你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
在 Azure 机器学习设计器中转换数据
本文介绍如何在 Azure 机器学习设计器中转换和保存数据集,从而为机器学习准备好自己的数据。
你将使用 Adult Census Income Binary Classification(成人普查收入的二元分类)示例数据集来准备两个数据集:一个数据集包含仅来自美国的成年人口信息,另一个数据集包含来自非美国成人的人口信息。
本文将指导如何进行以下操作:
- 转换数据集以准备用于训练。
- 将生成的数据集导出到数据存储。
- 查看结果。
此操作说明是如何重新训练设计器模型文章的先决条件。 在本文中,你将了解如何使用转换后的数据集,通过管道参数训练多个模型。
重要
如果看不到本文档中提到的图形元素(例如工作室或设计器中的按钮),则可能没有正确级别的工作区权限。 请与 Azure 订阅管理员联系,验证是否已向你授予正确级别的访问权限。 有关详细信息,请访问管理用户和角色。
转换数据集
在此部分中,你将了解如何导入示例数据集并将数据拆分为美国数据集和非美国数据集。 若要详细了解如何将自己的数据导入到设计器,请访问如何导入数据。
导入数据
按照以下步骤导入示例数据集:
登录到 Azure 机器学习工作室,并选择要使用的工作区
转到设计器。 选择“使用经典预生成组件创建新管道”创建新管道
在管道画布左侧的“组件”选项卡中,展开“示例数据”节点
将“Adult Census Income Binary classification”数据集拖放到画布上
右键选择“成年人口收入”数据集组件,然后选择“预览数据”
使用数据预览窗口浏览数据集。 请特别注意“native-country”列值
拆分数据
在此部分中,会使用“拆分数据”组件标识和拆分在“native-country”列中包含“United-States”的行
在画布左侧的组件选项卡中,展开“数据转换”部分并找到“拆分数据”组件
将“拆分数据”组件拖动到画布上,并将组件放置在数据集组件下
将此数据集组件连接到“拆分数据”组件
选择“拆分数据”组件,打开“拆分数据”窗格
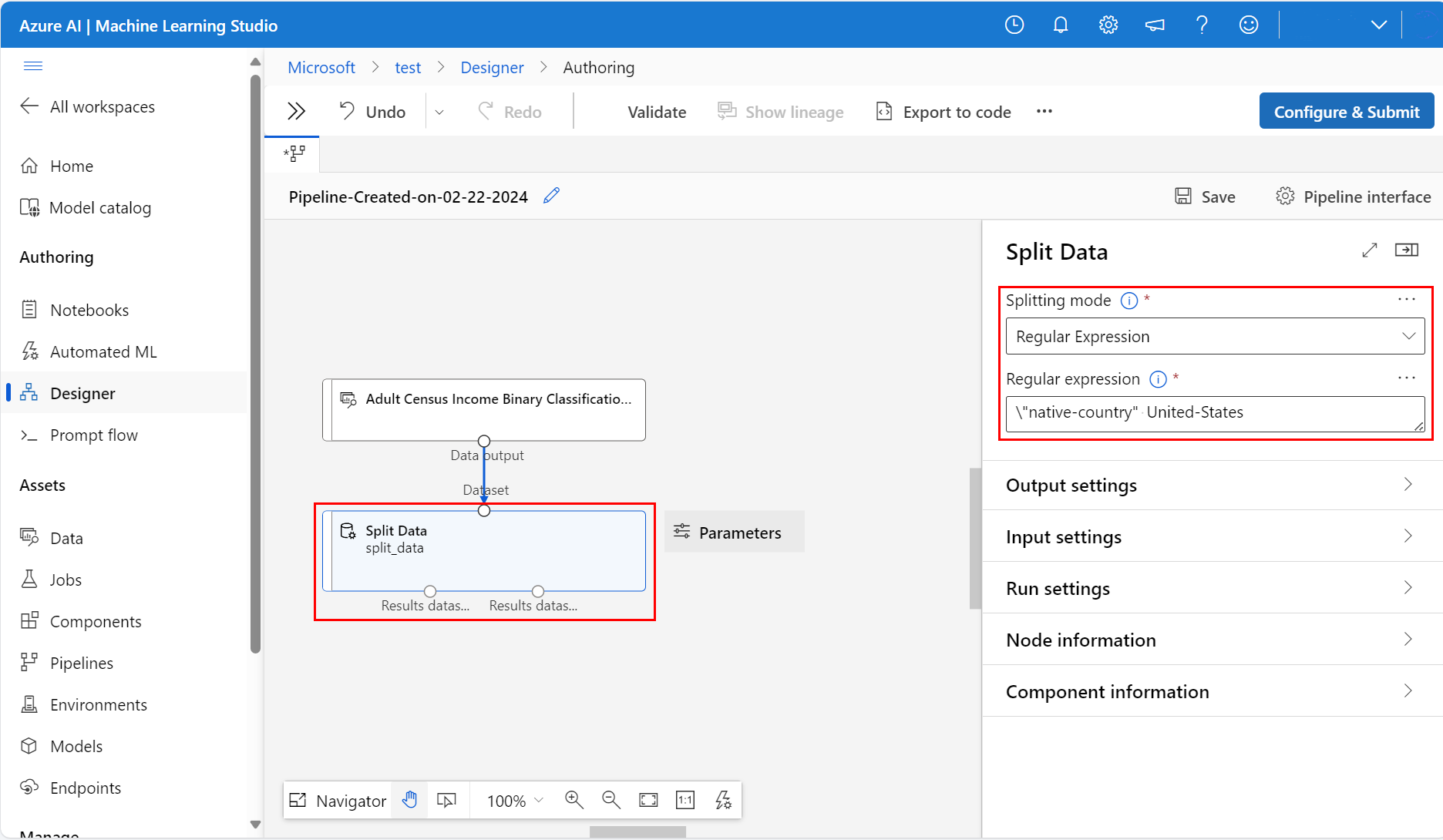
在画布右侧的“参数”图标中,将“拆分模式”设置为“正则表达式”
输入“正则表达式”:
\"native-country" United-States“正则表达式”模式对值测试单列。 有关“拆分数据”组件的详细信息,请参阅相关算法组件参考页
你的管道应如此屏幕截图所示:
保存数据集
现在你已设置了管道来拆分数据,接下来必须指定保存数据集的位置。 对于此示例,请使用“导出数据”组件将数据集保存到数据存储。 有关数据存储的详细信息,请访问连接到 Azure 存储服务。
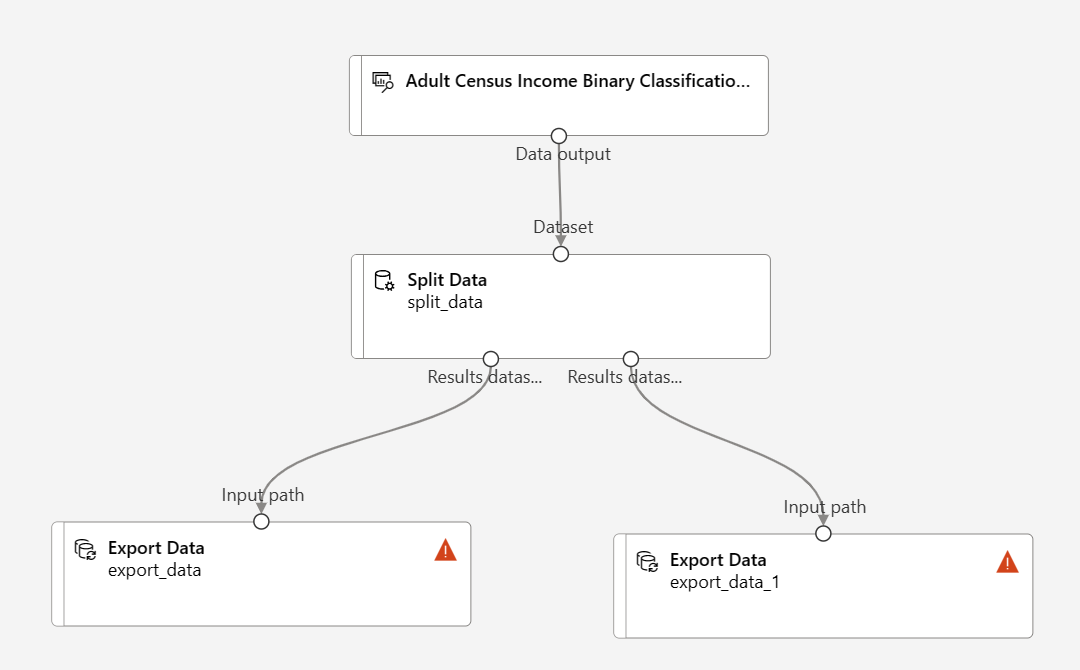
在画布左侧的组件控制板中,展开“数据输入和输出”部分并找到“导出数据”组件
将两个“导出数据”组件拖放到“拆分数据”组件下
将“拆分数据”组件的每个输出端口都连接到不同的“导出数据”组件
你的管道应如下所示:
选择连接到“拆分数据”组件的最左侧端口的“导出数据”组件,打开“导出数据”配置窗格
对于“拆分数据”组件,输出端口的顺序很重要。 第一个输出端口包含正则表达式为 true 的行。 在此例中,第一个端口包含基于美国的收入的行,第二个端口包含基于美国以外的收入的行
在画布右侧的组件详细信息窗格中,设置以下选项:
数据存储类型:Azure Blob 存储
数据存储:选择现有数据存储,或者选择“新建数据存储”来新建一个
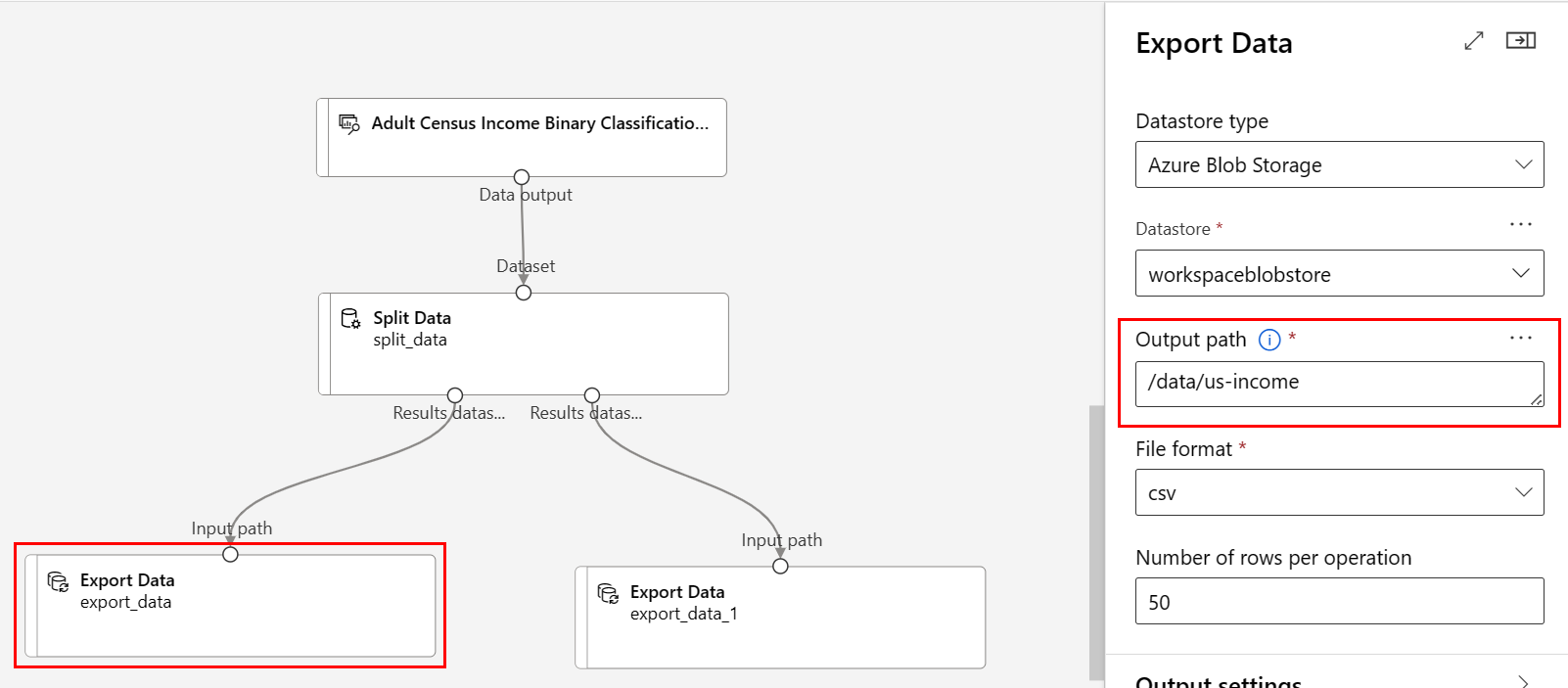
路径:
/data/us-income文件格式:csv
注意
本文假设你有权访问注册到当前 Azure 机器学习工作区的数据存储。 有关数据存储设置说明,请访问连接到 Azure 存储服务
如果现在没有数据存储,可创建一个。 例如,本文会将数据集保存到与工作区关联的默认 blob 存储帐户。 它会将数据集保存到名为
data的新文件夹中的azureml容器选择连接到“拆分数据”组件的最右侧端口的“导出数据”组件,打开“导出数据”配置窗格
在画布右侧的组件细节窗格中,设置以下选项:
数据存储类型:Azure Blob 存储
数据存储:选择以前的数据存储
路径:
/data/non-us-income文件格式:csv
验证连接到“拆分数据”左侧端口的“导出数据”组件是否具有路径
/data/us-income验证连接到右侧端口的“导出数据”组件是否具有路径
/data/non-us-income管道和设置应如下所示:
提交作业
现在你已设置了管道来拆分和导出数据,接下来请提交管道作业。
在画布顶部选择“配置和提交”
在“设置管道作业”的“基本信息”窗格中,选择“新建”选项以创建试验
试验将相关管道作业以逻辑方式分组在一起。 如果在将来运行此管道,则应使用相同试验进行日志记录和跟踪
提供描述性试验名称,例如“split-census-data”
选择“查看 + 提交”,然后选择“提交”
查看结果
管道运行完成后,可导航到 Azure 门户 Blob 存储来查看结果。 还可以查看“拆分数据”组件的中间结果,以确认数据正确拆分。
选择“拆分数据”组件
在画布右侧的组件详细信息窗格中,选择“输出 + 日志”选项卡
选择“显示数据输出”下拉列表
选择“结果数据集 1”旁的可视化图标

验证“native-country”列是否只包含值“United-States”
选择“结果数据集 2”旁的可视化图标
验证“native-country”列是否不包含值“United-States”
清理资源
若要继续学习第二部分(使用 Azure 机器学习设计器重新训练模型操作说明),请跳过此部分。
重要
可以使用你创建的、用作其他 Azure 机器学习教程和操作指南文章的先决条件的资源。
删除所有内容
如果你不打算使用所创建的任何内容,请删除整个资源组,以免产生任何费用。
在 Azure 门户的窗口左侧选择“资源组”。
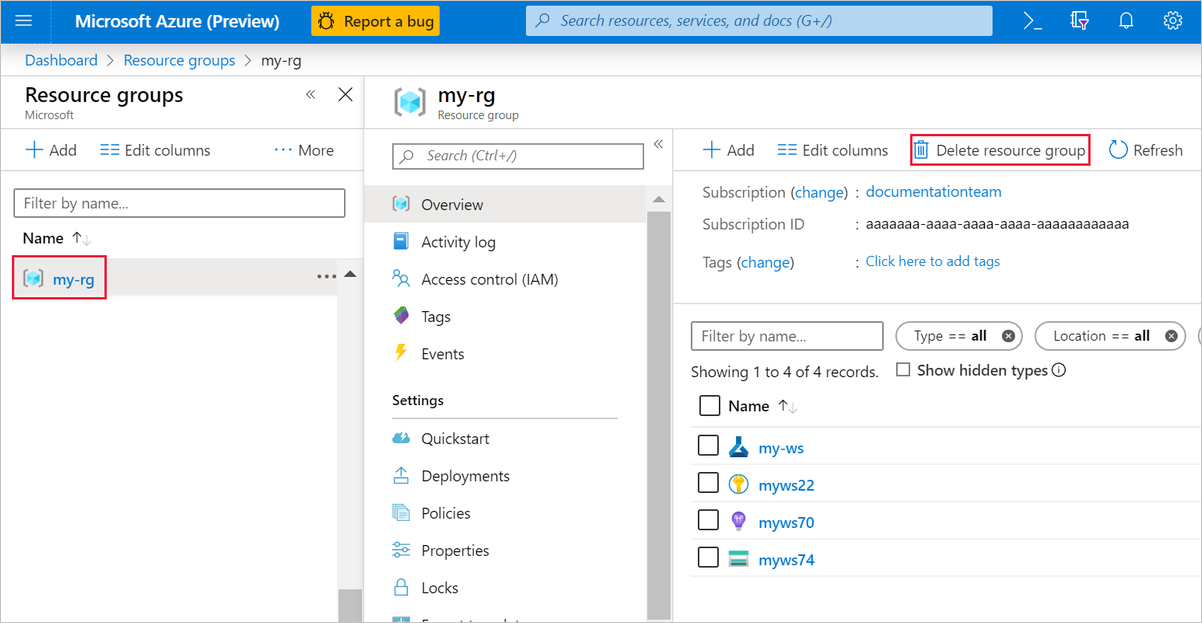
在列表中选择你创建的资源组。
选择“删除资源组”。
删除该资源组也会删除在设计器中创建的所有资源。
删除各项资产
在创建试验的设计器中删除各个资产,方法是将其选中,然后选择“删除”按钮。
此处创建的计算目标在未使用时,会自动缩减到零个节点。 此操作旨在最大程度地减少费用。 若要删除计算目标,请执行以下步骤:
可以通过选择每个数据集并选择“注销”,从工作区中注销数据集。

若要删除数据集,请使用 Azure 门户或 Azure 存储资源管理器访问存储帐户,然后手动删除这些资产。
后续步骤
本文介绍了如何转换数据集并将它保存到已注册的数据存储中。
继续学习此操作说明系列的下一个部分(使用 Azure 机器学习设计器重新训练模型),使用转换后的数据集和管道参数训练机器学习模块。