你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
通过在 Azure Data Lake Analytics 上使用 Azure 数据工厂和 Synapse Analytics 运行 U-SQL 脚本来处理数据
适用于: Azure 数据工厂 Azure Synapse Analytics
Azure 数据工厂 Azure Synapse Analytics
提示
试用 Microsoft Fabric 中的数据工厂,这是一种适用于企业的一站式分析解决方案。 Microsoft Fabric 涵盖从数据移动到数据科学、实时分析、商业智能和报告的所有内容。 了解如何免费开始新的试用!
Azure 数据工厂或 Synapse Analytics 工作区中的管道通过使用链接计算服务来处理链接存储服务中的数据。 它包含一系列活动,其中每个活动执行特定的处理操作。 本文介绍在 Azure Data Lake Analytics 计算链接服务上运行 U-SQL 脚本的 Data Lake Analytics U-SQL 活动。
在使用 Data Lake Analytics U-SQL 活动创建管道之前,先创建 Azure Data Lake Analytics 帐户。 若要了解 Azure Data Lake Analytics,请参阅 Azure Data Lake Analytics 入门。
使用 UI 将 Azure Data Lake Analytics 的 U-SQL 活动添加到管道
若要在管道中将 U-SQL 活动用于 Azure Data Lake Analytics,请完成以下步骤:
在管道“活动”窗格中搜索“数据湖”,然后将 U-SQL 活动拖动到管道画布上。
在画布上选择新的 U-SQL 活动(如果尚未选择)。
选择“ADLA 帐户”选项卡以选择或创建将用于执行 U-SQL 活动的新 Azure Data Lake Analytics 链接服务。
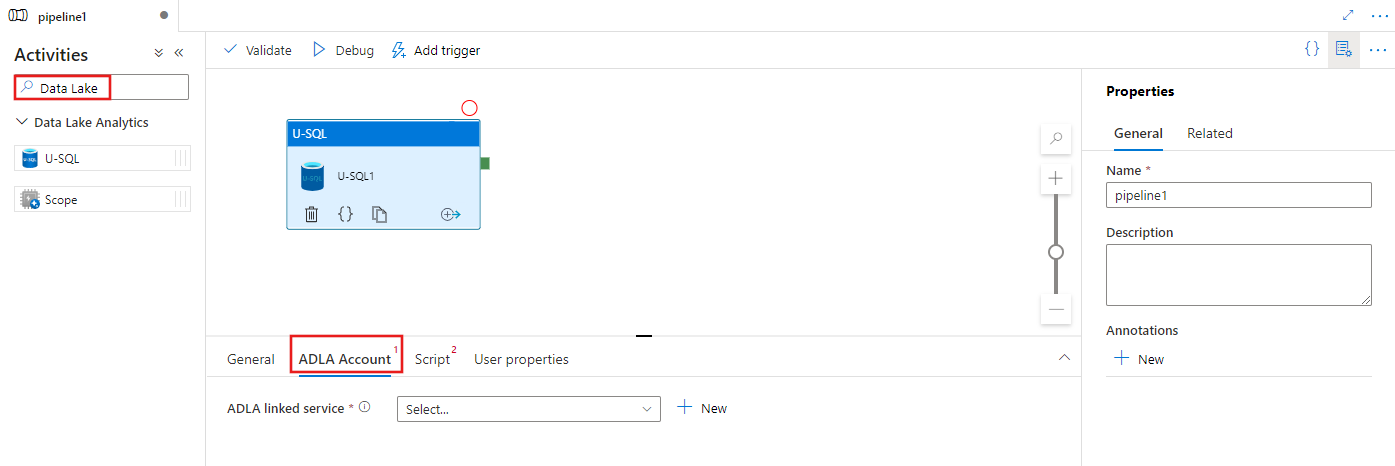
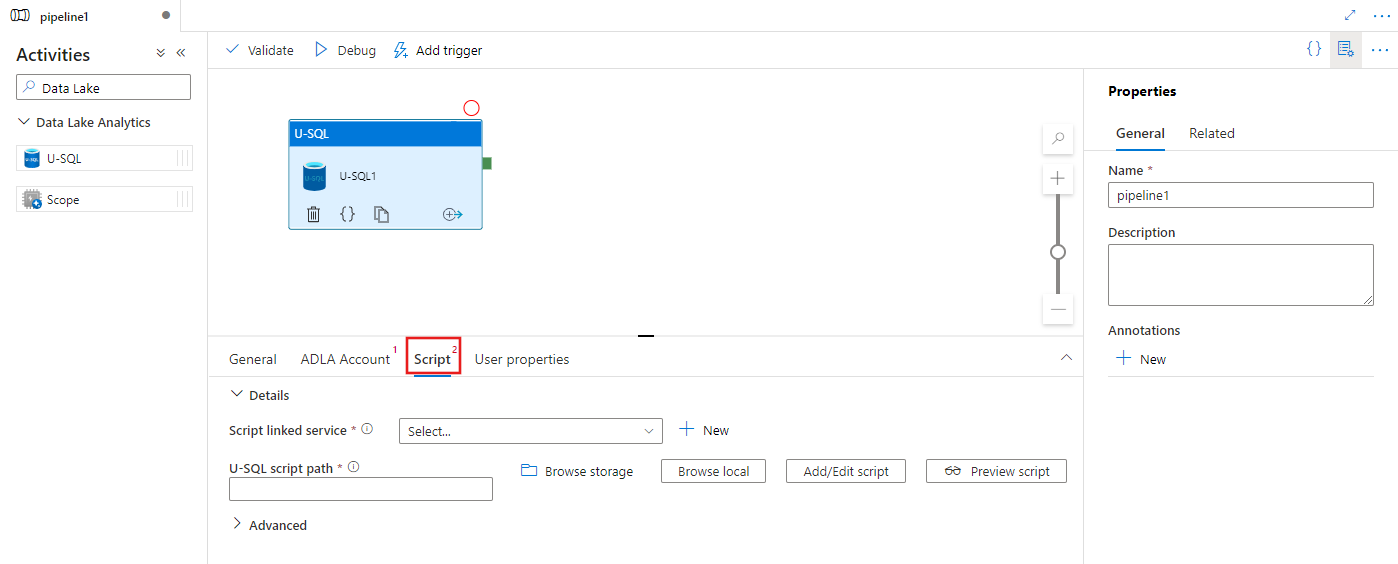
选择“脚本”选项卡以选择或创建新的存储链接服务,并在存储位置中选择一个路径,该路径将承载脚本。
Azure Data Lake Analytics 链接服务
创建 Azure Data Lake Analytics 链接服务将 Azure Data Lake Analytics 计算服务链接到 Azure 数据工厂或 Synapse Analytics 工作区。 管道中的 Data Lake Analytics U-SQL 活动是指此链接服务。
下表介绍了 JSON 定义中使用的一般属性。
| properties | 描述 | 必需 |
|---|---|---|
| type | 类型属性应设置为:AzureDataLakeAnalytics。 | 是 |
| accountName | Azure Data Lake Analytics 帐户名。 | 是 |
| dataLakeAnalyticsUri | Azure Data Lake Analytics URI。 | 否 |
| subscriptionId | Azure 订阅 ID | 否 |
| resourceGroupName | Azure 资源组名称 | 否 |
服务主体身份验证
Azure Data Lake Analytics 链接服务需要进行服务主体身份验证,才能连接到 Azure Data Lake Analytics 服务。 若要使用服务主体身份验证,在 Microsoft Entra ID 中注册应用程序实体,并向其授予对 Data Lake Analytics 及其使用的 Data Lake Store 的访问权限。 有关详细步骤,请参阅服务到服务身份验证。 记下下面的值,这些值用于定义链接服务:
- 应用程序 ID
- 应用程序密钥
- 租户 ID
使用添加用户向导向 Azure Data Lake Analytics 授予服务主体权限。
通过指定以下属性使用服务主体身份验证:
| 属性 | 描述 | 必选 |
|---|---|---|
| servicePrincipalId | 指定应用程序的客户端 ID。 | 是 |
| servicePrincipalKey | 指定应用程序的密钥。 | 是 |
| tenant | 指定应用程序的租户信息(域名或租户 ID)。 可将鼠标悬停在 Azure 门户右上角进行检索。 | 是 |
示例:服务主体身份验证
{
"name": "AzureDataLakeAnalyticsLinkedService",
"properties": {
"type": "AzureDataLakeAnalytics",
"typeProperties": {
"accountName": "<account name>",
"dataLakeAnalyticsUri": "<azure data lake analytics URI>",
"servicePrincipalId": "<service principal id>",
"servicePrincipalKey": {
"value": "<service principal key>",
"type": "SecureString"
},
"tenant": "<tenant info, e.g. microsoft.onmicrosoft.com>",
"subscriptionId": "<optional, subscription id of ADLA>",
"resourceGroupName": "<optional, resource group name of ADLA>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
若要了解有关链接服务的详细信息,请参阅计算链接服务。
Data Lake Analytics U-SQL 活动
以下 JSON 代码段定义了具有 Data Lake Analytics U-SQL 活动的管道。 活动定义具有对之前创建的 Azure Data Lake Analytics 链接服务的引用。 若要执行 Data Lake Analytics U-SQL 脚本,该服务会将你指定的脚本提交到 Data Lake Analytics,Data Lake Analytics 的脚本中将定义所需的输入和输出,以便提取和输出。
{
"name": "ADLA U-SQL Activity",
"description": "description",
"type": "DataLakeAnalyticsU-SQL",
"linkedServiceName": {
"referenceName": "<linked service name of Azure Data Lake Analytics>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"scriptLinkedService": {
"referenceName": "<linked service name of Azure Data Lake Store or Azure Storage which contains the U-SQL script>",
"type": "LinkedServiceReference"
},
"scriptPath": "scripts\\kona\\SearchLogProcessing.txt",
"degreeOfParallelism": 3,
"priority": 100,
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
}
}
下表描述了此活动特有的属性的名称和描述。
| 属性 | 描述 | 必需 |
|---|---|---|
| name | 管道中活动的名称 | 是 |
| description | 描述活动用途的文本。 | 否 |
| type | 对于 Data Lake Analytics U-SQL 活动,活动类型是 DataLakeAnalyticsU-SQL。 | 是 |
| linkedServiceName | Azure Data Lake Analytics 的链接服务。 若要了解此链接服务,请参阅计算链接服务一文。 | 是 |
| scriptPath | 包含 U-SQL 脚本的文件夹路径。 文件的名称区分大小写。 | 是 |
| scriptLinkedService | 链接服务链接包含脚本的 Azure Data Lake Store 或 Azure 存储 | 是 |
| degreeOfParallelism | 同时用于运行作业的最大节点数。 | 否 |
| priority | 确定应在所有排队的作业中选择哪些作业首先运行。 编号越低,优先级越高。 | 否 |
| parameters | 要传入 U-SQL 脚本的参数。 | 否 |
| runtimeVersion | 要使用的 U-SQL 引擎的运行时版本。 | 否 |
| compilationMode | U-SQL 编译模式。 必须是这些值之一:Semantic: 只执行语义检查和必要的健全性检查;Full: 执行完整编译,包括语法检查、优化、代码生成等;SingleBox: 执行完整编译,且 TargetType 设置为 SingleBox。 如果该属性未指定值,则服务器将确定最佳编译模式。 |
否 |
请参阅 SearchLogProcessing.txt 了解有关脚本定义的信息。
示例 U-SQL 脚本
@searchlog =
EXTRACT UserId int,
Start DateTime,
Region string,
Query string,
Duration int,
Urls string,
ClickedUrls string
FROM @in
USING Extractors.Tsv(nullEscape:"#NULL#");
@rs1 =
SELECT Start, Region, Duration
FROM @searchlog
WHERE Region == "en-gb";
@rs1 =
SELECT Start, Region, Duration
FROM @rs1
WHERE Start <= DateTime.Parse("2012/02/19");
OUTPUT @rs1
TO @out
USING Outputters.Tsv(quoting:false, dateTimeFormat:null);
在上面的脚本示例中,脚本的输入和输出分别在“@in”和“@out”参数中定义。 and 该服务使用“parameters”部分动态传递 U-SQL 脚本中的“@in”和“@out”参数值。
也可在 Azure Data Lake Analytics 服务上运行的作业的管道定义中指定其他属性,如 degreeOfParallelism 和 priority。
动态参数
在示例管道定义中,in 和 out 参数都分配有硬编码值。
"parameters": {
"in": "/datalake/input/SearchLog.tsv",
"out": "/datalake/output/Result.tsv"
}
可改为使用动态参数。 例如:
"parameters": {
"in": "/datalake/input/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/data.tsv",
"out": "/datalake/output/@{formatDateTime(pipeline().parameters.WindowStart,'yyyy/MM/dd')}/result.tsv"
}
在这种情况下,输入文件仍从 /datalake/input 文件夹中获取,输出文件仍在 /datalake/output 文件夹中生成。 文件名是基于触发管道时传入的窗口开始时间动态生成的。
相关内容
参阅以下文章了解如何以其他方式转换数据: