你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
将 .NET for Apache Spark 与 Azure Synapse Analytics 配合使用
.NET for Apache Spark 提供针对 Spark 的免费开放源代码跨平台 .NET 支持。
它针对 Spark 提供了 .NET 绑定,允许你通过 C# 和 F# 访问 Spark API。 利用 .NET for Apache Spark,你还可以为使用 .NET 编写的 Spark 编写和执行用户定义的函数。 使用 .NET APIs for Spark,你可以在分析数据时访问 Spark DataFrame 的所有方面,包括 Spark SQL、增量 Lake 和结构化流式处理。
可以使用 NET for Apache Spark 通过 Spark 批处理作业定义或交互式 Azure Synapse Analytics 笔记本来分析数据。 本文介绍如何通过这两种技术将 .NET for Apache Spark 与 Azure Synapse 配合使用。
重要
.NET for Apache Spark 是 .NET Foundation 下的一个开源项目,它当前需要 .NET 3.1 库,而该库已到达不受支持状态。 我们希望告知 Azure Synapse Spark 的用户,在 Azure Synapse Runtime for Apache Spark 版本 3.3 中,.NET for Apache Spark 库已被移除。 有关此情况的详细信息,用户可以参阅 .NET 支持策略。
因此,用户将无法再通过 C# 和 F# 使用 Apache Spark API,也无法再在 Synapse 中的笔记本中或通过 Synapse 中的 Apache Spark 作业定义执行 C# 代码。 请务必注意,此更改仅影响 Azure Synapse Runtime for Apache Spark 3.3 及更高版本。
我们将根据 Azure Synapse Runtime 的生命周期阶段继续在 Azure Synapse Runtime 的所有早期版本中支持 .NET for Apache Spark。 但是,我们没有在 Azure Synapse Runtime for Apache Spark 3.3 和未来版本中支持 .NET for Apache Spark 的计划。 建议使用由 C# 或 F# 编写的现有工作负载的用户迁移到 Python 或 Scala。 建议用户关注此信息并相应地进行计划。
提交使用了 Spark 作业定义的批处理作业
访问教程,了解如何使用 Azure Synapse Analytics 创建 Synapse Spark 池的 Apache Spark 作业定义。 如果你尚未将应用打包提交到 Azure Synapse,请完成以下步骤。
配置
dotnet应用程序依赖项以与 Synapse Spark 兼容。 所需的 .NET Spark 版本将在 Synapse Studio 界面中的 Apache Spark 池配置下的管理工具箱下注明。
将项目创建为输出 Ubuntu x86 可执行文件的 .NET 控制台应用程序。
<Project Sdk="Microsoft.NET.Sdk"> <PropertyGroup> <OutputType>Exe</OutputType> <TargetFramework>netcoreapp3.1</TargetFramework> </PropertyGroup> <ItemGroup> <PackageReference Include="Microsoft.Spark" Version="2.1.0" /> </ItemGroup> </Project>运行以下命令来发布你的应用。 请确保将 mySparkApp 替换为你的应用的路径。
cd mySparkApp dotnet publish -c Release -f netcoreapp3.1 -r ubuntu.18.04-x64压缩发布文件夹(如
publish.zip)的内容,该文件夹是在步骤 1 中创建的。 所有程序集都应位于 ZIP 文件的根目录中,并且不应有中间文件夹层。 这意味着,当你解压缩publish.zip时,所有程序集都将被提取到当前工作目录中。在 Windows 上:
使用 Windows PowerShell 或 PowerShell 7,从发布目录的内容创建 .zip。
Compress-Archive publish/* publish.zip -Update在 Linux 上:
使用所有已发布的二进制文件打开 Bash Shell 并通过 cd 命令进入 bin 目录,然后运行以下命令。
zip -r publish.zip
Azure Synapse Analytics 笔记本中的 .NET for Apache Spark
若要为 .NET for Apache Spark 管道和方案构建原型,笔记本是一个不错的方法。 你可以快速高效地开始使用、了解、筛选、显示和可视化数据。
数据工程师、数据科学家、业务分析员和机器学习工程师都可以通过共享的交互式文档进行协作。 你可以看到数据探索的即时结果,并且可以在同一个笔记本中可视化你的数据。
如何使用 .NET for Apache Spark 笔记本
创建新笔记本时,你需要选择用来表述业务逻辑的语言内核。 提供了针对多种语言(包括 C#)的内核支持。
若要在 Azure Synapse Analytics 笔记本中使用 .NET for Apache Spark,请选择 .NET Spark (C#) 作为内核,并将笔记本附加到现有的无服务器 Apache Spark 池。
.NET Spark 笔记本基于 .NET 交互式体验并提供了交互式 C# 体验,能够直接将 .NET for Spark 与已预定义的 Spark 会话变量 spark 配合使用。
在笔记本中安装 NuGet 包
通过在 Nuget 包的名称之前使用 #r nuget magic 命令,可以将自己选择的 NuGet 包安装到笔记本中。 下图显示了一个示例:
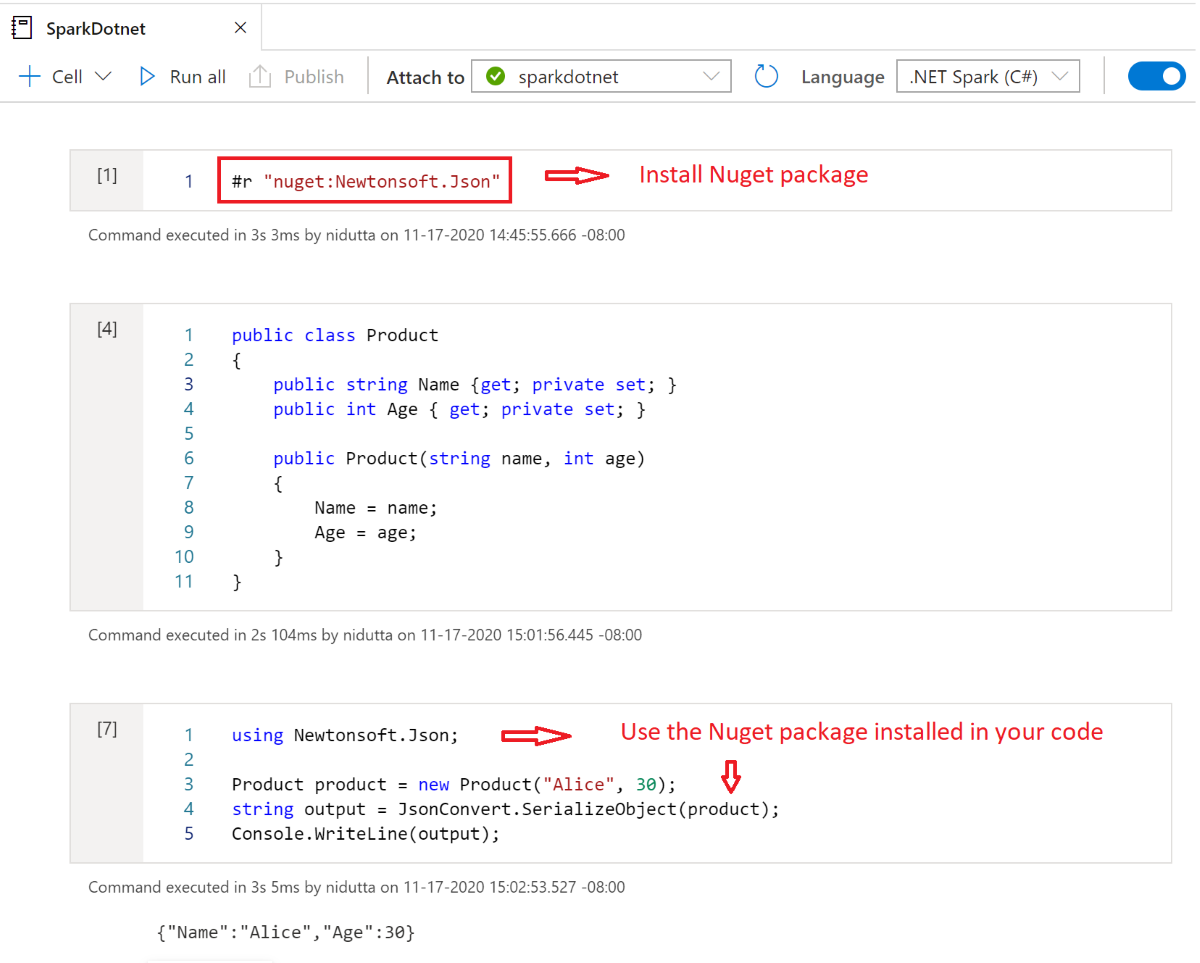
若要详细了解如何在笔记本中使用 NuGet 包,请参阅 .Net 交互式文档。
.NET for Apache Spark C# 内核功能
在 Azure Synapse Analytics 笔记本中使用 .NET for Apache Spark 时,可以使用以下功能:
- 声明性 HTML:使用 HTML 语法(例如标题、项目符号列表甚至显示图像)从单元中生成输出。
- 简单的 C# 语句(例如分配、输出到控制台、引发异常,等等)。
- 多行 C# 代码块(例如 if 语句、foreach 循环、类定义,等等)。
- 对标准 C# 库(例如 System、LINQ、Enumerables,等等)的访问权限。
- 支持 C# 8.0 语言功能。
- 预定义的变量“
spark”,使你能够访问 Apache Spark 会话。 - 支持定义可在 Apache Spark 内运行的 .NET 用户定义函数。 建议在 .NET for Apache Spark 交互式环境中编写和调用 UDF,以了解如何在 .NET for Apache Spark 交互式体验中使用 UDF。
- 支持通过
XPlot.Plotly库使用不同的图表(例如折线图、条形图或直方图)和布局(例如单一布局、重叠布局,等等)来可视化 Spark 作业的输出。 - 能够在 C# 笔记本中包括 NuGet 程序包。
疑难解答
Synapse Spark 作业定义运行中的 DotNetRunner: null / Futures timeout
使用 Spark 2.4 的 Spark 池上的 Synapse Spark 作业定义需要 Microsoft.Spark 1.0.0。 清除 bin 和 obj 目录,并使用 1.0.0 发布项目。
org.apache.spark 上的 OutOfMemoryError: java 堆空间
Dotnet Spark 1.0.0 使用与 1.1.1+ 不同的调试体系结构。 必须将 1.0.0 用于已发布的版本,将 1.1.1+ 用于本地调试。