你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
教程:无代码训练机器学习模型(已弃用)
可使用自动化机器学习训练的新的机器学习模型轻松扩充 Spark 表中的数据。 在 Azure Synapse Analytics 中,可在工作区中选择 Spark 表作为训练数据集,用于在无代码体验中构建机器学习模型。
本教程介绍如何使用 Synapse Studio 中的无代码体验来训练机器学习模型。 Synapse Studio 是 Azure Synapse Analytics 的一项功能。
你将在 Azure 机器学习中使用自动化机器学习,而不是手动对体验进行编码。 你训练的模型类型取决于你要解决的问题。 在本教程中,你将使用回归模型根据纽约市出租车数据集来预测出租车费用。
如果没有 Azure 订阅,请在开始之前创建一个免费帐户。
警告
- 从 2023 年 9 月 29 日起,Azure Synapse 将停止对 Spark 2.4 运行时的官方支持。 在 2023 年 9 月 29 日后,我们不再处理与 Spark 2.4 相关的任何支持工单。 不会有对 Spark 2.4 的 bug 或安全修复的发布管道。 在支持截止日期后使用 Spark 2.4 的风险自行承担。 我们强烈建议不再继续使用,因为有潜在的安全和功能问题。
- 在 Apache Spark 2.4 弃用过程中,我们会通知你:Azure Synapse Analytics 中的 AutoML 也会被弃用。 其中包括低代码接口和用于通过代码创建 AutoML 试用版的 API。
- 请注意,AutoML 功能只能通过 Spark 2.4 运行时使用。
- 对于希望继续利用 AutoML 功能的客户,我们建议将数据保存到 Azure Data Lake Storage Gen2 (ADLSg2) 帐户中。 可以从那里通过 Azure 机器学习 (AzureML) 无缝访问 AutoML 体验。 此处提供有关该解决方法的更多信息。
先决条件
- 一个 Azure Synapse Analytics 工作区。 确保它具有配置为默认存储的 Azure Data Lake Storage Gen2 存储帐户。 对于使用的 Data Lake Storage Gen2 文件系统,请确保你是存储 Blob 数据参与者。
- Azure Synapse Analytics(版本 2.4)工作区中的 Apache Spark 池。 有关详细信息,请参阅快速入门:使用 Synapse Studio 创建无服务器 Apache Spark 池。
- Azure Synapse Analytics 工作区中的 Azure 机器学习链接服务。 有关详细信息,请参阅快速入门:在 Azure Synapse Analytics 中创建新的 Azure 机器学习链接服务。
登录到 Azure 门户
登录到 Azure 门户。
创建用于训练数据集的 Spark 表
在本教程中,需要一个 Spark 表。 以下笔记本会创建一个:
将笔记本导入 Synapse Studio。
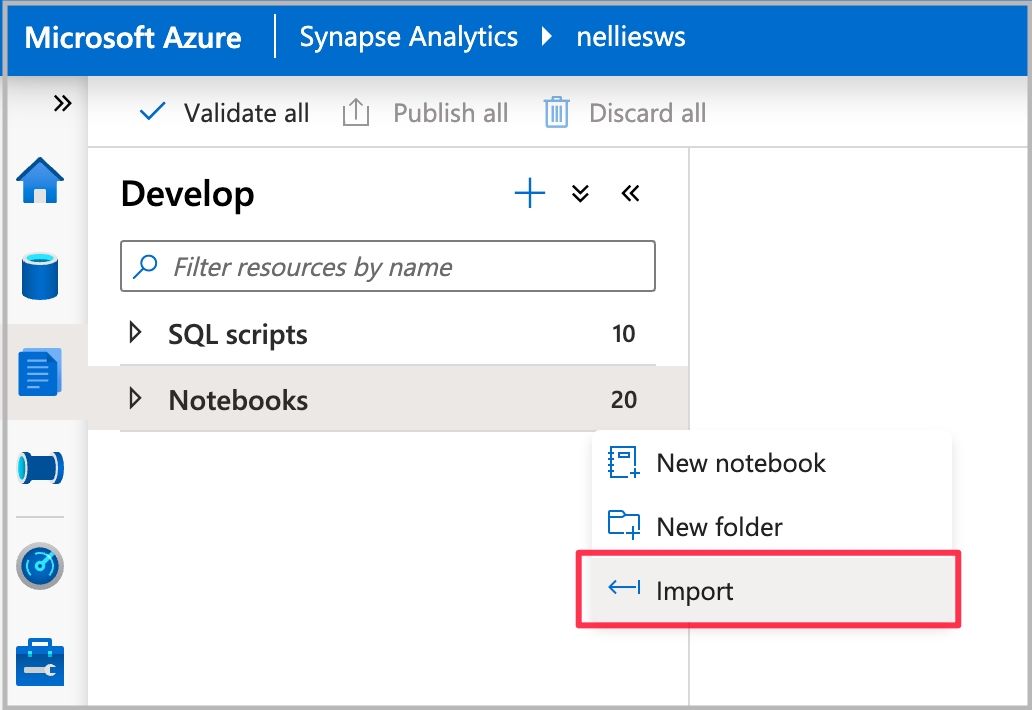
选择要使用的 Spark 池,然后选择“全部运行”。 此步骤将从打开的数据集获取纽约出租车数据,并将数据保存到默认的 Spark 数据库中。

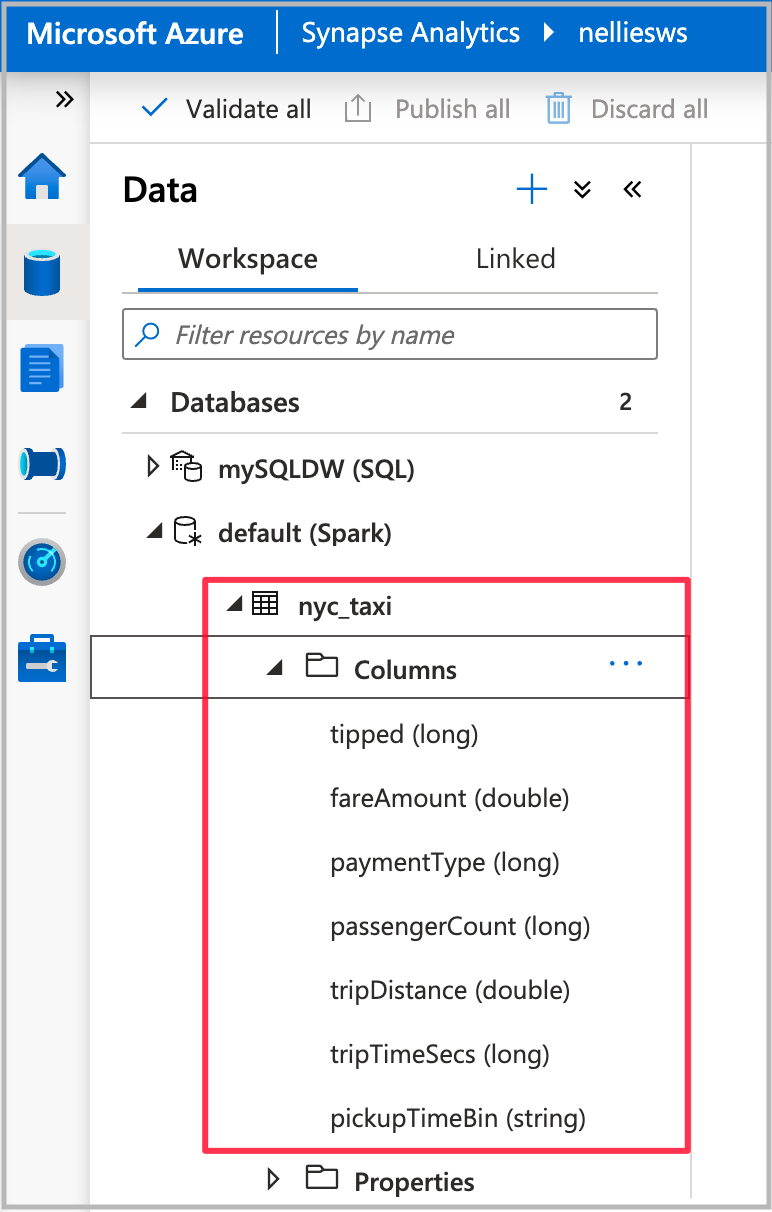
笔记本运行完成后,你将在默认的 Spark 数据库下看到一个新的 Spark 表。 从“数据”中找到名为 nyc_taxi 的表 。
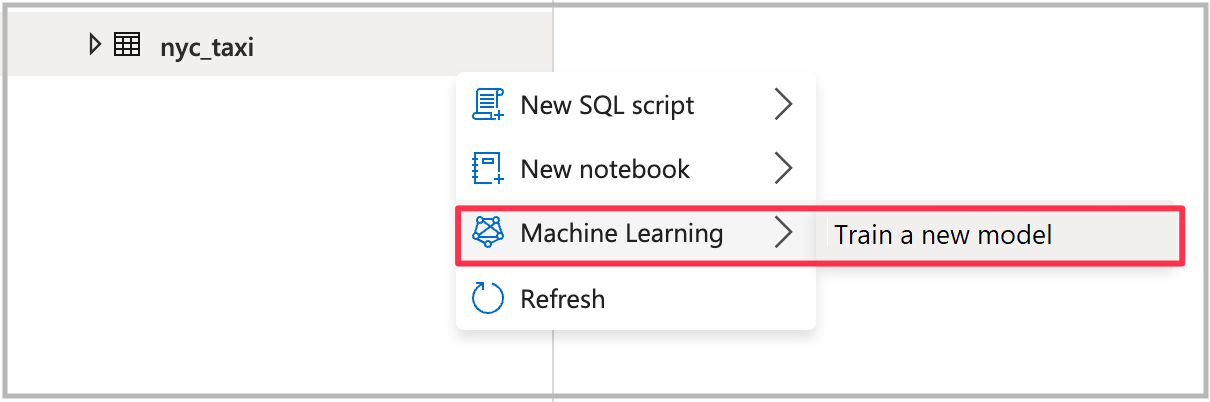
打开自动化机器学习向导
要打开向导,请右键单击在上一步中创建的 Spark 表。 然后选择“机器学习”>“训练新模型”。
选择模型类型
根据要回答的问题选择用于试验的机器学习模型类型。 由于尝试预测的值是数字(出租车费用),因此请在此处选择“回归”。 然后选择“继续”。
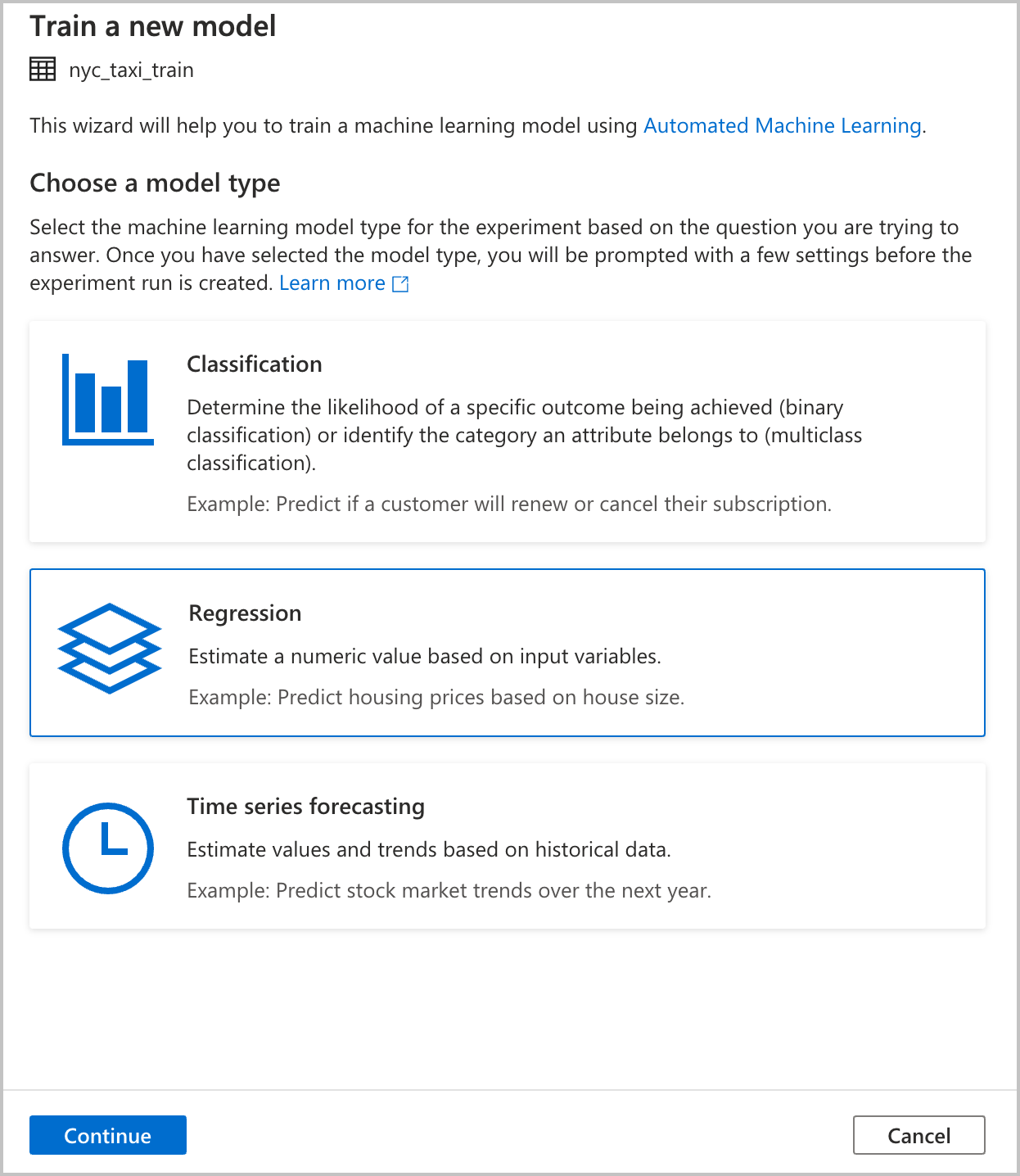
配置试验
提供配置详细信息用于创建在 Azure 机器学习中运行的自动化机器学习实验。 此运行会训练多个模型。 成功运行的最佳模型是在 Azure 机器学习模型注册表中注册的。
Azure 机器学习工作区:需要 Azure 机器学习工作区才能创建自动化机器学习试验运行。 你还需要使用链接服务将 Azure Synapse Analytics 工作区与 Azure 机器学习工作区相关联。 满足所有先决条件后,就可指定要用于此自动化运行的 Azure 机器学习工作区。
试验名称:指定试验名称。 提交自动化机器学习运行时,需提供试验名称。 运行的信息存储在 Azure 机器学习工作区中的试验下。 默认情况下,这种体验将创建一个新试验并生成建议的名称,但你也可提供现有试验的名称。
最佳模型名称:指定自动化运行中最佳模型的名称。 将此名称赋予最佳模型,并在该运行后自动保存在 Azure 机器学习模型注册表中。 自动化机器学习运行会创建许多机器学习模型。 根据将在后面步骤中选择的主要指标,可比较这些模型并选择最佳模型。
目标列:这是要训练模型预测的内容。 选择数据集中包含要预测的数据的列。 对于本教程,选择数字列
fareAmount作为目标列。Spark 池:指定要用于自动化试验运行的 Spark 池。 计算在指定的池上运行。
Spark 配置详细信息:除 Spark 池外,还可选择提供会话配置详细信息。
选择“继续”。
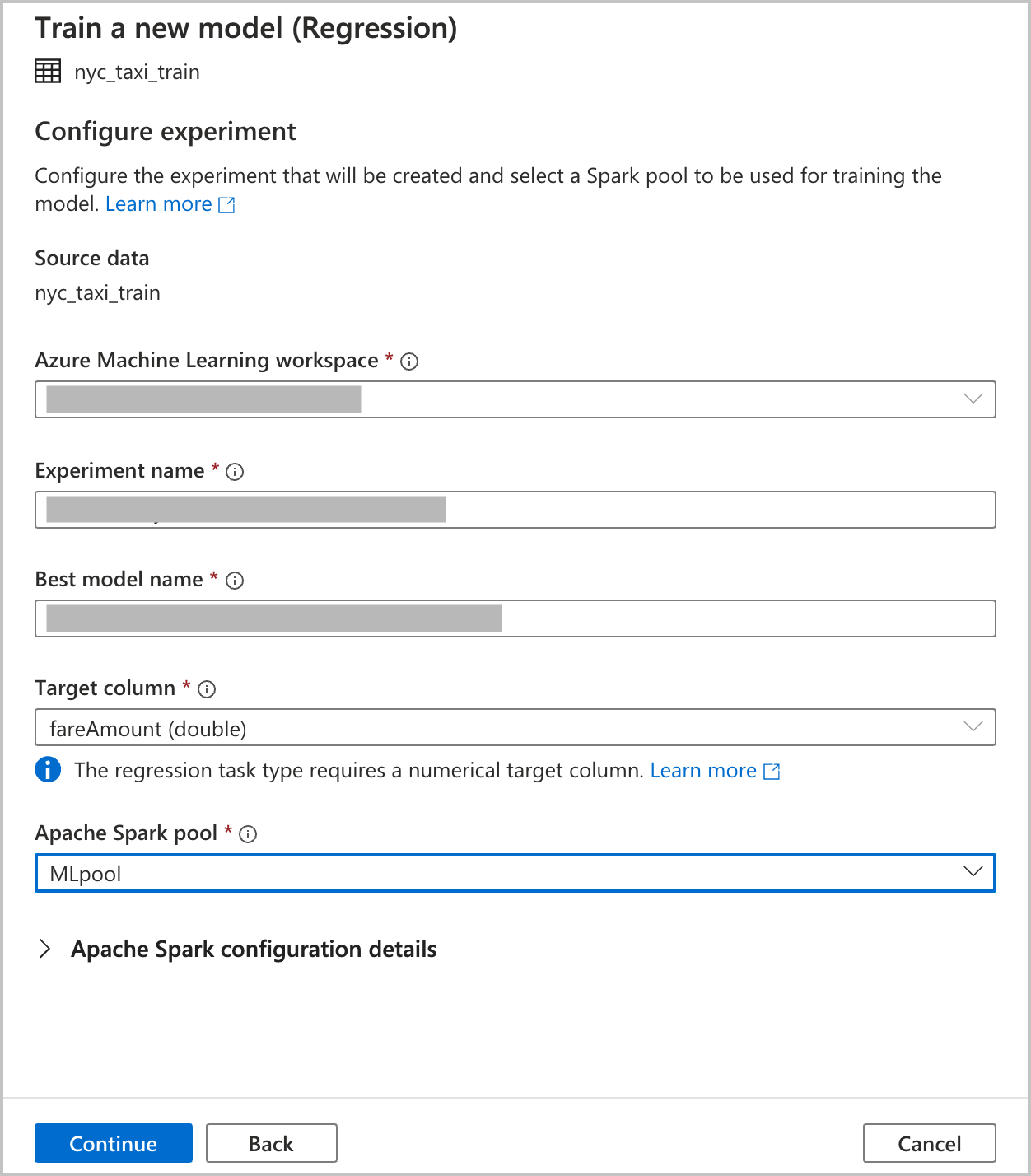
配置模型
由于在上一部分中选择了“回归”作为模型类型,因此可使用以下配置(这些也适用于“分类”模型类型) :
主要指标:输入用于衡量模型运行情况的指标。 使用该指标比较在自动化运行中创建的不同模型,并确定哪个模型效果最佳。
训练作业时间(小时):指定运行和训练模型的试验所需的最长时间(以小时为单位)。 请注意,还可提供小于 1 的值(例如 0.5)。
最大并发迭代数:选择并行运行的最大迭代数。
ONNX 模型兼容性:如果启用此选项,则由自动化机器学习训练的模型将转换为 ONNX 格式。 如果想要使用模型在 Azure Synapse Analytics SQL 池中进行评分,这一点尤其重要。
所有这些设置都具有可自定义的默认值。
启动运行
完成所有必需配置后,可启动自动化运行。 可以通过选择“创建运行”来选择直接创建运行,这将在没有代码的情况下启动运行。 如果更希望使用代码,也可选择“在笔记本中打开”,这将打开包含创建运行的代码的笔记本,这样你可以查看代码并自行启动运行。

注意
如果在上一部分中选择“时序预测”作为模型类型,则必须进行其他配置。 预测也不支持 ONNX 模型兼容性。
直接创建运行
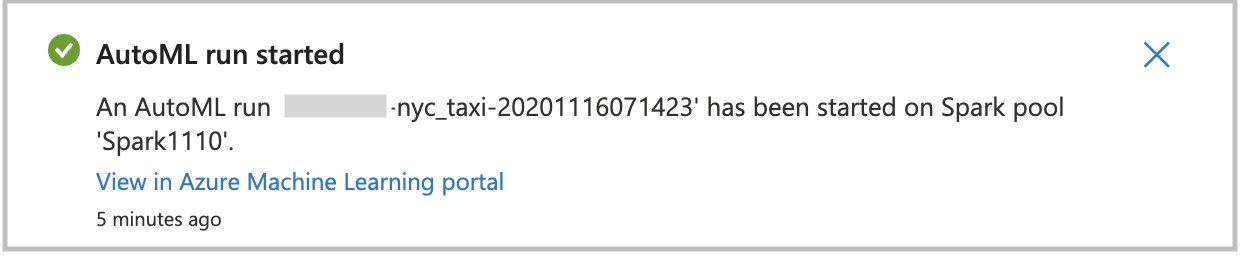
若要直接启动自动化机器学习运行,请选择“创建运行”。 你会看到一个通知,它指示运行正在启动。 然后,你会再看到一个通知显示操作成功。 你还可选择通知中的链接来查看 Azure 机器学习中的状态。
使用笔记本创建运行
若要生成笔记本,请选择“在笔记本中打开”。 这样,你就有机会为自动化机器学习运行添加设置或修改代码。 准备好运行代码后,选择“全部运行”。

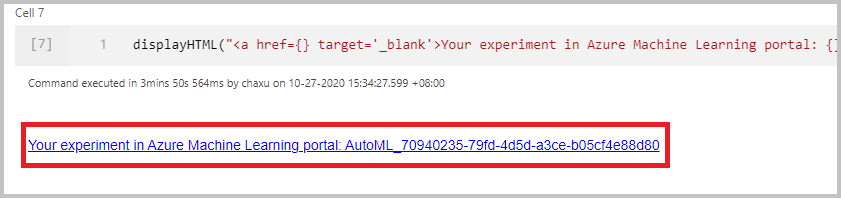
监视运行
成功提交运行后,你将在笔记本输出中看到一个链接,它指向 Azure 机器学习工作区中的试验运行。 选择该链接可监视 Azure 机器学习中的自动化运行。