你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:使用“自定义视觉”网站生成对象检测器
本快速入门介绍如何使用自定义视觉网站创建对象检测器模型。 生成模型后,可以使用新图像测试该模型,并将该模型集成到你自己的图像识别应用中。
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
先决条件
- 一组用于训练检测器模型的图像。 可以使用 GitHub 上的一组示例图像。 或者,可以根据下面的提示选择你自己的图像。
- 受支持的 Web 浏览器
创建自定义视觉资源
若要使用自定义视觉服务,需要在 Azure 中创建“自定义视觉训练和预测”资源。 为此,在 Azure 门户中填写创建自定义视觉页上的对话框窗口,以创建“训练和预测”资源。
创建新项目
在 Web 浏览器中,导航到自定义影像服务网页,然后选择“登录” 。 使用用于登录 Azure 门户的帐户登录。

若要创建首个项目,请选择“新建项目” 。 将显示“创建新项目”对话框。
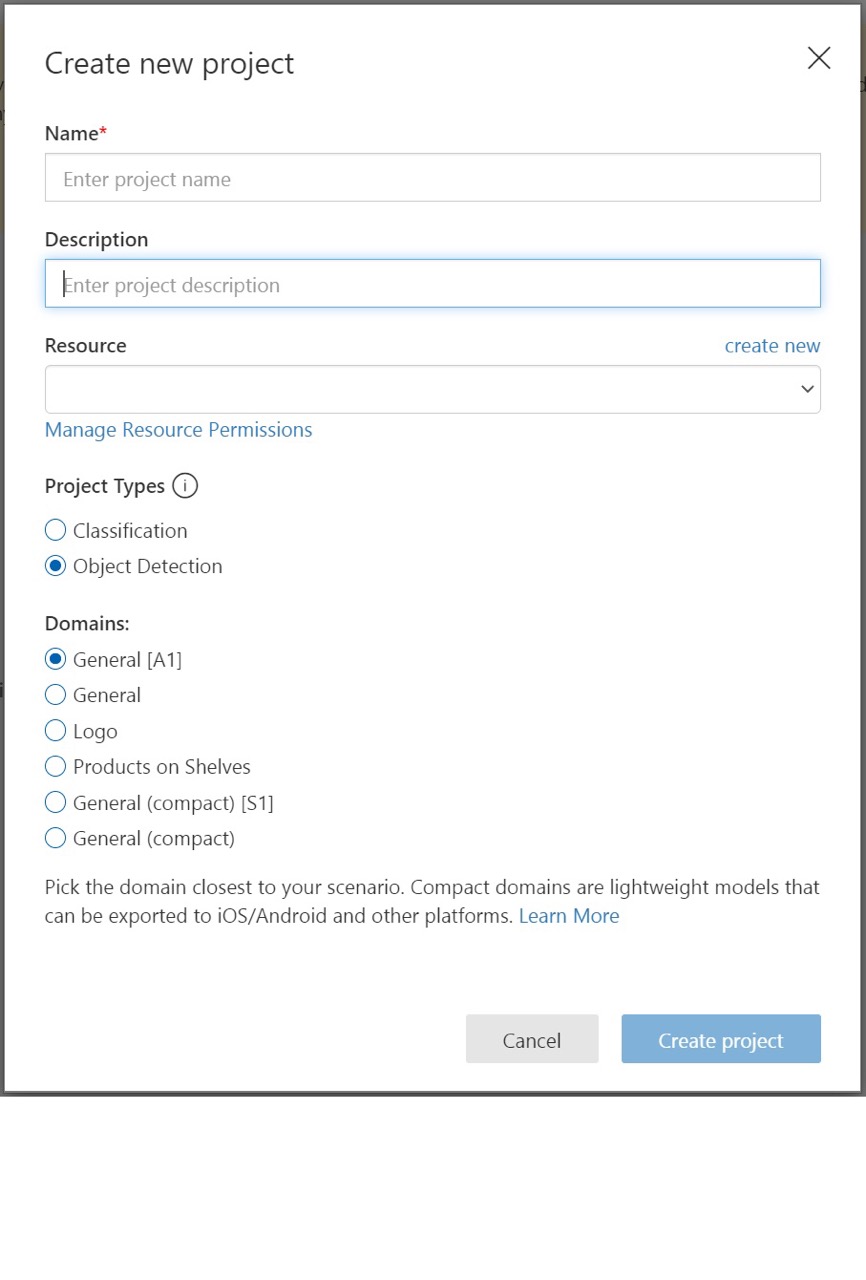
输入项目名称和描述。 然后选择自定义视觉训练资源。 如果登录帐户与 Azure 帐户相关联,则“资源”下拉列表将显示所有兼容的 Azure 资源。
注意
如果没有可用的资源,请确认已使用登录 Azure 门户时所用的同一帐户登录 customvision.ai。 此外,请确认在自定义视觉网站中选择的“目录”与自定义视觉资源所在 Azure 门户中的目录相同。 在这两个站点中,可从屏幕右上角的下拉帐户菜单中选择目录。
在
选择“项目类型”下的“对象检测”。
接下来,选择一个可用域。 每个域都会针对特定类型的图像优化检测器,如下表所述。 稍后可按需更改域。
域 目的 常规 已针对各种对象检测任务进行优化。 如果其他域都不合适,或者不确定要选择哪个域,请选择“常规”域。 徽标 已针对在图像中查找品牌徽标进行优化。 货架上的产品 已针对检测和分类货架上的产品进行优化。 压缩域 已针对移动设备上实时对象检测的约束进行优化。 可导出压缩域生成的模型在本地运行。 最后,选择“创建项目”。
选择训练图像
作为最低要求,我们建议在初始训练集中每个标记使用至少 30 张图像。 此外还需要收集一些额外的图像,以便在训练模型后测试模型。
为了有效地训练模型,请使用具有视觉多样性的图像。 选择在以下方面有所不同的图像:
- 照相机角度
- 照明
- background
- 视觉样式
- 个人/分组主题
- 大小
- type
此外,请确保所有训练图像满足以下条件:
- .jpg、.png、.bmp 或 .gif 格式
- 大小不超过 6 MB (预测图像不超过 4 MB)
- 最短的边不小于 256 像素;任何小于此像素的图像将通过自定义影像服务自动纵向扩展
上传和标记图像
在本部分中,你将上传图像并手动标记图像来帮助训练检测器。
若要添加图像,请选择“添加图像”,然后选择“浏览本地文件” 。 选择“打开”以上传图像。
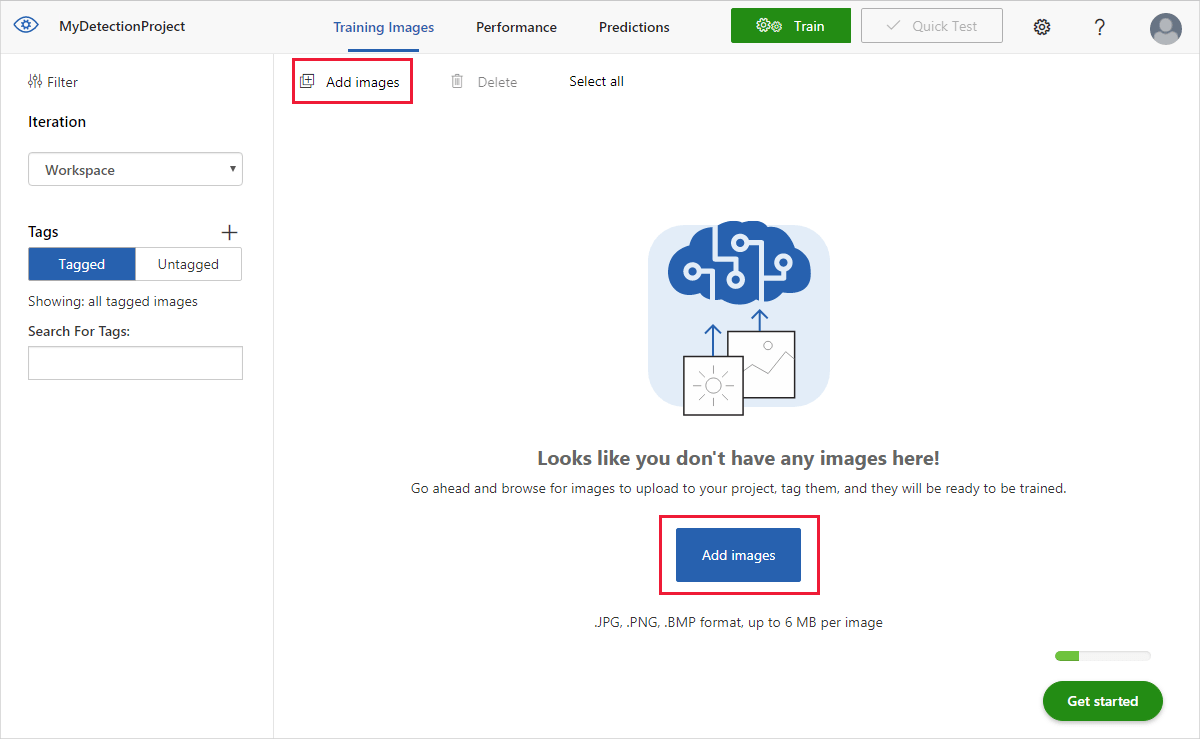
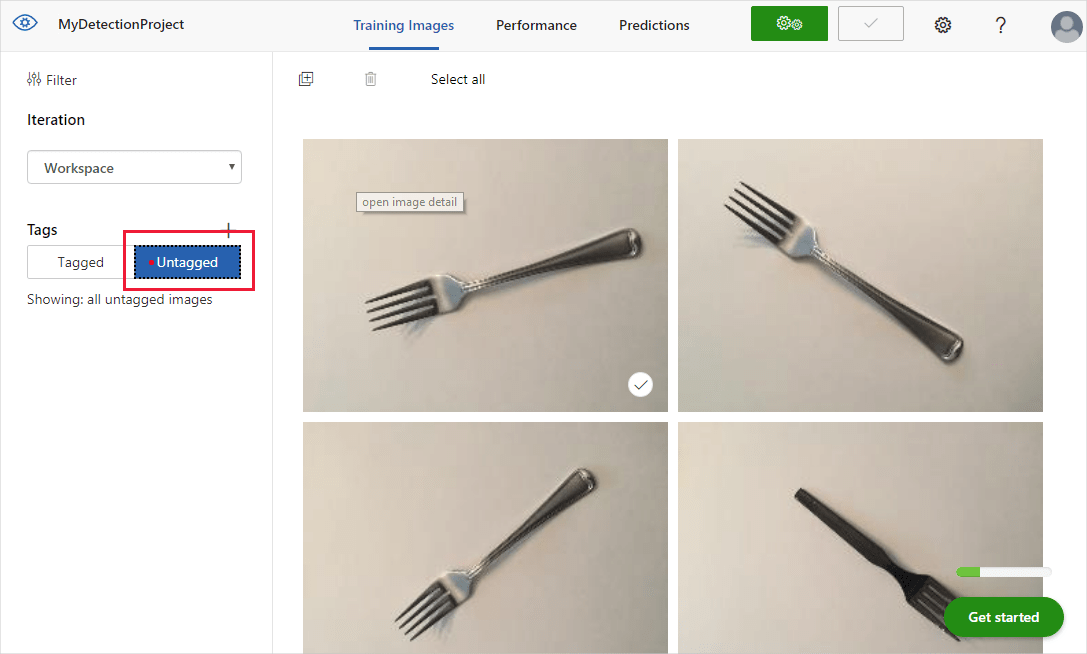
UI 的“未标记”部分会显示已上传的图像。 下一步是手动标记你希望检测器通过学习识别的对象。 选择第一个图像以打开“标记”对话框窗口。
选择一个矩形并将其拖动到图像中的物体周围。 然后,使用 + 按钮输入新的标记名称,或者从下拉列表中选择现有的标记。 请务必标记要检测的对象的每个实例,因为检测器在训练中使用未标记的背景区域作为负面示例。 完成标记后,选择右侧的箭头保存标记并转到下一个图像。
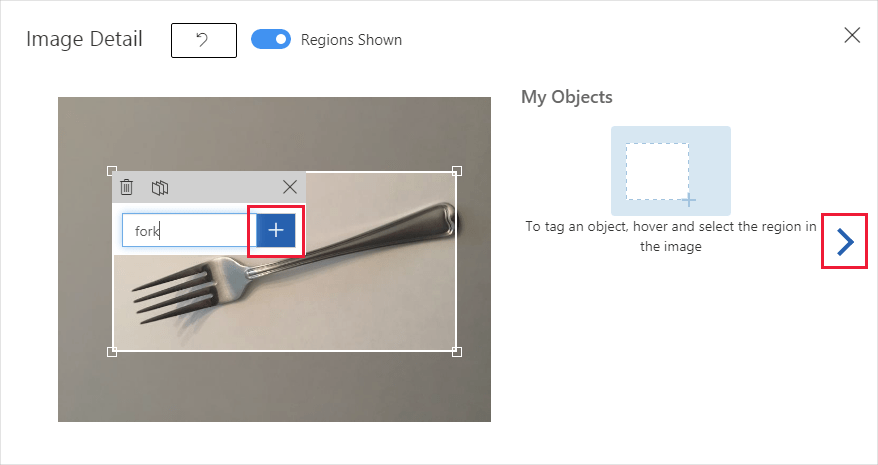
若要上传另一组图像,请返回到本部分顶部并重复上述步骤。
训练检测器
若要训练检测器模式,请选择“训练”按钮。 检测器将使用所有当前图像及其标记来创建用于识别每个标记对象的模型。 这个过程可能需要几分钟。

此训练过程应该只需要几分钟的时间。 在此期间,会在“性能”选项卡显示有关训练过程的信息。
评估检测器
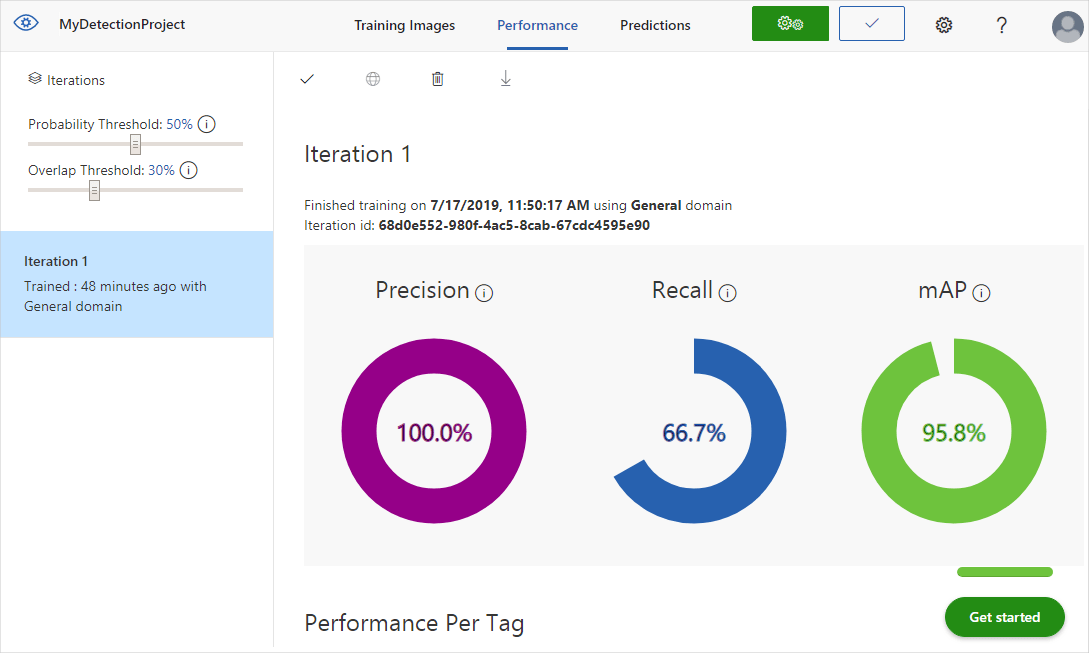
完成训练后,将计算并显示模型的性能。 自定义视觉服务使用提交用于训练的图像来计算精度、召回率和平均精度。 精度和召回率是检测器有效性的两个不同度量值:
- 精确度表示已识别的正确分类的分数。 例如,如果模型将 100 张图像识别为狗,实际上其中 99 张是狗,那么精确度为 99%。
- 召回率表示正确识别的实际分类的分数。 例如,如果实际上有 100 张苹果的图像,并且该模型将 80 张标识为苹果,则召回率为 80%。
- 平均精度是平均精准率 (AP) 的平均值。 AP 是精准率/召回率曲线下的区域(精准率根据每次进行的预测的召回率绘制)。
概率阈值
请注意“性能”选项卡左窗格上的“概率阈值”滑块 。这是预测被视为正确时所需具有的置信度(用于计算精度和召回率)。
当解释具有高概率阈值的预测调用时,它们往往会以牺牲召回为代价返回高精度的结果 - 检测到的分类是正确的,但许多分类仍然未被检测到。 使用较低的概率阈值则恰恰相反 - 大多数实际分类会被检测到,但该集合内有更多误报。 考虑到这一点,应该根据项目的特定需求设置概率阈值。 稍后,在客户端接收预测结果时,应使用与此处所用概率阈值相同的概率阈值。
重叠阈值
“重叠阈值”滑块处理在训练中必须将对象预测视为“正确”的方式。 此滑块设置预测的对象边界框和实际用户输入的边界框之间允许的最小重叠。 如果边界框未达到这种重叠度,则不会将预测视为正确。
管理训练迭代
每次训练检测器时,都会创建一个新的迭代,其中包含其自身的已更新性能指标。 可以在“性能”选项卡的左窗格中查看所有迭代。在左侧窗格中,还可以找到“删除”按钮,如果迭代已过时,可以使用该按钮删除迭代。 删除迭代时,会删除唯一与其关联的所有图像。
请参阅将模型与预测 API 配合使用,以了解如何以编程方式访问已训练模型。
后续步骤
本快速入门已介绍如何使用自定义视觉网站创建和训练对象检测器模型。 接下来,获取有关改进模型的迭代过程的详细信息。