选择参数优化机器学习工作室(经典)中的算法
适用于: 机器学习工作室(经典)
机器学习工作室(经典) Azure 机器学习
Azure 机器学习
重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
本主题介绍如何为机器学习工作室(经典)中的算法选择合适的超参数集。 大多数机器学习算法使用参数来设置。 训练模型时,需要为这些参数提供值。 经过训练的模型效力取决于选择的模型参数。 查找最佳参数集的过程称为模型选择。
有多种方法可选择模型。 在机器学习中,交叉验证是模型选择中最广泛使用的方法之一,并且是机器学习工作室(经典)中的默认模型选择机制。 由于机器学习工作室(经典)支持 R 和 Python,因此你始终可以使用 R 或 Python 执行其自己的模型选择机制。
查找最佳参数集有四个步骤:
- 定义参数空间:对于算法,首先决定要考虑的确切参数值。
- 定义交叉验证设置:决定如何为数据集选择交叉验证折叠。
- 定义指标:决定用于确定最佳参数集的指标,例如准确性、均方根误差、精度、撤销率或 F 分数。
- 训练、评估和比较:对于每个独一无二的参数值组合,交叉验证基于定义的误差指标进行执行。 评估和比较后,可选择最佳模型。
下图说明了如何在机器学习工作室(经典)中执行此操作。
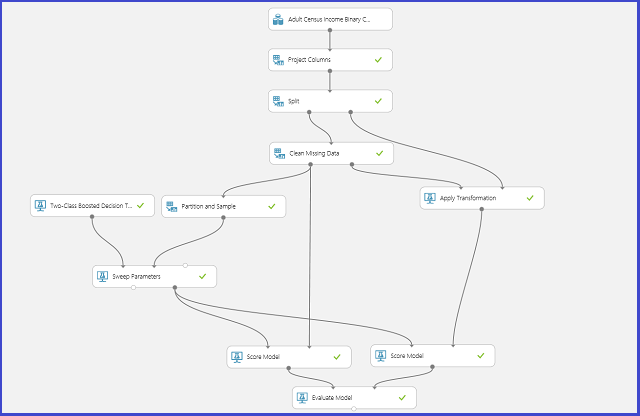
定义参数空间
可在模型初始化步骤中定义参数集。 所有机器学习算法的参数窗格中具有两个训练模式:单个参数和参数范围。 选择参数范围模式。 在参数范围模式下,可为每个参数输入多个值。 可在文本框中输入以逗号分隔的值。
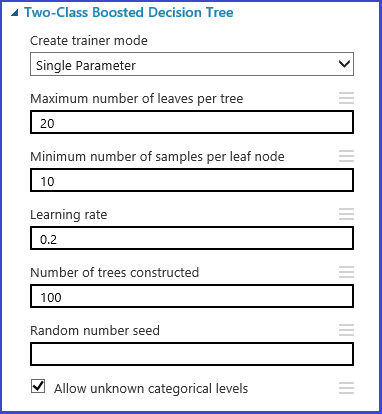
或者,使用使用范围生成器定义网格的最大和最小网格点和生成的总点数。 默认情况下,参数值按线性刻度生成。 但是,如果“对数刻度”处于选中状态,这些值会在对数刻度中生成(即相邻点的比率是常量,而不是它们的差)。 对于整数参数,可使用连字符定义范围。 例如,“1-10”是指介于 1 到 10(两者均含)之间的所有整数构成参数集。 也支持混合模式。 例如,参数集“1-10, 20, 50”将包括整数 1-10、20 和 50。
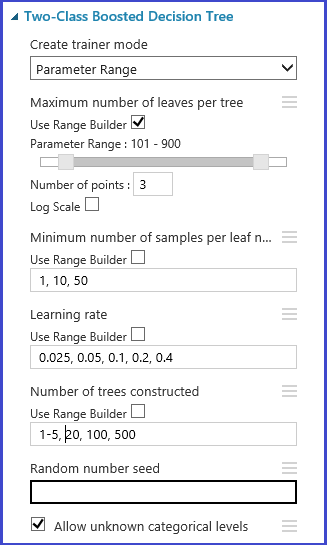
定义交叉验证折叠
分区和示例模块可用于随机将折叠分配到数据。 在模块的以下示例配置中,我们定义 5 个折叠并随机将折叠号分配到示例实例。
定义指标
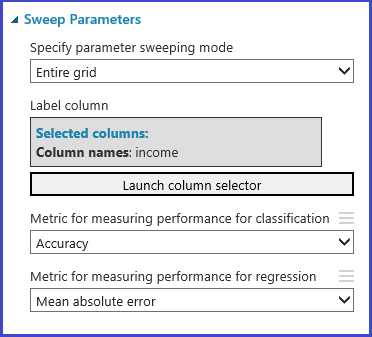
优化模型超参数 模块支持为给定算法和数据集凭经验选择最佳参数集。 除了有关训练模型的其他信息,此模块的“属性”窗格包括确定最佳参数集的指标。 它分别具有两个不同的下拉列表框用于分类和回归算法。 如果正在考虑的算法是分类算法,则忽略回归指标,反之亦然。 在此特定示例中,该指标为准确性。
训练、评估和比较
相同的优化模型超参数 模块训练所有对应于参数集的模型、评估各种指标并基于所选指标创建训练最佳的模型。 此模块具有两个必需输入:
- 未训练的学习器
- 数据集
该模块还具有一个可选数据集输入。 使用折叠信息将数据集连接到必需数据集输入。 如果未向数据集分配任何折叠信息,那么默认情况下会自动执行 10 个折叠交叉验证。 如果未执行折叠分配且在可选数据集端口提供验证数据集,则将选择训练-测试模式且第一个数据集用于为每个参数组合训练模型。
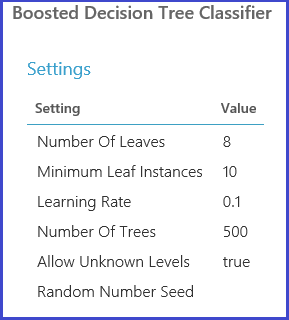
然后会在验证数据集上评估模型。 模块的左侧输出端口显示不同的指标作为参数值的函数。 右输出端口根据所选指标提供对应于最佳模型的已训练模型(本例中为准确性)。
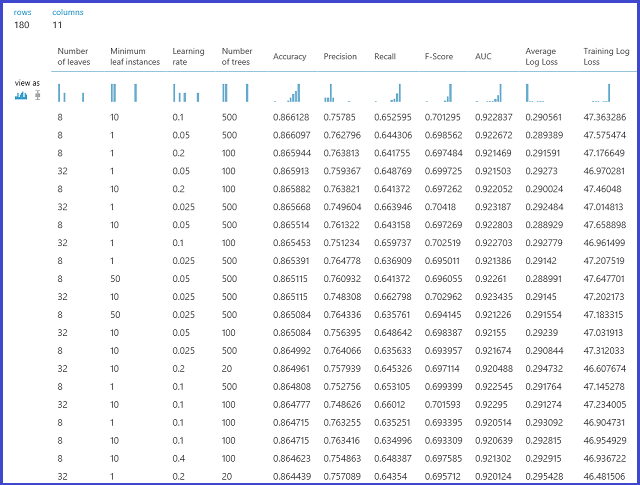
可以通过可视化右侧输出端口查看所选的确切参数。 保存为已训练模型后,此模型可用于对测试集进行评分或可操作性 Web 服务。