你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
使用 Azure 机器学习大规模训练 TensorFlow 模型
适用于: Python SDK azure-ai-ml v2(当前版本)
Python SDK azure-ai-ml v2(当前版本)
本文介绍如何使用 Azure 机器学习 Python SDK v2 大规模运行 TensorFlow 训练脚本。
本文中的示例代码使用深度神经网络 (DNN) 训练 TensorFlow 模型来对手写数字进行分类,注册模型,并将其部署到联机终结点。
无论你是从头开始开发 TensorFlow 模型,还是将现有模型引入到云中,都可通过 Azure 机器学习使用弹性云计算资源来横向扩展开源训练作业。 你可以通过 Azure 机器学习来构建、部署和监视生产级模型以及对其进行版本控制。
先决条件
要从本文内容中受益,你需要:
- 有权访问 Azure 订阅。 如果还没有帐户,请创建一个免费帐户。
- 使用 Azure 机器学习计算实例或你自己的 Jupyter Notebook 运行本文的代码。
- Azure 机器学习计算实例(无需下载或安装)
- 完成创建资源以开始使用教程,以创建预先加载了 SDK 和示例存储库的专用笔记本服务器。
- 在笔记本服务器上的示例深度学习文件夹中,导航到以下目录来找到已完成且已展开的笔记本:v2 > sdk > python > jobs > single-step > tensorflow > train-hyperparameter-tune-deploy-with-tensorflow。
- Jupyter Notebook 服务器
- Azure 机器学习计算实例(无需下载或安装)
- 下载以下文件:
- 训练脚本 tf_mnist.py
- 评分脚本 score.py
- 示例请求文件 sample-request.json
此外,还可以在 GitHub 示例页上找到本指南的完整 Jupyter Notebook 版本。
在运行本文中的代码以创建 GPU 群集之前,需要为工作区请求增加配额。
设置作业
本部分会加载所需的 Python 包、连接到工作区、创建计算资源来运行命令作业,并创建用于运行作业的环境,从而设置作业来进行训练。
连接到工作区
首先,需要连接到你的 Azure 机器学习工作区。 Azure 机器学习工作区是服务的顶级资源。 它提供了一个集中的位置,用于处理使用 Azure 机器学习时创建的所有项目。
使用 DefaultAzureCredential 来访问工作区。 该凭据应能够处理大多数 Azure SDK 身份验证方案。
如果 DefaultAzureCredential 不适用,请参阅 azure-identity reference documentation 或 Set up authentication 了解更多可用凭据。
# Handle to the workspace
from azure.ai.ml import MLClient
# Authentication package
from azure.identity import DefaultAzureCredential
credential = DefaultAzureCredential()如果你更喜欢使用浏览器进行登录和身份验证,应取消注释以下代码,而是改为使用它。
# Handle to the workspace
# from azure.ai.ml import MLClient
# Authentication package
# from azure.identity import InteractiveBrowserCredential
# credential = InteractiveBrowserCredential()
接下来,通过提供订阅 ID、资源组名称和工作区名称来获取工作区的句柄。 要查找这些参数:
- 在 Azure 机器学习工作室工具栏的右上角查找工作区名称。
- 选择工作区名称以显示资源组和订阅 ID。
- 将资源组和订阅 ID 的值复制到代码中。
# Get a handle to the workspace
ml_client = MLClient(
credential=credential,
subscription_id="<SUBSCRIPTION_ID>",
resource_group_name="<RESOURCE_GROUP>",
workspace_name="<AML_WORKSPACE_NAME>",
)运行此脚本会得到一个工作区句柄,你使用它来管理其他资源和作业。
注意
- 创建
MLClient不会将客户端连接到工作区。 客户端初始化是惰性操作,将等待其所需的首次调用。 在本文中,这将发生在计算创建期间。
创建计算资源
Azure 机器学习需要计算资源才能运行作业。 此资源可以是具有 Linux 或 Windows OS 的单节点或多节点计算机,也可以是 Spark 等特定计算结构。
在以下示例脚本中,我们预配了 Linux compute cluster。 可以查看 Azure Machine Learning pricing 页面,了解 VM 大小和价格的完整列表。 我们需要对此示例使用 GPU 群集,因此让我们选择一个 STANDARD_NC6 模型并创建一个 Azure 机器学习计算。
from azure.ai.ml.entities import AmlCompute
gpu_compute_target = "gpu-cluster"
try:
# let's see if the compute target already exists
gpu_cluster = ml_client.compute.get(gpu_compute_target)
print(
f"You already have a cluster named {gpu_compute_target}, we'll reuse it as is."
)
except Exception:
print("Creating a new gpu compute target...")
# Let's create the Azure ML compute object with the intended parameters
gpu_cluster = AmlCompute(
# Name assigned to the compute cluster
name="gpu-cluster",
# Azure ML Compute is the on-demand VM service
type="amlcompute",
# VM Family
size="STANDARD_NC6s_v3",
# Minimum running nodes when there is no job running
min_instances=0,
# Nodes in cluster
max_instances=4,
# How many seconds will the node running after the job termination
idle_time_before_scale_down=180,
# Dedicated or LowPriority. The latter is cheaper but there is a chance of job termination
tier="Dedicated",
)
# Now, we pass the object to MLClient's create_or_update method
gpu_cluster = ml_client.begin_create_or_update(gpu_cluster).result()
print(
f"AMLCompute with name {gpu_cluster.name} is created, the compute size is {gpu_cluster.size}"
)创建作业环境
运行 Azure 机器学习作业需要一个环境。 Azure 机器学习环境封装了在计算资源上运行机器学习训练脚本所需的依赖项(例如软件运行时和库)。 此环境类似于本地计算机上的 Python 环境。
通过 Azure 机器学习可使用策展(或现成)环境 - 这适用于常见训练和推理方案,或者使用 Docker 映像或 Conda 配置来创建自定义环境。
在本文中,请重复使用策展的 Azure 机器学习环境 AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu。 请通过使用 @latest 指令来使用此环境的最新版本。
curated_env_name = "AzureML-tensorflow-2.7-ubuntu20.04-py38-cuda11-gpu@latest"配置并提交训练作业
在本部分,我们首先介绍用于训练的数据。 然后,我们介绍如何使用提供的训练脚本运行训练作业。 请学习如何通过配置用于运行训练脚本的命令来生成训练作业。 然后,请提交训练作业以在 Azure 机器学习中运行它。
获取训练数据
你将使用修改后的国家标准和技术研究所 (MNIST) 手写数字数据库中的数据。 此数据源自杨立昆 (Yan LeCun) 的网站,存储在 Azure 存储帐户中。
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"有关 MNIST 数据集的详细信息,请访问杨立昆的网站。
准备训练脚本
在本文中,我们提供了训练脚本 tf_mnist.py。 实际上,你应该能够原样获取任何自定义训练脚本,并使用 Azure 机器学习运行它,而无需修改你的代码。
提供的训练脚本会执行以下操作:
- 处理数据预处理,将数据拆分为测试数据和训练数据;
- 使用数据训练模型;并且
- 返回输出模型。
在管道运行期间,请使用 MLFlow 记录参数和指标。 若要了解如何启用 MLFlow 跟踪,请参阅使用 MLflow 跟踪 ML 试验和模型。
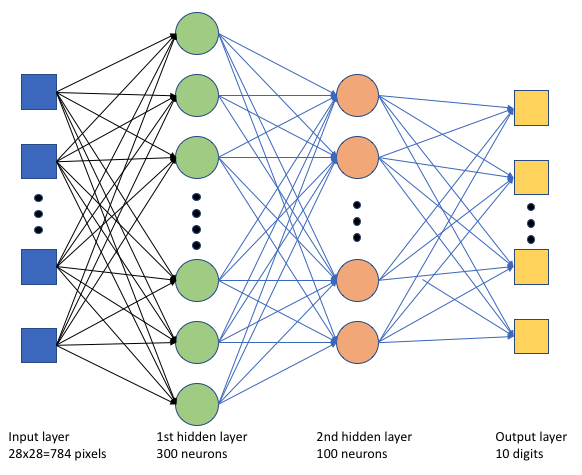
在训练脚本 tf_mnist.py 中,我们创建一个简单的深度神经网络 (DNN)。 此 DNN 具有以下内容:
- 一个具有 28 * 28 = 784 个神经元的输入层。 每个神经元表示一个图像像素。
- 两个隐藏层。 第一个隐藏层有 300 个神经元,第二个隐藏层有 100 个神经元。
- 一个具有 10 个神经元的输出层。 每个神经元表示一个介于 0 到 9 之间的目标标签。
生成训练作业
现在你已拥有运行作业所需的所有资产,是时候使用 Azure 机器学习 Python SDK v2 进行生成了。 在本示例中,我们将创建一个 command。
Azure 机器学习 command 是一种资源,用于指定在云中执行训练代码所需的所有详细信息。 这些详细信息包括输入和输出、要使用的硬件类型、要安装的软件以及代码运行方式。 command 包含用于执行单个命令的信息。
配置命令
请使用常规用途 command 来运行训练脚本并执行所需的任务。 创建一个 Command 对象来指定训练作业的配置详细信息。
from azure.ai.ml import command
from azure.ai.ml import UserIdentityConfiguration
from azure.ai.ml import Input
web_path = "wasbs://datasets@azuremlexamples.blob.core.windows.net/mnist/"
job = command(
inputs=dict(
data_folder=Input(type="uri_folder", path=web_path),
batch_size=64,
first_layer_neurons=256,
second_layer_neurons=128,
learning_rate=0.01,
),
compute=gpu_compute_target,
environment=curated_env_name,
code="./src/",
command="python tf_mnist.py --data-folder ${{inputs.data_folder}} --batch-size ${{inputs.batch_size}} --first-layer-neurons ${{inputs.first_layer_neurons}} --second-layer-neurons ${{inputs.second_layer_neurons}} --learning-rate ${{inputs.learning_rate}}",
experiment_name="tf-dnn-image-classify",
display_name="tensorflow-classify-mnist-digit-images-with-dnn",
)此命令的输入包括数据位置、批大小、第一层和第二层中的神经元数以及学习速率。 请注意,我们已将 Web 路径作为输入直接传入。
对于参数值:
- 提供为运行此命令而创建的计算群集
gpu_compute_target = "gpu-cluster"; - 提供前面声明的策展环境
curated_env_name; - 配置命令行操作本身 - 在这种情况下,命令为
python tf_mnist.py。 可通过${{ ... }}表示法访问命令中的输入和输出;并且 - 配置显示名称和试验名称等元数据;其中一个试验是一个容器,包含在某个项目上所做的全部迭代。 在同一试验名称下提交的所有作业将在 Azure 机器学习工作室中彼此相邻地列出。
- 提供为运行此命令而创建的计算群集
在此示例中,你将使用
UserIdentity来运行该命令。 使用用户标识意味着该命令将使用你的标识来运行作业并访问 Blob 中的数据。
提交作业
现在可以提交要在 Azure 机器学习中运行的作业。 这一次,你将对 ml_client.jobs 使用 create_or_update。
ml_client.jobs.create_or_update(job)完成后,该作业将在工作区中注册一个模型(这是训练的结果),并输出一个在 Azure 机器学习工作室中查看该作业的链接。
警告
Azure 机器学习通过复制整个源目录来运行训练脚本。 如果你有不想上传的敏感数据,请使用 .ignore 文件或不将其包含在源目录中。
在作业执行过程中发生的情况
执行作业时,会经历以下阶段:
准备:根据所定义的环境创建 docker 映像。 将映像上传到工作区的容器注册表,缓存以用于后续运行。 还会将日志流式传输到作业历史记录,可以查看日志以监视进度。 如果指定策展环境,将会使用支持该策展环境的缓存映像。
缩放:如果群集执行运行所需的节点多于当前可用节点,则该群集将尝试纵向扩展。
运行:脚本文件夹 src 中的所有脚本都上传到计算目标,装载或复制数据存储,然后执行脚本。 stdout 和 ./logs 文件夹中的输出会流式传输到作业历史记录,并可用于监视作业。
优化模型超参数
现在,你已经了解如何使用 SDK 进行 TensorFlow 训练运行,接下来让我们看看是否可进一步提高模型的准确性。 可使用 Azure 机器学习的 sweep 功能调整和优化模型的超参数。
要调整模型的超参数,请定义要在训练期间搜索的参数空间。 为此,将使用 azure.ml.sweep 包中的特殊输入替换传递给训练作业的一些参数(batch_size、first_layer_neurons、second_layer_neurons 和 learning_rate)。
from azure.ai.ml.sweep import Choice, LogUniform
# we will reuse the command_job created before. we call it as a function so that we can apply inputs
# we do not apply the 'iris_csv' input again -- we will just use what was already defined earlier
job_for_sweep = job(
batch_size=Choice(values=[32, 64, 128]),
first_layer_neurons=Choice(values=[16, 64, 128, 256, 512]),
second_layer_neurons=Choice(values=[16, 64, 256, 512]),
learning_rate=LogUniform(min_value=-6, max_value=-1),
)然后,请在命令作业上配置扫描,使用一些特定于扫描的参数,例如要监视的主要指标和要使用的采样算法。
在以下代码中,我们使用随机采样来尝试不同的超参数配置集,以尝试最大化我们的主要指标 validation_acc。
我们还定义了一个提前终止策略 - BanditPolicy。 此策略通过每两次迭代检查一次作业来操作。 如果主要指标 validation_acc 超出前 10% 的范围,Azure 机器学习将终止作业。 这样,模型就无需继续探索那些未显示出能帮助达到目标指标的迹象的超参数。
from azure.ai.ml.sweep import BanditPolicy
sweep_job = job_for_sweep.sweep(
compute=gpu_compute_target,
sampling_algorithm="random",
primary_metric="validation_acc",
goal="Maximize",
max_total_trials=8,
max_concurrent_trials=4,
early_termination_policy=BanditPolicy(slack_factor=0.1, evaluation_interval=2),
)现在,可以像之前一样提交此作业。 这一次,你将运行一个扫描作业来扫描训练作业。
returned_sweep_job = ml_client.create_or_update(sweep_job)
# stream the output and wait until the job is finished
ml_client.jobs.stream(returned_sweep_job.name)
# refresh the latest status of the job after streaming
returned_sweep_job = ml_client.jobs.get(name=returned_sweep_job.name)可使用在作业运行期间显示的工作室用户界面链接来监视作业。
查找并注册最佳模型
所有运行完成后,可以找到生成具有最高准确度的模型的运行。
from azure.ai.ml.entities import Model
if returned_sweep_job.status == "Completed":
# First let us get the run which gave us the best result
best_run = returned_sweep_job.properties["best_child_run_id"]
# lets get the model from this run
model = Model(
# the script stores the model as "model"
path="azureml://jobs/{}/outputs/artifacts/paths/outputs/model/".format(
best_run
),
name="run-model-example",
description="Model created from run.",
type="custom_model",
)
else:
print(
"Sweep job status: {}. Please wait until it completes".format(
returned_sweep_job.status
)
)然后,可以注册此模型。
registered_model = ml_client.models.create_or_update(model=model)将模型部署为联机终结点
注册模型后,可将模型部署为联机终结点,即 Azure 云中的 Web 服务。
若要部署机器学习服务,通常需要:
- 要部署的模型资产。 这些资产包括已在训练作业中注册的模型文件和元数据。
- 一些要作为服务运行的代码。 这些代码根据给定的输入请求(入口脚本)执行模型。 该入口脚本接收提交到已部署的 Web 服务的数据,并将此数据传递给模型。 模型处理数据后,脚本会将模型的响应返回到客户端。 该脚本特定于你的模型,并且必须识别模型需要和返回的数据。 使用 MLFlow 模型时,Azure 机器学习会自动为你创建此脚本。
有关部署的详细信息,请参阅使用 Python SDK v2 部署使用托管联机终结点的机器学习模型并为其评分。
创建新的联机终结点
部署模型的第一步是,需要创建联机终结点。 终结点名称在整个 Azure 区域中必须是唯一的。 在本文中,请使用通用唯一标识符 (UUID) 创建唯一名称。
import uuid
# Creating a unique name for the endpoint
online_endpoint_name = "tff-dnn-endpoint-" + str(uuid.uuid4())[:8]from azure.ai.ml.entities import (
ManagedOnlineEndpoint,
ManagedOnlineDeployment,
Model,
Environment,
)
# create an online endpoint
endpoint = ManagedOnlineEndpoint(
name=online_endpoint_name,
description="Classify handwritten digits using a deep neural network (DNN) using TensorFlow",
auth_mode="key",
)
endpoint = ml_client.begin_create_or_update(endpoint).result()
print(f"Endpint {endpoint.name} provisioning state: {endpoint.provisioning_state}")创建终结点后,可按如下方式检索它:
endpoint = ml_client.online_endpoints.get(name=online_endpoint_name)
print(
f'Endpint "{endpoint.name}" with provisioning state "{endpoint.provisioning_state}" is retrieved'
)将模型部署到终结点
创建终结点后,可使用入口脚本部署模型。 一个终结点可以有多个部署。 然后,终结点可使用规则将流量定向到这些部署。
在以下代码中,请创建单个部署来处理 100% 的传入流量。 我们使用任意颜色名称 (tff-blue) 进行部署。 还可对部署使用任何其他名称,例如 tff-green 或 tff-red。 用于将模型部署到终结点的代码会执行以下操作:
- 部署之前注册的模型的最佳版本;
- 使用
score.py文件对模型进行评分;以及 - 使用前面声明的相同策展环境执行推理。
model = registered_model
from azure.ai.ml.entities import CodeConfiguration
# create an online deployment.
blue_deployment = ManagedOnlineDeployment(
name="tff-blue",
endpoint_name=online_endpoint_name,
model=model,
code_configuration=CodeConfiguration(code="./src", scoring_script="score.py"),
environment=curated_env_name,
instance_type="Standard_DS3_v2",
instance_count=1,
)
blue_deployment = ml_client.begin_create_or_update(blue_deployment).result()注意
预计此部署需要一些时间才能完成。
使用示例查询来测试部署
将模型部署到终结点后,可对终结点使用 invoke 方法来预测已部署模型的输出。 若要运行推理,请使用 request 文件夹中的示例请求文件 sample-request.json。
# # predict using the deployed model
result = ml_client.online_endpoints.invoke(
endpoint_name=online_endpoint_name,
request_file="./request/sample-request.json",
deployment_name="tff-blue",
)然后,可打印返回的预测并将其与输入图像一起绘制。 使用红色字体和反色图像(黑底白色)来突出显示错误分类的样本。
# compare actual value vs. the predicted values:
import matplotlib.pyplot as plt
i = 0
plt.figure(figsize=(20, 1))
for s in sample_indices:
plt.subplot(1, n, i + 1)
plt.axhline("")
plt.axvline("")
# use different color for misclassified sample
font_color = "red" if y_test[s] != result[i] else "black"
clr_map = plt.cm.gray if y_test[s] != result[i] else plt.cm.Greys
plt.text(x=10, y=-10, s=result[i], fontsize=18, color=font_color)
plt.imshow(X_test[s].reshape(28, 28), cmap=clr_map)
i = i + 1
plt.show()注意
由于模型准确度较高,可能需要运行几次该单元格才能看到错误分类的样本。
清理资源
如果不使用终结点,请将其删除以停止使用资源。 在删除终结点之前,请确保没有其他任何部署正在使用该终结点。
ml_client.online_endpoints.begin_delete(name=online_endpoint_name)注意
预计此清理需要一些时间才能完成。
后续步骤
在本文中,你训练和注册了一个 TensorFlow 模型。 你还将该模型部署到了联机终结点。 有关 Azure 机器学习的详细信息,请参阅以下其他文章。