你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
OCR - 光学字符识别
光学字符识别 (OCR) 也称为文本识别或文本提取。 借助基于机器学习的 OCR 技术,可以从海报、路标和产品标签等图像,以及文章、报表、表单和发票等文档中提取印刷或手写文本。 文本通常提取为单词、文本行和段落或文本块,从而获取扫描文本的电子版。 该功能可消除或显著减少手动输入数据的需求。
OCR 与智能文档处理 (IDP) 有何关系?
智能文档处理 (IDP) 使用 OCR 作为其基础技术,通过基于机器学习的高级 AI 服务(如文档智能)额外提取结构、关系、键值、实体和其他以文档为中心的见解。 文档智能包含文档优化版本的“读取”作为其 OCR 引擎,同时委托给其他模型以获取更详细的见解。 如果你想要从扫描的文档和数字文档中提取文本,请使用文档智能读取 OCR。
OCR 引擎
Microsoft 的 Read OCR 引擎由多种支持全球语言的基于机器学习的高级模型组成。 它能够提取印刷和手写文本,包括混合语言和书写风格的文本。 “读取”作为云服务和本地容器提供,以实现部署灵活性。 在最新预览版中,它还作为同步 API 提供,适用于单一非文档仅图像方案,并提供增强的性能来更轻松地实现 OCR 辅助用户体验。
警告
不建议使用 v3.2 中的 OCR API 和 v2.1 中的 RecognizeText API Azure AI 视觉旧式操作。
OCR(读取)版
重要
选择最适合你的要求的读取版本。
| 输入 | 示例 | 读取版本 | 好处 |
|---|---|---|---|
| 图像:常规的现实图像 | 标签、路标和海报 | 适用于图像的 OCR(版本 4.0) | 通过性能增强的同步 API 对常规非文档图像进行优化,可更轻松地在用户体验方案中嵌入 OCR。 |
| 文档:数字文档和扫描文档,包括图像 | 书籍、文章和报表 | 文档智能读取模型 | 使用异步 API 对文本密集型扫描文档和数字文档进行优化,有助于大规模地自动执行智能文档处理。 |
关于 Azure AI 视觉 v3.2 GA Read
正在查找最新的 Azure AI 视觉 v3.2 GA Read? 所有未来的读取 OCR 增强功能都是前面列出的两项服务的一部分。 Azure AI 视觉 v3.2 将不再更新。 有关详细信息,请参阅调用 Azure AI 视觉 3.2 GA 读取 API 和快速入门:Azure AI 视觉 v3.2 GA 读取。
如何使用 OCR
在 Vision Studio 中试用 OCR。 然后参考指向最符合你要求的阅读版的链接。
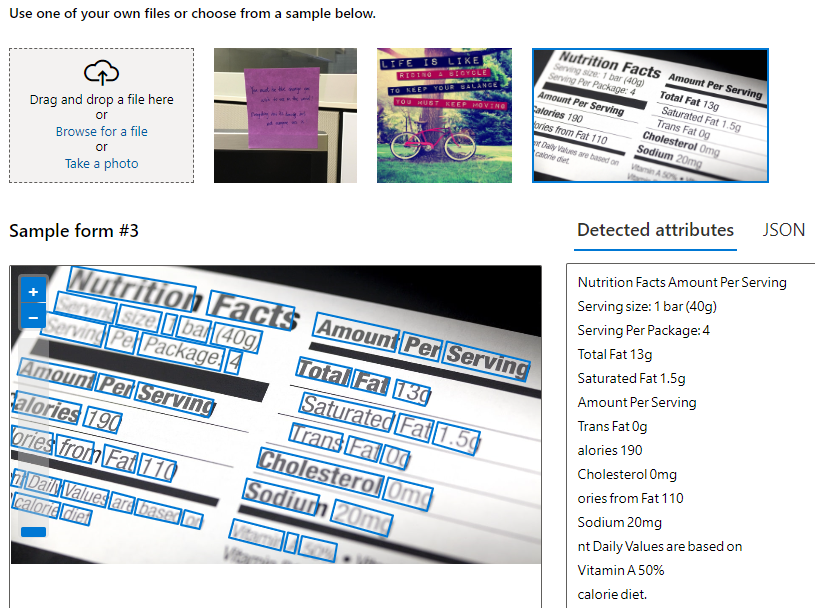
OCR 支持的语言
目前在 Azure AI 视觉中提供的两个“读取”版本都支持多种语言的印刷和手写文本。 印刷文本的 OCR 包括对英语、法语、德语、意大利语、葡萄牙语、西班牙语、中文、日语、韩语、俄语、阿拉伯语、印地语和其他使用拉丁语、西里尔语、阿拉伯语和梵文脚本的国际语言的支持。 手写文本 OCR 包括对英语、简体中文、法语、德语、意大利语、日语、韩语、葡萄牙语和西班牙语的支持。
请参阅 OCR 支持的语言完整列表。
OCR 常用功能
读取 OCR 模型可在具有通用基线功能的 Azure AI 视觉和文档智能中使用,同时针对相关的方案进行优化。 以下列表汇总了常用功能:
- 提取受支持语言的印刷和手写文本
- 具有位置和置信度分数的页面、文本行和字词
- 支持混合语言、混合模式(打印和手写)
- 本地部署可用的 Distroless Docker 容器
使用 OCR 云 API 或在本地部署
大多数客户都青睐云 API,因为它们易于集成,而且其现成可用的性质能够提高工作效率。 Azure 和 Azure AI 视觉服务将处理缩放、性能、数据安全与合规需求,你只需将工作重心放在满足客户需求上。
对于本地部署,可以使用读取 Docker 容器在你自己的本地环境中部署 Azure AI 视觉 v3.2 正式版 OCR 功能。 容器非常适合用于满足特定的安全性和数据管理要求。
OCR 数据隐私和安全
与所有 Azure AI 服务一样,使用 Azure AI 视觉服务的开发人员应该了解 Microsoft 针对客户数据的政策。 请参阅 Microsoft 信任中心上的“Azure AI 服务”页面来了解详细信息。
后续步骤
- 对于常规(非文档)图像的 OCR:请尝试学习 Azure AI 视觉 4.0 预览版图像分析 REST API 快速入门。
- 对于 PDF、Office 和 HTML 文档以及文档图像的 OCR,从先阅读文档智能读取。
- 想要查找以前的 GA 版本? 请参阅 Azure AI 视觉 3.2 GA SDK 或 REST API 快速入门。