你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure AI 文档智能的新增功能
此内容适用于:![]() v4.0(预览版)
v4.0(预览版)![]() v3.1 (GA)
v3.1 (GA)![]() v3.0 (GA)
v3.0 (GA)![]() v2.1 (GA)
v2.1 (GA)
文档智能服务会不断更新。 将此页添加为书签,以了解最新的发行说明、功能增强和我们的最新文档。
重要
发布 GA API 后,预览版 API 将会停用。 2023-02-28-preview API 版本即将停用,如果仍在使用预览版 API 或关联的 SDK 版本,请将代码更新为面向最新 API 版本 2023-07-31 (GA)。
2024 年 5 月
文档智能工作室添加了对 Microsoft Entra(以前称为 Azure Active Directory)身份验证的支持。 有关详细信息,请参阅文档智能工作室概述。
2024 年 2 月
文档智能 2024-02-29-preview REST API 现已推出。 此预览版 API 引入并更新了多项功能:
公共预览版 2024-02-29-preview 目前仅在以下 Azure 区域中可用:
- 美国东部
- 美国西部 2
- “西欧”
布局模型现在支持图形检测和分层文档结构分析(节和子节)。 读取顺序和逻辑角色检测的 AI 质量也得到了改进。
-
- 自定义提取模型现在支持单元格、行和表级别的置信度分数。 详细了解表、行和单元格置信度。
- 自定义提取模型对字段提取做出了 AI 质量改进。
- 自定义模板提取模型现在支持提取重叠字段。 详细了解重叠字段及其用法。
-
- 支持新的区域设置:
区域设置 代码 阿拉伯语 ( ar)保加利亚语 ( bg)希腊语 ( el)希伯来语 ( he)马其顿语 ( mk)俄语 ( ru)塞尔维亚语(西里尔)( sr-cyrl)乌克兰语 ( uk)泰语 ( th)土耳其语 ( tr)越南语 ( vi)- 支持新的货币代码:
货币 区域设置 代码 BAM 波斯尼亚可兑换马克 ( ba)BGN 保加利亚列弗 ( bg)ILS 以色列新谢克尔 ( il)MKD 马其顿代纳尔 ( mk)RUB 俄罗斯卢布 ( ru)THB 泰国铢 ( th)TRY 土耳其里拉 ( tr)UAH 乌克兰格里夫纳 ( ua)VND 越南盾 ( vn)- 税务项支持德国 (
de)、西班牙 (es)、葡萄牙 (pt)、加拿大英语en-CA的扩展。
-
- 扩展字段支持欧盟身份证和驾照。
-
- 从统一住宅贷款申请中提取信息(表单 1003)。
- 从统一承保和传递汇总(表单 1008)中提取信息。
- 从抵押贷款最终披露中提取信息。
-
- 从银行卡中提取信息。
-
- 用于从结婚证中提取信息的新预生成模型。
2023 年12 月
针对 REST API 2023-10-31-preview 的 文档智能客户端库现已可供使用!
2023 年 11 月
文档智能 2023-10-31-preview REST API 现在可用。 此预览版 API 引入并更新了多项功能:
公共预览版 2023-10-31-preview 目前仅在以下 Azure 区域中可用:
- 美国东部
- 美国西部 2
- “西欧”
“读取”模型
- 手写语言扩展:俄语(
ru)、阿拉伯语(ar)、泰国语(th)。 - 网络行政命令 (EO) 合规性。
- 手写语言扩展:俄语(
-
- 支持 Office 和 HTML 文件。
- Markdown 输出支持。
- 改进表提取、读取顺序和节标题检测。
- 推出文档智能 2023-10-31-preview 后,常规文档模型(预生成文档)已弃用。 今后,若要从文档中提取键值对,请使用
prebuilt-layout模型并启用可选的查询字符串参数features=keyValuePairs。
-
- 现在提取所有与价格相关的字段的货币。
-
- 针对医疗保险和医疗补助信息的新字段支持。
-
- 新的 1099 税务模型。 支持基本 1099 形式和以下变体:A、B、C、CAP、DIV、G、H、INT、K、LS、LTC、MISC、NEC、OID、PATR、Q、QA、R、S、SA、SB。
-
- 对
KVK字段的支持。 - 对
BPAY字段的支持。 - 许多字段优化。
- 对
-
- 支持多语言文档。
- 新的页面拆分选项:自动拆分、始终按页面拆分、不拆分。
注意
随着 2022-08-31 API 正式版 (GA) 的发布,关联的预览版 API 即将弃用。 如果使用 2021-09-30-preview、2022-01-30-preview 或 2022-06-30-preview API 版本,请更新应用程序,使之以 2022-08-31 API 版本为目标。 涉及一些细微更改。有关详细信息,请参阅迁移指南。
2023 年 7 月
注意
表单识别器现在称为 Azure AI 文档智能!
- 文档,Azure AI 服务包含之前称为认知服务和 Azure 应用 AI 服务的所有内容。
- 定价不变。
- Azure 计费、成本分析、价目表和价格 API 中将继续使用名称“认知服务”和“Azure 应用 AI”。
- 应用程序编程接口 (API) 或客户端库没有中断性变更。
- 某些平台仍在等待命名更新。 文档中所有提及的表单识别器或文档智能均指同一 Azure 服务。
文档智能 v3.1(正式发布)
文档智能 3.1 版 API 现已正式发布! 此 API 版本对应于 2023-07-31。
v3.1 API 引入并更新了多项功能:
- 文档智能 API 现在更模块化,并且支持可选功能。 现在可以自定义输出,专门包含所需的功能。 详细了解可选参数。
- 用于将单个文件拆分为多个独立文档的文档分类 API。 详细了解文档分类。
- 预构建的合同模型。
- 预构建的美国纳税表 1098 模型。
- 通过读取 API 支持 Office 文件类型。
- 识别文档中的二维码。
- 公式识别加载项功能。
- 字体识别加载项功能。
- 支持高分辨率文档。
- 自定义神经网络模型现在只需要一个标记样本即可进行训练。
- 自定义神经网络模型语言扩展。 使用 30 种语言训练文档的神经网络模型。 有关受支持语言的完整列表,请参阅语言支持。
- 🆕 预构建的医疗保险卡模型。
- 预构建的发票模型区域设置扩展。
- 预构建的收据模型语言和区域设置扩展,支持 100 多种语言。
- 预构建的身份证模型现在支持欧洲地区的身份证。
文档智能工作室用户体验更新
✔️ 分析选项
文档智能现支持更加复杂的分析功能,工作室允许通过统一入口(Azure 选项按钮)轻松配置加载项功能。
根据文档提取的使用场景配置分析范围、文档页面范围、可选检测,以及高级检测功能。

注意
字体提取在文档智能工作室中未进行可视化处理。 但可以查看字体检测结果 JSON 输出中的样式部分。
✔️ 使用预构建模型或你自己的模型自动标记文档
在自定义提取模型标记页面,现在可以使用文档智能服务预构建的模型或你自己之前训练好的模型自动标记文档。

对于某些文档,运行自动标记后可能会有重复的标签。 请确保修改标签,以便标记页面之后不存在重复的标签。

✔️ 自动标记表
在自定义提取模型标记页面,现在无需手动标记表即可自动标记文档中的表。

✔️ 将测试文件直接添加到训练数据集
训练好自定义提取模型后,如果需要,可将测试文档上传到训练数据集,以利用测试页面来提高模型质量。
如果某些标签返回的置信度分数较低,则请确保正确地标记它们。 如果存在标记错误,请将其添加到训练数据集并重新标记以提高模型质量。

✔️ 在自定义项目中充分利用文档列表选项和筛选器
使用自定义提取模型标记页。 现在,可以使用按特征搜索、筛选和排序轻松浏览训练文档。
利用网格视图预览文档或使用列表视图更轻松地在文档间滚动浏览。

✔️ 项目共享
- 轻松共享自定义提取项目。 有关详细信息,请参阅使用自定义模型进行项目共享。
2023 年 5 月
2023 版本的更新文档简介
🆕 文档智能概览具有增强的导航、结构化的访问点和丰富的图像。
(新)选择文档智能模型可指导你选择自己项目和工作流的最佳文档智能解决方案。
2023 年 4 月
宣布推出最新的文档智能客户端库公共预览版
文档智能 REST API 版本 2023-02-28-preview 支持公共预览版客户端库。 此版本包括适用于 .NET/C# (4.1.0-beta-1)、Java (4.1.0-beta-1)、JavaScript (4.1.0-beta-1) 和 Python (3.3.0b.1) 客户端库的以下新特性和功能:
有关详细信息,请参阅文档智能 SDK(公共预览版)和 2023 年 3 月发行说明
2023 年 3 月
- 从
2023-02-28-previewAPI 开始,自定义分类模型是文档智能中的一项新功能。 使用文档智能工作室或 REST API 尝试文档分类功能。 - 添加到“常规文档”模型的查询字段功能使用 Azure OpenAI 模型从文档中提取特定字段。 使用文档智能工作室尝试“带查询字段的常规文档”功能。 查询字段目前仅对
East US区域的资源有效。 - 加载项功能:
- 自定义提取模型更新:
- 文档智能工作室更新:
- 除了支持分类和查询字段等所有新功能外,工作室现在还支持自定义模型项目的项目共享。
- 处于封闭预览版阶段的新增模型有:疫苗接种卡、合同、美国税务 1098、美国税务 1098-E 和美国税务 1098-T。 若要请求访问门控式预览版模型,请填写并提交文档智能个人预览版请求表单。
- 收据模型更新:
- 收据模型增加了对热收据的支持。
- 收据模型现在增加了对 18 种语言和三种区域性语言(英语、法语、葡萄牙语)的语言支持。
- 收据模型现在支持
TaxDetails提取。
- 布局模型现在改进了表识别。
- 读取模型现在增加了对单位数字符识别的改进。
2023 年 2 月
v3.0 的文档智能容器现已可供使用!
Read v3.0 和 Layout v3.0 容器目前可用。
有关详细信息,请参阅安装和运行文档智能容器。
2023 年 1 月
预生成收据模型 - 添加了支持的语言。 收据模型现在支持这些添加的语言和区域设置
- 日语 - 日本 (ja-JP)
- 法语 - 加拿大 (fr-CA)
- 荷兰语 - 荷兰 (nl-NL)
- 英语 - 阿拉伯联合酋长国 (en-AE)
- 葡萄牙语 - 巴西 (pt-BR)
预生成发票模型 - 添加了支持的语言。 发票模型现在支持这些添加的语言和区域设置
- 英语 - 美国 (en-US)、澳大利亚 (en-AU)、加拿大 (en-CA)、英国 (en-UK)、印度 (en-IN)
- 西班牙语 - 西班牙 (es-ES)
- 法语 - 法国 (fr-FR)
- 意大利语 - 意大利 (it-IT)
- 葡萄牙语 - 葡萄牙 (pt-PT)
- 荷兰语 - 荷兰 (nl-NL)
预生成发票模型 - 添加了识别的字段。 发票模型现在可识别这些添加的字段
- 货币代码
- 支付选项
- 总折扣
- 税项(仅限 en-IN)
预生成 ID 模型 - 添加了支持的文档类型。 ID 模型现在支持这些添加的文档类型
- 美国军人 ID
提示
所有 2023 年 1 月更新均通过 REST API 版本 2022-08-31 (GA) 提供。
预生成收据模型 – 其他语言支持:
预生成收据模型添加了对以下语言的支持:
- 英语 - 阿拉伯联合酋长国 (en-AE)
- 荷兰语 - 荷兰 (nl-NL)
- 法语 - 加拿大 (fr-CA)
- 德语–(de-DE)
- 意大利语 - (it-IT)
- 日语 - 日本 (ja-JP)
- 葡萄牙语 - 巴西 (pt-BR)
预生成发票模型 - 其他语言支持和字段提取
预生成发票模型添加了对以下语言的支持:
- 英语 - 澳大利亚 (en-AU)、加拿大 (en-CA)、英国 (en-UK)、印度 (en-IN)
- 葡萄牙语 - 巴西 (pt-BR)
预生成发票模型现在添加了对以下字段提取的支持:
- 货币代码
- 支付选项
- 总折扣
- 税项(仅限 en-IN)
预生成 ID 文件模型 - 其他文件类型支持
预生成 ID 文件模型现在添加了对以下文件类型的支持:
- 支持印度、加拿大、英国和澳大利亚的驾照扩展
- 美国军人 ID 和证件
- 印度身份证和证件(PAN 和 Aadhaar)
- 澳大利亚身份证和证件(照片卡、钥匙通身份证)
- 加拿大身份证和证件(身份证、枫叶卡)
- 英国身份证和证件(国家/地区身份证)
2022 年 12 月
-
12 月文档智能工作室版本包含对文档智能工作室的最新更新。 用户体验进行了重大改进,主要针对自定义模型标记支持。
页面范围。 工作室现在支持分析文档中的指定页面。
自定义模型标记:
自动运行布局 API。 在自定义模型的设置过程中,可以选择为 Blob 存储中的所有文档自动运行布局 API。
搜索。 工作室现在包含搜索功能,用于在文档中查找字词。 此改进有助于在标记时更轻松地导航。
导航。 可以选择标签以便以文档中标记的字词作为目标。
自动表标记。 选择文档中的表图标后,可以选择在标签视图中自动标记提取的表。
标签子类型和二级子类型 工作室现在支持表列、表行的子类型,以及日期和数字等类型的二级子类型。
US Gov 弗吉尼亚州区域现在支持生成自定义神经网络模型。
预览 API 版本
2022-01-30-preview和2021-09-30-preview将于 2023 年 1 月 31 日停用。 请更新到2022-08-31API 版本以避免任何服务中断。
2022 年 11 月
- 宣布推出 Azure AI 文档智能库的最新稳定版本
- 此版本包括 .NET、Java、JavaScript 和 Python 客户端库的重要更改和更新。 有关详细信息,请参阅Azure SDK DevBlog。
- 最重要的增强功能是引入了两个新客户端,即
DocumentAnalysisClient和DocumentModelAdministrationClient。
2022 年 10 月
文档智能版本控制内容
文档智能文档已更新,以提供带版本控制的体验。 现在,可以选择查看针对
v3.0 GA体验或v2.1 GA体验的内容。 默认使用 v3.0 体验。
文档智能工作室示例代码
- GitHub 上现已提供文档智能工作室标记体验的示例代码。 客户可以开发文档智能并将其集成到自己的用户体验中,或者使用文档智能工作室示例代码自行构建新的用户体验。
语言扩展
- 最新预览版文档智能的读取 (OCR)、布局和自定义模板模型支持 134 种新语言。 添加的这些语言包括希腊语、拉脱维亚语、塞尔维亚语、泰语、乌克兰语、越南语以及几种拉丁语和西里尔语。 文档智能现在共有 299 种支持的语言,适用于最新的正式版和新预览版。 请参阅支持的语言页,查看所有支持的语言。
- 使用 API 或相应的 SDK 在应用程序中支持新语言时,请使用 REST API 参数
api-version=2022-06-30-preview。
全新预生成合同模型
- 全新的预生成方式,可从合同中提取信息(如当事方、标题、合同 ID、执行日期等)。 合同模型目前为预览版,在此处请求访问权限。
用于训练自定义神经模型的区域扩展
- 现已增加支持训练自定义神经模型的区域。
- 美国东部
- 美国东部 2
- US Gov 亚利桑那州
- 现已增加支持训练自定义神经模型的区域。
2022 年 9 月
注意
从版本 4.0.0 开始,引入了一组新的客户端来利用文档智能服务的最新功能。
SDK 版本 4.0.0 正式版包括以下更新:
- 版本 4.0.0 GA (2022-09-08)
- 支持 REST API v3.0 和 v2.0 客户端
现在,有六个新区域用于支持训练自定义神经网络模型的区域扩展
- 澳大利亚东部
- 美国中部
- 东亚
- 法国中部
- 英国南部
- 美国西部 2
2022 年 8 月
文档智能 SDK beta 2022 年 8 月预览版包含以下更新:
版本 4.0.0-beta.5 (2022-08-09)
文档智能 v3.0 正式发布
- 文档智能 REST API v3.0 现已正式发布,可在生产应用程序中使用! 使用 REST API 版本 2022-08-31 更新应用程序。
文档智能工作室更新
- 后续步骤。 在每个模型页下,工作室现在都有一个后续步骤部分。 用户可以快速参考示例代码、故障排除指南和定价信息。
- 自定义模型。 工作室现在包含在自定义模型项目中重新排序标签以提高标记效率的功能。
- 复制模型。可以从工作室内跨文档智能服务复制自定义模型。 此操作可以将经过训练的模型提升到其他环境和区域。
- 删除文档。 工作室现在支持从自定义项目中的已标记数据集中删除文档。
文档智能服务更新
- prebuilt-read。 读取 OCR 模型现在也可以在文档智能中使用,其中段落和语言检测是两项新功能。 文档智能读取的目标是与文档智能中更广泛的文档智能功能对齐的高级文档方案。
- prebuilt-layout。 布局模型提取段落并识别提取的文本是段落、标题、节标题、脚注、页眉、页脚还是页码。
- prebuilt-invoice。 TotalVAT 和 Line/VAT 字段现在分别解析为现有字段 TotalTax 和 Line/Tax。
- prebuilt-idDocument。 数据提取支持美国身份证、社会保障卡和绿卡。 支持护照签证信息。
- prebuilt-receipt。 扩展了对法语 (fr-FR)、西班牙语 (es-ES)、葡萄牙语 (pt-PT)、意大利语 (it-IT) 和德语 (de-DE) 的语言环境支持。
- prebuilt-businessCard。 地址解析支持提取地址组件的子字段,例如地址、城市、省/市/自治区、国家/地区和邮政编码。
AI 质量改进
- prebuilt-read。 增强了对单字符、手写日期、金额、名称以及收据和发票中常见的其他关键数据的支持,并改进了数字 PDF 文档的处理。
- prebuilt-layout。 支持更好地检测裁剪表、无边框表,并改进了对长跨度单元格的识别。
- prebuilt-document。 改进了值和复选框检测。
- custom-neural。 提高了表检测和提取的准确性。
2022 年 6 月
- 文档智能 SDK beta 2022 年 6 月预览版包含以下更新:
版本 4.0.0-beta.4 (2022-06-08)
文档智能工作室 6 月版本是文档智能工作室的最新更新。 此更新中有大量用户体验和可访问性改进:
- JavaScript 和 C# 的代码示例。 除了现有的 Python 示例外,工作室代码选项卡现在还会添加 JavaScript 和 C# 代码示例。
- 新的文档上传 UI。 工作室现支持通过拖放文档将其上传到新的上传用户界面中。
- 自定义项目的新功能。 自定义项目现支持在配置项目时创建存储帐户和 Blob。 此外,自定义项目现支持直接在工作室中上传训练文件并复制现有的自定义模型。
文档智能 v3.0 2022-06-30-preview 版本提供了跨功能 API 的大量更新:
- 布局扩展了结构提取。 布局现在包含添加的结构元素,包括部分、部分标题和段落。 此项更新可以实现更细致的文档分段方案。 有关已确定的结构元素的完整列表,请参阅增强的结构。
- 自定义神经模型表格字段支持。 自定义文档模型现在支持表格字段。 默认情况下,表格字段也是多页的。 若要详细了解自定义神经模型中的表格字段,请参阅表格字段。
- 自定义模板模型表格字段支持跨页表。 自定义表单模型现在支持跨页的表格字段。 若要详细了解自定义模板模型中的表格字段,请参阅表格字段。
- 发票模型输出现在包含常规文档键值对。 如果发票包含预生成模型中所包含的字段之外的必填字段,则常规文档模型会使用键值对来补充输出。 请参阅键值对。
- 发票语言扩展。 发票模型包括扩展的语言支持。 请参阅支持的语言。
- 预生成名片现在包括日语支持。 请参阅支持的语言。
- 预生成 ID 文档模型。 ID 文档模型现在可以从美国驾照中提取 DateOfIssue、Height、Weight、EyeColor、HairColor 和 DocumentDiscriminator。 请参阅字段提取。
- 读取模型现在支持常见的 Microsoft Office 文档类型。 读取 API 现在支持 Word (docx)、Excel (xlsx) 和 PowerPoint (ppt) 等文档类型。 请参阅读取数据提取。
2022 年 2 月
版本 4.0.0-beta.3 (2022-02-10)
文档智能 v3.0 预览版引入了几个新特性、功能和增强:
- 自定义神经模型(自定义文档模型)是一个新的自定义模型,可用于从结构化表单、半结构化和非结构化文档中提取文本和选择标记。
- W-2 预生成模型是一个新的预生成模型,可用于从 W-2 表单中提取字段以用于税务报告和收入确认场景。
- 读取 API 可提取印刷体文本行、单词、文本位置、检测到的语言和手写文本(如检测到)。
- 常规文档预训练模型现已更新为支持选择标记,此外还支持表格和文档中的 API 文本、表、结构和键值对。
- 发票 API 发票预生成模型扩展了对西班牙语发票的支持。
- 文档智能工作室新增了读取、W2、酒店收据示例的演示,并支持训练新的自定义神经模型。
- 语言扩展在文档智能读取、布局和自定义表单中,添加了对 42 种新语言(包括阿拉伯语、印地语及其他使用阿拉伯文和梵文的语言)的支持,覆盖范围扩大至 164 种语言。 手写语言支持扩展到了日语和韩语。
文档智能模型数据提取:
型号 文本提取 键值对 选择标记 表 签名 读取 ✓ 常规文档 ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ 发票 ✓ ✓ ✓ ✓ 回执 ✓ ✓ ✓ 身份文档 ✓ ✓ 名片 ✓ ✓ 自定义模板 ✓ ✓ ✓ ✓ ✓ 自定义神经 ✓ ✓ ✓ ✓ 文档智能 SDK beta 预览版包含以下更新:
-
- 自定义模板(前自定义表单)。
- 自定义神经。
- 自定义模型 - 生成模式。
W-2 预生成模型 (prebuilt-tax.us.w2)。
读取预生成模型 (prebuilt-read)。
发票预生成模型(西班牙语) (prebuilt-invoice)。
-
2021 年 11 月
版本 4.0.0-beta.2 (2021-11-09)
| 包 (NuGet) | 更改日志/发布历史记录 | API 参考文档
- 文档智能 v3.0 预览版 SDK 版本更新 (beta.2) 包含 bug 修复和次要功能更新。
2021 年 10 月
文档智能 v3.0 预览版 4.0.0-beta.1 (2021-10-07) 引入了几个新的特性和功能:
常规文档模型是一个新的 API,它使用预先训练的模型从表单和文档中提取文本、表、结构和键值对。
已将酒店收据模型添加到预生成收据处理。
身份文档的扩展字段:身份模型支持从美国驾照提取准驾车型、限制和车辆分类信息。
签名字段是自定义表单中的新字段类型,用于检测表单字段中是否存在签名。
语言扩展:支持 122 种打印语言和 7 种手写语言。 最新预览版的文档智能布局和自定义表单将支持的语言扩展为 122 种。 此预览版可以从 49 种新语言(包括俄语、保加利亚语、其他西里尔语和其他拉丁语)的打印文本中提取文本。 此外,手写文本提取现在支持 7 种语言,包括英语,以及简体中文、法语、德语、意大利语、葡萄牙语和西班牙语的新预览版。
表和文本提取增强:布局现在支持提取单行表(也称为键值表)。 文本提取增强包括可以更好地处理数字 PDF,以及身份文档中的机器可读区域 (MRZ) 文本,同时可以保持一般的性能。
文档智能工作室:为了简化服务的使用,现在你可以访问文档智能工作室来测试不同的预生成模型,或者标记和训练自定义模型。
文档智能模型数据提取
Model 文本提取 键值对 选择标记 表 常规文档 ✓ ✓ ✓ ✓ Layout ✓ ✓ ✓ 发票 ✓ ✓ ✓ ✓ 回执 ✓ ✓ 身份文档 ✓ ✓ 名片 ✓ ✓ 自定义 ✓ ✓ ✓ ✓
2021 年 9 月
Azure 指标资源管理器高级功能可在 Azure 门户的文档智能资源概述页上使用。
监视菜单:

图表:

身份文档模型更新:可成功处理包含后缀并且带有或不带有点号(句点)的姓名:
输入文本 更新后的结果 William Isaac Kirby Jr. FirstName:William Isaac
LastName:Kirby Jr。Henry Caleb Ross Sr FirstName:Henry Caleb
LastName:Ross Sr.
2021 年 7 月
- 系统分配的托管标识支持:你现在可以启用系统分配的托管标识,以授予文档智能对专用存储帐户的有限访问权限,这些帐户包括受虚拟网络或防火墙保护的帐户,或启用了自带存储 (BYOS) 的帐户。 请参阅为文档智能资源创建和使用托管标识,了解详细信息。
2021 年 6 月
| 参考文档 | NuGet 包版本 3.1.1 |
在门控式预览版中发布的文档智能容器 v2.1 现在由六个功能容器(即“布局”、“名片”、“ID 文档”、“回执”、“发票”和“自定义”)提供支持。 若要使用这些容器,必须提交在线请求并获得批准。
以预览版形式发布的文档智能连接器:文档智能连接器与 Azure 逻辑应用、Microsoft Power Automate 和 Microsoft Power Apps 集成。 连接器支持工作流操作和触发器,可从自定义和预生成的表单、发票、回执、名片和 ID 文档提取并分析文档数据和结构。
文档智能 SDK v3.1.0 修补成 v3.1.1,适用于 C#、Java 和 Python。 补丁可处理未检测到子行项字段的发票,例如具有
Text但没有BoundingBox或Page信息的FormField。
2021 年 5 月
- 版本 3.1.0 (2021-05-26)
文档智能 2.1 现已正式发布。 此 GA 版本标志着先前 2.1 预览版包版本中引入的更改的稳定性。 利用此版本,你能够检测和提取以下文档类型中的信息和数据:
更新后的布局 API 表功能添加了标头识别,其中列标题可跨越多行。 每个表单元格都有一个属性,指示其是否为标头的一部分。 此更新可用于确定构成表头的行。
2021 年 4 月
NuGet 包版本 3.1.0 - beta.4
用于分析标识文档中数据的新方法:
StartRecognizeIdDocumentsFromUriAsync
StartRecognizeIdDocumentsAsync
有关字段值的列表,请参阅文档智能文档中的提取的字段。
扩展了可提供给 StartRecognizeContent 方法的文档语言集。
以下类支持的新属性 :
RecognizeBusinessCardsOptions
RecognizeCustomFormsOptions
RecognizeInvoicesOptions
RecognizeReceiptsOptionsPages属性允许选择多页 PDF 和 TIFF 文档的单个页面或特定范围的页面。 对于单个页面,请输入页码,例如3。 对于页面范围(如第 2 页和第 5 页到第 7 页),请输入用逗号分隔的页码和范围:2, 5-7。以下类支持的新属性
ReadingOrder:ReadingOrder属性是一个可选参数,可用于指定应该应用哪一种读取顺序算法(basic或natural)对文本元素的提取进行排序。 如果未指定,默认值为basic。
- API 版本
2.1-preview.3的 SDK 预览版更新引入了功能更新和增强功能。
2021 年 3 月
文档智能 v2.1 公共预览版 v2.1-preview.3 已发布,并包括以下功能:
新的预生成 ID 模型 新的预生成 ID 模型使客户能够创建 ID,并返回结构化数据以进行自动处理。 它结合了强大的光学字符识别 (OCR) 功能与 ID 理解模型,可从护照和美国驾照中提取关键信息。
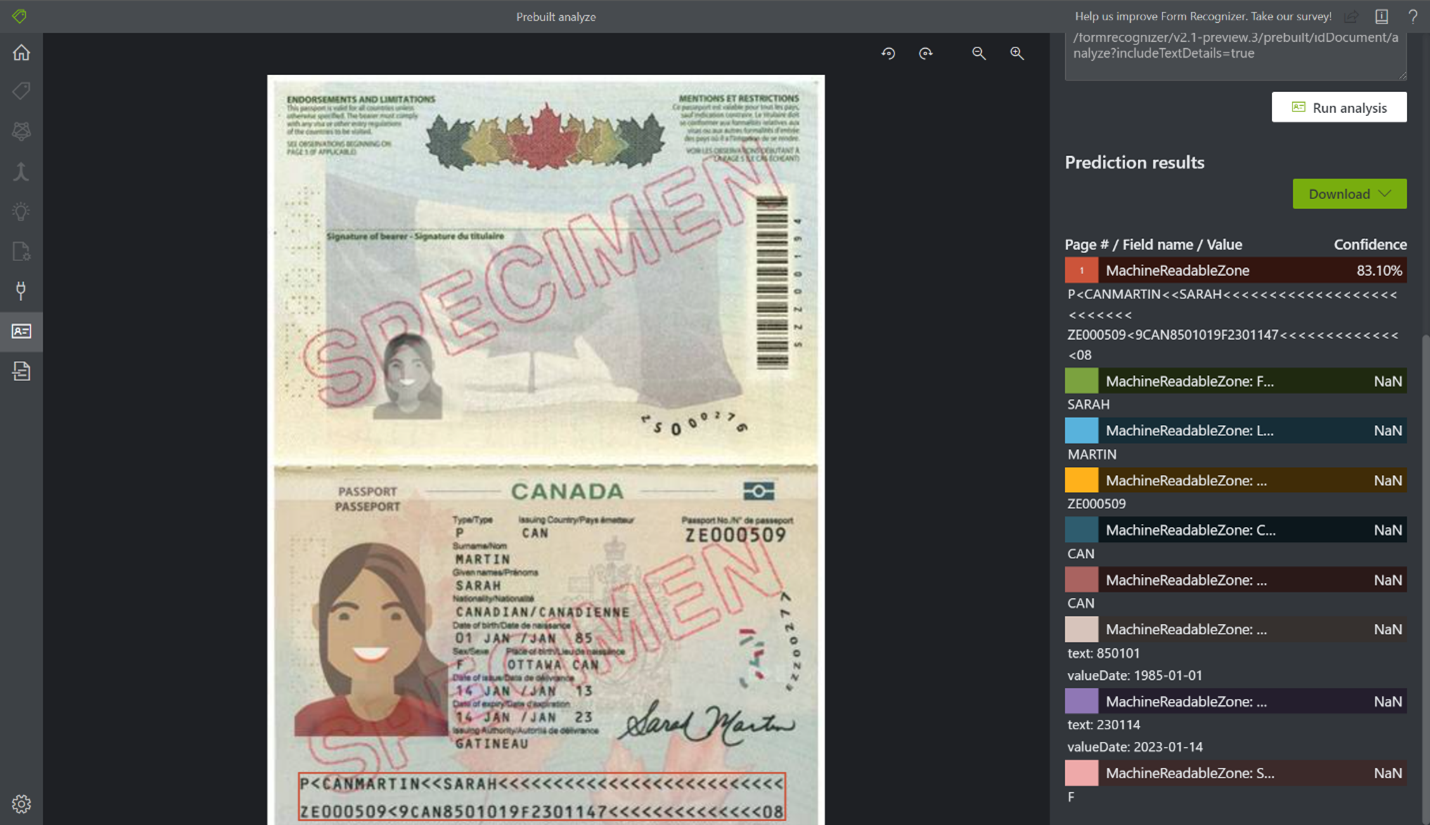
发票模型的行项提取 - 预生成发票模型现在支持行项提取;现在,它将提取所有项及其部件:说明、金额、数量、产品 ID、日期等。 使用简单的 API/SDK 调用,可以从发票中提取有用数据:文本、表、键值对和行项。
监督式表标记和训练,空值标记 - 除了文档智能的先进深度学习自动表提取功能,现在还允许客户对表进行标记和训练。 此新版本包括对行项/表进行标记和训练(动态和固定),并训练自定义模型来提取键值对和行项。 对模型进行训练后,模型会将行项提取为 JSON 输出中 documentResults 节的一部分。
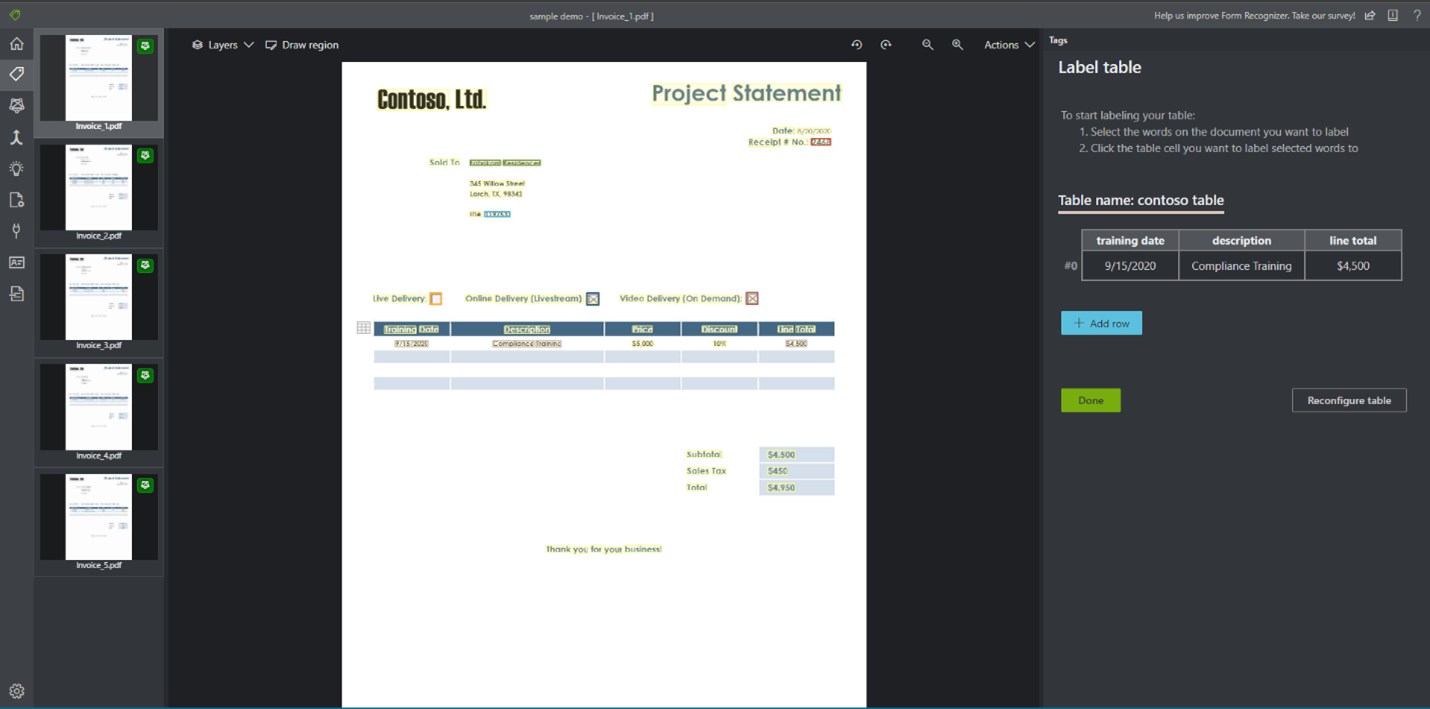
除了标记表之外,现在还可以标记空值和区域。 如果训练集中的某些文档不包含某些字段的值,你可以标记这些值,使模型知道如何从分析的文档中正确提取值。
支持 66 种新语言 - 文档智能的布局 API 和自定义模型现在支持 73 种语言。
自然阅读顺序、手写分类和页面选择 - 通过此更新,你可以选择以自然阅读顺序(而不是从左到右和从上到下的顺序)获取文本行输出。 使用新的 readingOrder 查询参数,并将其设置为“natural”值,以获得更友好的阅读顺序输出。 此外,对于拉丁语系语言,文档智能会将文本行归类为手写样式,并提供置信度分数。
预生成收据模型质量改进 此更新包括预生成收据模型的许多质量改进,尤其是有关行项提取的改进。


2020 年 11 月
文档智能 v2.1-preview.2 已发布,并包括以下功能:
新的预生成发票模型 - 新的预生成发票模型使客户能够以各种格式创建发票,并返回结构化数据以自动处理发票。 它结合了强大的光学字符识别 (OCR) 功能与发票理解深度学习模型,可从英语发票中提取重要信息。 可提取重要文本、表和信息,如客户、供应商、发票 ID、发票到期日期、总计、应付金额、税金、送货地址和帐单地址。

增强的表提取 - 文档智能现在提供了增强的表提取功能,该功能结合了强大的光学字符识别 (OCR) 功能与深度学习表提取模型。 文档智能可以从表中提取数据,包括包含合并列、行、无边框等的复杂表。

客户端库更新 - 适用于 .NET、Python、Java 和 JavaScript 的客户端库的最新版本支持文档智能 2.1 API。
支持的新语言:日语 - 现在支持以下新语言:对于 和
AnalyzeCustomForm:日语 (ja)。 语言支持。文本行样式指示(手写/其他)(仅拉丁语系语言)- 文档智能现在会输出一个
appearance对象(该对象会分类每个文本行是否为手写样式)以及置信度分数。 此功能仅支持拉丁语。质量改进 - 提取改进(包括一位数提取改进)。
文档智能示例和标记工具中的新试用功能 - 可以使用文档智能示例标记工具试用预生成的发票、收据和名片模型以及布局 API。 查看如何在不编写任何代码的情况下提取数据。
-
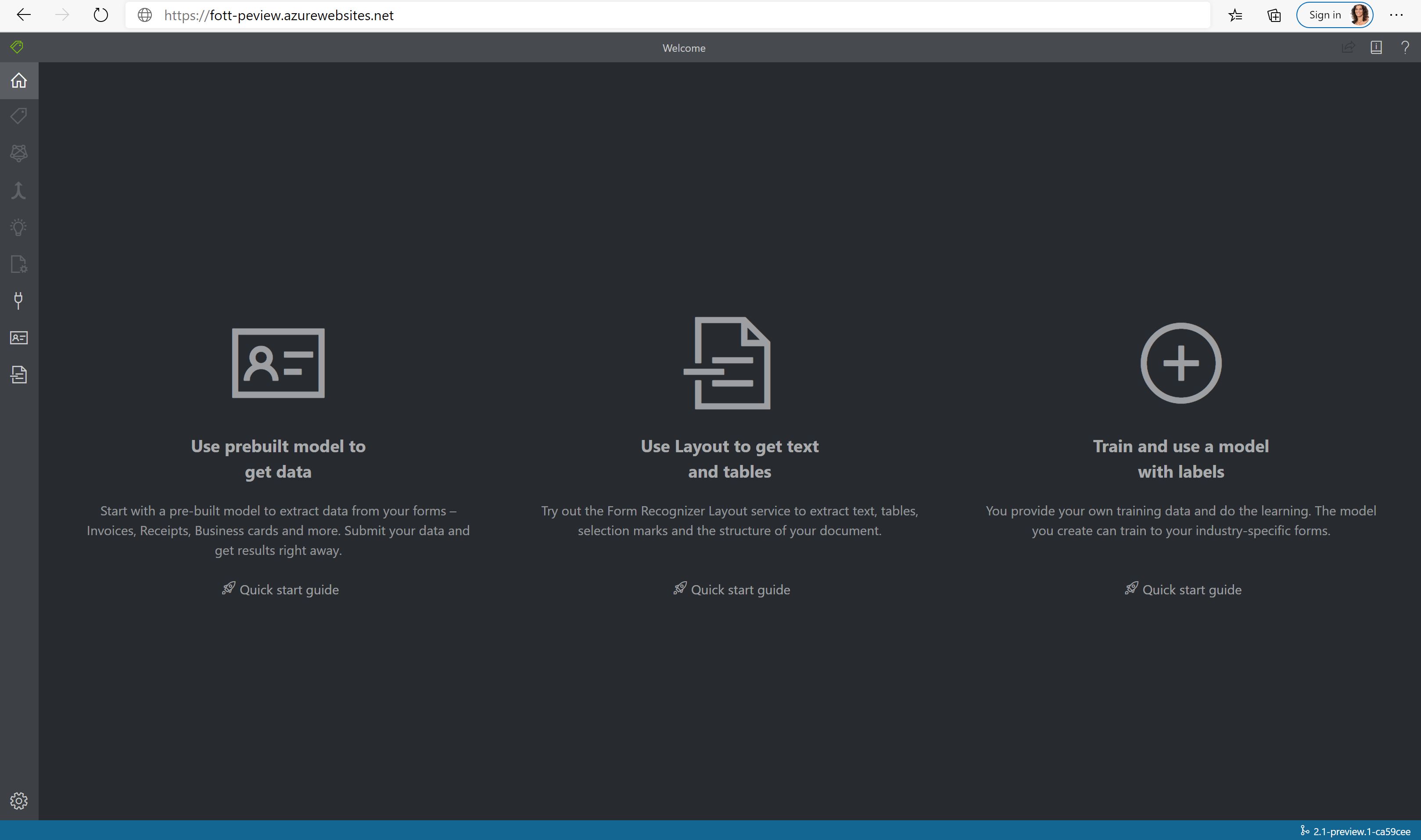
- 反馈循环 - 通过示例标记工具分析文件时,现在还可以将其添加到训练集,根据需要调整标记,并训练以改进模型。
- 自动标记文档 - 根据项目中以前标记的文档自动标记添加的文档。


2020 年 8 月
**文档智能
v2.1-preview.1包括以下功能:- REST API 参考已发布 - 查看
v2.1-preview.1 reference。 - 除了英语以外受支持的新语言,以下语言现在受支持:对于
Layout和Train Custom Model:英语 (en)、简体中文 (zh-Hans)、荷兰语 (nl)、法语 (fr)、德语 (de)、意大利语 (it)、葡萄牙语 (pt) 和西班牙语 (es)。 - 复选框/选择标记检测 - 文档智能支持检测和提取选择标记(如复选框和单选按钮)。 选择标记是在
Layout中提取的,你现在还可以在Train Custom Model- “使用标签进行训练”中进行标记和训练,以便提取选择标记的键值对。 - 模型组合 - 允许组合多个模型并使用单个模型 ID 调用。 提交要使用组合模型 ID 分析的文档时,首先会执行分类步骤以将其路由到正确的自定义模型。 模型组合可用于
Train Custom Model- “使用标签进行训练”。 - 模型名称 - 将友好名称添加到自定义模型,以便更轻松地进行管理和跟踪。
- 新的名片预生成模型,用于提取英语、语言名片中的公共字段。
- 预生成收据的新区域设置除 EN-US 外,现在还支持 EN-AU、EN-CA、EN-GB、EN-IN。
- 针对 、
Train Custom Model- “在没有标签的情况下进行训练”和“使用标签进行训练”的质量改进。
- REST API 参考已发布 - 查看
2.0 版包括以下更新:
- NET、Python、Java 和 JavaScript 的客户端库已正式发布。
可在 GitHub 上找到新示例。
- 知识提取方案 - 表单操作手册从真实的文档智能客户互动中收集最佳做法,并提供用于开发这些项目的可用代码示例、清单和示例管道。
- 示例标记工具已更新,以支持新的 2.1 版功能。 请参阅此快速入门,了解如何开始使用此工具。
- 智能展台文档智能示例显示了如何集成
Analyze Receipt和 “Train Custom Model- 在没有标签的情况下进行训练”。
2020 年 7 月
- 文档智能 2.0 版参考可用 - 查看 2.0 版 API 参考和适用于 .NET、Python、Java 和 JavaScript 的更新的客户端库。
表增强功能和提取增强功能 - 包括准确性改进和表提取增强功能,具体是指在“在没有标签的情况下自定义训练”中了解表头和结构的功能。
货币支持 - 检测和提取全球货币符号。
Azure Gov - 文档智能现已在 Azure Gov 提供。
增强的安全性功能:
- 自带密钥 - 文档智能会在保存到云时自动加密数据,以保护数据,并帮助你满足组织的安全性和合规性承诺。 默认情况下,订阅使用 Microsoft 托管的加密密钥。 你现在也可以使用自己的加密密钥来管理订阅。 客户管理的密钥(也称为自带密钥,BYOK),在创建、轮换、禁用和撤销访问控制方面可提供更大的灵活性。 此外,你还可以审核用于保护数据的加密密钥。
- 专用终结点 - 使你能够在虚拟网络中通过专用链接安全访问数据。
2020 年 6 月
- 添加到客户端库的 CopyModel API - 现在可以使用客户端库将模型从一个订阅复制到另一个订阅。 有关此功能的一般信息,请参阅备份和恢复模型。
- Azure Active Directory 集成 - 你现在可以使用你的 Azure AD 凭据对客户端库中的文档智能客户端对象进行身份验证。
- SDK 特定更改 - 此更改包括添加的次要功能和重大更改。 有关详细信息,请参阅 SDK 更改日志。
2020 年 4 月
- SDK 对文档智能 API 2.0 公共预览版的支持 - 本月,我们扩展了我们的服务支持,以包括适用于文档智能 2.0 的预览版 SDK。 使用以下链接开始使用你选择的语言:
- .NET SDK
- Java SDK
- Python SDK
- JavaScript SDK
新的 SDK 支持适用于文档智能的 v2.0 REST API 的所有功能。 可以通过 SDK 反馈表单分享有关客户端库的反馈。
复制自定义模型 你现在可以使用新的复制自定义模型功能在区域和订阅之间复制模型。 在调用“复制自定义模型”API 之前,必须先获取复制到目标资源的授权。 通过针对目标资源终结点调用“复制授权”操作来保护此授权。
生成复制授权 REST API。
复制自定义模型 REST API。
安全性改进。
客户管理的密钥现在可用于 FormRecognizer。 有关更多信息,请参阅文档智能的静态数据加密。
使用托管标识通过 Azure Active Directory 访问 Azure 资源。 有关更多信息,请参阅授权访问托管标识。
2020 年 3 月
- 用于标记的值类型 你现在可以指定使用文档智能示例标记工具标记的值类型。 目前支持以下值类型和变体:
string- default、
no-whitespaces、alphanumeric
- default、
number- default、
currency
- default、
date- default、
dmy、mdy、ymd
- default、
timeinteger
若要了解如何使用此功能,请参阅示例标记工具指南。
表可视化示例标记工具现在会显示在文档中识别的表。 利用此功能,可以在标记和分析之前先查看从该文档识别和提取的表。 可以使用“层”选项开启/关闭此功能。
下图是如何识别和提取表的示例:
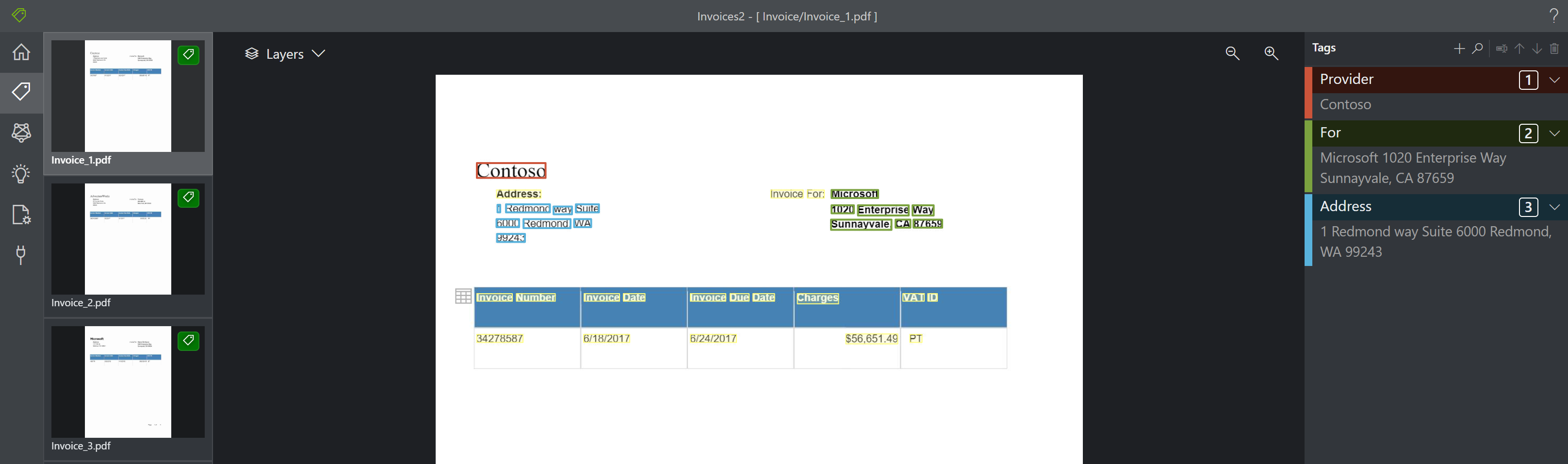
提取的表在 JSON 输出中的
"pageResults"下可用。重要
标记表不受支持。 如果无法识别并自动提取表,则只能将它们标记为键/值对。 如果将表标记为键/值对,请将每个单元标记为唯一值。
提取增强功能。
此版本包括提取增强功能和准确性改进,具体是指在同一文本行中标记和提取多个键/值对的功能。
示例标记工具现在为开源。
文档智能示例标记工具现在可作为开源项目提供。 你可以将其集成到你的解决方案中,并根据需要进行特定于客户的更改。
有关文档智能示例标记工具的更多信息,请查看 GitHub 上提供的文档。
TLS1.2 强制执行。现在会对此服务的所有 HTTP 请求强制执行
TLS1.2。 有关详细信息,请参阅 Azure AI 服务安全性。
2020 年 1 月
此版本引入了文档智能 2.0。 在后续部分,你将找到有关新功能、增强功能和更改的更多信息。
新增功能
自定义模型
- 使用标签进行训练 你现在可以使用手动标记的数据来训练自定义模型。 此方法会生成表现更好的模型,并且可以生成处理复杂表单或所含值没有键的表单的模型。
- 异步 API 可以使用异步 API 调用来训练和分析大型数据集和文件。
- TIFF 文件支持 你现在可以训练和提取 TIFF 文档中的数据。
- 提取准确性改进。
预生成收据模型
- 小费金额 你现在可以提取小费金额和其他手写值。
- 行项提取 你可以从收据中提取行项值。
- 置信度值 你可以查看模型对每个提取值的置信度。
- 提取准确性改进。
- 布局提取 你现在可以使用布局 API 从表单中提取文本数据和表数据。
自定义模型 API 更改
所有用于训练和使用自定义模型的 API 都已重命名,并且一些同步方法现在是异步的。 以下是主要更改:
- 模型训练过程现在是异步的。 通过 /custom/model API 调用发起训练。 此调用将返回一个操作 ID,你可以将该 ID 传递到 custom/models/{modelID} 以返回训练结果。
- 键/值提取现在由 /custom/models/{modelID}/analyze API 调用发起。 此调用将返回一个操作 ID,你可以将该 ID 传递到 custom/models/{modelID}/analyzeResults/{resultID} 以返回提取结果。
- 训练操作的操作 ID 现在位于 HTTP 响应的 Location 标头中,而非 Operation-Location 标头中。
收据 API 更改
用于读取销售收据的 API 已重命名。
收据数据提取现在由 /prebuilt/receipt/analyze API 调用发起。 此调用将返回一个操作 ID,你可以将该 ID 传递到 /prebuilt/receipt/analyzeResults/{resultID} 以返回提取结果。
输出格式更改
- 所有 API 调用的 JSON 响应都具有新格式。 已添加、移除或重命名某些键和值。 有关当前 JSON 格式的示例,请参阅快速入门。
后续步骤
尝试使用 Document Intelligence Studio 来处理你自己的表单和文档。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。
尝试使用文档智能示例标记工具来处理你自己的表单和文档。
完成文档智能快速入门,并使用你选择的开发语言开始创建文档处理应用。