你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
运行状况检查
CycleCloud 提供了两种用于检查 VM 运行状况的机制:节点运行状况检查是一项较新的功能,可在预配阶段执行检查并防止不正常的 VM 加入,而 HealthCheck 在 VM 作为节点加入群集后定期运行它们。
节点运行状况检查
节点运行状况检查可以在允许 VM 加入 CycleCloud 群集之前检测不正常的硬件。 此功能的当前版本将运行运行状况检查内置于 /opt/azurehpc/test/azurehpc-health-checks/ 下的官方 AzureHPC 映像中的脚本。 这些脚本的源位于 AzureHPC 节点运行状况检查存储库中,但请注意,内置于群集版本的 AzureHPC 映像的版本可能不是存储库中提供的最新版本。
要求
节点运行状况检查的当前版本仅支持 2023 年 11 月 7 日之后发布的 AzureHPC 映像, (包含 azurehpc-health-checks 版本 v2.0.6 或更高版本) 和派生自它们的自定义映像。 Windows 当前不支持节点运行状况检查。
为 Slurm 群集启用节点运行状况检查
Slurm 群集创建窗体提供了一个复选框,用于在 “高级设置” 选项卡下启用节点运行状况检查。选中此框可对群集的 HPC 节点数组启用节点运行状况检查。 如果要在其他节点数组上启用节点运行状况检查 (或其他群集类型) ,则必须使用自定义群集模板。
只需取消选中 该框,即可在正在运行的群集上禁用节点运行状况检查。 无需缩减节点数组即可使更改生效。
了解节点运行状况检查结果
VM 通过运行状况检查后,它将进入软件配置阶段。
如果 VM 无法通过任何运行状况检查脚本,则会向 CycleCloud 发送一条错误消息,并自动阻止该 VM 加入群集。
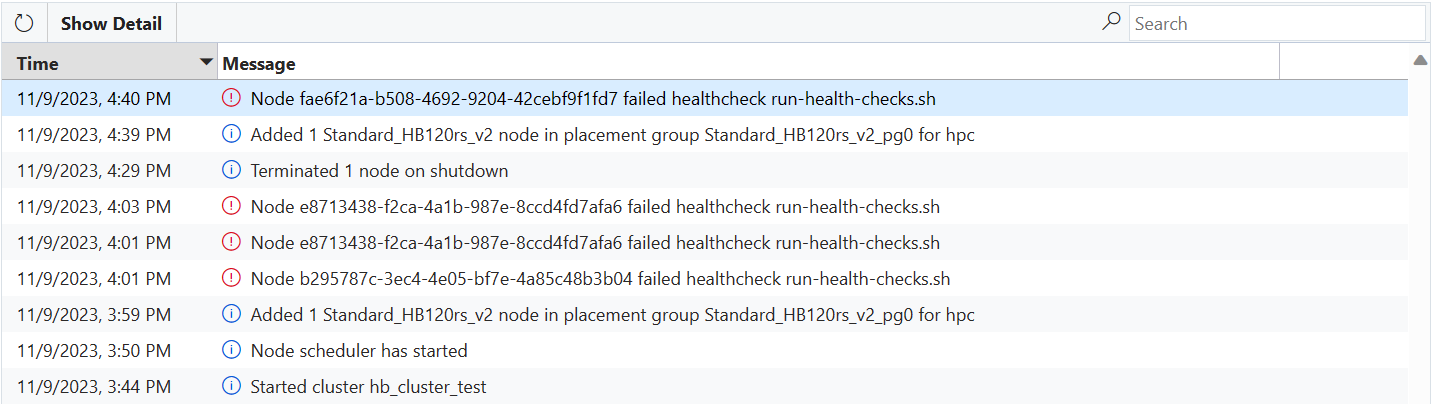
如果在启用过度预配的 NodeArray 中启动 VM, (例如 Slurm hpc Node Array) ,则 VM 应作为过度预配的一部分自动替换。 在这种情况下,无需执行任何操作,并且会选择正常的 VM 加入群集 (但群集页上会显示一条错误消息,指示) 一个或多个 VM 检查失败。
如果为单个节点启动 VM,禁用了过度预配的节点阵列 (例如 Slurm htc Node Array) ,或者如果 VM 未通过运行状况检查的 VM 数超过过度预配所支持的 VM 数,则节点将进入“失败”状态,分配将失败。 CycleCloud 可能会尝试重新映像 VM 以更正问题,但如果重新映像失败,则需要由管理员手动或自动缩放程序) (终止并替换节点。
注意
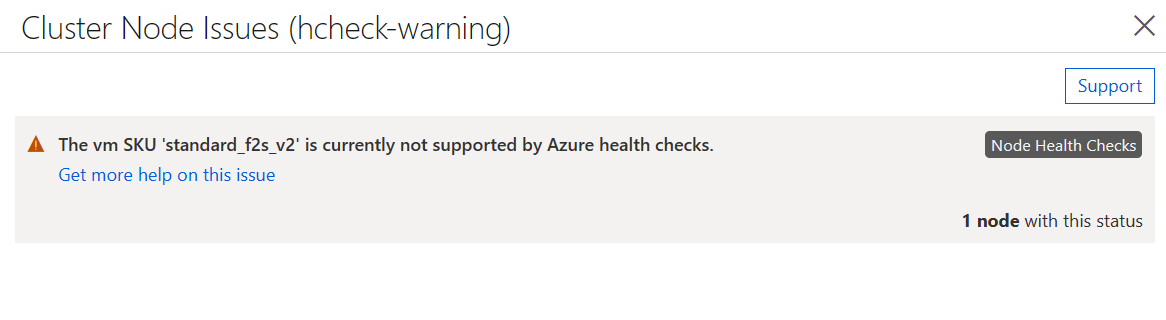
如果已启用节点运行状况检查,但 VM 映像不符合上述要求,则允许所有 VM 加入群集,但状态将包含一条警告,指示检查不受支持。
属性引用
| Attribute | 类型 | 定义 |
|---|---|---|
| EnableNodeHealthChecks | 布尔 | (可选) 为此节点或节点数组启用启动时节点运行状况检查 |
HealthCheck
Azure CycleCloud 提供了一种机制,用于终止虚拟机 (VM) 处于名为 HealthCheck 的不正常状态。 (Python 和 Bash) 的系统脚本和用户定义的脚本在 Windows 上定期运行 (5 分钟,在 Linux) 上运行 10 分钟,以确定 VM 的总体运行状况。 HealthCheck 允许管理员定义应终止 VM 的条件,而无需手动监视和修正。
内置 HealthCheck 脚本
已启用 CycleCloud 的 VM 附带两个默认 HealthCheck 脚本:
- converge_timeout脚本将在启动后四小时内终止尚未完成软件配置的实例。 可以使用设置 (以秒) 定义来控制
cyclecloud.keepalive.timeout此超时期限。 - scheduled_shutdown脚本在 $JETPACK_HOME/run/scheduled_shutdown 中查找 maker 文件,其中包含一行(以 Unix 时间戳秒为单位提供关机时间)和可选的第二行说明。 当当前时间晚于文件中最早的时间戳时,VM 被视为不正常。
工作原理
HealthCheck 脚本位于 $JETPACK_HOME/config/healthcheck.d 目录中。 Linux 支持 Python 和 Bash 脚本,而 Windows 仅支持 Python 脚本。 脚本应确定 VM 的运行状况。 如果发现 VM 运行不正常,脚本应退出,状态 254为 ,这向 CycleCloud 指示 VM 运行不正常,应终止。
登录到运行 HealthCheck 的 VM 后,可以通过运行 jetpack keepalive 命令来阻止 VM 关闭。 在 Linux 实例上,可以指定时间范围(以小时为单位)或在 forever Windows forever 上指定时间范围是唯一的选项。
注意
当确定 VM 运行不正常时,HealthCheck 代理会请求 CycleCloud 终止 VM,该 VM 永远不会通过 shutdown 命令在本地关闭。 如果 VM 无法与 CycleCloud 通信,则 VM 将保持运行状态,即使它处于不正常状态,直到可以到达 CycleCloud 的时间为止。
示例
作为一个简单的示例,我们将编写 HealthCheck 脚本,该脚本可确保 Linux VM 在 24 小时内不处于活动状态。 此脚本可用于模拟低优先级逐出,以测试工作流对逐出 VM 的反应。 此脚本将放置在 /opt/cycle/jetpack/config/healthcheck.d/healthcheck_example.sh 中
#!/bin/bash
# Get the uptime of the system (in seconds) and check to see if it is
# greater than 86,400 (24 hours in seconds). If it is, exit 254 to
# signal that the VM is unhealthy.
if (( $(cat /proc/uptime | awk '{print ($1 > 86400)}'))); then
exit 254
fi
注意
此脚本可以通过 CycleCloud 项目 放置在 VM 上,也可以在 创建自定义映像时直接添加它。