你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
Azure 流分析中的异常情况检测
Azure 流分析可在云和 Azure IoT Edge 中使用,它提供内置的机器学习异常情况检测功能,此功能可用于监视两种最常见的异常情况:暂时性异常和永久性异常。 使用 AnomalyDetection_SpikeAndDip 和 AnomalyDetection_ChangePoint 函数可以直接在流分析作业中执行异常情况检测。
机器学习模型采用统一采样的时序。 如果时序不统一,可以在调用异常情况检测之前插入包含翻转窗口的聚合步骤。
机器学习操作目前不支持季节性趋势或多变体关联。
使用 Azure 流分析中的机器学习进行异常情况检测
以下视频演示了如何使用 Azure 流分析中的机器学习函数实时检测异常情况。
模型行为
一般情况下,模型的准确度会随着滑动窗口中数据的增多而提升。 指定的滑动窗口中的数据被视为该时间范围内其正态值范围的一部分。 检查当前事件是否为异常事件时,模型只考虑滑动窗口中的事件历史记录。 随着滑动窗口的移动,将从模型的训练中逐出旧值。
函数的工作方式是根据它们到目前为止所观测到的值建立特定的法线。 通过在置信度级别内根据建立的法线进行比较来识别离群值。 窗口大小应该基于训练正常行为模型所需的最小事件数,这样,在发生异常时,该模型才能识别它。
模型的响应时间随着历史记录的大小增大而延长,因为它需要对更多的以往事件进行比较。 建议仅包含必要的事件数,以提高性能。
时序中的间隙可能是模型在特定的时间点未接收事件而造成的。 流分析将使用插补逻辑来处理这种情况。 历史记录大小以及同一滑动窗口的持续时间用于计算事件预期抵达的平均速率。
可以使用此处提供的异常情况生成器在 IoT 中心馈送采用不同异常模式的数据。 可以使用这些异常检测函数来设置 Azure 流分析作业,以便从此 Iot 中心读取并检测异常。
高峰和低谷
时序事件流中的暂时性异常称为高峰和低谷。 可以使用基于机器学习的运算符 AnomalyDetection_SpikeAndDip 来监视高峰和低谷。
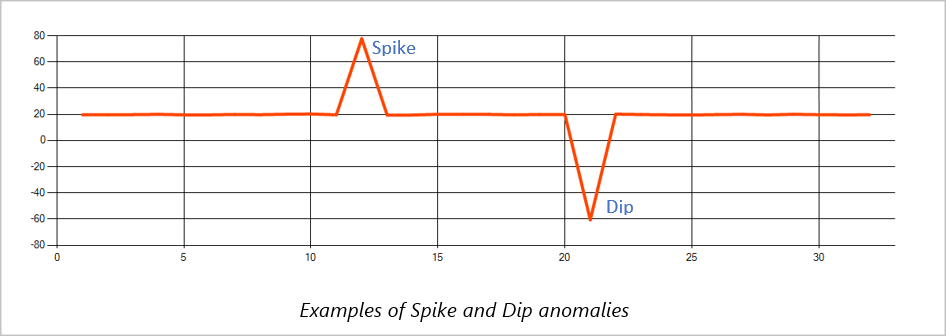
在同一滑动窗口中,如果第二个高峰小于第一个高峰,则相比于在指定的置信度级别内为第一个高峰计算的评分,较小高峰的计算评分可能不够明显。 可以尝试降低模型的置信度级别来检测此类异常。 但是,如果开始收到过多的警报,则可以使用更高的置信度间隔。
以下示例查询假设在 2 分钟的滑动窗口中,以每秒 1 个事件的统一速率输入事件,历史记录中包含 120 个事件。 最终的 SELECT 语句将提取事件,并输出评分和置信度级别为 95% 的异常状态。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_SpikeAndDip(CAST(temperature AS float), 95, 120, 'spikesanddips')
OVER(LIMIT DURATION(second, 120)) AS SpikeAndDipScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'Score') AS float) AS
SpikeAndDipScore,
CAST(GetRecordPropertyValue(SpikeAndDipScores, 'IsAnomaly') AS bigint) AS
IsSpikeAndDipAnomaly
INTO output
FROM AnomalyDetectionStep
变化点
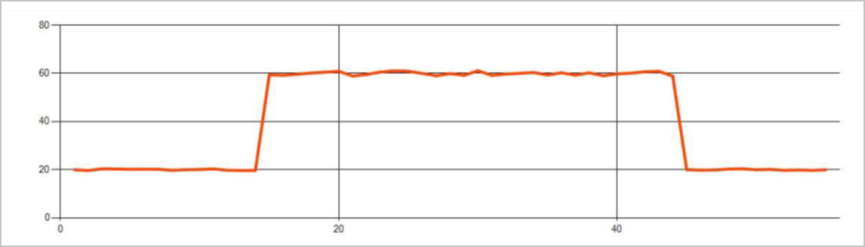
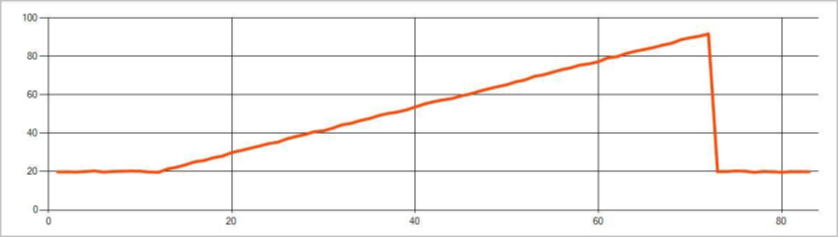
时序事件流中的永久性异常是指事件流中的值分布变化,例如级别变化和趋势。 在流分析中,将使用基于机器学习的 AnomalyDetection_ChangePoint 运算符检测此类异常。
持久更改的持续时间比峰值和下降要长得多,并可能表示灾难性事件。 通常肉眼很难观察到永久性变化,但可以使用“AnomalyDetection_ChangePoint”运算符来检测。
下图是级别变化的示例:
下图是趋势变化的示例:
以下示例查询假定在 20 分钟的滑动窗口中,一个统一的输入速率为每秒 1,200 个事件,其历史记录大小为 1,200 个事件。 最终的 SELECT 语句将提取事件,并输出评分和置信度级别为 80% 的异常状态。
WITH AnomalyDetectionStep AS
(
SELECT
EVENTENQUEUEDUTCTIME AS time,
CAST(temperature AS float) AS temp,
AnomalyDetection_ChangePoint(CAST(temperature AS float), 80, 1200)
OVER(LIMIT DURATION(minute, 20)) AS ChangePointScores
FROM input
)
SELECT
time,
temp,
CAST(GetRecordPropertyValue(ChangePointScores, 'Score') AS float) AS
ChangePointScore,
CAST(GetRecordPropertyValue(ChangePointScores, 'IsAnomaly') AS bigint) AS
IsChangePointAnomaly
INTO output
FROM AnomalyDetectionStep
性能特征
这些模型的性能取决于历史记录大小、窗口持续时间、事件负载,以及是否使用函数级分区。 本部分讨论这些配置,并提供有关如何维持每秒 1 K、5 K 和 10K 事件的引入速率的示例。
- 历史记录大小 - 这些模型的性能与历史记录大小呈线性关系。 历史记录越长,模型为新事件评分所需的时间就越长。 这是因为模型将新事件与历史记录缓冲区中的每个过去事件进行比较。
- 窗口持续时间 - 窗口持续时间应反映接收历史记录大小指定的事件数所花费的时间。 如果窗口中没有这么多事件,Azure 流分析会插补缺失值。 因此,CPU 消耗量取决于历史记录大小。
- 事件负载 - 事件负载越大,模型执行的工作就越多,因而会影响 CPU 消耗量。 假设易并行有利于业务逻辑利用更多的输入分区,则可以通过易并行来横向扩展作业。
- 函数级分区 - 可在异常情况检测函数调用中使用
PARTITION BY来执行函数级分区。 此类分区会增大开销,因为需要同时保留多个模型的状态。 函数级分区在设备级分区等方案中使用。
关系
历史记录大小、窗口持续时间和总事件负载之间的关系如下:
窗口持续时间 (毫秒) = 1000 * 历史记录大小 / (每秒输入事件总数 / 输入分区计数)
按 deviceId 对函数分区时,请将“PARTITION BY deviceId”添加到异常情况检测函数调用。
观测结果
下表包括针对非分区事例的单个节点(6 SU)的吞吐量观察值:
| 历史记录大小(事件数) | 窗口持续时间(毫秒) | 每秒输入事件总数 |
|---|---|---|
| 60 | 55 | 2,200 |
| 600 | 728 | 1,650 |
| 6,000 | 10,910 | 1,100 |
下表包括分区事例的单个节点(6 SU)的吞吐量观察值:
| 历史记录大小(事件数) | 窗口持续时间(毫秒) | 每秒输入事件总数 | 设备计数 |
|---|---|---|---|
| 60 | 1,091 | 1,100 | 10 |
| 600 | 10,910 | 1,100 | 10 |
| 6,000 | 218,182 | <550 | 10 |
| 60 | 21,819 | 550 | 100 |
| 600 | 218,182 | 550 | 100 |
| 6,000 | 2,181,819 | <550 | 100 |
运行上述非分区配置的示例代码位于 Azure 示例的大规模流式处理存储库 中。 该代码创建一个不使用函数级分区的流分析作业,该作业使用事件中心作为输入和输出。 输入负载是使用测试客户端生成的。 每个输入事件都是一个 1 知识库(KB) json 文档。 事件模拟发送 JSON 数据的 IoT 设备(最多 1 K 台设备)。 历史记录大小、窗口持续时间和总事件负载因两个输入分区而异。
注意
若要获得更准确的估算值,请根据具体的方案自定义示例。
识别瓶颈
若要识别管道中的瓶颈,请在 Azure 流分析作业中使用“指标”窗格。 查看针对吞吐量的“输入/输出事件”,以及“水印延迟”或“积压事件”,可以确定作业是否跟得上输入速率。 对于事件中心指标,请查看“限制的请求数”并相应地调整阈值单位。 对于 Azure Cosmos DB 指标,请查看“吞吐量”下的“每个分区键范围所使用的最大 RU/秒”,以确保均匀使用分区键范围。 对于 Azure SQL 数据库,请监视“日志 IO”和“CPU”。