你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
快速入门:在 Azure 门户创建搜索索引
在本 Azure AI 搜索快速入门中,使用导入数据 向导和由 Microsoft 托管的虚构酒店数据构成的内置示例数据源创建第一个搜索索引。 此向导将指导你完成创建无代码搜索索引的过程,以帮助你在几分钟内编写有趣的查询。
该向导在搜索服务(可搜索索引 )上创建多个对象,但还会创建索引器和数据源连接来进行自动数据检索。 在本快速入门结束时,我们将查看每个对象。
注意
导入数据向导包括本快速入门中未涵盖的 OCR、文本翻译和其他 AI 扩充选项。 有关侧重于 AI 扩充的类似演练,请参阅《快速入门:在 Azure 门户中创建技能集》。
先决条件
检查空间
很多客户开始使用免费服务。 免费层限制为三个索引、三个数据源和三个索引器。 在开始之前,请确保有空间存储额外的项目。 本快速入门将为每个对象创建一个。
检查服务的“概述 > 使用情况”选项卡,以查看已拥有的索引、索引器和数据源数。

启动向导
使用 Azure 帐户登录到 Azure 门户,然后转到 Azure AI 搜索服务。
在“概述”页上,选择“导入数据”以启动向导。

创建和加载索引
在本部分中,通过四个步骤创建和加载索引。
连接到数据源
该向导创建与 Microsoft 在 Azure Cosmos DB 上托管的示例数据的数据源连接。 此示例数据是通过内部连接检索和访问的。 无需使用自己的 Azure Cosmos DB 帐户或源文件即可运行本快速入门。
在连接到数据时,展开“数据源”下拉列表,然后选择“示例”。
在内置示例列表中,选择“hotels-sample”。

选择“下一步: 添加认知技能(可选)”继续操作。
跳过认知技能配置
导入数据向导支持创建技能集和对索引进行 AI 扩充。
在本快速入门中,请忽略“添加认知技能”选项卡上的 AI 扩充配置选项。
选择“跳到: 自定义目标索引”以继续操作。

提示
对 AI 扩充感兴趣? 试用此《快速入门:在 Azure 门户中创建技能集》
配置索引
该向导可推断内置酒店示例索引的架构。 请按照以下步骤来配置索引:
对于“索引名称”(hotels-sample-index) 和“键”字段 (HotelId),接受系统生成的值。
对于所有字段属性,接受系统生成的值。
重要
如果重新运行向导和使用现有的 hotels-sample 数据源,则不会使用默认属性配置索引。 以后导入时,必须手动选择属性。
选择“下一步: 创建索引器”以继续操作。
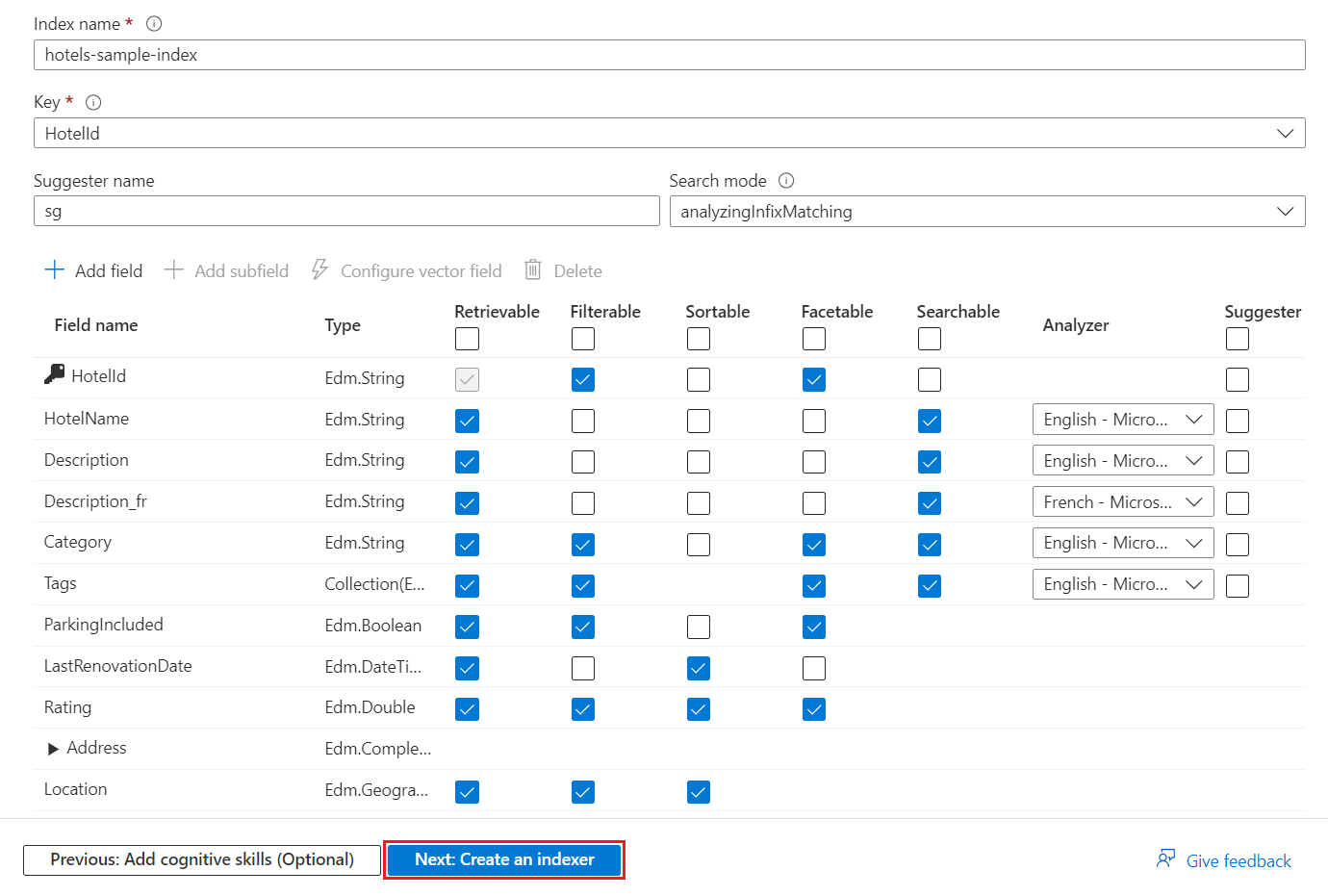
索引至少需要“索引名称”和“字段”集合。 一个字段必须标记为文档键,用于唯一标识每个文档。 该值始终为字符串。 向导会扫描唯一的字符串字段,并选择一个作为密钥。
每个字段都有一个名称、数据类型和属性,用于控制如何在搜索索引中使用字段。 复选框可启用或禁用以下属性:
- 可检索:查询响应中返回的字段。
- 可筛选:接受筛选表达式的字段。
- 可排序:接受 orderby 表达式的字段。
- 可分面:分面导航结构中使用的字段。
- 可搜索:全文搜索中使用的字段。 字符串可搜索。 数值字段和布尔字段通常标记为不可搜索。
字符串经过属性化,可检索且可搜索。 整数归属为可检索、可筛选、可排序和可分面。
属性会影响存储。 可筛选字段会消耗额外的存储,但 可检索字段不会。 有关详细信息,请参阅演示属性和建议器的存储意义的示例。
如果需要自动完成或建议查询,可以指定语言分析器或建议器。
配置和运行索引器
最后一步是配置并运行索引器。 此对象定义一个可执行过程。 在此步骤中将会创建数据源、索引和索引器。
对于“索引器名称”(hotels-sample-indexer),接受系统生成的值。
在本快速入门中,请使用默认选项立即运行索引器一次。 托管数据是静态的,因此没有为其启用更改跟踪。
选择“提交”以创建并同时运行索引器。
监视索引器进度
可以在门户中监视索引器或索引的创建。 服务“概述”页提供了指向 Azure AI 搜索服务中创建的资源的链接。
在左侧,选择“索引器”。
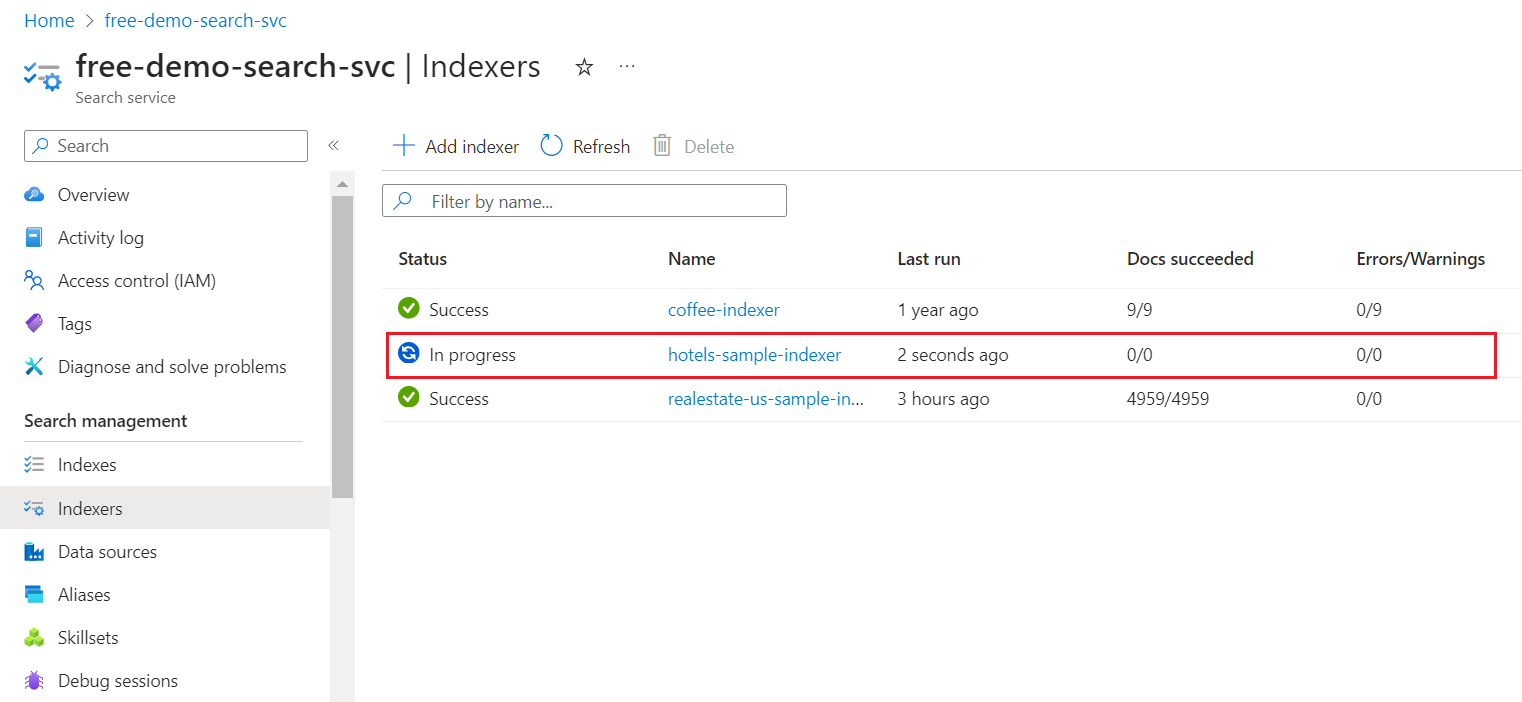
在 Azure 门户中更新页面结果可能需要几分钟时间。 此时会在列表中看到新创建的索引器,其状态为“正在进行”或“成功”。 该列表还显示已编制索引的文档数。
检查搜索索引结果
在左侧,选择“索引”。
选择“hotels-sample-index”。
等待 Azure 门户页刷新。 页面上应该会显示索引以及对应的文档计数和存储大小。
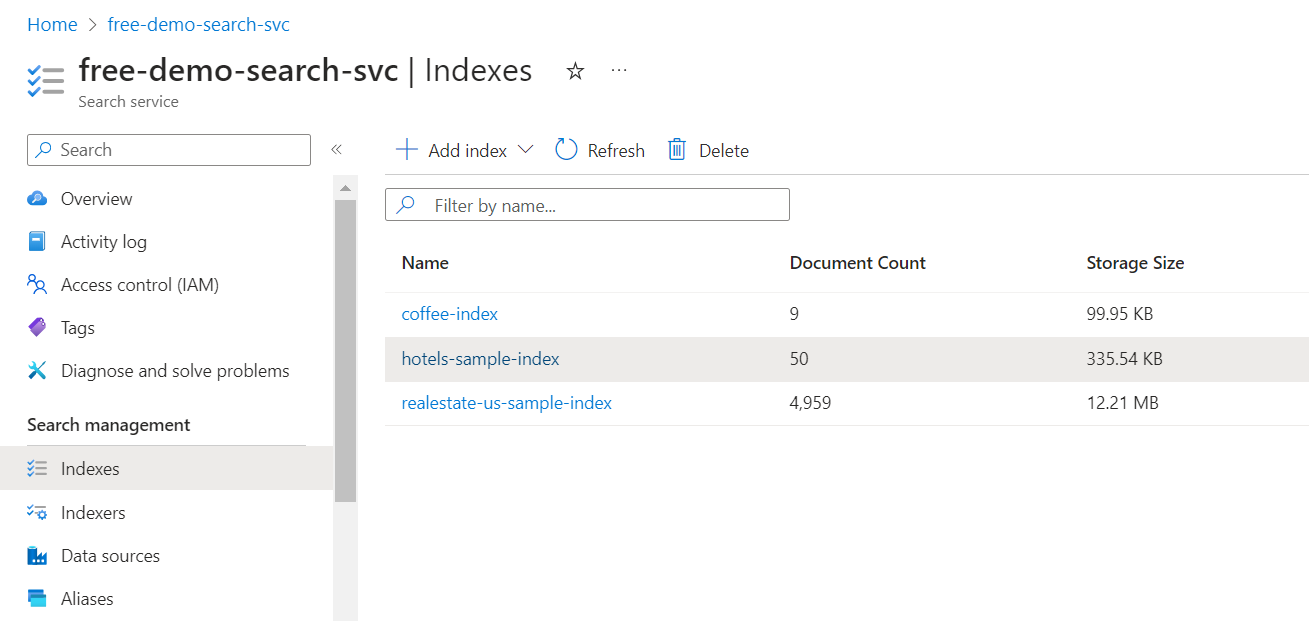
选择“字段”选项卡以查看索引架构。
检查哪些字段是可筛选或可排序字段,以便了解要编写的查询。
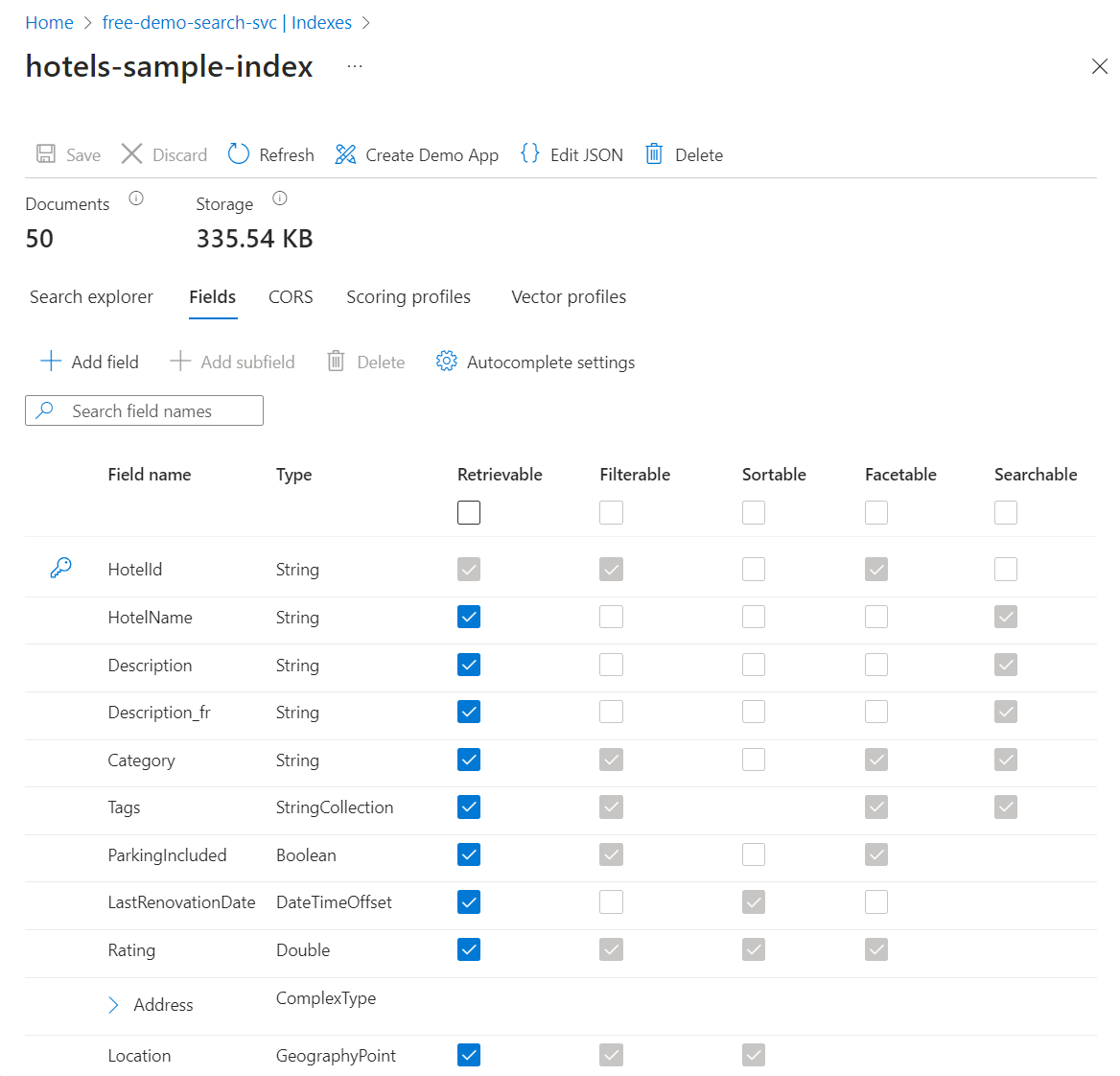
添加或更改字段
在“字段”选项卡上,可以使用“添加字段”及名称、支持的数据类型和属性创建新字段。
更改现有字段则更为困难。 现有字段在索引中具有物理表示形式,因此它们不可修改,即使在代码中也是如此。 要从根本上更改现有字段,需要创建一个替换原始字段的新字段。 随时可以向索引添加其他构造,例如评分配置文件和 CORS 选项。
若要清楚地了解在索引设计过程中可以和不可以编辑哪些内容,请花点时间查看索引定义选项。 字段列表中变灰的选项指示这些值无法修改或删除。
使用搜索浏览器查询
现在,你已有一个可以使用搜索浏览器来查询的搜索索引。 搜索资源管理器会发送符合 搜索 POST REST API 的 REST 调用。 该工具支持简单查询语法和完整的 Lucene 查询语法。
在“搜索资源管理器”选项卡上,输入要搜索的文本。
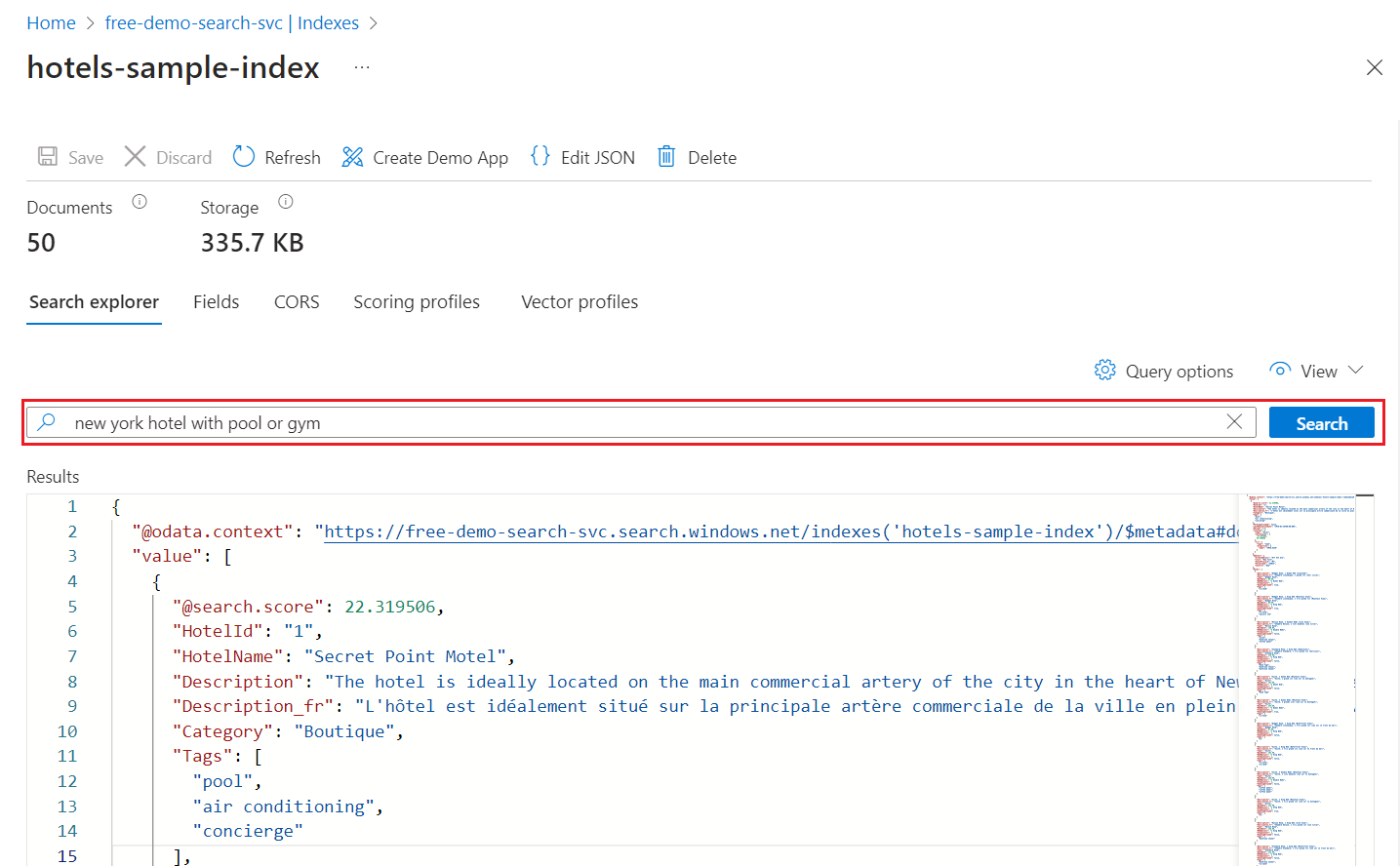
使用“微型地图”快速跳转到输出的非可见区域。
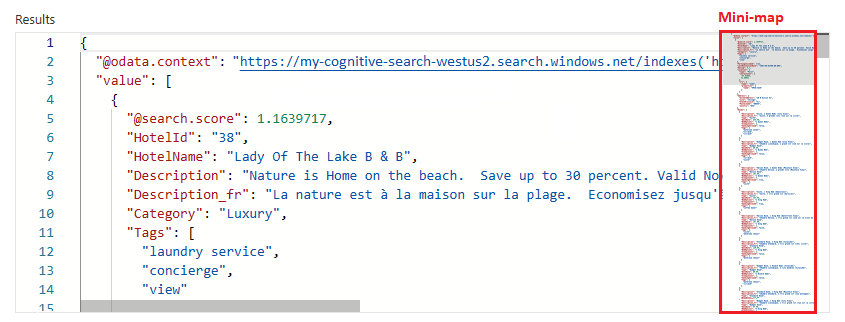
要指定语法,请切换到 JSON 视图。
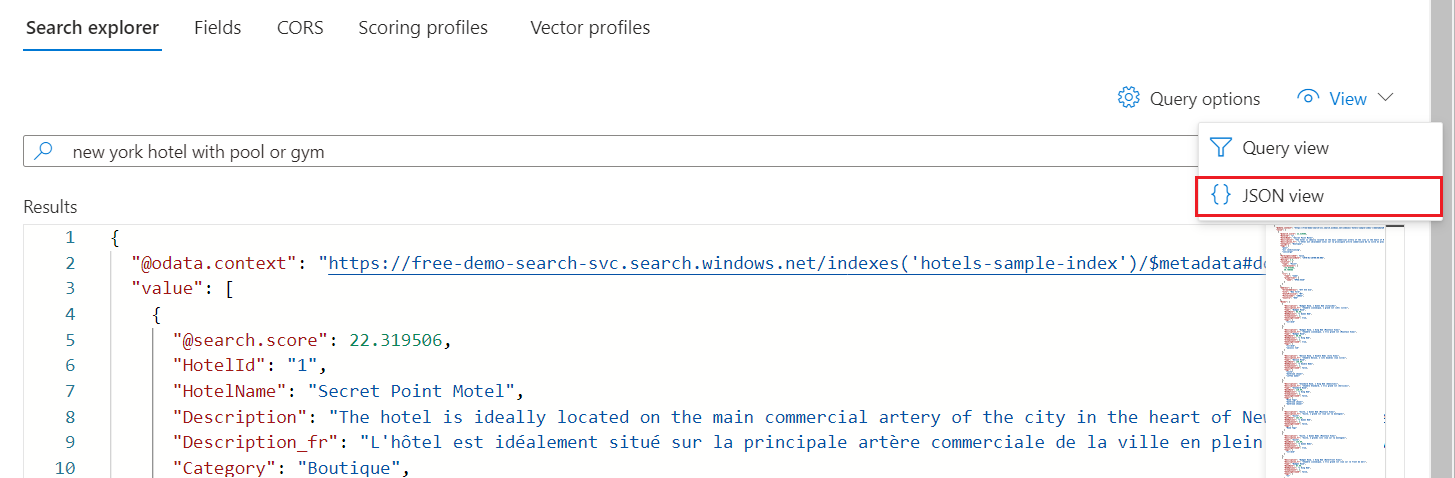
酒店示例索引的示例查询
以下示例假定使用 JSON 视图和 2023-11-01 REST API 版本。
筛选器示例
停车、标记、装修日期、评级和位置是可筛选的。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "Rating gt 4"
}
默认情况下,布尔筛选器假定为“true”。
{
"search": "beach OR spa",
"select": "HotelId, HotelName, Description, Rating",
"count": true,
"top": 10,
"filter": "ParkingIncluded"
}
地理空间搜索基于筛选器。 该 geo.distance 函数可根据指定 Location 和 geography'POINT 坐标筛选位置数据的所有结果。 该查询查找位于纬度经度坐标 -122.12 47.67(即“美国华盛顿州雷德蒙德”)5 公里范围内的酒店。该查询显示匹配项的总数 &$count=true 以及酒店名称和地址位置。
{
"search": "*",
"select": "HotelName, Address/City, Address/StateProvince",
"count": true,
"top": 10,
"filter": "geo.distance(Location, geography'POINT(-122.12 47.67)') le 5"
}
完整的 Lucene 语法示例
默认语法为简单语法,但如果需要使用模糊搜索或字词提升或正则表达式,请指定完整语法。
{
"queryType": "full",
"search": "seatle~",
"select": "HotelId, HotelName,Address/City, Address/StateProvince",
"count": true
}
默认情况下,执行典型搜索时,如果拼错查询字词(例如,将 seatle 错拼为 Seattle),则无法返回匹配项。 queryType=full 参数调用支持波形符 ~ 操作数的完整 Lucene 查询分析程序。 如果存在这些参数,则查询对指定的关键字执行模糊搜索。 该查询将查找匹配的结果以及与关键字相似但不完全匹配的结果。
请花一点时间尝试对索引使用上面的一些示例查询。 要了解有关查询的详细信息,请参阅《Azure AI 搜索中的查询》。
清理资源
在自己的订阅中操作时,最好在项目结束时确定是否仍需要已创建的资源。 持续运行资源可能会产生费用。 可以逐个删除资源,也可以删除资源组以删除整个资源集。
可以在 Azure 门户左侧窗格的“所有资源”或“资源组”下查找和管理服务的资源。
如果使用的是免费服务,请记住限制为三个索引、索引器和数据源。 可以在 Azure 门户中删除单个项目,以不超出此限制。
后续步骤
请尝试使用 Azure 门户向导生成在浏览器中运行的即用型 Web 应用。 可以在本快速入门中创建的小索引上尝试使用此向导,也可以使用内置的示例数据集之一来获得更丰富的搜索体验。