你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
将 Apache Hive 用作提取、转换和加载 (ETL) 工具
通常需要先将传入的数据清理并转换,才能将它载入适合用于分析的目标。 提取、转换和加载 (ETL) 操作可用于准备数据并将其载入数据目标。 HDInsight 上的 Apache Hive 可以读入非结构化数据、根据需要处理该数据,然后将该数据载入关系数据仓库,供决策支持系统使用。 在此方法中,从源中提取数据。 数据存储在自适应存储中,例如 Azure 存储 blob 或 Azure Data Lake Storage。 然后,使用一系列 Hive 查询对数据进行转换。 接下来,将数据暂存在 Hive 中,为批量载入到目标数据存储中做好准备。
用例和模型概述
下图提供 ETL 自动化用例和模型的概述。 将转换输入数据以生成适当的输出。 在转换期间,数据会更改形状、数据类型甚至语言。 ETL 过程可将英制转换为公制、更改时区和提高精确度,以便与目标中现有的数据相符。 ETL 过程还可将新数据与现有数据相结合来更新报告,或者提供现有数据的更深入见解。 然后,应用程序(例如报告工具和服务)能以所需的格式使用此数据。
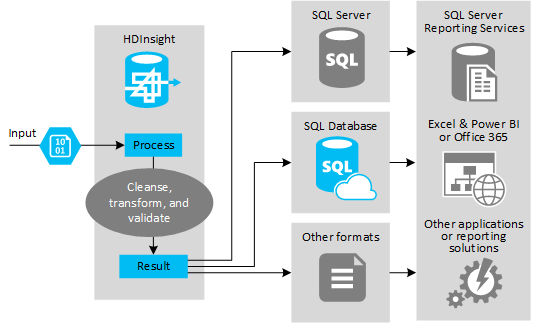
在导入大量文本文件(例如 CSV)或数量较少但经常更改的文本文件。 或上述两者兼具的 ETL 过程中,通常使用 Hadoop。 Hive 是一个很好的工具,可以在将数据载入数据目标之前先准备好数据。 在 Hive 中,可以基于 CSV 创建架构,然后使用类似于 SQL 的语言来生成与数据交互的 MapReduce 程序。
使用 Hive 执行 ETL 的典型步骤如下:
将数据载入 Azure Data Lake Storage 或 Azure Blob 存储。
创建元数据存储数据库(使用 Azure SQL 数据库)供 Hive 用于存储架构。
创建 HDInsight 群集并连接数据存储。
定义要在读取阶段应用到数据存储中的数据的架构:
DROP TABLE IF EXISTS hvac; --create the hvac table on comma-separated sensor data stored in Azure Storage blobs CREATE EXTERNAL TABLE hvac(`date` STRING, time STRING, targettemp BIGINT, actualtemp BIGINT, system BIGINT, systemage BIGINT, buildingid BIGINT) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE LOCATION 'wasbs://{container}@{storageaccount}.blob.core.windows.net/HdiSamples/SensorSampleData/hvac/';转换数据并将其载入目标。 在转换和加载期间,可通过多种方式使用 Hive:
- 使用 Hive 查询和准备数据,并将其以 CSV 格式存储在 Azure Data Lake Storage 或 Azure Blob 存储中。 然后,使用 SQL Server Integration Services (SSIS) 等工具获取这些 CSV,并将数据载入 SQL Server 等目标关系数据库。
- 使用 Hive ODBC 驱动程序直接从 Excel 或 C# 查询数据。
- 使用 Apache Sqoop 读取已准备好的 CSV 平面文件,并将其载入目标关系数据库。
数据源
数据源通常是可与数据存储中现有数据进行匹配的外部数据,例如:
- 社交媒体数据、日志文件、传感器,以及生成数据文件的应用程序。
- 从数据提供程序获取的数据集,例如天气统计信息或供应商销售数字。
- 通过适当的工具或框架捕获、筛选和处理的数据。
输出目标
可以使用 Hive 将数据输出到不同种类的目标,其中包括:
- 关系数据库,例如 SQL Server 或 Azure SQL 数据库。
- 数据仓库,如 Azure Synapse Analytics。
- Excel。
- Azure 表和 Blob 存储。
- 要求将数据处理成特定格式或处理成包含特定类型的信息结构的应用程序或服务。
- JSON 文档存储,如 Azure Cosmos DB。
注意事项
有以下需要时,通常可以使用 ETL 模型:
* 将流数据或大量半结构化或非结构化数据从外部源载入现有数据库或信息系统。
* 在加载数据之前,先清理、转换和验证这些数据(也许是通过群集使用多个转换阶段执行此操作)。
* 生成定期更新的报表和可视化效果。 例如,如果在日间生成报表耗时太长,可以安排在夜间运行报告。 若要自动运行 Hive 查询,可以使用 Azure 逻辑应用和 PowerShell。
如果数据目标不是数据库,可以在查询中以相应格式(例如 CSV)生成文件。 然后,可将此文件导入 Excel 或 Power BI。
如果需要在 ETL 过程中对数据执行多个操作,请考虑如何管理这些操作。 由于操作由外部程序而不是解决方案中的工作流控制,因此需确定某些操作是否可以并行执行。 还应检测每项作业何时完成。 与使用外部脚本或自定义程序来尝试协调一系列操作相比,使用工作流机制(例如 Hadoop 中的 Oozie)可能更方便。