你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
一个 Azure 区域内的 SAP HANA 可用性
本文介绍一个 Azure 区域中 SAP HANA 的多个可用性方案。 Azure 已在许多区域上市,这些区域分散在世界各地。 有关 Azure 区域的列表,请查阅 Azure 区域。 Microsoft 将 SAP HANA 部署在一个 Azure 区域内的 VM 上,可以提供包含一个 HANA 实例的单一 VM 部署。 为了提高可用性,可以使用具有 FD=1 的灵活规模集、可用性区域或使用 HANA 系统副本 (replica)的可用性集部署两个具有两个 HANA 实例的 VM。
提供可用性区域的 Azure 区域由多个数据中心组成,每个数据中心都有自己的电源、冷却和网络基础结构。 在单个 Azure 区域中提供不同区域的目的是在两到三个可用可用性区域之间部署应用程序。 通过跨区域分配应用程序部署,影响特定 Azure 可用性区域基础结构的任何电源或网络问题都不会完全中断应用程序在 Azure 区域中的功能。 虽然容量可能会降低一些,例如一个区域中 VM 的潜在损失,但剩余区域中的 VM 将继续运行,而不会中断。 若要在跨不同区域的单独 VM 中设置两个 HANA 实例,可以选择使用 具有 FD=1 的灵活规模集或 可用性区域 部署选项部署 VM。
为了提高区域中的可用性,建议使用可用性集部署两个具有两个 HANA 实例的 VM。 Azure 可用性集是一项逻辑分组功能,可确保在可用性集中配置的 VM 资源在 Azure 数据中心内部署时相互故障隔离。 Azure 确保可用性集中部署的 VM 能够跨多个物理服务器、计算机架、存储单元和网络交换机运行。 在某些 Azure 文档中,此配置被阐述为将 VM 放置在不同的更新域和容错域中。 这些位置通常是在 Azure 数据中心内。 假设电源和网络问题会影响要部署的数据中心,一个 Azure 区域中的所有容量都会受到影响。
代表 Azure 可用性区域的数据中心的位置既要考虑到不同区域中部署的服务之间的网络延迟是否可接受,也要考虑到数据中心之间的距离。 在理想情况下,自然灾害不会影响到此区域中所有可用性区域的电源、网络和基础结构。 但是,在出现非常严重的自然灾害时,可用性区域不一定总能在一个区域中提供可用性。 想像一下,2017 年 8 月 20 日玛丽亚飓风袭击了波多黎各岛。 这场飓风使方圆 90 英里的岛屿几乎完全陷入一片黑暗。
单一 VM 场景
在单一 VM 场景中,我们将为 SAP HANA 实例创建一个 Azure VM。 使用 Azure 高级存储来托管操作系统磁盘和所有数据磁盘。 99.9% 的 Azure 正常运行时间 SLA 和其他 Azure 组件提供的 SLA 足以向客户履行可用性 SLA。 在此方案中,无需为运行 DBMS 层的 VM 使用 Azure 可用性集。 此场景依赖于两种不同的功能:
- Azure VM 自动重启(也称为 Azure 服务修复)
- SAP HANA 自动重启
Azure VM 自动重启(服务修复)是 Azure 中的一项功能,它在两个级别工作:
- Azure 服务器主机(检查服务器主机上托管的 VM 的运行状况)。
- Azure 结构控制器(监视服务器主机的运行状况和可用性)。
运行状况检查功能将会监视 Azure 服务器主机上托管的每个 VM 的运行状况。 如果 VM 的状态不正常,则检查 VM 运行状况的 Azure 主机代理可以执行 VM 重新启动。 结构控制器会通过检查指示主机硬件问题的许多不同参数,来检查主机的运行状况。 此外,它还会通过网络检查主机的可访问性。 主机出现问题迹象可能会导致以下事件:
- 如果出现主机状态不正常的迹象,则会触发主机重新启动,以及该主机上运行的 VM 重启。
- 如果成功重新启动后主机处于不正常状态,则将最初节点(现在不正常)上的 VM 将重新部署到正常的主机服务器。 在这种情况下,原始主机将标记为不正常。 在清除问题或更换主机之前,不会将它进一步用于部署。
- 如果不正常的主机在重新启动过程中出现问题,则在正常的主机上触发 VM 立即重启。
借助 Azure 提供的主机和 VM 监视功能,遇到主机问题的 Azure VM 可在正常的 Azure 主机上自动重启。
重要
Azure 服务修复不会重启其来宾 OS 处于内核崩溃状态的 Linux VM。 常用 Linux 版本的默认设置不会自动重启其 Linux 内核处于崩溃状态的 VM 或服务器。 默认设置预期出现内核崩溃状态的 OS 能够附加内核调试程序进行分析。 Azure 通过不自动重启具有处于此类状态的来宾 OS 的 VM 来遵守该行为。 Azure 假设这种情况极其少见。 可以覆盖默认行为,以启用 VM 重启。 若要更改默认行为,请在 /etc/sysctl.conf 中启用参数“kernel.panic”。 为此参数设置的时间以秒为单位。 常用的建议值是等待 20-30 秒,然后通过此参数触发重新启动。 有关详细信息,请参阅 sysctl.conf。
此场景中依赖的第二项功能是,重新启动 VM 后,在重启后的 VM 中运行的 HANA 服务会自动启动。 可以通过各种 HANA 服务的监视器服务设置 HANA 服务自动重启 。
在 SAP HANA 配置中添加一个冷故障转移节点可以改进这种单一 VM 场景。 在 SAP HANA 文档中,此设置称为 主机自动故障转移。 此配置在服务器硬件受限的本地部署情况下可能有意义,并且将单服务器节点指定为一组生产主机的主机自动故障转移节点。 但在 Azure 中,Azure 的基础基础结构为成功重启 VM 提供正常的目标服务器,因此部署 SAP HANA 主机自动故障转移没有意义。 由于 Azure 服务修复,没有可预见 HANA 主机自动故障转移的备用节点的参考体系结构。
Azure 中 SAP HANA 横向扩展配置的特殊情况
可在以下文档中找到基于备用节点或 HANA 系统复制的高可用性体系结构。 在 SAP HANA 横向扩展配置中未使用备用节点或 HANA 系统副本 (replica)高可用性的情况下,可以依赖于 Azure VM 的服务修复功能和 VM 再次运行后自动重启 SAP HANA 实例。
- RedHat Enterprise Linux
- SU标准版 Linux Enterprise Server
两个不同 VM 的可用性场景
若要确保特定区域中 HANA 系统的可用性,可以选择跨区域或区域中的可用性区域配置两个 VM。 为了实现此目标,可以使用灵活的规模集、可用性区域或可用性集部署选项配置 VM。 Azure 中的基本设置如下:
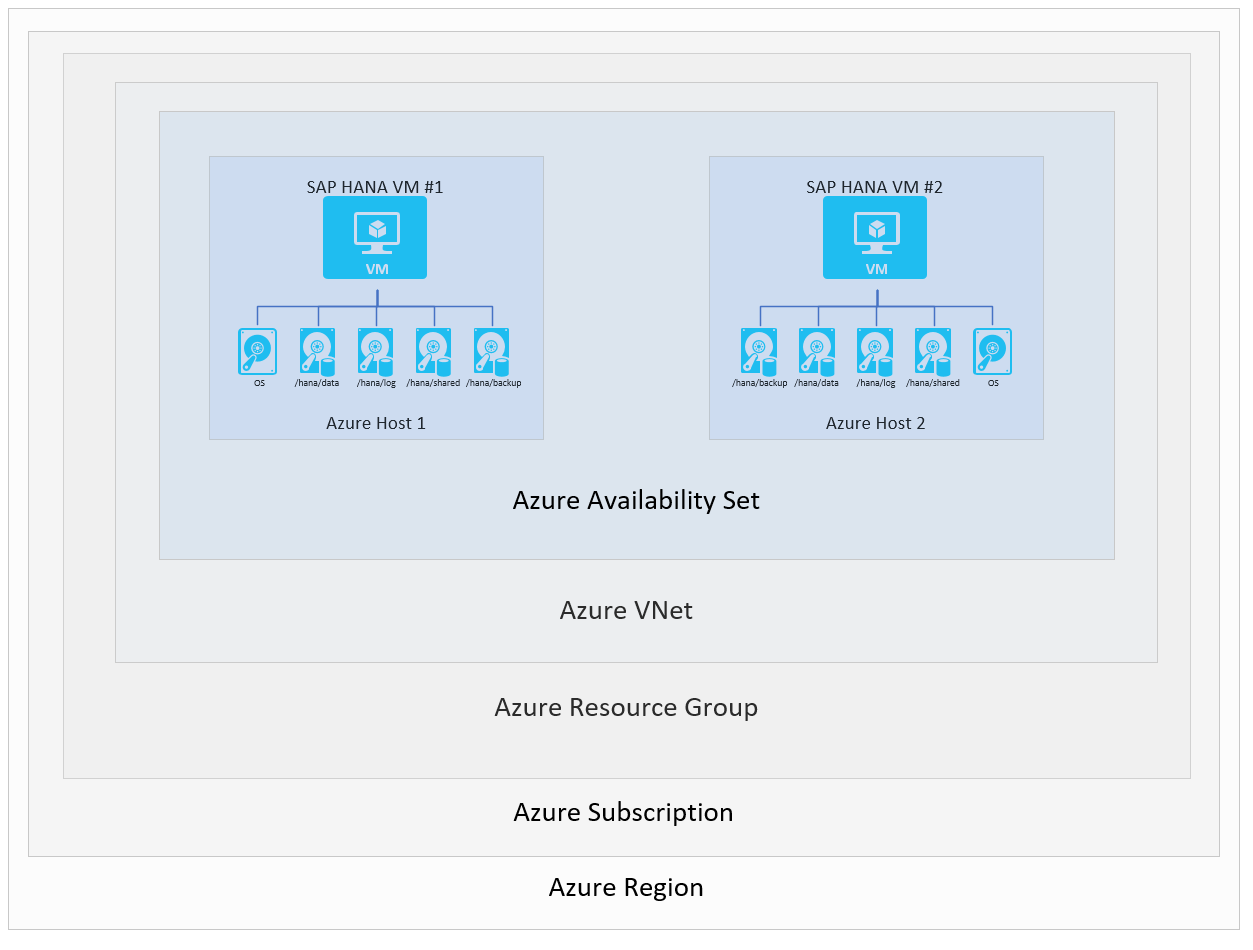
为了说明不同的 SAP HANA 可用性方案,将省略关系图中的一些层。 图形中只显示了描绘 VM、主机、可用性集和 Azure 区域的层。 Azure 虚拟网络实例、资源组和订阅不影响本部分所述的场景。
将备份复制到第二个虚拟机
最基本的设置之一是使用备份。 具体而言,可将事务日志备份从一个 VM 传送到另一个 Azure VM。 可以选择 Azure 存储类型。 在此设置中,负责编写在第一个 VM 到第二个 VM 上执行的计划备份副本的脚本。 如果需要使用第二个 VM 实例,则必须将完整、增量/差异和事务日志备份还原到所需的时间点。
体系结构如下:
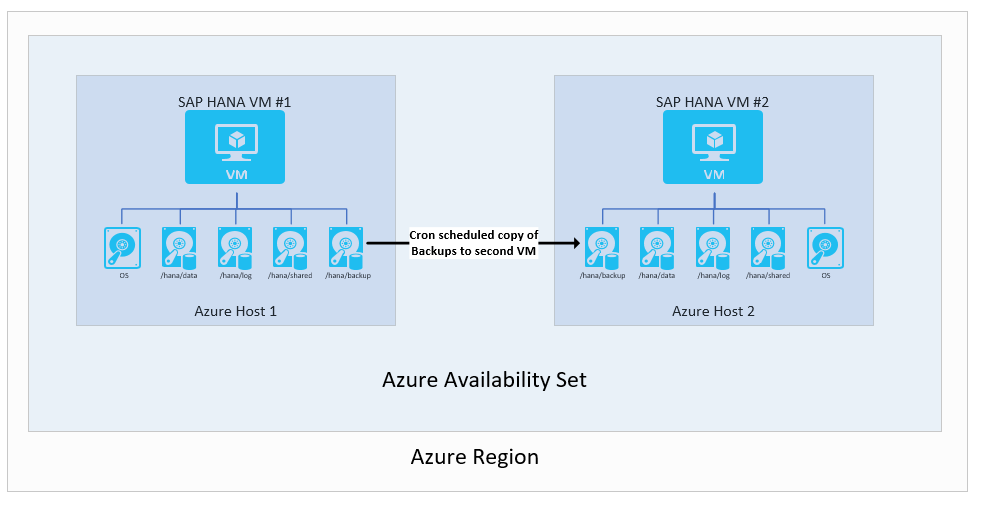
此设置不适合实现出色的恢复点目标(RPO)和恢复时间目标(RTO)时间。 RTO 甚至会受到损害,因为需要使用复制的备份来完全还原整个数据库。 但是,在主要实例上意外删除数据后,可以使用此设置进行恢复。 使用这种设置,随时可以还原到特定的时间点、提取数据,并将删除的数据导入主要实例。 因此,结合其他高可用性功能使用这种备份复制方法会很有帮助。
在复制备份期间,可以使用一个比运行 SAP HANA 实例的主要 VM 更小的 VM。 请注意,在较小的 VM 上只能附加更少的 VHD。 有关各种 VM 类型的限制信息,请参阅 Azure 中 Linux 虚拟机的大小。
在不使用自动故障转移的情况下执行 SAP HANA 系统复制
本部分所述的场景使用 SAP HANA 系统复制。 有关 SAP 文档,请参阅系统复制。 对于一个 Azure 区域中的配置来说,没有自动故障转移的方案并不常见。 不采用自动故障转移的配置虽然可以避免 Pacemaker 设置,但会强制要求手动监视和故障转移。 由于手动操作也很费时费力,因此大多数客户都依赖于 Azure 服务修复。 只是在一些不太常见的情况下,这种配置才对故障场景有所帮助。 在客户想要提高效率的情况下,这种配置也比较有利。
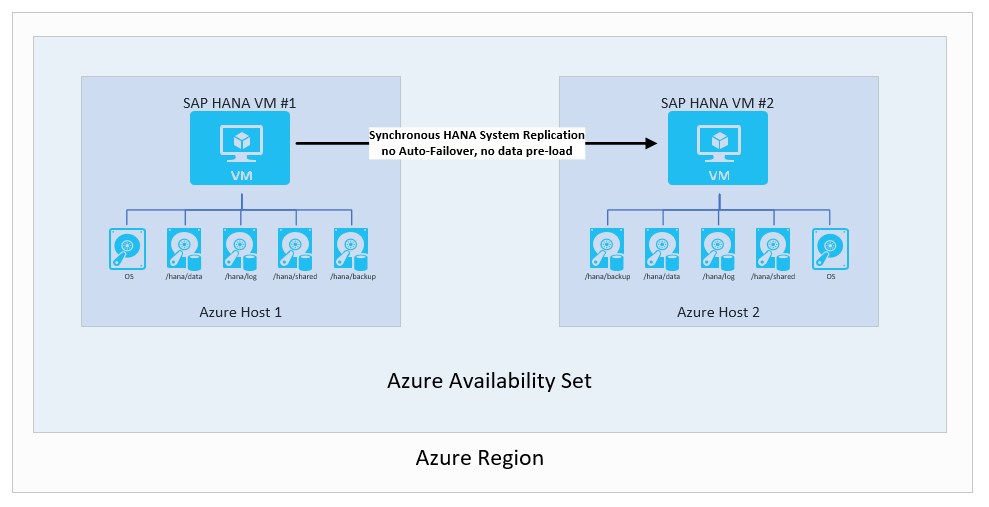
在不使用自动故障转移和数据预先加载的情况下执行 SAP HANA 系统复制
在此场景中,使用 SAP HANA 系统复制来同步移动数据,以实现 0 RPO。 另一方面,由于 RTO 足够长,因此,无需将数据故障转移或预先加载到 HANA 实例缓存。 在这种情况下,可通过执行以下操作,进一步在配置中实现更高的经济效益:
- 在第二个 VM 中运行另一个 SAP HANA 实例。 第二个 VM 中的 SAP HANA 实例充分利用虚拟机的内存。 如果故障转移到第二个 VM,则需要关闭正在运行的、包含第二个 VM 中完全加载的数据的 SAP HANA 实例,以便将复制的数据载入第二个 VM 中目标 HANA 实例的缓存。
- 对第二个 VM 使用较小的 VM。 如果发生故障转移,在手动故障转移之前,需要执行一个附加的步骤。 此步骤将 VM 大小调整为源 VM 的大小。
方案如下所示:
注意
即使不在 HANA 系统复制目标中使用数据预先加载,也至少需要 64 GB 内存。 除了 64 GB 内存以外,还需要足够的内存用于在目标实例的内存中保留行存储数据。
在不使用自动故障转移但使用数据预先加载的情况下执行 SAP HANA 系统复制
在此场景中,复制到第二个 VM 中 HANA 实例的数据会预先加载。 这样,就失去了不预先加载数据所带来的两个优势。 在这种情况下,无法在第二个 VM 上运行另一个 SAP HANA 系统。 此外,不能使用较小的 VM。 因此,客户很少实施此场景。
在使用自动故障转移的情况下执行 SAP HANA 系统复制
在一个 Azure 区域中的标准和最常见的可用性配置中,使用 HA 包运行 Linux 的两个 Azure VM 定义了故障转移群集。 HA Linux 群集基于Pacemaker将 SLES 或 RHEL 与 fencing deviceSLES 或 RHEL 配合使用的框架作为示例。
从 SAP HANA 的角度看,使用的复制模式是同步的,并且配置了自动故障转移。 在第二个 VM 中,SAP HANA 实例充当热备用节点。 备用节点从主 SAP HANA 实例接收同步的更改记录流。 应用程序在 HANA 主节点上提交事务后,HANA 主节点会一直等待确认提交到应用程序,直到 SAP HANA 辅助节点确认收到提交记录。 SAP HANA 提供两种同步复制模式。 有关这两种同步复制模式的详细信息和差异说明,请参阅 SAP 文章 SAP HANA 系统复制的复制模式。
总体配置如下:
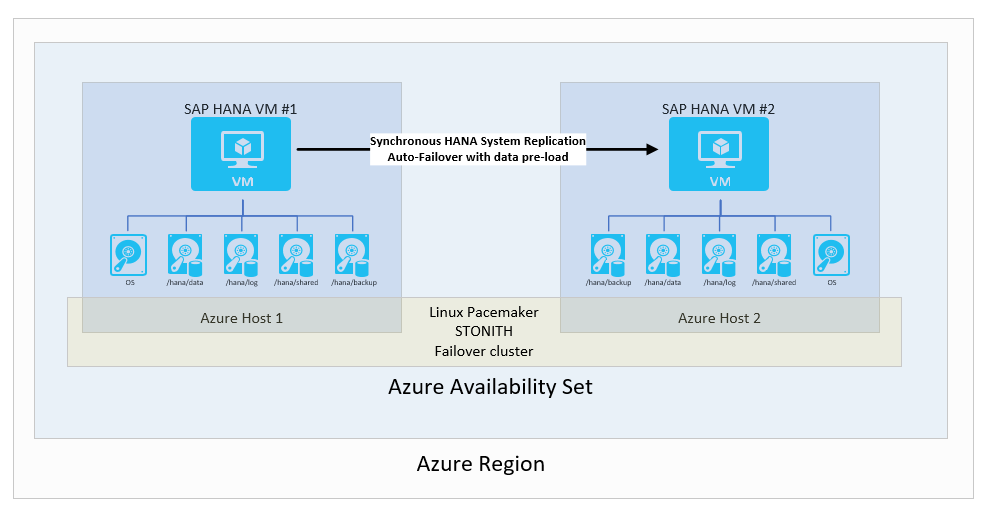
可以选择此解决方案,因为它使你能够实现 RPO=0 和低 RTO。 配置 SAP HANA 客户端连接,使 SAP HANA 客户端能够使用虚拟 IP 地址连接到 HANA 系统复制配置。 故障转移到辅助节点时,此类配置可以消除重新配置应用程序的需要。 在此场景中,主 VM 和辅助 VM 的 Azure VM SKU 必须相同。
后续步骤
有关在 Azure 中设置这些配置的分步指导,请参阅:
有关跨 Azure 区域的 SAP HANA 可用性的详细信息,请参阅: