本文介绍开发团队如何使用指标来查找瓶颈并提高分布式系统的性能。 本文基于我们对示例应用程序执行的实际负载测试。 应用程序来自微服务的 Azure Kubernetes 服务 (AKS) 基线。
本文是一系列文章的其中一篇。 请在此处阅读第一部分。
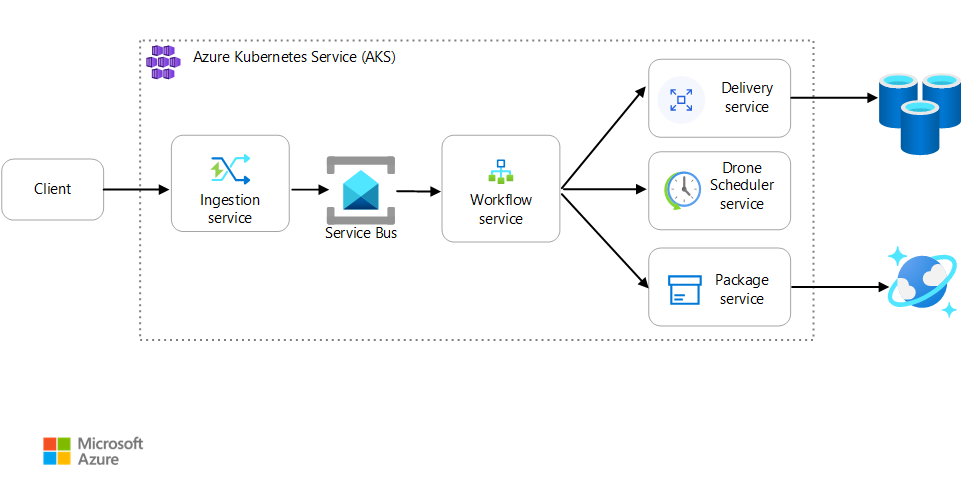
方案:客户端应用程序启动涉及多个步骤的业务事务。
此方案涉及在 AKS 上运行的无人机交付应用程序。 客户使用 Web 应用安排无人机交付。 每个事务都需要多个步骤,这些步骤由后端单独的微服务执行:
- 交付服务管理交付。
- 无人机计划程序服务安排无人机交付。
- 包服务管理包。
还有另外两种服务:接受客户端请求并将其放入队列进行处理的引入服务,以及协调工作流中步骤的工作流服务。
有关此方案的详细信息,请参阅设计微服务体系结构。
测试 1:基线
对于第一次负载测试,团队创建了六节点的 AKS 部署,并部署了每个微服务的三个副本。 负载测试是单步负载测试,从两个模拟用户开始,逐渐增加到 40 个模拟用户。
| 设置 | 值 |
|---|---|
| 群集节点 | 6 |
| Pod | 每个服务 3 个 |
下图显示了负载测试的结果,如 Visual Studio 中所示。 紫色线绘制用户负载,橙色线绘制总请求。
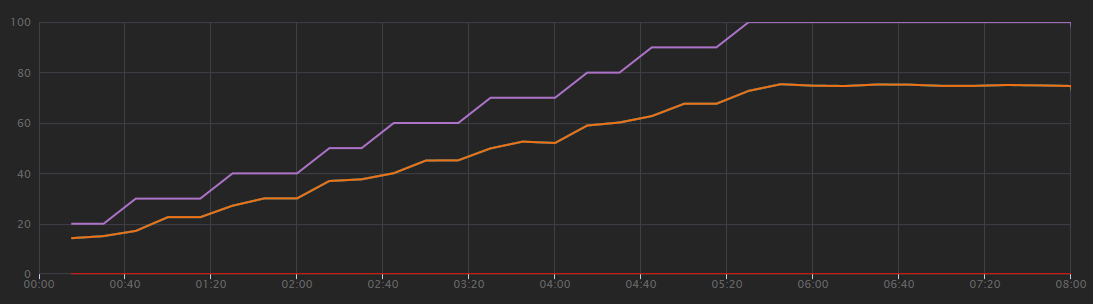
关于此方案,首先要认识到的是,每秒客户端请求数并不是有用的性能指标。 这是因为应用程序异步处理请求,所以客户端立即得到响应。 响应代码始终为 HTTP 202(已接受),这表示已接受请求,但尚未完成处理。
真正需要了解的是后端是否跟上请求率。 服务总线队列可以吸收峰值,但如果后端无法处理持续负载,则处理将越来越落后。
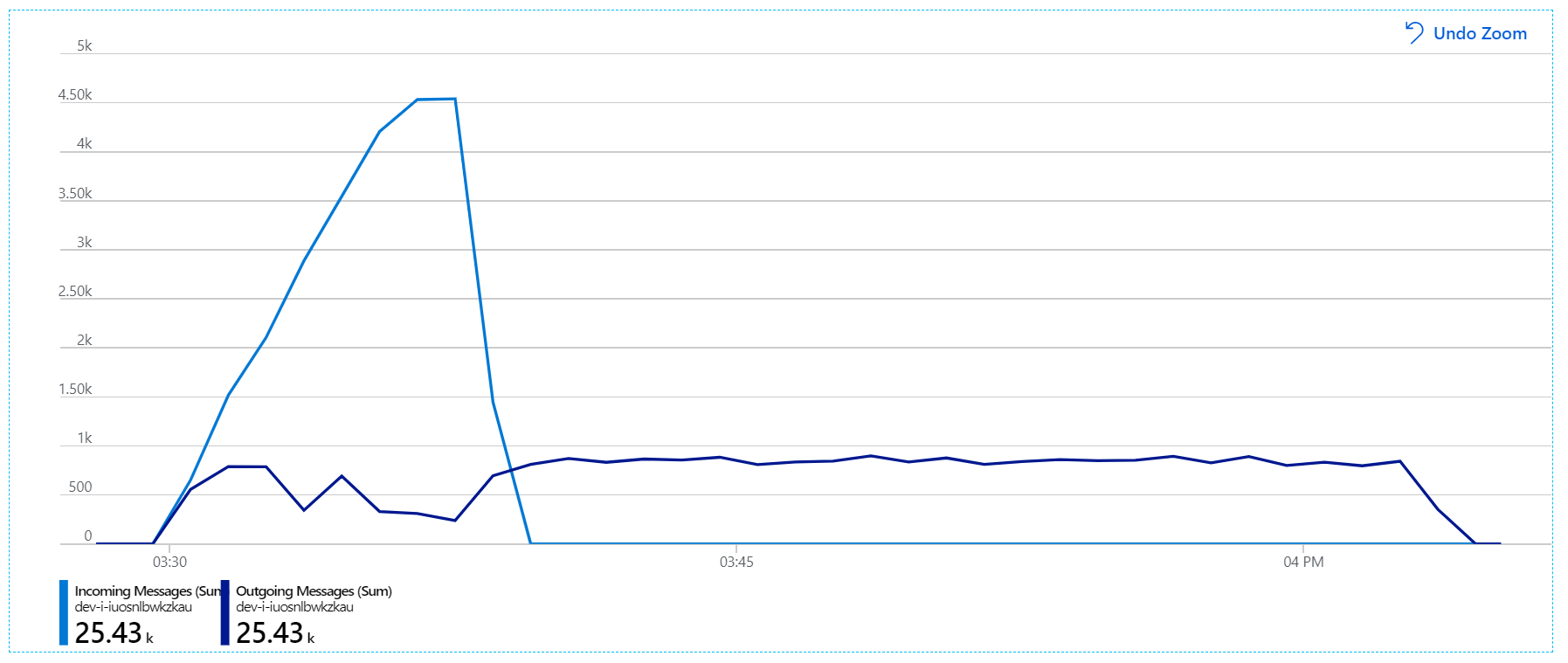
此图信息更丰富。 它绘制了服务总线队列上传入和传出消息的数量。 传入消息显示为浅蓝色,传出消息显示为深蓝色:
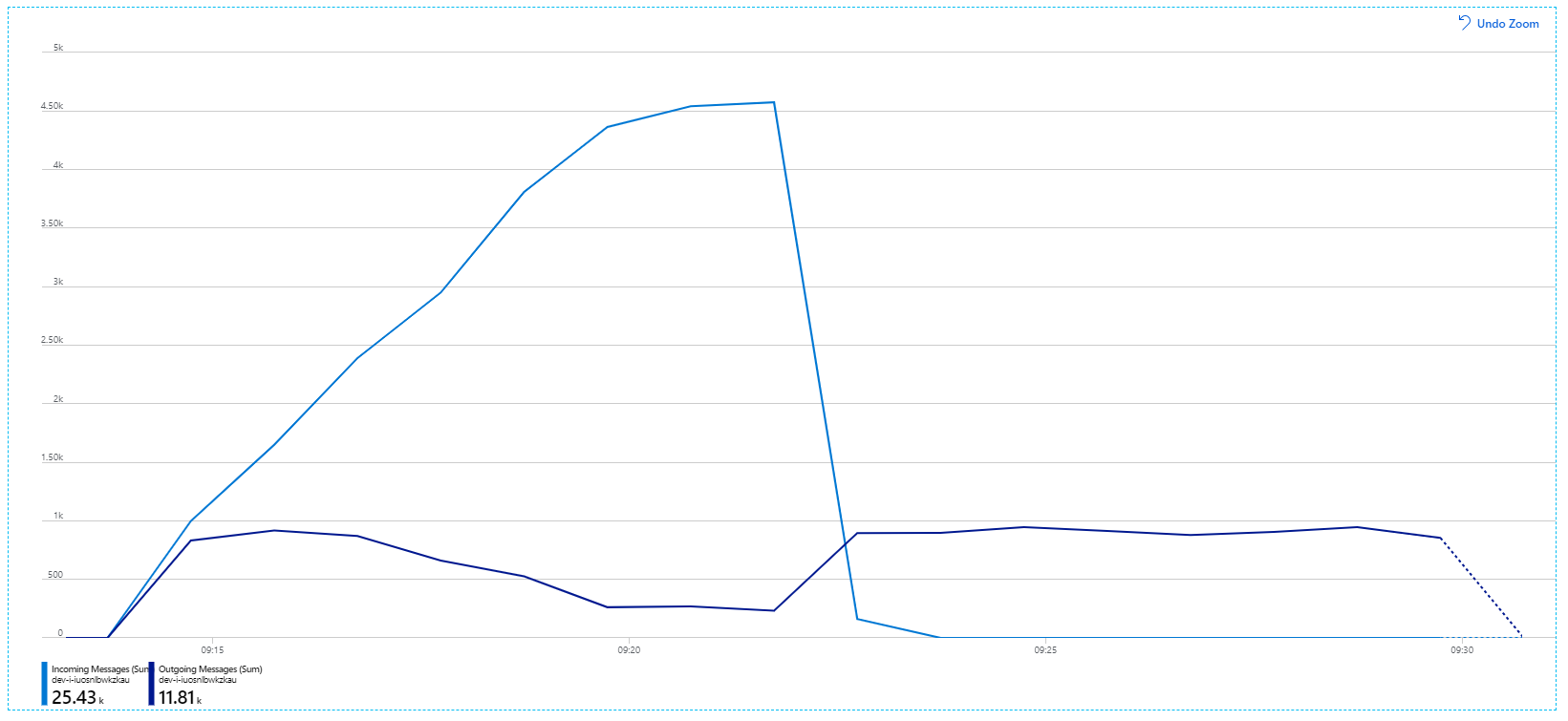
此图表显示传入消息的速率增加,达到峰值,然后在负载测试结束时降至零。 但传出消息的数量在测试早期达到峰值,然后实际下降。 这表示处理请求的工作流服务无法跟上。 即使在负载测试结束后(图中 9:22 左右),消息仍在处理中,因为工作流服务继续排出队列。
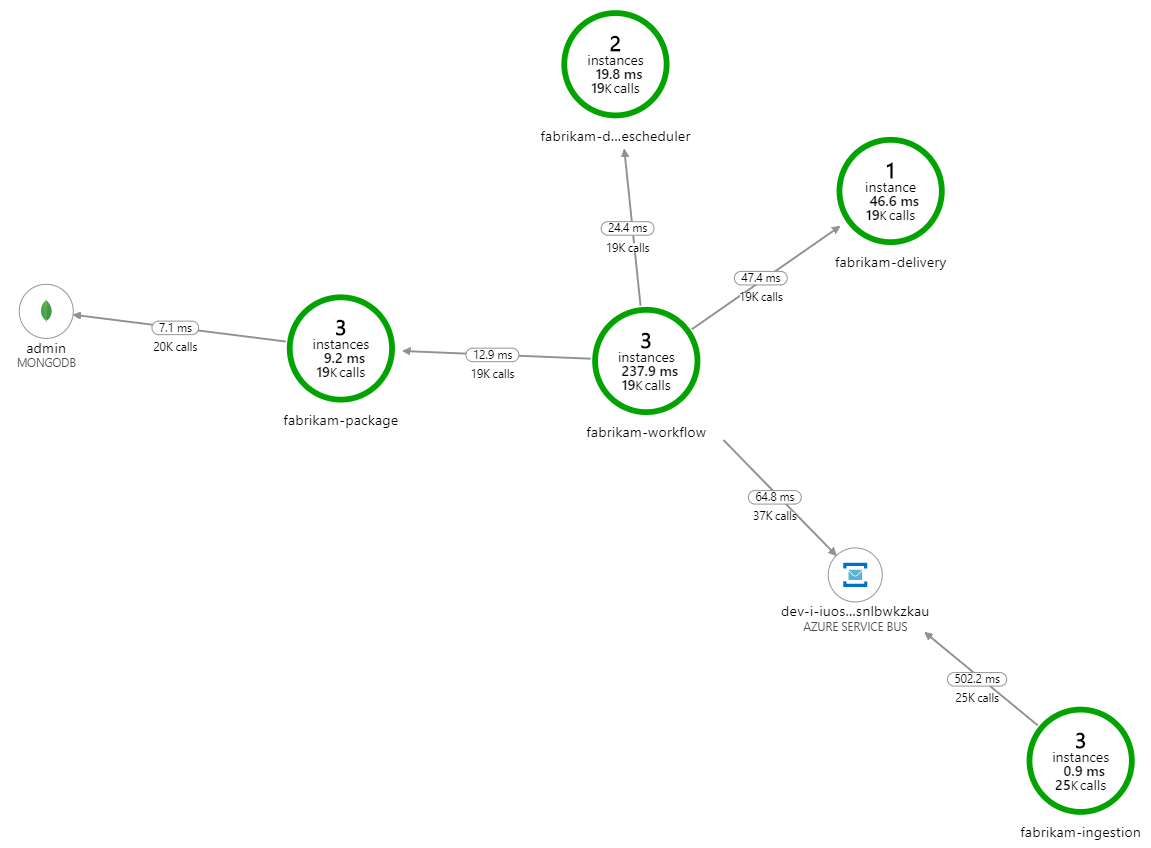
是什么减缓了处理速度? 首先要查找的是可能表明系统问题的错误或异常。 Azure Monitor 中的应用映射显示组件之间的调用图,是发现问题并单击以获取更多详细信息的快速方法。
果不其然,应用程序映射显示工作流服务正在从交付服务中获取错误:
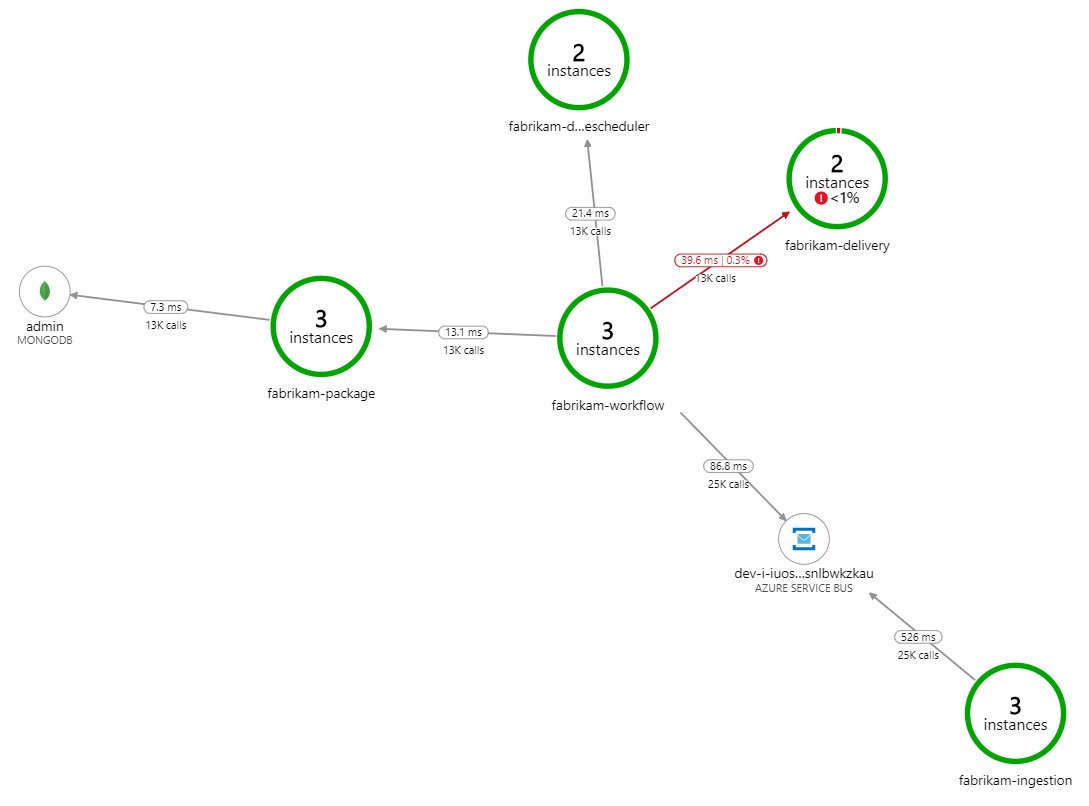
要查看更多详细信息,可以在图中选择节点,然后单击进入端到端事务视图。 在这种情况下,它显示交付服务正在返回 HTTP 500 错误。 错误消息表示,由于 Azure Cache for Redis 中的内存限制,正在引发异常。
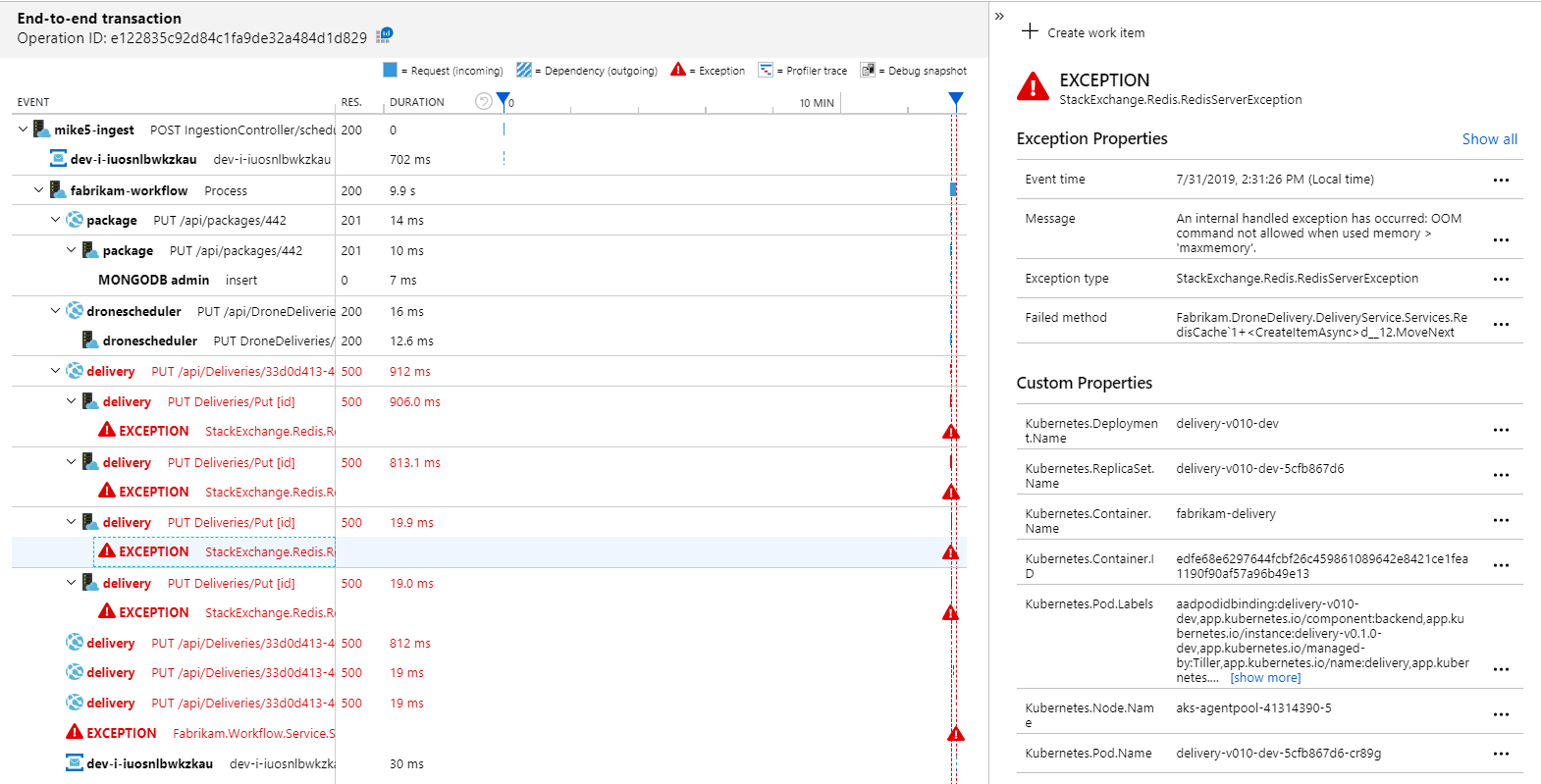
可能会注意到,这些对 Redis 的调用并没有出现在应用映射中。 这是因为 Application Insights 的 .NET 库没有可将 Redis 作为依赖项进行跟踪的内置支持。 (有关现成支持的列表,请参阅依赖项自动收集。)作为备用,可以使用 TrackDependency API 跟踪任何依赖项。 负载测试通常会显示遥测中的这些间距,它们是可以修正的。
测试 2:增加缓存大小
对于第二次负载测试,开发团队增加了 Azure Cache for Redis 中的缓存大小。 (请参阅如何缩放 Azure Cache for Redis。)此更改解决了内存不足的异常,现在应用映射显示零错误:
然而,在处理消息方面仍然存在显著的滞后。 在负载测试的峰值,传入消息速率大于传出速率的 5 倍:
下图根据消息完成度来度量吞吐量,即工作流服务将服务总线消息标记为已完成的速率。 图上的每一点代表 5 秒的数据,显示约 16/秒的最大吞吐量。
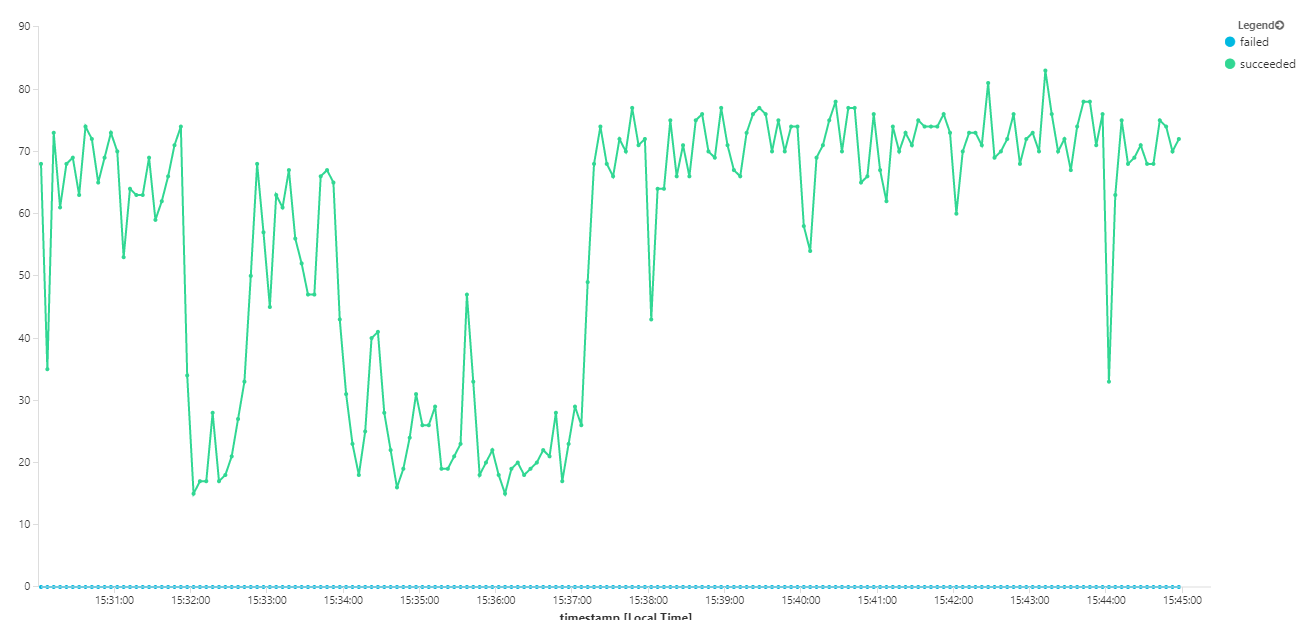
此图通过使用 Kusto 查询语言在 Log Analytics 工作区中运行查询生成:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
dependencies
| where cloud_RoleName == 'fabrikam-workflow'
| where timestamp > start and timestamp < end
| where type == 'Azure Service Bus'
| where target has 'https://dev-i-iuosnlbwkzkau.servicebus.windows.net'
| where client_Type == "PC"
| where name == "Complete"
| summarize succeeded=sumif(itemCount, success == true), failed=sumif(itemCount, success == false) by bin(timestamp, 5s)
| render timechart
测试 3:横向扩展后端服务
后端似乎是瓶颈。 简单的下一步是横向扩展业务服务(包、交付和无人机计划程序),看看吞吐量是否有所提高。 在下一次负载测试中,团队将这些服务从三个副本缩放到六个副本。
| 设置 | 值 |
|---|---|
| 群集节点 | 6 |
| 引入服务 | 3 个副本 |
| 工作流服务 | 3 个副本 |
| 包、交付、无人机计划程序服务 | 每个 6 个副本 |
不幸的是,这个负载测试只显示了适度的改进。 传出消息仍然跟不上传入消息:

吞吐量更加一致,但实现的最大值与之前的测试大致相同:
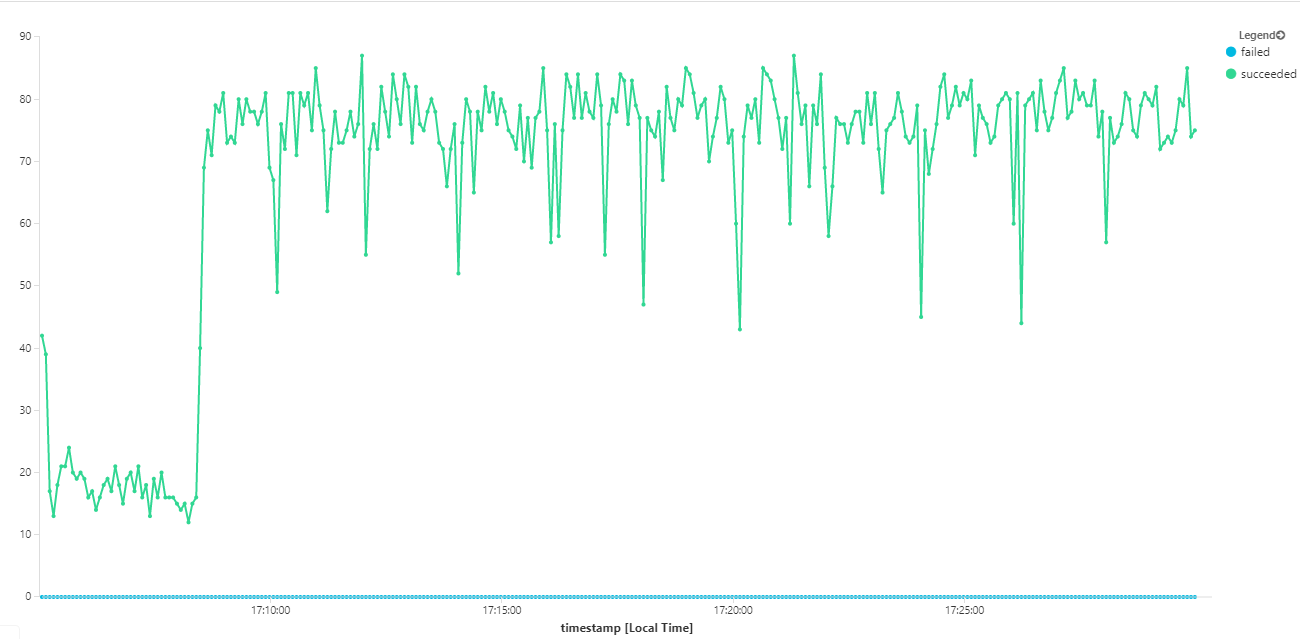
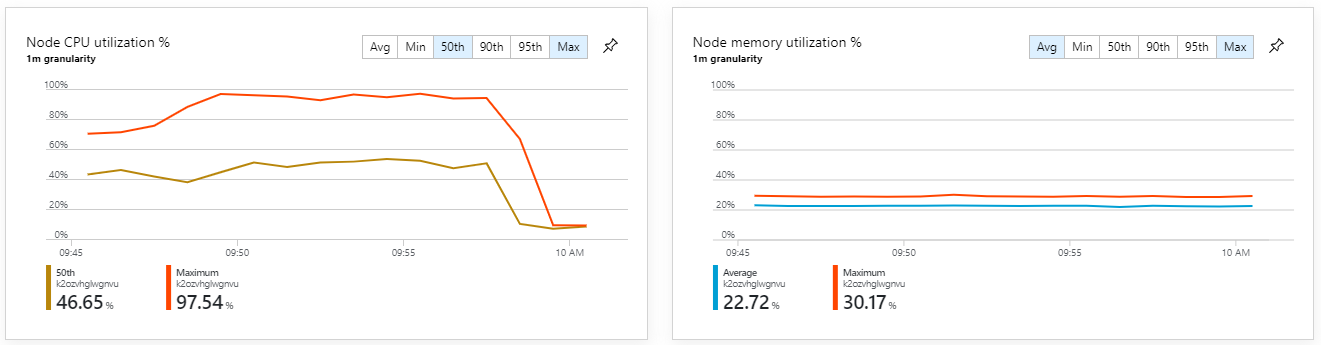
此外,从 Azure Monitor 容器见解来看,问题似乎不是由群集内的资源耗尽引起的。 首先,节点级指标显示,即使在第 95 个百分位,CPU 利用率仍低于 40%,而内存利用率约为 20%。
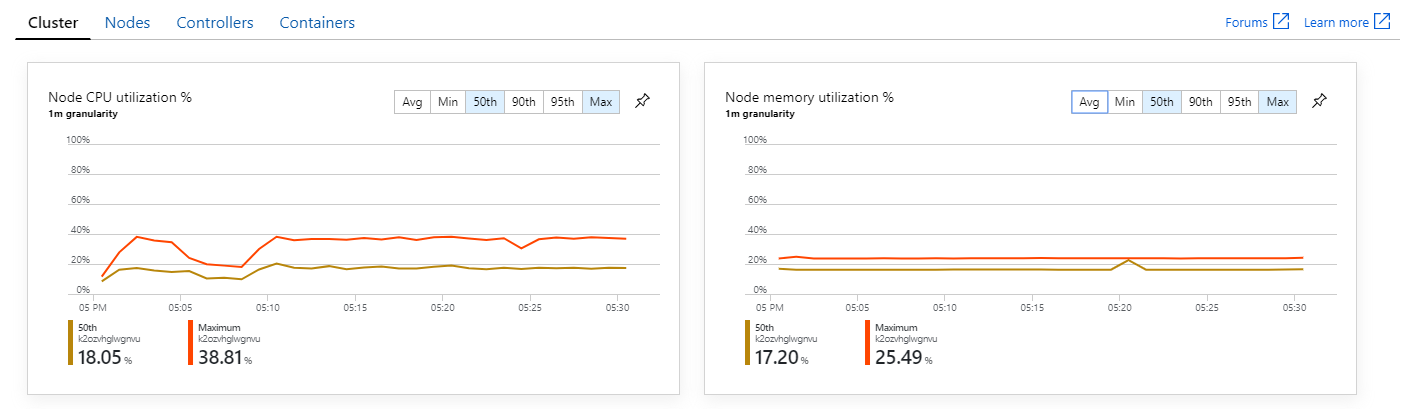
在 Kubernetes 环境中,即使节点不受资源约束,单个 Pod 也可能受到资源约束。 但 Pod 级视图显示,所有 Pod 都正常。
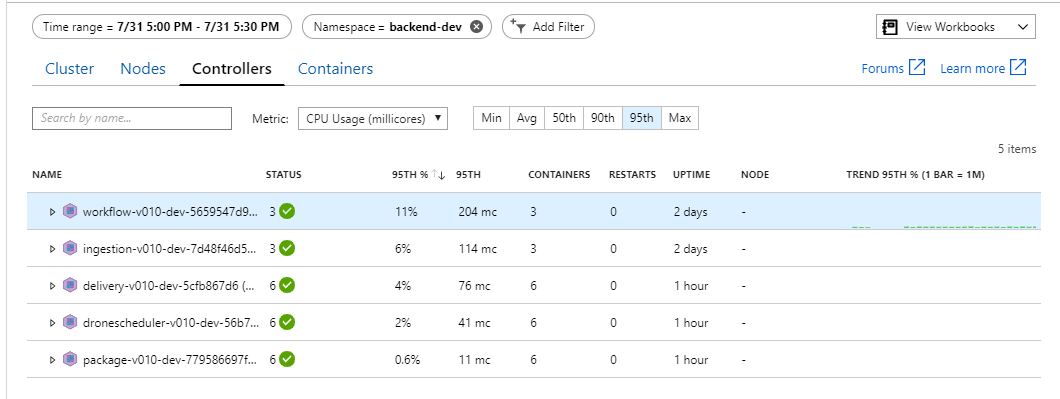
从这个测试来看,仅仅在后端添加更多 Pod 似乎没有帮助。 下一步是更仔细地查看工作流服务,以了解它处理消息时发生了什么。 Application Insights 显示,工作流服务的 Process 操作平均持续时间为 246 毫秒。
还可以运行查询来获取每个事务中各个操作的指标:
| 目标 | percentile_duration_50 | percentile_duration_95 |
|---|---|---|
https://dev-i-iuosnlbwkzkau.servicebus.windows.net/ | dev-i-iuosnlbwkzkau |
86.66950203 | 283.4255578 |
| 调试 | 37 | 57 |
| 包 | 12 | 17 |
| dronescheduler | 21 | 41 |
此表中的第一行表示服务总线队列。 其他行是对后端服务的调用。 作为参考,以下是此表的 Log Analytics 查询:
let start=datetime("2020-07-31T22:30:00.000Z");
let end=datetime("2020-07-31T22:45:00.000Z");
let dataset=dependencies
| where timestamp > start and timestamp < end
| where (cloud_RoleName == 'fabrikam-workflow')
| where name == 'Complete' or target in ('package', 'delivery', 'dronescheduler');
dataset
| summarize percentiles(duration, 50, 95) by target

这些延迟看起来是合理的。 但关键见解如下:如果总操作时间约为 250 毫秒,那么串行处理消息的速度就有了严格的上限。 因此,提高吞吐量的关键是提高并行度。
在此方案中,这应该是有可能的,原因有两个:
- 这些都是网络调用,所以大部分时间都在等待 I/O 完成
- 这些消息是独立的,不需要按顺序处理。
测试 4:提高并行度
在此测试中,团队专注于提高并行度。 为此,他们调整了工作流服务使用的服务总线客户端上的两个设置:
| 设置 | 说明 | 默认 | 新值 |
|---|---|---|---|
MaxConcurrentCalls |
要同时处理的最大消息数。 | 1 | 20 |
PrefetchCount |
客户端将提前提取到其本地缓存中的消息数。 | 0 | 3000 |
有关这些设置的详细信息,请参阅有关使用服务总线消息传送提高性能的最佳做法。 使用这些设置运行测试生成下图:
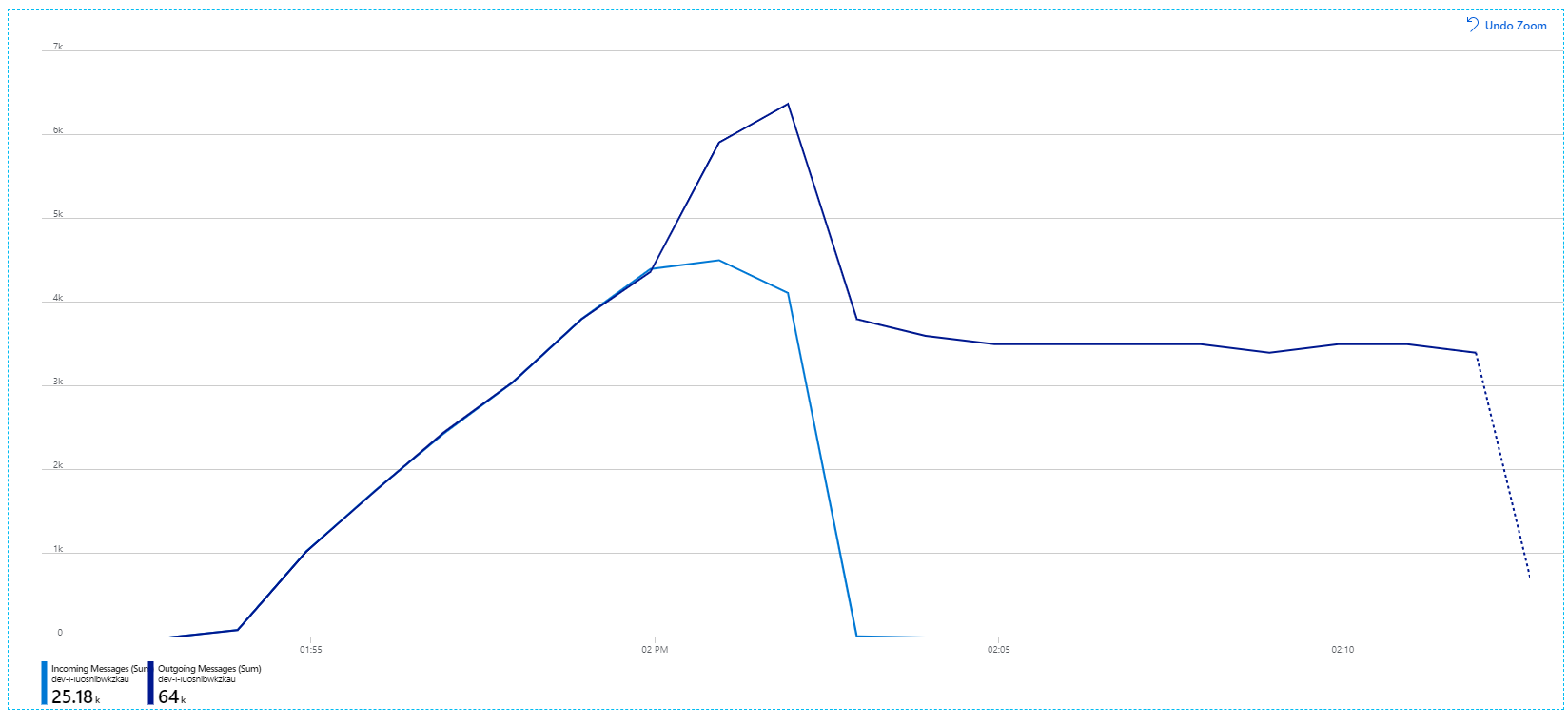
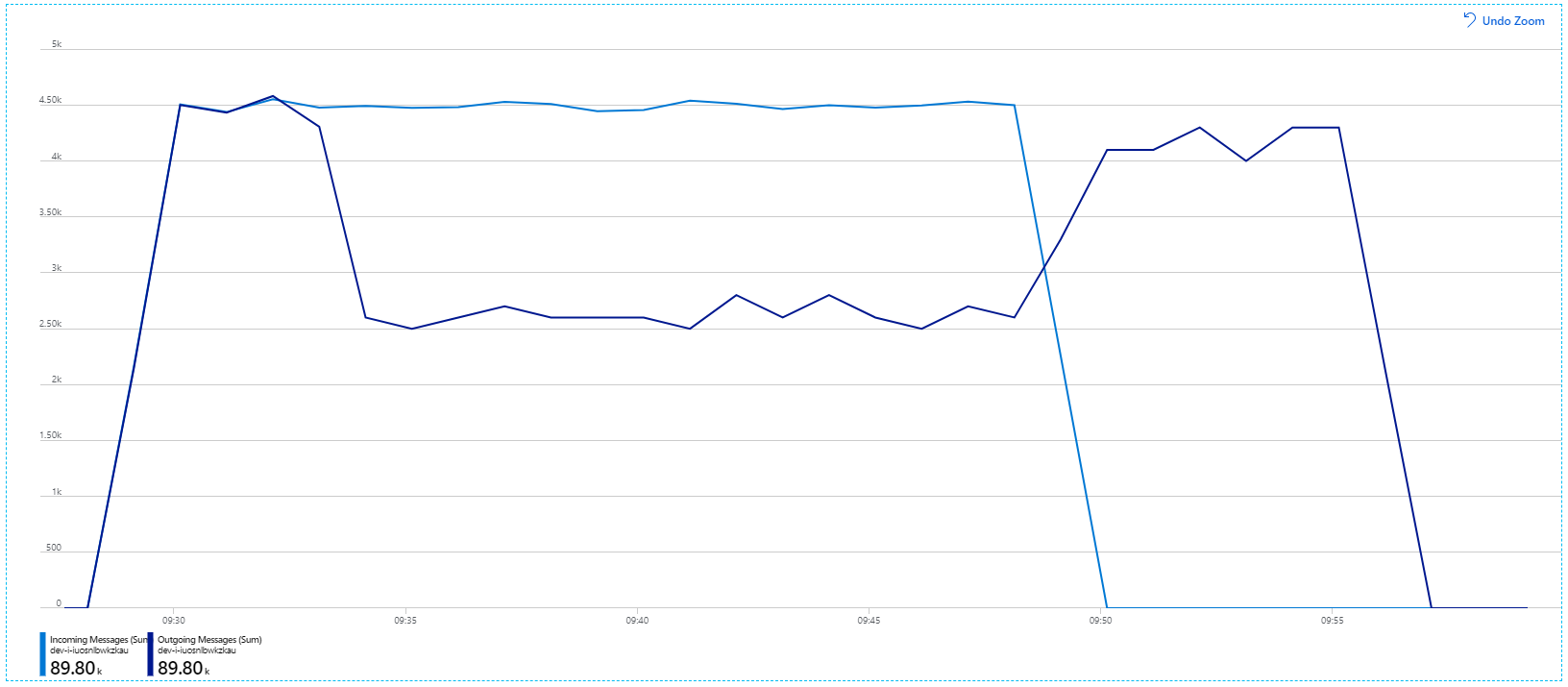
回顾传入消息显示为浅蓝色,传出消息显示为深蓝色。
乍一看,此图非常奇怪。 有一段时间,传出消息速率与传入消息速率完全一致。 但是,大约在 2:03 时,传入消息的速率趋于平稳,而传出消息的数量继续上升,实际上超过了传入消息的总数。 这似乎是不可能的。
这个谜团的线索可以在 Application Insights 的“依赖项”视图中找到。 此图表总结了工作流服务对服务总线进行的所有调用:
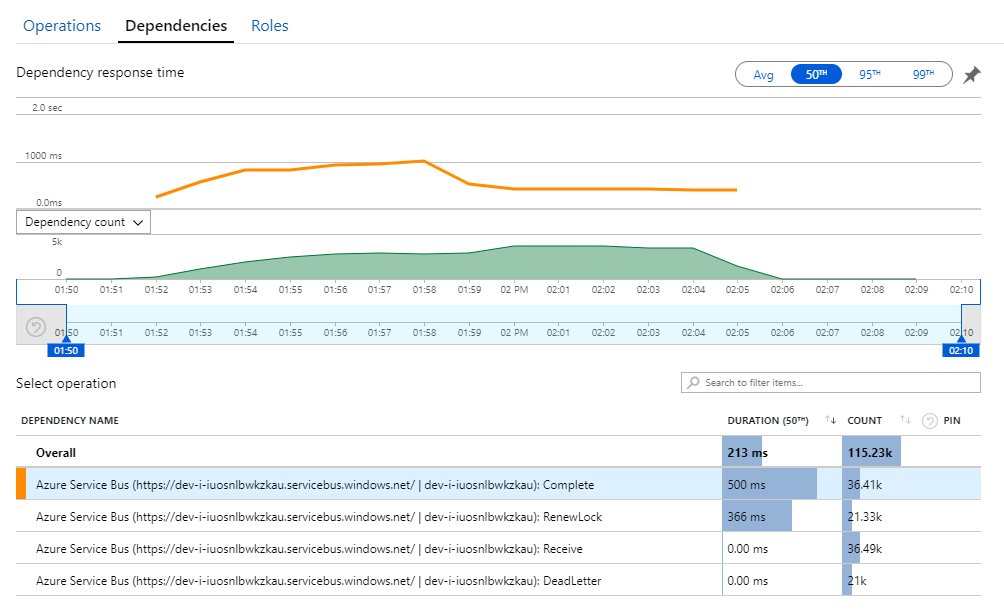
请注意 DeadLetter 的条目。 该调用表示消息正在进入服务总线死信队列。
要了解发生的情况,需要了解服务总线中的扫视-锁定语义。 当客户端使用扫视-锁定时,服务总线会自动检索并锁定消息。 在锁定期间,保证消息不会传递给其他接收方。 如果锁定过期,就会向其他接收方提供该消息。 达到交付尝试次数上限(这是可配置的)之后,服务总线将把消息放入死信队列中,稍后可以在该处进行检查。
请记住,工作流服务正在预提取大批量的消息(一次 3000 条消息)。 这表示处理每条消息的总时间更长,从而导致消息超时、返回队列并最终进入死信队列。
也可以在异常中看到这种行为,其中记录了许多 MessageLostLockException 异常:
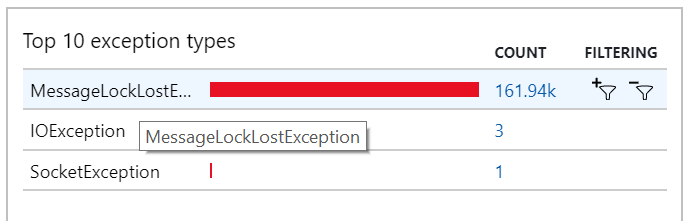
测试 5:增加锁定持续时间
对于此负载测试,消息锁定持续时间设置为 5 分钟,以防止锁定超时。 传入和传出消息图现在显示系统正在跟上传入消息的速率:
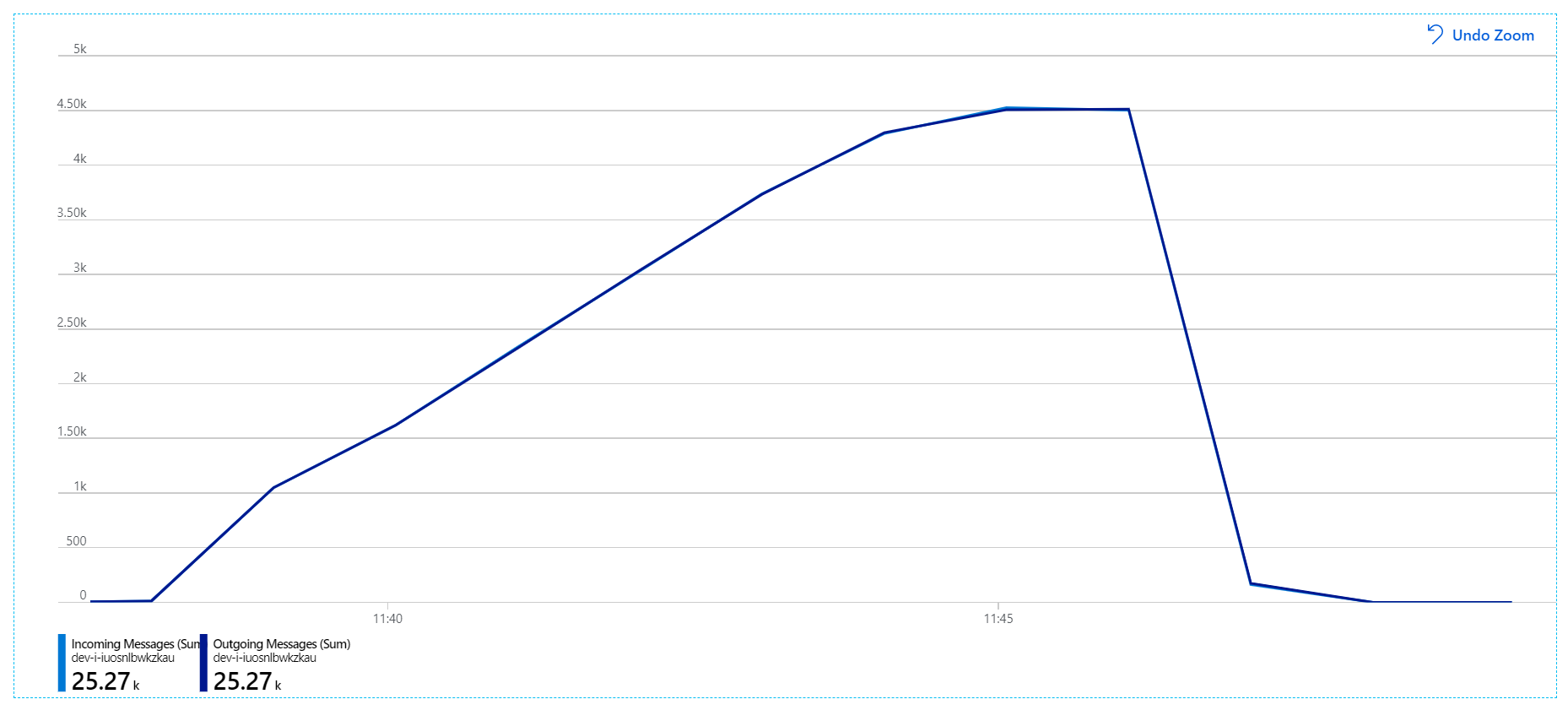
在 8 分钟负载测试的总持续时间内,应用程序完成了 25,000 次操作,峰值吞吐量为 72 次操作/秒,这表示最大吞吐量增加了 400%。
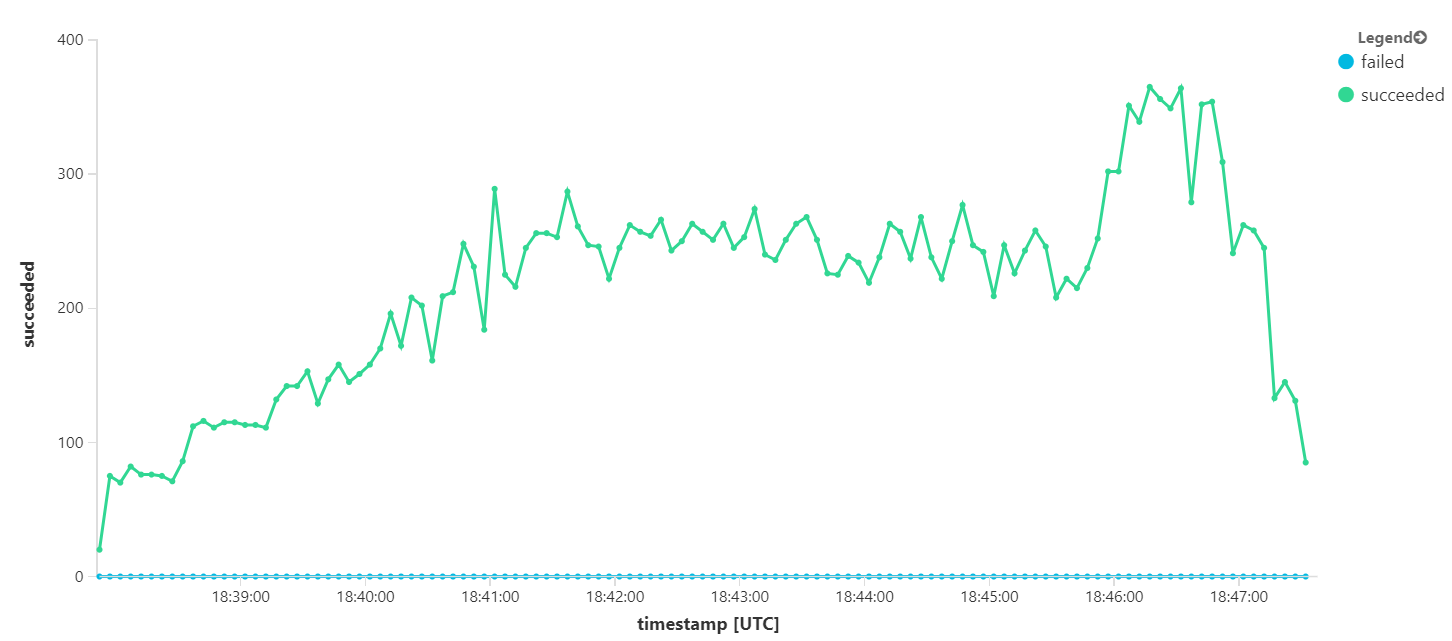
然而,以更长的持续时间运行相同的测试表明,应用程序无法维持此速率:
容器指标显示,最大 CPU 利用率接近 100%。 此时,应用程序似乎已与 CPU 绑定。 与以前尝试横向扩展不同,现在缩放群集可能会提高性能。
测试 6:横向扩展后端服务(再次)
对于序列的最后一次负载测试,团队按如下方式横向扩展了 Kubernetes 群集和 Pod:
| 设置 | 值 |
|---|---|
| 群集节点 | 12 |
| 引入服务 | 3 个副本 |
| 工作流服务 | 6 个副本 |
| 包、交付、无人机计划程序服务 | 每个 9 个副本 |
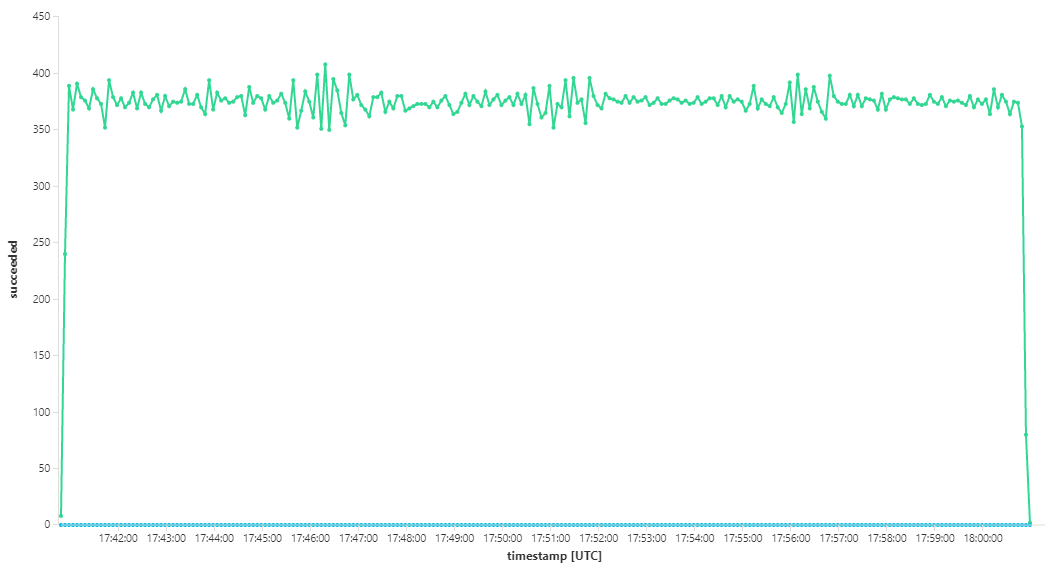
此测试导致更高的持续吞吐量,在处理消息时没有明显的滞后。 此外,节点 CPU 利用率保持在 80% 以下。
摘要
对于此方案,已确定以下瓶颈:
- Azure Cache for Redis 内存不足异常。
- 消息处理中缺乏并行度。
- 消息锁定持续时间不足,导致锁定超时,消息被放入死信队列。
- CPU 耗尽。
为了诊断这些问题,开发团队依赖于以下指标:
- 传入和传出服务总线消息的速率。
- Application Insights 中的应用程序映射。
- 错误和异常。
- 自定义 Log Analytics 查询。
- Azure Monitor 容器见解中的 CPU 和内存利用率。
后续步骤
有关此方案设计的更多信息,请参阅设计微服务体系结构。