将训练数据从各种数据源导入机器学习工作室(经典)
适用于: 机器学习工作室(经典)
机器学习工作室(经典) Azure 机器学习
Azure 机器学习
重要
对机器学习工作室(经典)的支持将于 2024 年 8 月 31 日结束。 建议在该日期之前转换到 Azure 机器学习。
从 2021 年 12 月 1 日开始,你将无法创建新的机器学习工作室(经典)资源。 在 2024 年 8 月 31 日之前,可继续使用现有的机器学习工作室(经典)资源。
ML 工作室(经典)文档即将停用,将来可能不会更新。
若要在机器学习工作室(经典)中使用自己的数据来开发和训练预测分析解决方案,可以使用来自以下源的数据:
- 本地文件 - 提前从硬盘驱动器加载本地数据,以便在工作区中创建数据集模块
- 联机数据源 - 运行试验时使用导入数据模块,访问来自多个联机源之一的数据
- 机器学习工作室(经典)试验 - 使用在机器学习工作室(经典)中保存为数据集的数据
- SQL Server 数据库 - 使用来自 SQL Server 数据库的数据,而无需手动复制数据
注意
机器学习工作室(经典)中提供了有许多可用于训练数据的示例数据集。 若要了解这些示例数据集,请参阅在机器学习工作室(经典)中使用示例数据集。
准备数据
机器学习工作室(经典)旨在使用矩形或表格数据,例如从数据库分隔或结构化数据的文本数据,但在某些情况下,可能会使用非矩形数据。
在将数据导入到工作室(经典)之前,数据最好相对整洁。 例如,你需要处理不带引号的字符串之类的问题。
但是,工作室(经典)中有些模块可用来在导入数据后在试验中实现某些数据操作。 根据要使用的机器学习算法,可能需要确定处理数据结构问题(如缺失值和稀疏数据)的方法,并且提供有模块帮助处理这些问题。 请查看模块控制板的“数据转换”部分,了解执行这些函数的模块。
通过单击输出端口,任何时候都可在试验中查看或下载模块生成的数据。 可能有不同的下载选项可用,或者能够在工作室(经典)中通过 Web 浏览器来使数据可视化,具体取决于模块。
支持的数据格式和数据类型
可将大量数据类型导入试验,具体取决于用于导入数据的机制以及数据的来源:
- 纯文本 (.txt)
- 逗号分隔值 (CSV),带有标头 (.csv) 或不带标头 (.nh.csv)
- 制表符分隔值 (TSV),带有标头 (.tsv) 或不带标头 (.nh.tsv)
- Excel 文件
- Azure 表
- Hive 表
- SQL 数据库表
- OData 值
- SVMLight 数据 (.svmlight)(有关格式的信息,请参阅 SVMLight 定义)
- 属性关系文件格式 (ARFF) 数据 (.arff)(有关格式的信息,请参阅 ARFF 定义)
- Zip 文件 (.zip)
- R 对象或工作区文件 (.RData)
如果导入包括元数据的数据(如 ARFF 格式),工作室(经典)将使用此元数据定义每个列的标题和数据类型。
如果导入不包括此元数据的数据(如 TSV 或 CSV 格式),工作室(经典)将通过数据采样推断每个列的数据类型。 如果数据也没有列标题,工作室(经典)将提供默认名称。
可使用编辑元数据模块显式指定或更改列的标题和数据类型。
工作室(经典)可识别以下数据类型:
- String
- Integer
- Double
- 布尔
- DateTime
- TimeSpan
工作室使用名为“数据表”的内部数据类型在模块间传递数据。 可使用转换为数据集模块,将数据显式转换为数据表格式。
任何接受格式而不是数据表的模块都会在不提示的情况将数据转换为数据表,然后再将其传递到下一个模块。
如有必要,可使用其他转换模块,将数据表格式转换回 CSV、TSV、ARFF 或 SVMLight 格式。 请查看模块控制板的“数据格式转换”部分,了解执行这些函数的模块。
数据容量
机器学习工作室(经典)中的模块针对常见用例支持最多包含 10 GB 密集数字数据的数据集。 如果模块接受多个输入,10 GB 这个值是所有输入大小的总计。 可通过 Hive 或 Azure SQL 数据库查询对更大的数据集采样,或者在导入数据之前使用“按计数学习”预处理。
以下数据类型可以在特征规范化期间扩展为较大数据集,其限制为小于 10 GB:
- 稀疏
- 分类
- 字符串
- Binary data
以下模块限制为小于 10 GB 的数据集:
- 推荐器模块
- 合成少数类过采样技术 (SMOTE) 模块
- 脚本模块:R、Python、SQL
- 输出数据大小可以大于输入数据大小的模块,例如联接或特征哈希
- 迭代数目极大时的交叉验证、调整模型超参数、顺序回归和一对多的多类
对于大于几个 GB 的数据集,应该将数据上传到 Azure 存储或 Azure SQL 数据库,或者使用 Azure HDInsight,而不要直接从本地文件上传。
可在导入图像模块参考中找到有关图像数据的信息。
从本地文件导入
可以上传硬盘驱动器中的数据文件,在工作室(经典)中将其用作训练数据。 导入数据文件时,你将在工作区中创建一个就绪可在试验中使用的数据集模块。
若要从本地硬盘驱动器导入数据,请执行以下操作:
- 单击工作室(经典)窗口底部的“+新建”。
- 选择“数据集”和“从本地文件”。
- 在“上传新的数据集”对话框中,浏览到要上传的文件。
- 输入名称、标识数据类型,还可选择输入描述。 建议输入描述:这样可以记录有关数据的任何特征,以便将来使用数据时能够记起。
- 使用复选框“这是现有数据集的新版本”可以使用新数据更新现有数据集。 为此,请单击此复选框,并输入现有数据集的名称。
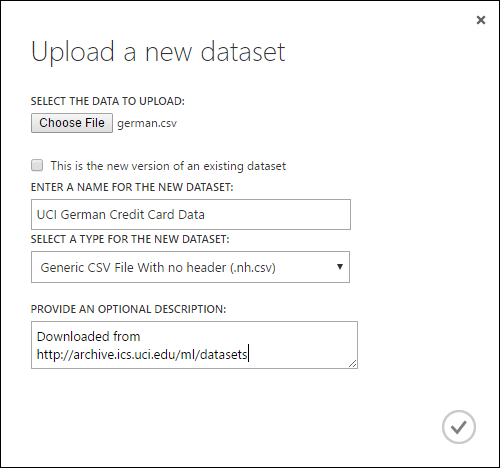
上传时间取决于数据大小和连接到服务的速度。 如果知道文件将花费很长时间,等待时可以在工作室(经典)中执行其他操作。 但是,在数据上传完成之前关闭浏览器将导致上传失败。
数据上传后,将存储在数据集模块中,并且可用于工作区中的任何实验。
编辑实验时,可以在模块选项板中的“已保存数据集”列表下的“我的数据集”列表中找到已上传的数据集。 如果希望将数据集用于进一步分析和机器学习,可以将数据集拖放到实验画布。
从联机数据源导入
使用导入数据模块,你的试验可以在试验运行时从各种联机数据源导入数据。
使用导入数据模块,可以在试验运行时从多种联机数据源之一访问数据:
- 使用 HTTP 的 Web URL
- 使用 HiveQL 的 Hadoop
- Azure Blob 存储
- Azure 表
- Azure SQL 数据库。 SQL 托管实例或 SQL Server
- 数据馈送提供程序(目前为 OData)
- Azure Cosmos DB
由于此训练数据是在试验正在运行时访问的,因此只能在该试验中使用。 相比之下,存储在数据集模块中的数据可供工作区中的任何试验使用。
若要在工作室(经典)试验中访问联机数据源,请向试验中添加导入数据模块。 然后,在“属性”下选择“启动导入数据向导”以根据分步指导说明来选择并配置数据源。 另外,也可以手动在“属性”下选择“数据源”并提供访问数据所需的参数。
下表列举了支持的联机数据源。 此表还汇总了支持的文件格式,以及用于访问数据的参数。
重要
导入数据和导出数据模块目前只能在使用经典部署模型创建的 Azure 存储中读取和写入数据。 换言之,目前尚不支持可提供热存储访问层或冷存储访问层的新式 Azure Blob 存储帐户类型。
一般情况下,在此服务选项推出之前创建的任何 Azure 存储帐户应该不受影响。 如果需要创建新帐户,请为“部署模型”选择“经典”或使用“资源管理器”;对于“帐户类型”,请选择“常规用途”而不是“Blob 存储”。
有关详细信息,请参阅 Azure Blob 存储:热存储层和冷存储层。
支持的联机数据源
机器学习工作室(经典)的“导入数据”模块支持以下数据源:
| 数据源 | 说明 | parameters |
|---|---|---|
| 通过 HTTP 的 Web URL | 从使用 HTTP 的任何 Web URL 中读取逗号分隔值 (CSV)、制表符分隔值 (TSV)、属性关系文件格式 (ARFF) 和支持向量机 (SVM-light) 格式的数据 | URL:指定文件的完整名称,包括站点 URL 和文件名与任何扩展名。 数据格式:指定支持的一种数据格式:CSV、TSV、ARFF 或 SVM-light。 如果数据包含标头行,该数据用于分配列名。 |
| Hadoop/HDFS | 从 Hadoop 中的分布式存储读取数据。 可以使用 HiveQL(类似于 SQL 的查询语言)指定所需的数据。 使用 HiveQL 还可以在将数据添加到工作室(经典)之前聚合数据和执行数据筛选。 | Hive 数据库查询:指定用于生成数据的 Hive 查询。 HCatalog 服务器 URI:使用 <群集名称>.azurehdinsight.net 格式指定群集的名称。 Hadoop 用户帐户名称:指定用于预配群集的 Hadoop 用户帐户名。 Hadoop 用户帐户密码:指定预配群集时使用的凭据。 有关详细信息,请参阅 Create Hadoop clusters in HDInsight(在 HDInsight 中创建 Hadoop 群集)。 输出数据的位置:指定数据是要存储在 Hadoop 分布式文件系统 (HDFS) 还是 Azure 中。
如果将输出数据存储在 Azure 中,则必须指定 Azure 存储帐户名、存储访问密钥和存储容器名称。 |
| SQL 数据库 | 读取在 Azure 虚拟机上运行的 Azure SQL 数据库、SQL 托管实例或 SQL Server 数据库中存储的数据。 | 数据库服务器名称:指定运行数据库的服务器的名称。
对于托管在 Azure 虚拟机上的 SQL Server,请输入 tcp:<虚拟机 DNS 名称>, 1433 数据库名称:指定服务器上的数据库名称。 服务器用户帐户名:指定具有数据库访问权限的帐户的用户名。 服务器用户帐户密码:指定用户帐户的密码。 数据库查询:输入 SQL 语句用于说明要读取的数据。 |
| 本地 SQL 数据库 | 读取 SQL 数据库中存储的数据。 | 数据网关:指定可访问 SQL Server 数据库的计算机上安装的数据管理网关的名称。 有关网关设置的信息,请参阅使用 SQL Server 中的数据通过机器学习工作室(经典)执行高级分析。 数据库服务器名称:指定运行数据库的服务器的名称。 数据库名称:指定服务器上的数据库名称。 服务器用户帐户名:指定具有数据库访问权限的帐户的用户名。 用户名和密码:单击“输入值”输入数据库凭据。 可以使用 Windows 集成身份验证或 SQL Server 身份验证,具体取决于配置 SQL Server 的方式。 数据库查询:输入 SQL 语句用于说明要读取的数据。 |
| Azure 表 | 从 Azure 存储中的表服务读取数据。 如果不常读取大量数据,请使用 Azure 表服务。 它提供了一个灵活、非关系 (NoSQL)、可大规模缩放、成本较低且高度可用的存储解决方案。 |
导入数据中的选项根据访问的是公共信息还是需要登录凭据的专用存储帐户而变化。 这一点可以根据“身份验证类型”来确定,其值可能是“PublicOrSAS”或“Account”,两者都有自身的参数集。 公共或共享访问签名 (SAS) URI:参数包括:
指定扫描属性名称的行:值为 TopN(扫描指定的行数)或 ScanAll(获取表中的所有行)。 如果数据是同构的且可预测,我们建议选择“TopN”并为 N 输入一个数字。对于大型表,这样可以加快读取速度。 如果已使用根据表的深度和位置变化的属性集将数据结构化,请选择“ScanAll”选项来扫描所有行。 这可确保生成的属性和元数据转换的完整性。
帐户密钥:指定与帐户关联的存储密钥。 表名称:指定要读取的数据所在的表的名称。 扫描属性名称的行:值为 TopN(扫描指定的行数)或 ScanAll(获取表中的所有行)。 如果数据是同构的且可预测,我们建议选择“TopN”并为 N 输入一个数字。对于大型表,这样可以加快读取速度。 如果已使用根据表的深度和位置变化的属性集将数据结构化,请选择“ScanAll”选项来扫描所有行。 这可确保生成的属性和元数据转换的完整性。 |
| Azure Blob 存储 | 读取存储在 Azure 存储的 Blob 服务中的数据,包括图像、非结构化文本或二元数据。 可以使用 Blob 服务公开数据,或者私下存储应用程序数据。 可以使用 HTTP 或 HTTPS 连接从任意位置访问数据。 |
导入数据模块中的选项根据访问的是公共信息还是需要登录凭据的专用存储帐户而变化。 这一点可以根据“身份验证类型”来确定,其值可能是“PublicOrSAS”或“Account”。 公共或共享访问签名 (SAS) URI:参数包括:
文件格式:指定 Blob 服务中数据的格式。 支持的格式包括 CSV、TSV 和 ARFF。
帐户密钥:指定与帐户关联的存储密钥。 容器、目录或 Blob 的路径:指定要读取的数据所在的 Blob 的名称。 Blob 文件格式:指定 Blob 服务中数据的格式。 支持的数据格式包括 CSV、TSV、ARFF、CSV(使用指定的编码)和 Excel。
可以使用“Excel”选项从 Excel 工作簿中读取数据。 在“Excel 数据格式”选项中,指明数据是在 Excel 工作表范围内还是在 Excel 表中。 在“Excel 工作表或嵌入表”选项中,指定要从中读取数据的工作表或表的名称。 |
| 数据馈送提供程序 | 从支持的馈送提供程序读取数据。 目前仅支持开放数据协议 (OData) 格式。 | 数据内容类型:指定 OData 格式。 源 URL:指定数据馈送的完整 URL。 例如,从 Northwind 示例数据库读取以下 URL: https://services.odata.org/northwind/northwind.svc/ |
从另一个试验导入
有时候想要从实验中提取直接结果,并将其用作其他实验的一部分。 为此,请将模块另存为数据集:
- 单击想要另存为数据集的模块的输出。
- 单击“另存为数据集”。
- 出现提示时,请输入可轻松标识数据集的名称和描述。
- 单击“确定”复选标记。
保存完成时,数据集将能在工作区的任何实验中使用。 可在模块面板的“保存的数据集”列表中找到它。