你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 数据工厂中的持续集成和交付
适用于: Azure 数据工厂
Azure 数据工厂  Azure Synapse Analytics
Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
持续集成是这样一种做法:自动尽早测试对代码库所做的每项更改。 在测试之后进行的持续交付可将更改推送到过渡或生产系统,而测试发生在持续集成期间。
在 Azure 数据工厂中,持续集成和交付 (CI/CD) 是指将数据工厂管道从一个环境(开发、测试、生产)移到另一个环境。 Azure 数据工厂利用 Azure 资源管理器模板存储各种 ADF 实体(管道、数据集、数据流等)的配置。 可通过两种建议的方式将数据工厂提升到另一个环境:
- 使用数据工厂与 Azure Pipelines 的集成进行自动化部署
- 使用数据工厂 UX 与 Azure 资源管理器的集成手动上传资源管理器模板。
注意
建议使用 Azure Az PowerShell 模块与 Azure 交互。 请参阅安装 Azure PowerShell 以开始使用。 若要了解如何迁移到 Az PowerShell 模块,请参阅 将 Azure PowerShell 从 AzureRM 迁移到 Az。
CI/CD 生命周期
注意
有关详细信息,请参阅持续部署改进。
下面是配置了 Azure Repos Git 的 Azure 数据工厂中的 CI/CD 生命周期示例概述。 若要详细了解如何配置 Git 存储库,请参阅 Azure 数据工厂中的源代码管理。
开发数据工厂是使用 Azure Repos Git 创建和配置的。 所有开发人员都应有权创作数据工厂资源,例如管道和数据集。
开发人员创建功能分支以进行更改。 他们使用最近的更改来调试其管道运行。 若要详细了解如何调试管道运行,请参阅使用 Azure 数据工厂进行迭代开发和调试。
对所做的更改满意以后,开发人员可以创建一个拉取请求,将请求从其功能分支拉取到主分支或协作分支,让同行来评审他们的更改。
在拉取请求获得批准并已将更改合并到主分支后,更改将发布到开发工厂。
团队在准备好将更改部署到测试或 UAT(用户验收测试)工厂后,会转到其 Azure Pipelines 发布阶段,并会将所需版本的开发工厂部署到 UAT。 此部署作为 Azure Pipelines 任务的一部分发生,使用资源管理器模板参数来应用相应的配置。
在测试工厂中验证更改后,将使用下一个管道发布任务部署到生产工厂。
注意
只有开发工厂才与 git 存储库相关联。 测试工厂和生产工厂不应有关联的 git 存储库,只能通过 Azure DevOps 管道或资源管理模板更新这些工厂。
下图突出显示了此生命周期的各个步骤。
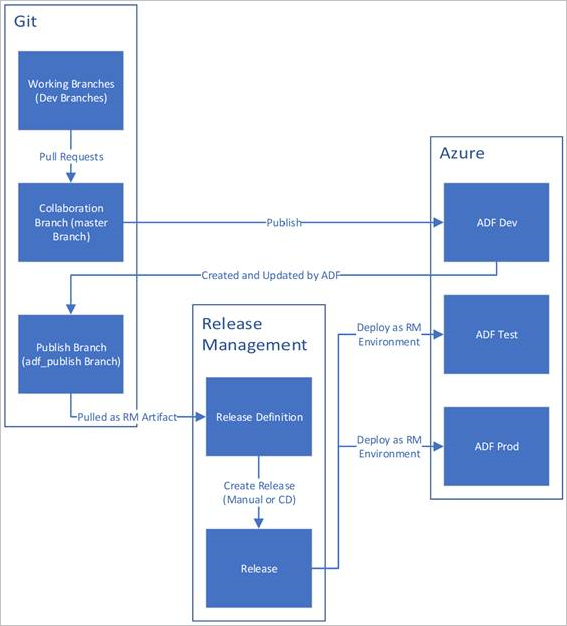
CI/CD 最佳做法
如果你使用数据工厂的 Git 集成,并且某个 CI/CD 管道会将更改从开发环境依次转移到测试和生产环境,则我们建议采用以下最佳做法:
Git 集成。 仅配置具有 Git 集成的开发数据工厂。 对测试和生产环境所做的更改将通过 CI/CD 进行部署,不需要 Git 集成。
部署前和部署后脚本。 在 CI/CD 中完成资源管理器部署步骤之前,需要先完成某些任务,例如停止再重启触发器并执行清理。 我们建议在执行部署任务之前和之后使用 PowerShell 脚本。 有关详细信息,请参阅更新活动触发器。 数据工厂团队已在本网页的末尾提供了一个可用的脚本。
注意
如果只是想关闭/打开已修改的触发器,而不是在 CI/CD 期间关闭/打开所有触发器,请使用 PrePostDeploymentScript.Ver2.ps1。
警告
确保在 ADO 任务中使用 PowerShell Core 来运行脚本。
警告
如果不使用最新版的 PowerShell 和数据工厂模块,可能会在运行命令时遇到反序列化错误。
集成运行时和共享。 集成运行时不经常更改,在 CI/CD 的所有阶段中都是类似的。 因此,数据工厂预期在 CI/CD 的所有阶段使用相同的集成运行时名称、类型和子类型。 若要在所有阶段中共享集成运行时,请考虑使用三元工厂,这只是为了包含共享的集成运行时。 可以在所有环境中将此共享工厂用作链接的集成运行时类型。
注意
集成运行时共享仅适用于自承载集成运行时。 Azure-SSIS 集成运行时不支持共享。
托管的专用终结点部署。 如果工厂中已经存在一个专用终结点,而你尝试部署的 ARM 模板包含一个名称相同但属性已修改的专用终结点,则部署将失败。 换句话说,只要专用终结点与工厂中已经存在的专用终结点具有相同的属性,就可以成功部署该终结点。 如果任何属性在不同的环境中是不同的,你可以通过参数化该属性并在部署期间提供相应的值来替代它。
Key Vault。 使用其连接信息存储在 Azure Key Vault 中的链接服务时,建议为不同的环境保留不同的密钥保管库。 此外,可为每个密钥保管库单独配置权限级别。 例如,你可能不希望团队成员有权访问生产机密。 如果采用此方法,我们建议在所有阶段中保留相同的机密名称。 如果保留相同的机密名称,则无需在 CI/CD 环境中参数化每个连接字符串,因为只需更改密钥保管库名称,而该名称是一个单独的参数。
资源命名。 由于 ARM 模板的约束,如果资源在名称中包含空格,部署中可能会出现问题。 Azure 数据工厂团队建议为资源使用“_”或“-”字符,而不是使用空格。 例如,“Pipeline_1”比“Pipeline 1”更可取。
更改存储库。 ADF 可自动管理 GIT 存储库内容。 在 ADF Git 存储库数据文件夹的任意位置更改或手动添加不相关的文件或文件夹可能会导致资源加载错误。 例如,如果存在 .bak 文件,则可能会导致 ADF CI/CD 错误,因此应将其移除,以便加载 ADF。
公开控制和功能标志。 在团队中工作时,在某些情况下,你可能想要合并更改,但不想这些更改在提升的环境(例如 PROD 和 QA)中运行。 为了应对这种情况,ADF 团队推荐有关使用功能标志的 DevOps 概念。 在 ADF 中,可以组合全局参数和 if condition 活动,以根据这些环境标志隐藏逻辑集。
若要了解如何设置功能标志,请参阅以下视频教程:
不支持的功能
按照设计,数据工厂不允许挑拣提交内容或选择性地发布资源。 发布将包含数据工厂中发生的所有更改。
- 数据工厂实体相互依赖。 例如,触发器依赖于管道,而管道又依赖于数据集和其他管道。 选择性发布资源子集可能会导致意外的行为和错误。
- 如果需要进行选择性发布(这种情况很少见),请考虑使用修补程序。 有关详细信息,请参阅修补程序生产环境。
Azure 数据工厂团队不建议将 Azure RBAC 控件分配给数据工厂中的单个实体(管道、数据集等)。 例如,如果开发人员可以访问管道或数据集,则他们应该能够访问数据工厂中的所有管道或数据集。 如果你认为需要在数据工厂中实现许多 Azure 角色,请考虑部署第二个数据工厂。
无法从专用分支发布。
目前无法在 Bitbucket 上托管项目。
当前无法以参数的形式导出和导入警报和矩阵。
在 adf_publish 分支下的代码存储库中,当前在“linkedTemplates”文件夹、“ARMTemplateForFactory.json”和“ARMTemplateParametersForFactory.json”文件旁边添加了一个名为“PartialArmTemplates”的文件夹,作为源代码管理发布的一部分。
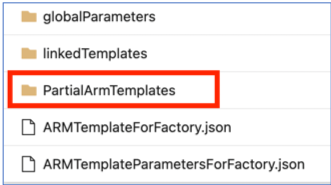
从 2021 年 11 月 1 日起,我们将不再向 adf_publish 分支发布“PartialArmTemplates”。
除非你使用的是“PartialArmTemplates”,否则不需要执行任何操作。 否则,请使用“ARMTemplateForFactory.json”或“linkedTemplates”文件切换到任何支持的部署机制。