你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
如何在 Azure Synapse Analytics 中通过无服务器 SQL 池使用 OPENROWSET
OPENROWSET(BULK...) 函数可用于访问 Azure 存储中的文件。 OPENROWSET 函数读取远程数据源(例如文件)的内容,并将内容作为行集返回。 在无服务器 SQL 池资源中,可以通过调用 OPENROWSET 函数并指定 BULK 选项来访问 OPENROWSET BULK 行集提供程序。
OPENROWSET 函数可以在查询的 FROM 子句中引用,就好象它是表名 OPENROWSET 一样。 该函数通过内置的 BULK 提供程序(用于从文件中读取数据并将数据作为行集返回)支持批量操作。
注意
专用 SQL 池中不支持 OPENROWSET 函数。
数据源
Synapse SQL 中的 OPENROWSET 函数从数据源读取文件的内容。 数据源是一个 Azure 存储帐户,它可以在 OPENROWSET 函数中显式引用,也可以基于你要读取的文件的 URL 动态推断。
可以选择让 OPENROWSET 函数包含 DATA_SOURCE 参数,以指定包含文件的数据源。
不带
DATA_SOURCE的OPENROWSET可用来从指定为BULK选项的 URL 位置直接读取文件的内容:SELECT * FROM OPENROWSET(BULK 'http://<storage account>.dfs.core.windows.net/container/folder/*.parquet', FORMAT = 'PARQUET') AS [file]
这是一种无需预先配置即可读取文件内容的简单快捷方法。 有了此选项,就可以使用基本身份验证选项来访问存储(使用 Microsoft Entra 直通身份验证进行 Microsoft Entra 登录,使用 SAS 令牌进行 SQL 登录)。
带
DATA_SOURCE的OPENROWSET可用来访问指定存储帐户中的文件:SELECT * FROM OPENROWSET(BULK '/folder/*.parquet', DATA_SOURCE='storage', --> Root URL is in LOCATION of DATA SOURCE FORMAT = 'PARQUET') AS [file]使用此选项,可以配置数据源中的存储帐户的位置,并指定应该用来访问存储的身份验证方法。
重要
不带
DATA_SOURCE的OPENROWSET提供了快速轻松地访问存储文件的方法,但提供的身份验证选项有限。 例如,Microsoft Entra 主体只能使用其 Microsoft Entra 标识或公开提供的文件来访问文件。 如果需要更强大的身份验证选项,请使用DATA_SOURCE选项,并定义需要将其用来访问存储的凭据。
安全性
数据库用户必须拥有 ADMINISTER BULK OPERATIONS 权限才能使用 OPENROWSET 函数。
存储管理员还必须提供有效的 SAS 令牌或允许 Microsoft Entra 主体访问存储文件,从而使用户能够访问文件。 请通过此文详细了解存储访问控制。
OPENROWSET 使用以下规则来确定如何向存储进行身份验证:
- 在不带
DATA_SOURCE的OPENROWSET中,身份验证机制依赖于调用方类型。- 任何用户都可使用
OPENROWSET而不使用DATA_SOURCE来读取 Azure 存储上公开提供的文件。 - 如果 Azure 存储允许 Microsoft Entra 用户访问基础文件(例如,如果调用方对 Azure 存储具有
Storage Reader权限),则 Microsoft Entra 登录名可以使用其自己的 Microsoft Entra 标识来访问受保护的文件。 - SQL 登录名还可以使用不带
DATA_SOURCE的OPENROWSET来访问公开可用的文件、使用 SAS 令牌或 Synapse 工作区的托管标识保护的文件。 你需要创建服务器范围的凭据,以便访问存储文件。
- 任何用户都可使用
- 在带
DATA_SOURCE的OPENROWSET中,身份验证机制是在分配给被引用数据源的数据库范围的凭据中定义的。 使用此选项,可以访问公开可用的存储,或者使用 SAS 令牌、工作区的托管标识或调用方的 Microsoft Entra 标识(如果调用方是 Microsoft Entra 主体)来访问存储。 如果DATA_SOURCE引用了非公共的 Azure 存储,则你需要创建数据库范围的凭据并在DATA SOURCE中引用该凭据以便访问存储文件。
调用方必须对凭据具有 REFERENCES 权限,才能使用它向存储进行身份验证。
语法
--OPENROWSET syntax for reading Parquet or Delta Lake files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT= ['PARQUET' | 'DELTA'] }
)
[WITH ( {'column_name' 'column_type' }) ]
[AS] table_alias(column_alias,...n)
--OPENROWSET syntax for reading delimited text files
OPENROWSET
( { BULK 'unstructured_data_path' , [DATA_SOURCE = <data source name>, ]
FORMAT = 'CSV'
[ <bulk_options> ]
[ , <reject_options> ] }
)
WITH ( {'column_name' 'column_type' [ 'column_ordinal' | 'json_path'] })
[AS] table_alias(column_alias,...n)
<bulk_options> ::=
[ , FIELDTERMINATOR = 'char' ]
[ , ROWTERMINATOR = 'char' ]
[ , ESCAPECHAR = 'char' ]
[ , FIRSTROW = 'first_row' ]
[ , FIELDQUOTE = 'quote_characters' ]
[ , DATA_COMPRESSION = 'data_compression_method' ]
[ , PARSER_VERSION = 'parser_version' ]
[ , HEADER_ROW = { TRUE | FALSE } ]
[ , DATAFILETYPE = { 'char' | 'widechar' } ]
[ , CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' } ]
[ , ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}' ]
<reject_options> ::=
{
| MAXERRORS = reject_value,
| ERRORFILE_DATA_SOURCE = <data source name>,
| ERRORFILE_LOCATION = '/REJECT_Directory'
}
参数
对于包含要查询的目标数据的输入文件,可以采用三个选项。 有效值是:
'CSV' - 包含带有行/列分隔符的任何分隔式文本文件。 任何字符(例如 TSV)均可用作字段分隔符:FIELDTERMINATOR = tab。
'PARQUET' - Parquet 格式的二进制文件
'DELTA' - 以 Delta Lake(预览版)格式组织的一组 Parquet 文件
空格值无效,例如“CSV”不是有效值。
'unstructured_data_path'
用于建立数据路径的 unstructured_data_path 可以是绝对路径,也可以是相对路径:
- 采用格式
\<prefix>://\<storage_account_path>/\<storage_path>的绝对路径使用户能够直接读取文件。 - 相对路径的格式为
<storage_path>,必须与DATA_SOURCE参数一起使用,它描述EXTERNAL DATA SOURCE中定义的 <storage_account_path> 位置中的文件模式。
在下面可以找到用于链接到特定外部数据源的 <相关存储帐户路径> 值。
| 外部数据源 | 前缀 | 存储帐户路径 |
|---|---|---|
| Azure Blob 存储 | http[s] | <storage_account>.blob.core.windows.net/path/file |
| Azure Blob 存储 | wasb[s] | <container>@<storage_account>.blob.core.windows.net/path/file |
| Azure Data Lake Store Gen1 | http[s] | <storage_account>.azuredatalakestore.net/webhdfs/v1 |
| Azure Data Lake Store Gen2 | http[s] | <storage_account>.dfs.core.windows.net /path/file |
| Azure Data Lake Store Gen2 | abfs[s] | <file_system>@<account_name>.dfs.core.windows.net/path/file |
'<storage_path>'
指定存储中的路径,该路径指向所要读取的文件夹或文件。 如果路径指向某个容器或文件夹,则会读取该特定容器或文件夹中的所有文件。 不包括子文件夹中的文件。
可以使用通配符将目标指定为多个文件或文件夹。 允许使用多个不连续的通配符。
下面的示例从以“/csv/population”开头的所有文件夹中读取以“population”开头的所有 csv 文件:
https://sqlondemandstorage.blob.core.windows.net/csv/population*/population*.csv
如果将 unstructured_data_path 指定为某个文件夹,则无服务器 SQL 池查询将从该文件夹中检索文件。
可以通过在路径末尾指定 /* 来指示无服务器 SQL 池遍历文件夹,如示例中所示:https://sqlondemandstorage.blob.core.windows.net/csv/population/**
注意
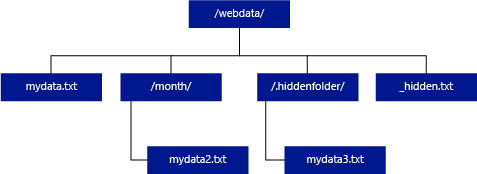
与 Hadoop 和 PolyBase 不同,无服务器 SQL 池不返回子文件夹,除非在路径末尾指定 /**。 与 Hadoop 和 PolyBase 一样,它不会返回文件名以下划线 (_) 或句点 (.) 开头的文件。
在以下示例中,如果 unstructured_data_path=https://mystorageaccount.dfs.core.windows.net/webdata/,则无服务器 SQL 池查询将返回 mydata.txt 中的行。 它不返回 mydata2.txt 和 mydata3.txt,因为这些文件位于子文件夹中。
[WITH ( {'column_name' 'column_type' [ 'column_ordinal'] }) ]
使用 WITH 子句可以指定要从文件中读取的列。
对于 CSV 数据文件,若要读取所有列,请提供列名及其数据类型。 如果需要列的子集,请使用序号按顺序从来源数据文件中选取列。 列将按序号指定值绑定。 如果使用 HEADER_ROW = TRUE,则列绑定是按列名而不是按顺序位置来完成的。
提示
对于 CSV 文件,你也可以省略 WITH 子句。 将从文件内容自动推断数据类型。 可以使用 HEADER_ROW 参数来指定是否存在标题行,在这种情况下,将从标题行中读取列名称。 有关详细信息,请查看自动架构发现。
对于 Parquet 或 Delta Lake 文件,请提供与来源数据文件中的列名匹配的列名。 列将按名称绑定,并区分大小写。 如果省略 WITH 子句,将返回 Parquet 文件中的所有列。
重要
Parquet 文件和 Delta Lake 文件中的列名区分大小写。 如果指定的列名的大小写不同于这些文件中的列名大小写,则会为该列返回
NULL值。
column_name = 输出列的名称。 如果提供,则此名称将替代源文件中的列名和 JSON 路径中提供的列名称(如果有)。 如果未提供 json_path,它将自动添加为“$.column_name”。 检查 json_path 参数的行为。
column_type = 输出列的数据类型。 将在此处发生隐式数据类型转换。
column_ordinal = 列在源文件中的序号。 对于 Parquet 文件,将忽略此参数,因为绑定是按名称进行的。 以下示例仅返回 CSV 文件中的第二列:
WITH (
--[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2,
[country_name] VARCHAR (100) COLLATE Latin1_General_BIN2 2
--[year] smallint,
--[population] bigint
)
json_path = 列或嵌套属性的 JSON 路径表达式。 默认的路径模式为宽松。
注意
在严格模式下,如果提供的路径不存在,则查询将失败并显示错误。 在宽松模式下,查询将成功,并且 JSON 路径表达式的计算结果将为 NULL。
<bulk_options>
FIELDTERMINATOR ='field_terminator'
指定要使用的字段终止符。 默认的字段终止符为逗号(“,”)。
ROWTERMINATOR ='row_terminator'`
指定要使用的行终止符。 如果未指定行终止符,将使用默认终止符之一。 PARSER_VERSION = '1.0' 的默认终止符为 \r\n、\n 和 \r。 PARSER_VERSION = '2.0' 的默认终止符为 \r\n 和 \n。
注意
使用 PARSER_VERSION='1.0' 并指定 \n(换行符)作为行终止符时,它将自动以 \r(回车符)作为前缀,从而形成行终止符 \r\n。
ESCAPE_CHAR = 'char'
指定文件中用于将自身及文件中所有分隔符值转义的字符。 如果转义字符后接除本身以外的某个值或者任何分隔符值,则读取值时会删除该转义字符。
无论是否启用了 FIELDQUOTE,都会应用 ESCAPECHAR 参数。 不会使用该参数来转义引号字符。 必须使用其他引号字符来转义引号字符。 要让引号字符出现在列值内,必须将值放在引号中。
FIRSTROW = 'first_row'
指定要加载的第一行的行号。 默认值为 1,表示指定数据文件中的第一行。 通过对行终止符进行计数来确定行号。 FIRSTROW 从 1 开始。
FIELDQUOTE = 'field_quote'
指定将用作 CSV 文件引号字符的字符。 如果未指定,将使用引号字符 (")。
DATA_COMPRESSION = 'data_compression_method'
指定压缩方法。 仅在 PARSER_VERSION='1.0' 时受支持。 支持以下压缩方法:
- GZIP
PARSER_VERSION = 'parser_version'
指定读取文件时要使用的分析器版本。 当前支持的 CSV 分析器版本为 1.0 和 2.0:
- PARSER_VERSION = '1.0'
- PARSER_VERSION = '2.0'
CSV 分析器版本 1.0 是默认版本且功能丰富。 版本 2.0 是为提高性能而构建的,并不支持所有选项和编码。
CSV 分析器版本 1.0 详细信息:
- 不支持以下选项:HEADER_ROW。
- 默认终止符为 \r\n、\n 和 \r。
- 如果指定 \n(换行符)作为行终止符,它将自动以 \r(回车符)作为前缀,从而形成行终止符 \r\n。
CSV 分析器版本 2.0 详细信息:
- 不是所有数据类型都受支持。
- 最大字符列长度为 8000。
- 最大行大小限制为 8 MB。
- 不支持以下选项:DATA_COMPRESSION。
- 带引号的空字符串 ("") 被解释为空字符串。
- 不支持 DATEFORMAT SET 选项。
- DATE 数据类型支持的格式:YYYY-MM-DD
- TIME 数据类型支持的格式:HH:MM:SS[.fractional seconds]
- DATETIME2 数据类型支持的格式:YYYY-MM-DD HH:MM:SS[.fractional seconds]
- 默认终止符为 \r\n 和 \n。
HEADER_ROW = { TRUE | FALSE }
指定 CSV 文件是否包含标题行。 默认为 FALSE.,在 PARSER_VERSION='2.0' 时受支持。 如果为 TRUE,则根据 FIRSTROW 参数从第一行读取列名称。 如果为 TRUE 且使用 WITH 指定了架构,则列名的绑定将按列名而不是按顺序位置来完成。
DATAFILETYPE = { 'char' | 'widechar' }
指定编码:char 用于 UTF8,widechar 用于 UTF16 文件。
CODEPAGE = { 'ACP' | 'OEM' | 'RAW' | 'code_page' }
指定该数据文件中数据的代码页。 默认值为 65001(UTF-8 编码)。 此处有关于此选项的更多详细信息。
ROWSET_OPTIONS = '{"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}'
此选项将在查询执行期间禁用文件修改检查,并读取查询运行时更新的文件。 当需要读取查询运行时追加的仅限追加的文件时,此选项非常有用。 在可追加文件中,不更新现有内容,仅添加新行。 因此,与可更新文件相比,这样做生成错误结果的可能性最低。 使用此选项,可以在不处理错误的情况下读取经常追加的文件。 有关详细信息,请参阅查询可追加的 CSV 文件部分。
拒绝选项
注意
已拒绝行功能目前以公共预览版提供。 请注意,已拒绝行功能适用于带分隔符的文本文件和 PARSER_VERSION 1.0。
可以指定用于确定服务如何处理它从外部数据源检索的脏记录的拒绝参数。 如果实际数据类型与外部表的列定义不匹配,则数据记录被视为“脏”。
未指定或更改拒绝选项时,服务会使用默认值。 服务将使用拒绝选项来确定在实际查询失败之前可以拒绝的行数。 查询会返回(部分)结果,直到超出拒绝阈值。 查询随后失败,并出现相应的错误消息。
MAXERRORS = reject_value
指定在查询失败之前可以拒绝的行数。 MAXERRORS 必须是介于 0 和 2,147,483,647 之间的整数。
ERRORFILE_DATA_SOURCE = data source
指定应写入拒绝行和相应错误文件的数据源。
ERRORFILE_LOCATION = Directory Location
指定应写入拒绝行和对应错误文件的 DATA_SOURCE 或 ERROR_FILE_DATASOURCE(如指定)中的目录。 如果指定的路径不存在,服务将代你创建一个。 创建名称为“rejectedrows”的子目录。除非在位置参数中明确命名,否则,“ ”字符将确保对该目录转义以进行其他数据处理。 在此目录中,存在根据负载提交时间创建的文件夹,格式为 YearMonthDay_HourMinuteSecond_StatementID(例如 20180330-173205-559EE7D2-196D-400A-806D-3BF5D007F891)。 可以使用语句 ID 将文件夹与生成它的查询相关联。 在此文件夹中,将写入两个文件:error.json 文件和数据文件。
error.json 文件包含遇到拒绝的行相关错误的 json 数组。 表示错误的每个元素都包含以下属性:
| Attribute | 说明 |
|---|---|
| 错误 | 拒绝行的原因。 |
| 行 | 文件中拒绝的行序号。 |
| 列 | 拒绝的列序号。 |
| 值 | 拒绝的列值。 如果值大于 100 个字符,则只显示前 100 个字符。 |
| 文件 | 行所属的文件的路径。 |
带分隔符的文本的快速分析
可以使用两种带分隔符的文本分析器版本。 CSV 分析器版本 1.0 是默认版本且功能丰富,而分析器版本 2.0 是为提高性能而构建的。 分析器 2.0 的性能改进来自高级分析技术和多线程处理。 随着文件大小的增大,速度差异会更大。
自动架构发现
通过省略 WITH 子句,无需了解或指定架构,即可轻松查询 CSV 和 Parquet 文件。 将从文件中推断列名称和数据类型。
Parquet 文件包含要读取的列元数据,可在 Parquet 的类型映射中找到类型映射。 有关示例,请查看在不指定架构的情况下读取 Parquet 文件。
对于 CSV 文件,可从标题行读取列名称。 可以使用 HEADER_ROW 参数指定是否存在标题行。 如果 HEADER_ROW = FALSE,将使用通用列名称:C1, C2, ...Cn,其中 n 是文件中的列数。 将从前 100 个数据行推断数据类型。 有关示例,请查看在不指定架构的情况下读取 CSV 文件。
请记住,如果一次读取多个文件,则将根据服务从存储中获取的第一个文件推断出架构。 这可能意味着预期的一些列被省略了,都是因为服务用于定义架构的文件不包含这些列。 在这种情况下,请使用 OPENROWSET WITH 子句。
重要
在有些情况下,由于缺少信息而无法推断出适当的数据类型,将改用较大的数据类型。 这会造成性能开销,并且对于将推断为 varchar(8000) 的字符列尤其重要。 为了获得最佳性能,请查看推断的数据类型并使用适当的数据类型。
Parquet 的类型映射
Parquet 文件和 Delta Lake 文件包含每一列的类型说明。 下表介绍了如何将 Parquet 类型映射到 SQL 本机类型。
| Parquet 类型 | Parquet 逻辑类型(批注) | SQL 数据类型 |
|---|---|---|
| BOOLEAN | bit | |
| BINARY/BYTE_ARRAY | varbinary | |
| DOUBLE | FLOAT | |
| FLOAT | real | |
| INT32 | int | |
| INT64 | bigint | |
| INT96 | datetime2 | |
| FIXED_LEN_BYTE_ARRAY | binary | |
| BINARY | UTF8 | varchar *(UTF8 collation) |
| BINARY | STRING | varchar *(UTF8 collation) |
| BINARY | ENUM | varchar *(UTF8 collation) |
| FIXED_LEN_BYTE_ARRAY | UUID | uniqueidentifier |
| BINARY | DECIMAL | Decimal |
| BINARY | JSON | varchar(8000) *(UTF8 排序规则) |
| BINARY | BSON | 不支持 |
| FIXED_LEN_BYTE_ARRAY | DECIMAL | Decimal |
| BYTE_ARRAY | INTERVAL | 不支持 |
| INT32 | INT(8, true) | smallint |
| INT32 | INT(16, true) | smallint |
| INT32 | INT(32, true) | int |
| INT32 | INT(8, false) | tinyint |
| INT32 | INT(16, false) | int |
| INT32 | INT(32, false) | bigint |
| INT32 | DATE | date |
| INT32 | DECIMAL | Decimal |
| INT32 | TIME (MILLIS) | time |
| INT64 | INT(64, true) | bigint |
| INT64 | INT(64, false) | decimal(20,0) |
| INT64 | DECIMAL | Decimal |
| INT64 | TIME (MICROS) | time |
| INT64 | TIME (NANOS) | 不支持 |
| INT64 | TIMESTAMP(规范化为 utc)(MILLIS / MICROS) | datetime2 |
| INT64 | TIMESTAMP(不规范化为 utc)(MILLIS / MICROS) | bigint - 在将 bigint 值转换为日期/时间值之前,请确保使用时区偏移量显式对其进行调整。 |
| INT64 | TIMESTAMP (NANOS) | 不支持 |
| 复杂类型 | 列表 | varchar(8000),序列化为 JSON |
| 复杂类型 | MAP | varchar(8000),序列化为 JSON |
示例
在不指定架构的情况下读取 CSV 文件
以下示例在不指定列名称和数据类型的情况下读取包含标题行的 CSV 文件:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0',
HEADER_ROW = TRUE) as [r]
以下示例在不指定列名称和数据类型的情况下读取不包含标题行的 CSV 文件:
SELECT
*
FROM OPENROWSET(
BULK 'https://pandemicdatalake.blob.core.windows.net/public/curated/covid-19/ecdc_cases/latest/ecdc_cases.csv',
FORMAT = 'CSV',
PARSER_VERSION = '2.0') as [r]
在不指定架构的情况下读取 Parquet 文件
以下示例在不指定列名和数据类型的情况下,以 Parquet 格式返回人口普查数据集中第一行的所有列:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
) AS [r]
在不指定架构的情况下读取 Delta Lake 文件
以下示例在不指定列名和数据类型的情况下,以 Delta Lake 格式返回人口普查数据集中第一行的所有列:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='DELTA'
) AS [r]
从 CSV 文件中读取特定列
以下示例仅返回 population*.csv 文件中序号为 1 和 4 的两列。 由于文件中没有标题行,因此该示例从第一行开始读取:
SELECT
*
FROM OPENROWSET(
BULK 'https://sqlondemandstorage.blob.core.windows.net/csv/population/population*.csv',
FORMAT = 'CSV',
FIRSTROW = 1
)
WITH (
[country_code] VARCHAR (5) COLLATE Latin1_General_BIN2 1,
[population] bigint 4
) AS [r]
从 Parquet 文件中读取特定列
以下示例以 Parquet 格式仅返回人口普查数据集内第一行的两列:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
[stateName] VARCHAR (50),
[population] bigint
) AS [r]
使用 JSON 路径指定列
以下示例演示了如何在 WITH 子句中使用 JSON 路径表达式,并说明了严格和宽松路径模式之间的区别:
SELECT
TOP 1 *
FROM
OPENROWSET(
BULK 'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=20*/*.parquet',
FORMAT='PARQUET'
)
WITH (
--lax path mode samples
[stateName] VARCHAR (50), -- this one works as column name casing is valid - it targets the same column as the next one
[stateName_explicit_path] VARCHAR (50) '$.stateName', -- this one works as column name casing is valid
[COUNTYNAME] VARCHAR (50), -- STATEname column will contain NULLs only because of wrong casing - it targets the same column as the next one
[countyName_explicit_path] VARCHAR (50) '$.COUNTYNAME', -- STATEname column will contain NULLS only because of wrong casing and default path mode being lax
--strict path mode samples
[population] bigint 'strict $.population' -- this one works as column name casing is valid
--,[population2] bigint 'strict $.POPULATION' -- this one fails because of wrong casing and strict path mode
)
AS [r]
在 BULK 路径中指定多个文件/文件夹
以下示例演示如何在 BULK 参数中使用多个文件/文件夹路径:
SELECT
TOP 10 *
FROM
OPENROWSET(
BULK (
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2000/*.parquet',
'https://azureopendatastorage.blob.core.windows.net/censusdatacontainer/release/us_population_county/year=2010/*.parquet'
),
FORMAT='PARQUET'
)
AS [r]
后续步骤
有关更多示例,请参阅查询数据存储快速入门,了解如何使用 OPENROWSET 来读取 CSV、PARQUET、DELTA LAKE 和 JSON 文件格式。 查看最佳做法以获得最佳性能。 你还可以了解如何使用 CETAS 将查询结果保存到 Azure 存储。