本文介绍开发团队如何使用指标来查找瓶颈并提高分布式系统的性能。 本文基于我们对示例应用程序执行的实际负载测试。 该应用程序来自用于微服务的 Azure Kubernetes 服务 (AKS) 基线,附带一个用于生成结果的 Visual Studio 负载测试项目。
本文是一系列文章的其中一篇。 请在此处阅读第一部分。
方案:调用多个后端服务以检索信息,然后聚合结果。
此方案涉及无人机交付应用程序。 客户端可以查询 REST API 以获取其最新的发票信息。 发票包含客户的交付、包裹和无人机总利用率的摘要。 此应用程序使用在 AKS 上运行的微服务体系结构,发票所需的信息分布在多个微服务中。
将由应用程序实现网关聚合模式,而不是由客户端直接调用每个服务。 使用此模式,客户端将向网关服务发出单个请求。 网关转而并行调用后端服务,然后将结果聚合成单个响应有效负载。
测试 1:基线性能
为了建立基线,开发团队从分步负载测试开始,在总共 8 分钟的时间内将负载从一个模拟用户增加到 40 个用户。 下图摘自 Visual Studio,显示了结果。 紫线显示用户负载,橙线显示吞吐量(每秒平均请求数)。
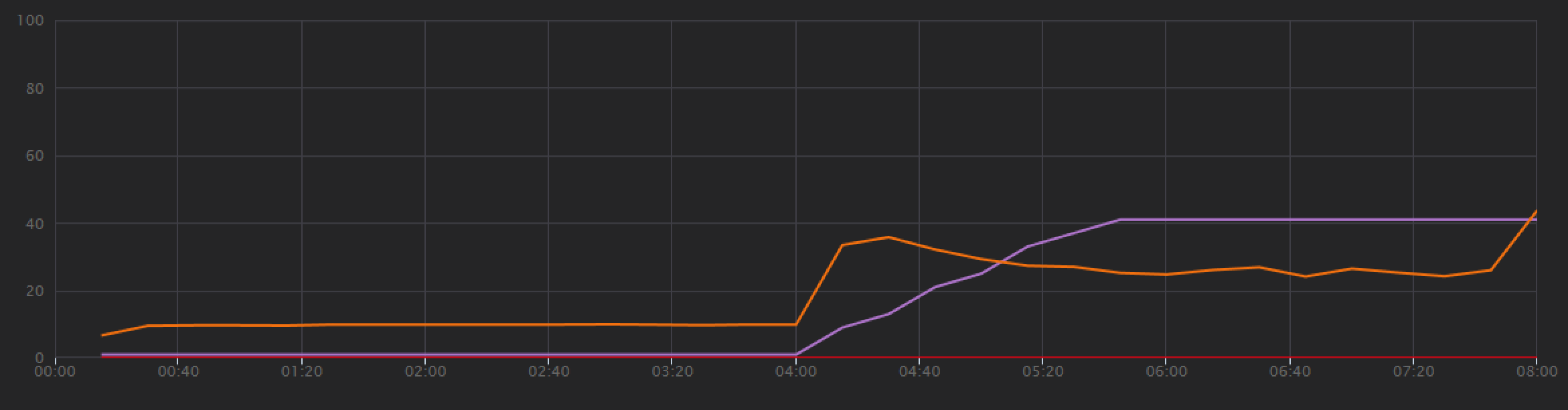
图表底部的红线显示没有错误返回到客户端,这令人鼓舞。 但是,平均吞吐量在测试进行到大约一半时达到峰值,然后下降,即使负载一直在增加。 这表示后端跟不上。 当系统开始达到资源限制时,此处看到的模式很常见 - 达到最大吞吐量后,吞吐量实际上会大幅下降。 资源争用、暂时性错误或出现异常的速率的增加都可能导致此模式。
让我们深入探索监视数据,了解系统中发生的情况。 下一个图表取自 Application Insights。 它显示从网关到后端服务的 HTTP 调用的平均持续时间。
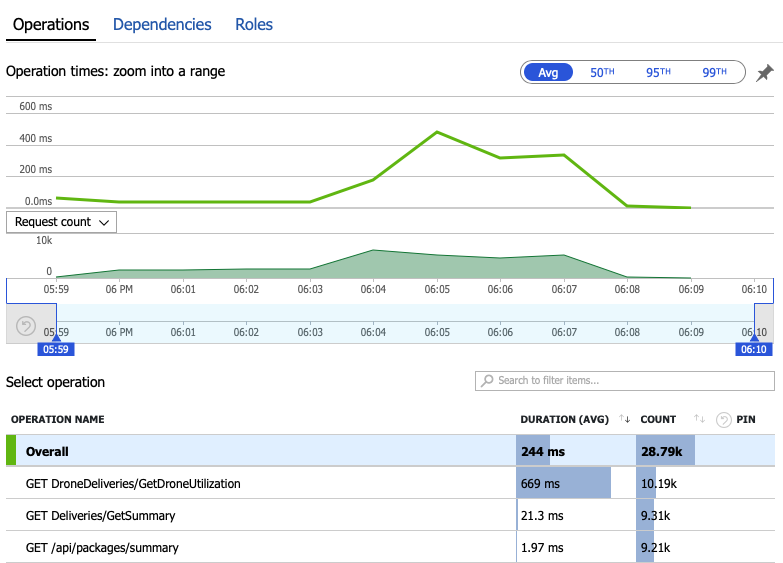
此图表显示,就平均值来说,一个操作(具体说来就是 GetDroneUtilization)花费的时间要长得多 - 相差一个数量级。 网关以并行方式发出这些调用,因此,最慢的操作决定了完成整个请求所需的时间。
显然,下一步是深入探索 GetDroneUtilization 操作,查找任何瓶颈。 一种可能性是资源耗尽。 也许这个特定的后端服务在耗尽 CPU 或内存。 对于 AKS 群集,此信息可通过 Azure Monitor 容器见解功能在 Azure 门户中获取。 下图显示了群集级别的资源利用率:

此屏幕截图显示了平均值和最大值。 请不要只查看平均值,因为平均值可能隐藏数据中的峰值。 在这里,平均 CPU 利用率保持在 50% 以下,但有几个峰值达到 80%。 这与容量接近,但仍在允许范围内。 其他因素导致瓶颈。
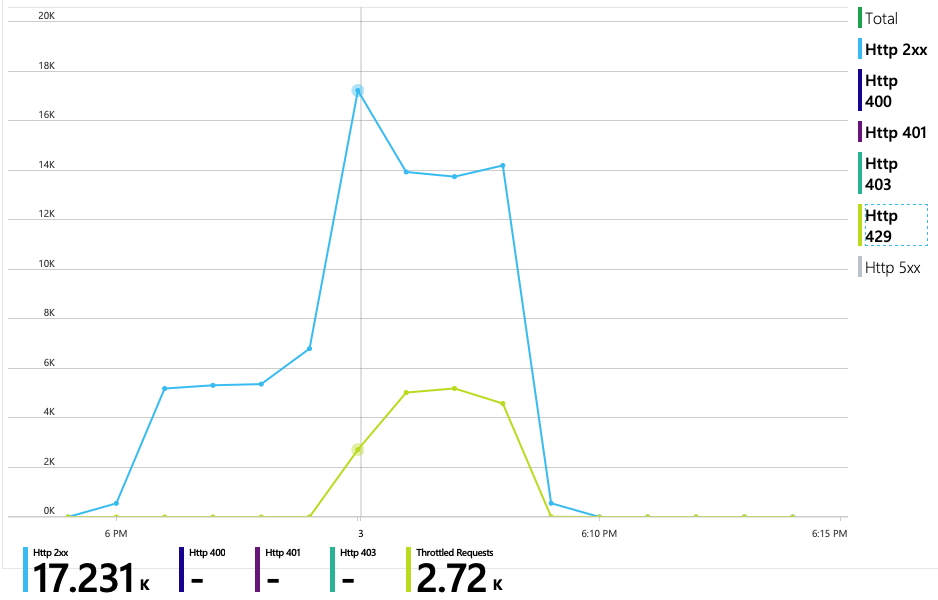
下一图表揭示了真正的“罪魁祸首”。 此图表显示了交付服务的后端数据库(在本例中为 Azure Cosmos DB)中的 HTTP 响应代码。 蓝线表示成功代码 (HTTP 2xx),而绿线则表示 HTTP 429 错误。 HTTP 429 返回代码表示 Azure Cosmos DB 在暂时限制请求,因为调用方消耗的资源单位 (RU) 比预配的多。
为了获得进一步的见解,开发团队使用了 Application Insights 来查看具有代表性的请求示例的端到端遥测数据。 下面是一个实例:
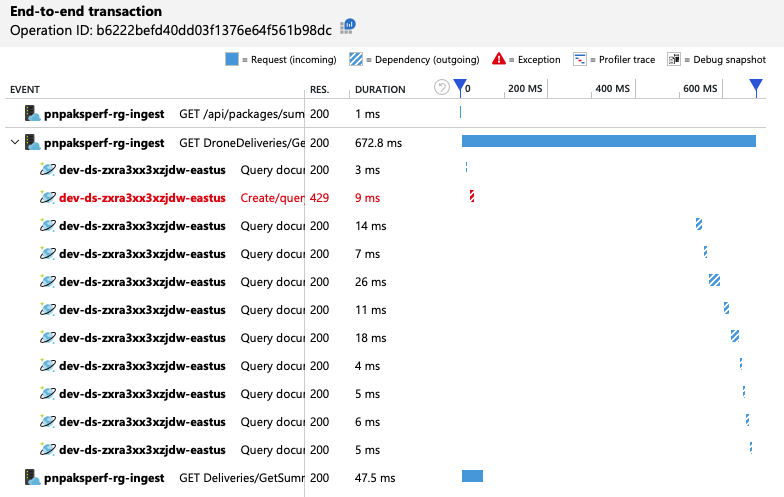
此视图显示与单个客户端请求相关的调用,以及计时信息和响应代码。 顶级调用是从网关到后端服务的。 对 GetDroneUtilization 的调用已展开,可以显示对外部依赖项(在本例中为 Azure Cosmos DB)的调用。 红色调用返回了 HTTP 429 错误。
请注意 HTTP 429 错误与下一次调用之间的较大差距。 当 Azure Cosmos DB 客户端库收到 HTTP 429 错误时,它会自动退让,等待重试该操作。 此视图显示此操作耗时 672 毫秒,大部分时间都在等待重试 Azure Cosmos DB。
下面是此分析的另一个有趣的图。 它显示每个物理分区的 RU 消耗量与每个物理分区的预配 RU 数:

若要搞清楚此图,需要了解 Azure Cosmos DB 如何管理分区。 Azure Cosmos DB 中的集合可以有分区键。 每个可能的键值定义集合中数据的逻辑分区。 Azure Cosmos DB 将这些逻辑分区分布到一个或多个物理分区。 物理分区的管理由 Azure Cosmos DB 自动处理。 当你存储更多数据时,Azure Cosmos DB 可能会将逻辑分区移到新的物理分区中,以便将负载分布到多个物理分区中。
对于此负载测试,我们为 Azure Cosmos DB 集合预配了 900 RU。 此图表显示每个物理分区 100 RU,这意味着总共有 9 个物理分区。 尽管 Azure Cosmos DB 会自动处理对物理分区进行的分片,但知道分区计数可以深入了解性能。 开发团队以后会使用此信息,因为他们会继续进行优化。 如果蓝线与紫色水平线相交,则表明 RU 消耗量已超过预配的 RU。 此时 Azure Cosmos DB 将开始限制调用数。
测试 2:增加资源单位
对于第二次负载测试,团队将 Azure Cosmos DB 集合从 900 RU 横向扩展到了 2500 RU。 吞吐量从 19 个请求/秒增加到 23 个请求/秒,平均延迟从 669 毫秒下降到 569 毫秒。
| 指标 | 测试 1 | 测试 2 |
|---|---|---|
| 吞吐量(请求/秒) | 19 | 23 |
| 平均延迟 (ms) | 669 | 569 |
| 成功的请求 | 9800 | 11000 |
这些不是巨大的增益,但随着时间的推移,查看图表时你会发现一个更完整的图片:
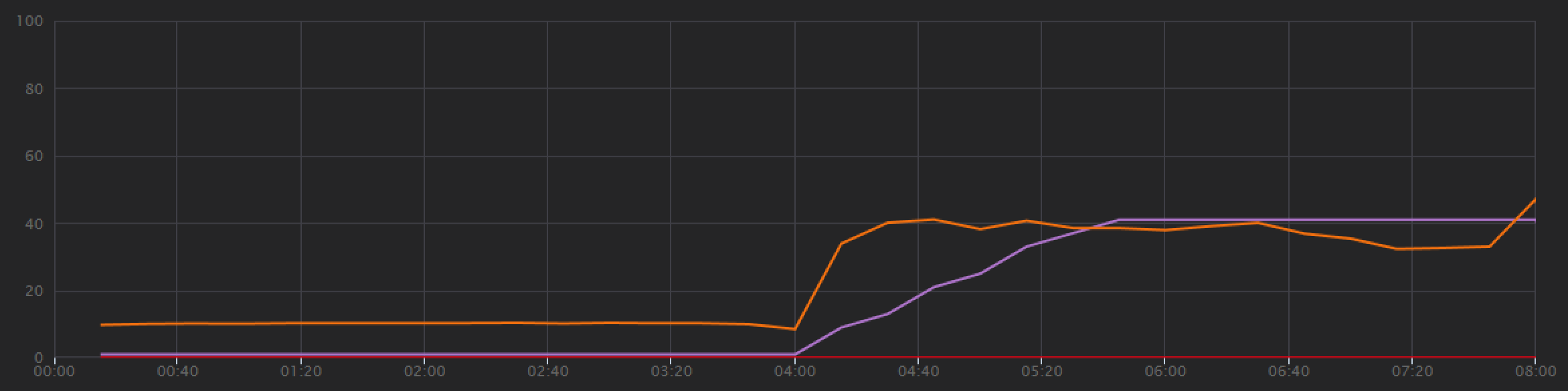
上次测试显示吞吐量在出现初始峰值后会出现急剧下降的情况,而此次测试则显示吞吐量更一致。 但是,最大吞吐量不会显著增加。
对 Azure Cosmos DB 的所有请求都返回了 2xx 状态,HTTP 429 错误消失:
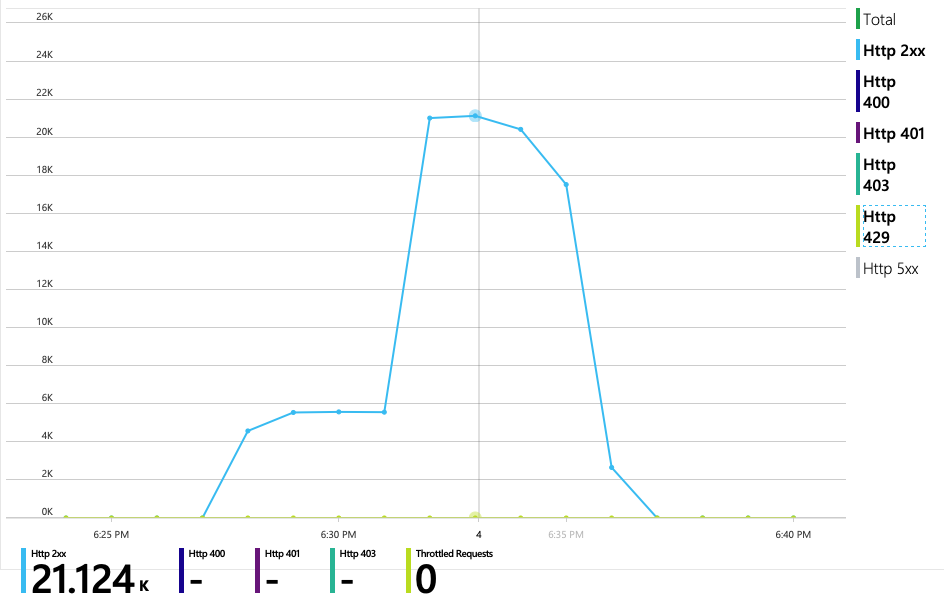
RU 消耗与预配 RU 图显示有大量空余空间。 每个物理分区大约有 275 RU,负载测试达到的峰值为每秒消耗大约 100 RU。
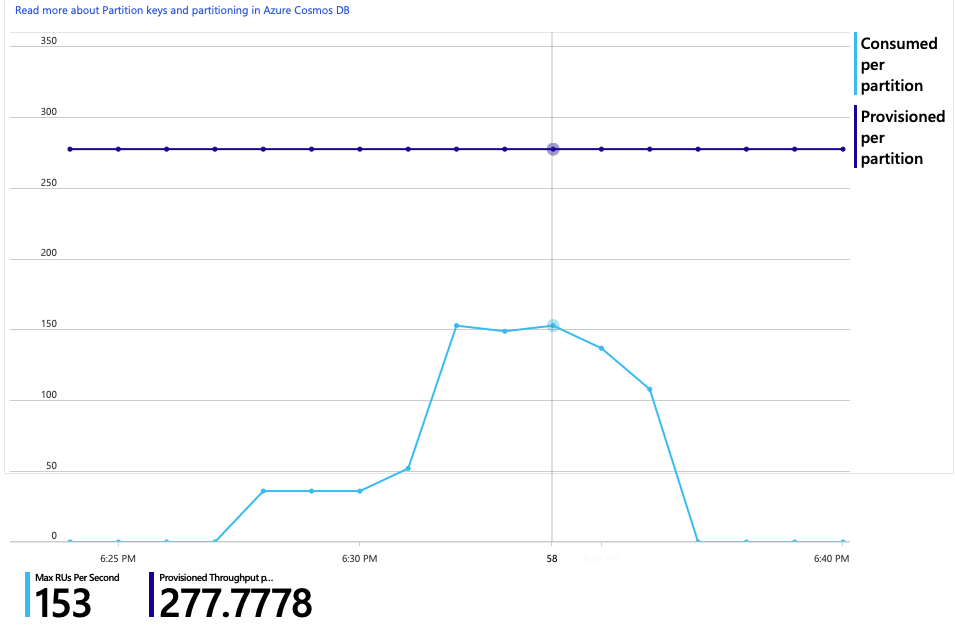
另一个有趣的指标是每次成功操作时完成的对 Azure Cosmos DB 的调用次数:
| 指标 | 测试 1 | 测试 2 |
|---|---|---|
| 每个操作的调用数 | 11 | 9 |
假设没有错误,调用数应与实际查询计划匹配。 在本例中,操作涉及一个跨分区查询,该查询命中所有 9 个物理分区。 第一个负载测试中的值较高,反映了返回 429 错误的调用数。
此指标是通过运行自定义 Log Analytics 查询来计算的:
let start=datetime("2020-06-18T20:59:00.000Z");
let end=datetime("2020-07-24T21:10:00.000Z");
let operationNameToEval="GET DroneDeliveries/GetDroneUtilization";
let dependencyType="Azure DocumentDB";
let dataset=requests
| where timestamp > start and timestamp < end
| where success == true
| where name == operationNameToEval;
dataset
| project reqOk=itemCount
| summarize
SuccessRequests=sum(reqOk),
TotalNumberOfDepCalls=(toscalar(dependencies
| where timestamp > start and timestamp < end
| where type == dependencyType
| summarize sum(itemCount)))
| project
OperationName=operationNameToEval,
DependencyName=dependencyType,
SuccessRequests,
AverageNumberOfDepCallsPerOperation=(TotalNumberOfDepCalls/SuccessRequests)
总之,第二个负载测试显示了改进。 但是,GetDroneUtilization 操作所花的时间仍比下一个最慢的操作长出大约一个数量级。 查看端到端事务有助于了解原因:
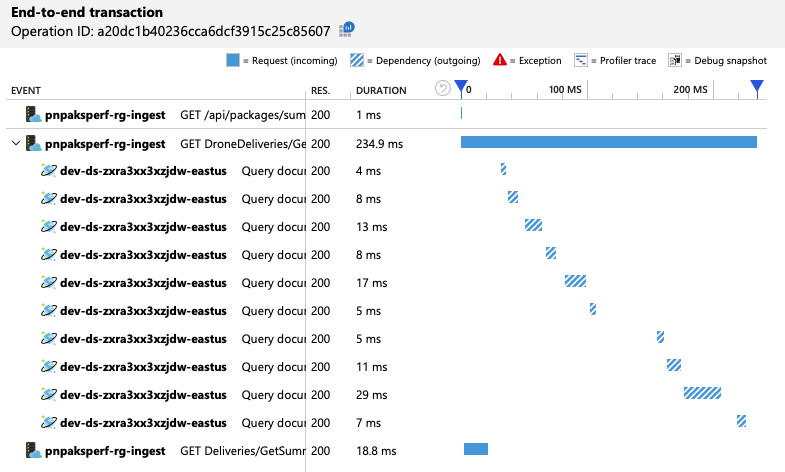
如前所述,GetDroneUtilization 操作涉及对 Azure Cosmos DB 的跨分区查询。 这意味着 Azure Cosmos DB 客户端必须向每个物理分区扇出查询并收集结果。 正如端到端事务视图所示,这些查询在以串行方式执行。 操作所用时间是所有查询所用时间的总和 - 只有在数据的大小增加且添加了更多物理分区的情况下,此问题才会凸显出来。
测试 3:并行查询
根据前面的结果,若要降低延迟,一种显而易见的方法是以并行方式发出查询。 Azure Cosmos DB 客户端 SDK 有一项控制最大并行度的设置。
| 值 | 说明 |
|---|---|
| 0 | 无并行(默认设置) |
| > 0 | 最大并行调用数 |
| -1 | 客户端 SDK 会选择最佳并行度 |
对于第三次负载测试,此设置已从 0 更改为 -1。 下表汇总了结果:
| 指标 | 测试 1 | 测试 2 | 测试 3 |
|---|---|---|---|
| 吞吐量(请求/秒) | 19 | 23 | 42 |
| 平均延迟 (ms) | 669 | 569 | 215 |
| 成功的请求 | 9800 | 11000 | 20000 |
| 限制的请求数 | 2720 | 0 | 0 |
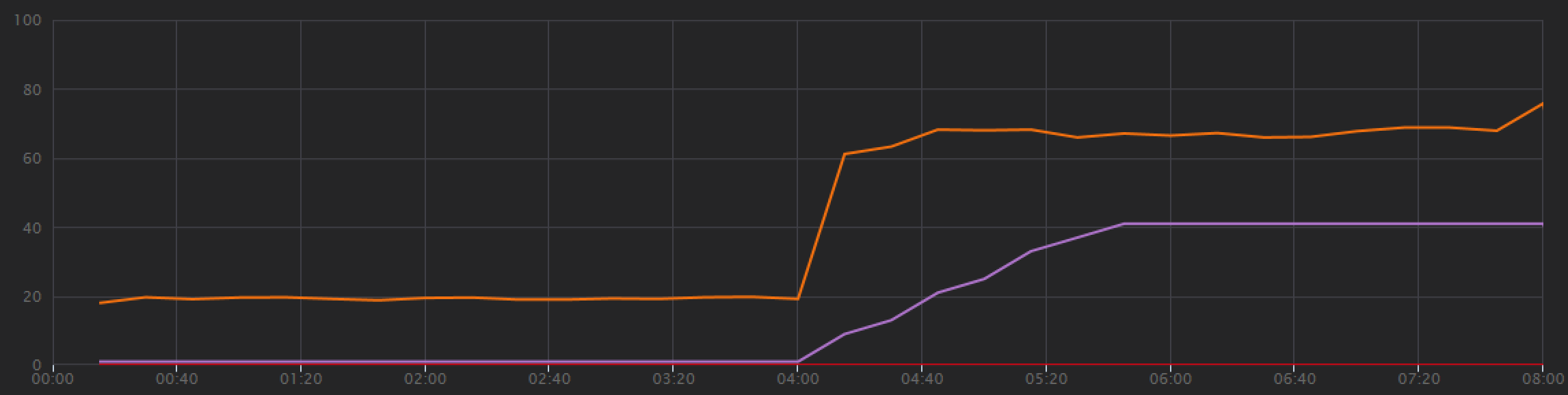
从负载测试图可以看出,不仅总体吞吐量要高得多(橙线),而且吞吐量也与负载保持同步(紫线)。
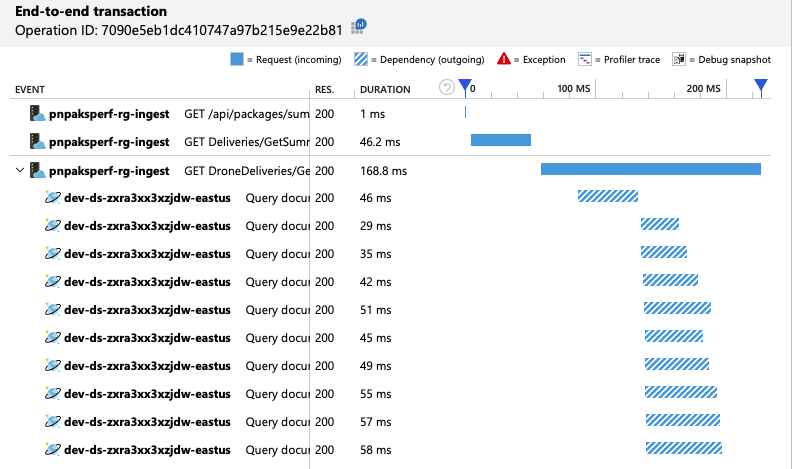
可以通过查看端到端事务视图来验证 Azure Cosmos DB 客户端是否在并行发出查询:
有趣的是,增加吞吐量的副作用是每秒消耗的 RU 数也会增加。 尽管 Azure Cosmos DB 在此测试期间未限制任何请求,但消耗量接近预配的 RU 限制:
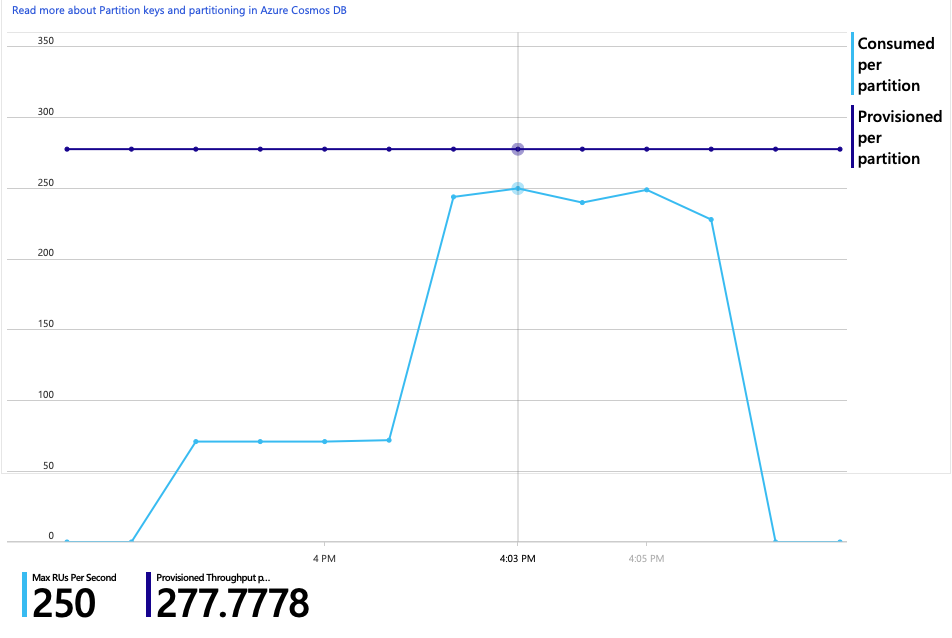
此图可能是进一步横向扩展数据库的信号。 但是,事实证明,我们可以改为优化查询。
步骤 4:优化查询
上一负载测试在延迟和吞吐量方面表现出更好的性能。 平均请求延迟降低了 68%,吞吐量增加了 220%。 但是,跨分区查询是一个问题。
跨分区查询的问题是,你为每个分区的 RU 支付费用。 如果查询只是偶尔运行(例如每小时一次),则它可能无关紧要。 但是,你在看到涉及跨分区查询的读取密集型工作负荷时,都应看到是否可以通过包括分区键来优化查询。 (可能需要重新设计集合才能使用不同的分区键。)
下面是此特定方案的查询:
SELECT * FROM c
WHERE c.ownerId = <ownerIdValue> and
c.year = <yearValue> and
c.month = <monthValue>
此查询选择与特定所有者 ID 和月份/年份匹配的记录。 在原始设计中,这些属性都不是分区键。 那要求客户端将查询扇出到每个物理分区并收集结果。 为了提高查询性能,开发团队更改了设计,使所有者 ID 成为集合的分区键。 这样,查询就可以面向特定的物理分区。 (Azure Cosmos DB 会自动处理此情况;你无需管理分区键值与物理分区之间的映射。)
将集合切换到新的分区键后,RU 消耗量有了显著改善,这样的直接结果就是成本降低。
| 指标 | 测试 1 | 测试 2 | 测试 3 | 测试 4 |
|---|---|---|---|---|
| 每个操作的 RU 数 | 29 | 29 | 29 | 3.4 |
| 每个操作的调用数 | 11 | 9 | 10 | 1 |
端到端事务视图显示查询仅读取一个物理分区,这与预测相符:
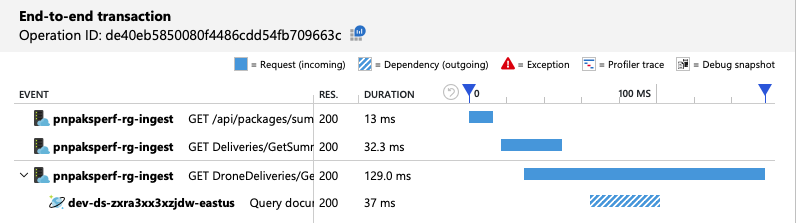
负载测试显示改进的吞吐量和延迟:
| 指标 | 测试 1 | 测试 2 | 测试 3 | 测试 4 |
|---|---|---|---|---|
| 吞吐量(请求/秒) | 19 | 23 | 42 | 59 |
| 平均延迟 (ms) | 669 | 569 | 215 | 176 |
| 成功的请求 | 9800 | 11000 | 20000 | 29000 |
| 限制的请求数 | 2720 | 0 | 0 | 0 |
性能提升的结果是节点 CPU 利用率变得非常高:
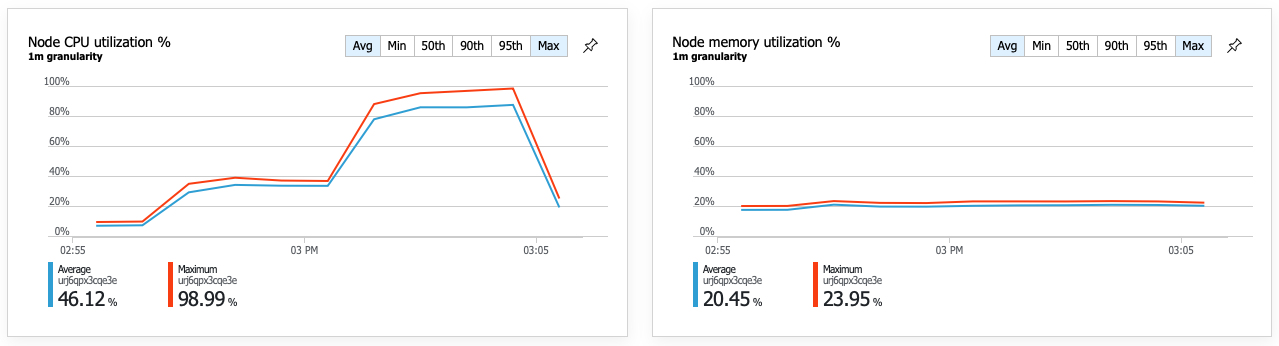
负载测试快结束时,平均 CPU 利用率达到约 90%,最大 CPU 利用率达到 100%。 此指标指示 CPU 是系统中的下一个瓶颈。 如果需要更高的吞吐量,下一步可能是将交付服务横向扩展到更多实例。
摘要
对于此方案,已确定以下瓶颈:
- 由于预配的 RU 不足,Azure Cosmos DB 限制请求数。
- 以串行方式查询多个数据库分区导致高延迟。
- 跨分区查询效率低,因为查询不包含分区键。
此外,在规模扩大时,CPU 利用率被确定为潜在瓶颈。 为了诊断这些问题,开发团队查看了以下内容:
- 负载测试的延迟和吞吐量。
- Azure Cosmos DB 错误和 RU 消耗。
- Application Insight 中的端到端事务视图。
- Azure Monitor 容器见解中的 CPU 和内存利用率。
后续步骤
查看性能对立模式