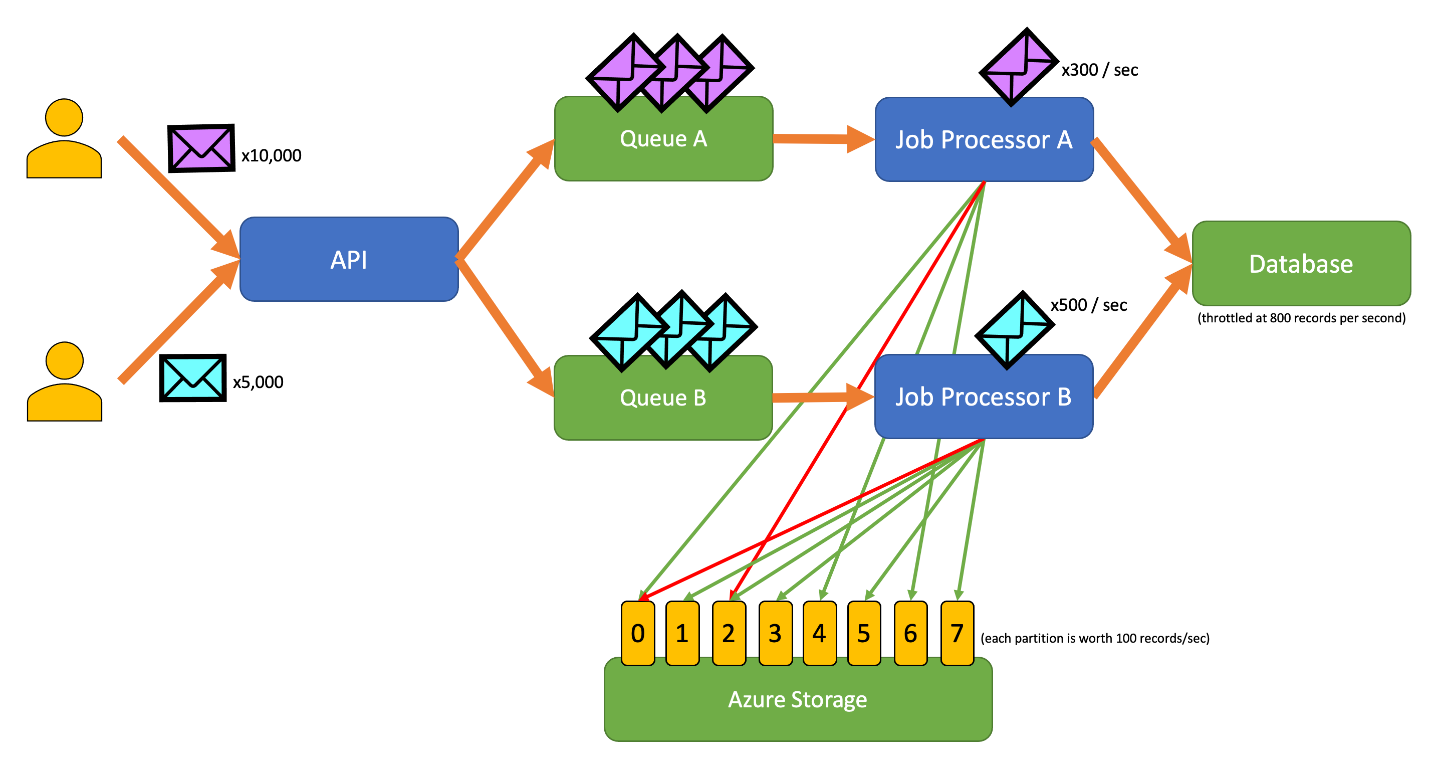
此图中整合了以下工作流:
- 用户向 API 提交 10,000 条 A 类型记录。
- API 将这 10,000 条记录排入队列 A。
- 用户向 API 提交 5,000 条 B 类型记录。
- API 将这 5,000 条记录排入队列 B。
- 作业处理器 A 发现队列 A 中包含记录,并尝试在 Blob 2 上获取独占租约。
- 作业处理器 B 发现队列 B 中包含记录,并尝试在 Blob 2 上获取独占租约。
- 作业处理器 A 无法获取租约。
- 作业处理器 B 在 Blob 2 上获取 15 秒的租约。 它现在可以将对数据库的请求速率限制为每秒 100 个。
- 作业处理器 B 将队列 B 中的 100 条记录取消排队并写入这些记录。
- 一秒钟过去。
- 作业处理器 A 发现队列 A 中包含更多记录,并尝试在 Blob 6 上获取独占租约。
- 作业处理器 B 发现队列 B 中包含更多记录,并尝试在 Blob 3 上获取独占租约。
- 作业处理器 A 在 Blob 6 上获取 15 秒的租约。 它现在可以将对数据库的请求速率限制为每秒 100 个。
- 作业处理器 B 在 Blob 3 上获取 15 秒的租约。 它现在可以将对数据库的请求速率限制为每秒 200 个。 (它还占有 Blob 2 的租约。)
- 作业处理器 A 将队列 A 中的 100 条记录取消排队并写入这些记录。
- 作业处理器 B 将队列 B 中的 200 条记录取消排队并写入这些记录。
- 一秒钟过去。
- 作业处理器 A 发现队列 A 中包含更多记录,并尝试在 Blob 0 上获取独占租约。
- 作业处理器 B 发现队列 B 中包含更多记录,并尝试在 Blob 1 上获取独占租约。
- 作业处理器 A 在 Blob 0 上获取 15 秒的租约。 它现在可以将对数据库的请求速率限制为每秒 200 个。 (它还占有 Blob 6 的租约。)
- 作业处理器 B 在 Blob 1 上获取 15 秒的租约。 它现在可以将对数据库的请求速率限制为每秒 300 个。 (它还占有 Blob 2 和 3 的租约。)
- 作业处理器 A 将队列 A 中的 200 条记录取消排队并写入这些记录。
- 作业处理器 B 将队列 B 中的 300 条记录取消排队并写入这些记录。
- 依此类推...
15 秒后,上述一个或两个作业仍未完成。 随着租约过期,处理器还应会减少它取消排队并写入的请求数。
 此模式可通过不同的编程语言实现:
此模式可通过不同的编程语言实现:
相关资源
实施此模式时,可能也会与以下模式和指南相关:
基于队列的负载调控与速率限制模式类似,但两者在几个关键方面有所不同:
- 速率限制不一定需要使用队列来管理负载,但它确实需要利用持久消息传递服务。 例如,速率限制模式可以利用 Apache Kafka 或 Azure 事件中心等服务。
- 速率限制模式在分区上引入了分布式互斥系统的概念,它允许你管理与同一受限制服务通信的多个未协调进程的容量。
- 每当服务之间存在性能不匹配或需要提高复原能力时,适合使用基于队列的负载调控模式。 因此,这种模式比速率限制使用更广泛,它更具体地考虑到了如何有效访问受限制的服务。