你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 HDInsight Spark 群集分析 Data Lake Storage Gen1 中的数据
本文使用随 HDInsight Spark 群集提供的 Jupyter Notebook 运行作业,以便从 Data Lake Storage 帐户中读取数据。
先决条件
Azure Data Lake Storage Gen1 帐户。 请遵循通过 Azure 门户开始使用 Azure Data Lake Storage Gen1 中的说明进行操作。
包含 Data Lake Storage Gen1 作为存储的 Azure HDInsight Spark 群集。 按照快速入门:在 HDInsight 中设置群集中的说明进行操作。
准备数据
注意
如果已创建将 Data Lake Storage 作为默认存储的 HDInsight 群集,则无需执行此步骤。 群集创建过程在创建群集时指定的 Data Lake Storage 帐户中添加一些示例数据。 跳转到“配合使用 HDInsight Spark 群集与 Data Lake Storage”一节。
如果创建了将 Data Lake Storage 作为附加存储并将 Azure 存储 Blob 作为默认存储的 HDInsight 群集,则应先将一些示例数据复制到 Data Lake Store 帐户。 可以使用与 HDInsight 群集关联的 Azure 存储 Blob 中的示例数据。
打开命令提示符,并导航到 AdlCopy 的安装目录(通常是
%HOMEPATH%\Documents\adlcopy)。运行以下命令,将特定的 Blob 从源容器复制到 Data Lake Storage:
AdlCopy /source https://<source_account>.blob.core.windows.net/<source_container>/<blob name> /dest swebhdfs://<dest_adls_account>.azuredatalakestore.net/<dest_folder>/ /sourcekey <storage_account_key_for_storage_container>将 /HdiSamples/HdiSamples/SensorSampleData/hvac/ 中的 HVAC.csv 示例数据文件复制到 Azure Data Lake Storage 帐户。 代码段应如下所示:
AdlCopy /Source https://mydatastore.blob.core.windows.net/mysparkcluster/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv /dest swebhdfs://mydatalakestore.azuredatalakestore.net/hvac/ /sourcekey uJUfvD6cEvhfLoBae2yyQf8t9/BpbWZ4XoYj4kAS5Jf40pZaMNf0q6a8yqTxktwVgRED4vPHeh/50iS9atS5LQ==警告
请确保文件和路径名称使用正确的大小写。
系统会提示输入 Azure 订阅(其下提供 Data Lake Storage 帐户)的凭据。 会显示类似于以下代码片段的输出:
Initializing Copy. Copy Started. 100% data copied. Copy Completed. 1 file copied.会将数据文件 (HVAC.csv) 复制到 Data Lake Storage 帐户中的 /hvac 文件夹下。
使用包含 Data Lake Store Gen1 的 HDInsight Spark 群集
在 Azure 门户上的启动板中,单击 Apache Spark 群集的磁贴(如果已将它固定到启动板)。 也可以单击“全部浏览”>“HDInsight 群集”导航到群集。
在 Spark 群集边栏选项卡中单击“快速链接”,并在“群集仪表板”边栏选项卡中单击“Jupyter 笔记本”。 出现提示时,请输入群集的管理员凭据。
注意
也可以在浏览器中打开以下 URL 来访问群集的 Jupyter 笔记本。 将 CLUSTERNAME 替换为群集的名称:
https://CLUSTERNAME.azurehdinsight.net/jupyter创建新的笔记本。 单击“新建”,并单击“PySpark”。
使用笔记本是使用 PySpark 内核创建的,因此不需要显式创建任何上下文。 运行第一个代码单元格时,系统会自动创建 Spark 和 Hive 上下文。 首先可以导入此方案所需的类型。 为此,请将以下代码片段粘贴到某个单元中,然后按 SHIFT + ENTER。
from pyspark.sql.types import *每次在 Jupyter 中运行作业时,Web 浏览器窗口标题中都会显示“(繁忙)”状态和笔记本标题。 右上角“PySpark”文本的旁边还会出现一个实心圆。 作业完成后,实心圆将变成空心圆。

使用已复制到 Data Lake Storage Gen1 帐户的 HVAC.csv 文件将示例数据加载到临时表。 可使用以下 URL 模式访问 Data Lake Storage 帐户中的数据。
如果将 Data Lake Storage Gen1 作为默认存储,则 HVAC.csv 位于类似以下 URL 的路径中:
adl://<data_lake_store_name>.azuredatalakestore.net/<cluster_root>/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv也可使用如下所示的缩写格式:
adl:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv如果将 Data Lake Storage 作为附加存储,则 HVAC.csv 位于复制它的位置,如:
adl://<data_lake_store_name>.azuredatalakestore.net/<path_to_file>在空白单元格中,粘贴以下代码示例,将 MYDATALAKESTORE 替换为自己的 Data Lake Storage 帐户名称,然后按 Shift + Enter。 此代码示例会将数据注册到名为 hvac的临时表中。
# Load the data. The path below assumes Data Lake Storage is default storage for the Spark cluster hvacText = sc.textFile("adl://MYDATALAKESTORazuredatalakestore. net/cluster/mysparkclusteHdiSamples/HdiSamples/ SensorSampleData/hvac/HVAC.csv") # Create the schema hvacSchema = StructType([StructField("date", StringTy(), False) ,StructField("time", StringType(), FalseStructField ("targettemp", IntegerType(), FalseStructField("actualtemp", IntegerType(), FalseStructField("buildingID", StringType(), False)]) # Parse the data in hvacText hvac = hvacText.map(lambda s: s.split(",")).filt(lambda s: s [0] != "Date").map(lambda s:(str(s[0]), s(s[1]), int(s[2]), int (s[3]), str(s[6]) )) # Create a data frame hvacdf = sqlContext.createDataFrame(hvac,hvacSchema) # Register the data fram as a table to run queries against hvacdf.registerTempTable("hvac")
由于使用的是 PySpark 内核,因此现在可直接在刚才使用
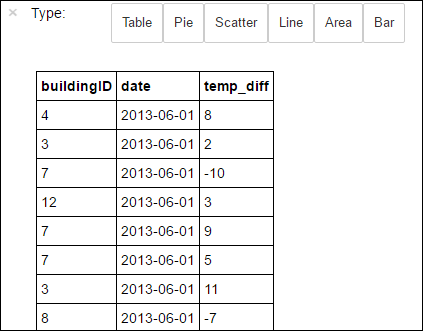
%%sqlmagic 创建的临时表 hvac 上运行 SQL 查询。 有关%%sqlmagic 以及可在 PySpark 内核中使用的其他 magic 的详细信息,请参阅包含 Apache Spark HDInsight 群集的 Jupyter Notebook 上可用的内核。%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"作业成功完成后,默认情况下会显示以下表格输出。
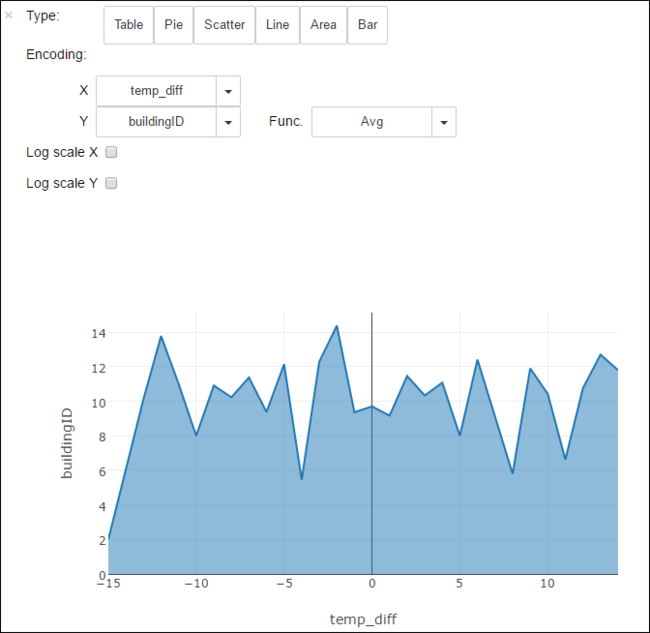
也可以在其他视觉效果中查看结果。 例如,同一输出的分区图看起来如下所示。
完成运行应用程序之后,应该要关闭笔记本以释放资源。 为此,请在笔记本的“文件”菜单中,单击“关闭并停止”。 这会关闭笔记本。