你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
负责任且受信任的 AI
Microsoft 概述了负责任的 AI 的六个关键原则:问责制、包容性、可靠性和安全、公平性、透明度,以及隐私和安全性。 当 AI 进入主流产品和服务时,这些原则对于创建负责任且值得信赖的 AI 至关重要。 它们以两个角度为指导:道德和可解释。
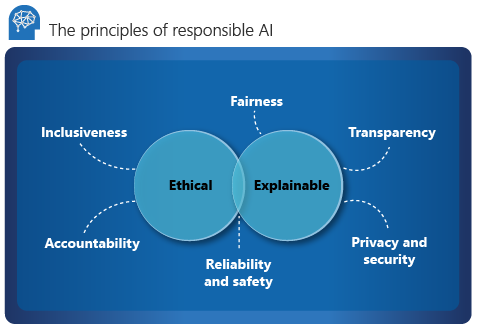
伦理
从道德角度来看,AI 应该:
- 在其断言中要公平和包容。
- 对其决定负责。
- 不歧视或阻碍不同的种族、残疾或背景。
2017 年,Microsoft (Aether) 成立了 AI、道德和工程和研究效果顾问委员会。 委员会的核心职责是就负责任的 AI 的问题、技术、流程和最佳做法提供建议。 若要了解详细信息,请参阅 了解 Microsoft 治理模型 - Aether + Office of Responsible AI。
问责制
问责制是负责任的 AI 的基本支柱。 设计和部署 AI 系统的人员需要对其操作和决策负责,尤其是在我们朝着更自治的系统迈进时。
组织应考虑建立一个内部审查机构,为开发和部署 AI 系统提供监督、见解和指导。 本指南可能因公司和地区而异,并且应反映组织的 AI 旅程。
包容
包容性要求 AI 应考虑所有人类和经验。 包容性设计实践可帮助开发人员了解并解决可能无意中排除人员的潜在障碍。 在可能的情况下,组织应使用语音转文本、文本转语音和视觉识别技术,为有听力、视觉和其他障碍的人提供支持。
可靠性和安全性
要使 AI 系统受信任,它们需要可靠且安全。 系统必须像最初设计的那样运行,并安全响应新情况。 其固有的复原能力应能抵御预期操作或意外操作。
组织应建立严格的操作条件测试和验证,以确保系统安全地响应边缘案例。 它应将 A/B 测试和冠军/质询器方法集成到评估过程中。
AI 系统的性能可能会随时间推移而降低。 组织需要建立一个可靠的监视和模型跟踪过程,以被动和主动地衡量模型的性能 (,并根据需要重新训练模型进行现代化) 。
解释
可解释性可帮助数据科学家、审核员和业务决策者确保 AI 系统能够证明其决策及其得出结论的方式。 可解释性还有助于确保符合公司政策、行业标准和政府法规。
数据科学家应该能够向利益干系人解释他们如何实现特定级别的准确性,以及影响结果的因素。 同样,为了遵守公司的政策,审核员需要一个用于验证模型的工具。 业务决策者需要通过提供透明模型来获得信任。
可解释性工具
Microsoft 开发了 InterpretML,这是一个开源工具包,可帮助组织实现模型可解释性。 它支持玻璃盒和黑盒模型:
玻璃盒模型因其结构而具有可解释性。 对于这些模型,可解释的提升计算机 (EBM) 基于决策树或线性模型提供算法的状态。 EBM 提供无损解释,可由领域专家编辑。
由于复杂的内部结构(神经网络),黑盒模型的解释更具挑战性。 本地可解释模型不可知的解释 (LIME) 或 SHapley Additive exPlanations (SHAP) 通过分析输入和输出之间的关系来解释这些模型。
Fairlearn 是一个 Azure 机器学习集成,也是用于 SDK 和 AutoML 图形用户界面的开源工具包。 它使用解释器来了解主要影响模型的内容,并使用领域专家来验证这些影响。
若要详细了解可解释性,请在 Azure 机器学习中探索模型可解释性。
公平性
公平性是所有人都希望理解和应用的核心伦理原则。 在开发 AI 系统时,这一原则尤为重要。 关键的制衡需要确保系统的决策不会基于性别、种族、性取向或宗教歧视或表达对群体或个人的偏见。
Microsoft 提供了一份 AI 公平性清单,为 AI 系统提供指导和解决方案。 这些解决方案大致分为 5 个阶段:设想、原型、构建、发布和演变。 每个阶段都列出了建议的尽职调查活动,以帮助最大程度地减少系统中不公平的影响。
Fairlearn 与 Azure 机器学习集成,支持数据科学家和开发人员评估和提高其 AI 系统的公平性。 它提供不公平缓解算法和交互式仪表板,可直观显示模型的公平性。 组织应在生成模型时使用该工具包并密切评估模型的公平性。 此活动应是数据科学过程不可或缺的一部分。
了解如何 缓解机器学习模型中的不公平性。
透明度
实现透明度可帮助团队了解:
- 用于训练模型的数据和算法。
- 应用于数据的转换逻辑。
- 生成的最终模型。
- 模型的关联资产。
此信息提供有关模型创建方式的见解,因此团队可以透明地重现模型。 Azure 机器学习工作区中的快照支持透明度,方式是通过记录实验中涉及的所有与训练相关的资产和指标或对这些内容重新训练。
隐私和安全
数据持有者有义务保护 AI 系统中的数据。 隐私和安全是此系统不可或缺的一部分。
个人数据需要受到保护,对个人数据的访问不应损害个人隐私。 Azure 差异隐私 通过随机化数据并添加干扰来向数据科学家隐藏个人信息,从而帮助保护和保留隐私。
人类 AI 指南
人类 AI 设计指南包含 18 条原则,涵盖 4 个阶段:最初阶段、交互阶段、出错阶段和未来阶段。 这些原则可帮助组织生成更具包容性且以人为本的 AI 系统。
起始阶段
阐明系统可以执行的操作。 如果 AI 系统使用或生成指标,那么全部显示它们和如何跟踪它们就很重要。
阐明系统可以执行其功能有多好。 帮助用户了解 AI 并不完全准确。 设置 AI 系统何时可能出错的预期。
交互阶段
显示上下文相关的信息。 提供与用户当前上下文和环境相关的视觉信息,例如附近的酒店。 返回接近目标目标和日期的详细信息。
缓解社会偏见。 确保语言和行为不会引入无意识的刻板印象或偏见。 例如,自动完成功能需要包含性别标识。
出错阶段
- 支持有效解除。 提供一种简单的机制来忽略或消除不需要的功能或服务。
- 支持高效更正。 提供一种直观的方式,使其更易于编辑、优化或恢复。
- 明确系统执行其工作的原因。 优化可解释的 AI,提供有关 AI 系统断言的见解。
随时间推移
- 记住最近的交互。 保留交互历史记录供将来参考。
- 从用户行为中学习。 根据用户的行为进行个性化交互。
- 谨慎更新和适应。 限制破坏性更改,并根据用户的个人资料进行更新。
- 鼓励精细反馈。 从用户与 AI 系统的交互中收集用户反馈。
受信任的 AI 框架

AI 设计者
AI 设计者构建模型并负责:
数据偏移和质量检查。 设计器检测离群值并执行数据质量检查以识别缺失值。 设计器还标准化分发、仔细检查数据,并生成用例和项目报告。
评估系统源中的数据以识别潜在的偏差。
设计 AI 算法以最大程度地减少数据偏差。 这些工作包括发现如何进行装箱、分组和规范化 (,尤其是在传统的机器学习模型中,例如基于树的机器学习模型,) 可以从数据中消除少数组。 分类 AI 设计通过对依赖于受保护健康信息的行业垂直行业中的社会、种族和性别类别进行分组来重申数据偏见, (PHI) 和个人数据。
优化监视和警报来识别目标泄漏并增强模型开发。
建立报告和见解的最佳做法,以便深入了解模型。 设计器避免使用特征或矢量重要性的黑盒方法、统一流形近似和投影 (UMAP) 聚类分析、弗里德曼的 H 统计、特征效果和相关技术。 识别指标有助于定义复杂和现代数据集中关联之间的预测影响、关系和依赖项。
AI 管理员和官员
AI 管理员和官员负责监督 AI、治理和审核框架操作和性能指标。 他们还监督 AI 安全性的实施方式和企业的投资回报。 他们的任务包括:
监视跟踪仪表板,该跟踪仪表板可帮助进行模型监视,并合并生产模型的模型指标。 仪表板侧重于准确性、模型降级、数据偏移、偏差和推理速度/误差的变化。
最好通过 REST API) 实现灵活部署和重新部署 (,该 API 允许将模型实现到开放且不可知的体系结构中。 该体系结构将模型与业务流程集成,并为反馈循环生成价值。
致力于构建模型治理和访问,以设置边界并减轻负面的业务和运营影响。 基于角色的访问控制 (RBAC) 标准确定安全控制,从而保留受限的生产环境和 IP。
使用 AI 审核和合规性框架跟踪模型开发和更改的方式,以维护行业特定的标准。 可解释和负责任的 AI 建立在可解释性度量值、简洁的特征、模型可视化和行业垂直语言的基础上。
AI 企业使用者
AI 业务使用者(业务专家)关闭反馈循环,并为 AI 设计者提供输入。 预测性决策和潜在的偏见影响(如公平和道德措施、隐私和合规性以及业务效率)有助于评估 AI 系统。 下面是业务使用者的一些注意事项:
反馈循环属于企业的生态系统。 显示模型的偏差、错误、预测速度和公平性的数据在 AI 设计人员、管理员和官员之间建立信任和平衡。 随着时间的推移,以人为中心的评估应逐渐改进 AI。
尽量减少多维复杂数据的 AI 学习有助于防止有偏见的学习。 此方法称为“小于一次拍摄” (LO-shot) 学习。
使用可解释性设计和工具可让 AI 系统对潜在的偏见负责。 应标记模型偏差和公平性问题,并将这些问题提供给警报和异常检测系统,后者从此行为中学习并自动解决偏见问题。
每个预测值应按重要性或影响细分为单个特征或向量。 它应该提供全面的预测解释,这些解释可以导出到业务报表中,以便进行审核和合规性评审、客户透明度和业务准备情况。
由于全球安全和隐私风险不断增加,解决推理期间数据违规的最佳做法要求遵守各个行业垂直行业的法规。 示例包括有关不符合 PHI 和个人数据的警报,或有关违反国家/地区安全法的警报。
后续步骤
探索人类 AI 指南,详细了解负责任的 AI。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈