云本机数据模式

正如我们在本书中所看到的,云原生方法会更改设计、部署和管理应用程序的方式。 它还会更改管理和存储数据的方式。
图 5-1 对比了这些差异。
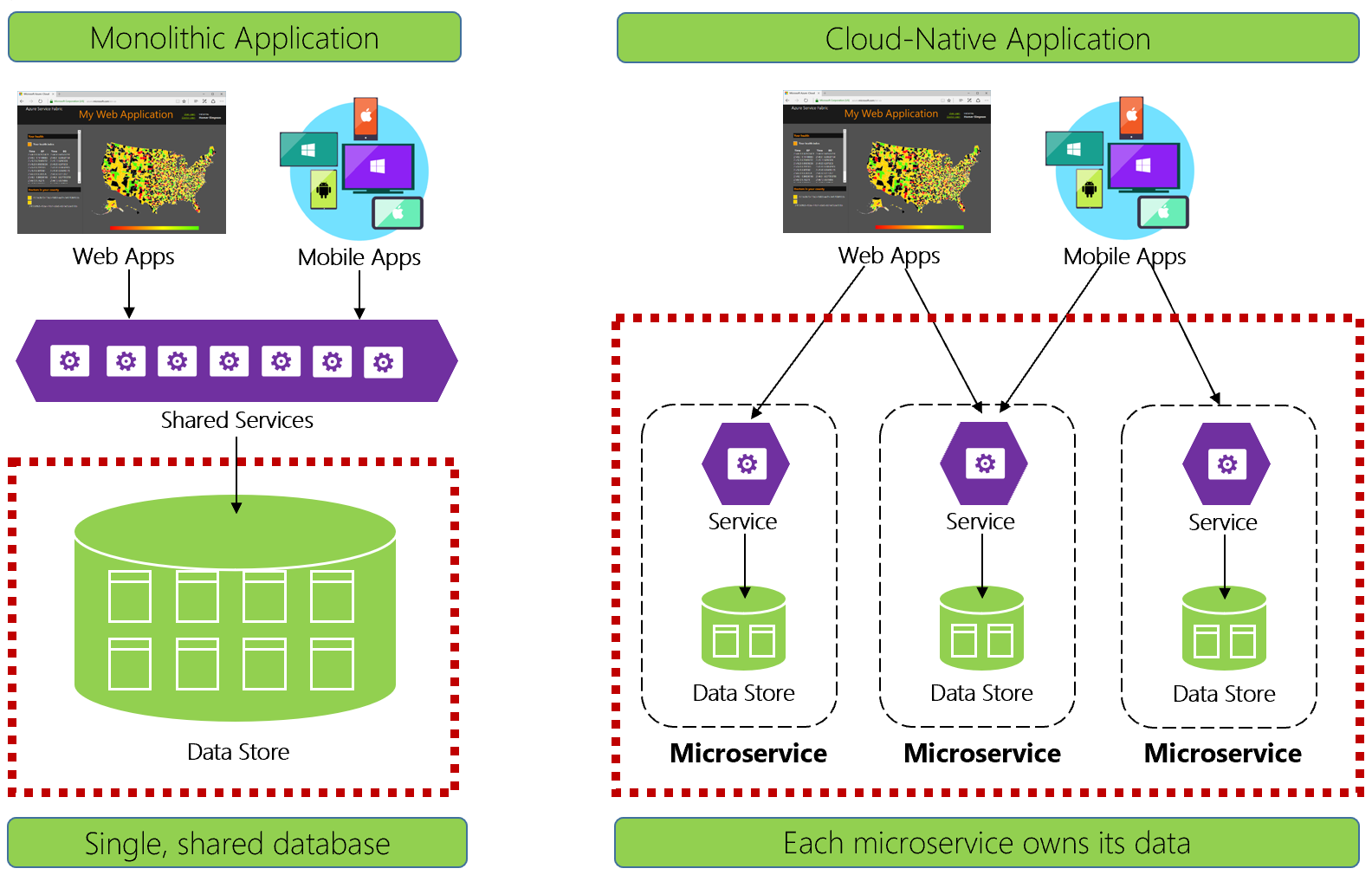
图 5-1。 云原生应用程序中的数据管理
经验丰富的开发人员可以轻松识别图 5-1 左侧的体系结构。 在此整体式应用程序中,业务服务组件共同并置于共享服务层,共享来自单个关系数据库的数据。
从许多方面来说,单一数据库简化了数据管理。 跨多个表查询数据变得非常简单。 对数据所做的更改会一起更新,或者全部回退。 ACID 事务保证了强一致性和即时一致性。
我们采用不同的方法对云原生应用程序进行设计。 在图 5-1 的右侧,请留意业务功能是如何分为小型、独立的微服务的。 每个微服务封装特定的业务功能及其自己的数据。 整体式数据库分解成具有许多较小数据库的分布式数据模型,每个数据库都与一个微服务对齐。 当一切明了时,我们得到了一个设计,该设计为每个微服务公开一个数据库。
每个微服务一个数据库,为什么?
每个微服务一个这样的数据库具有许多优势,尤其是对于必须快速发展并支持大规模缩放的系统。 使用此模型...
- 域数据封装在服务中
- 数据架构可以在不直接影响其他服务的情况下发展
- 每个数据存储可以独立缩放
- 某个服务中的数据存储故障不会直接影响其他服务
隔离数据还使每个微服务能够实现最适合其工作负载、存储需求和读/写模式的数据存储类型。 选项包括关系数据存储、文档数据存储、键值数据存储,甚至基于图形的数据存储。
图 5-2 显示了云原生系统中多语言持久化的原则。
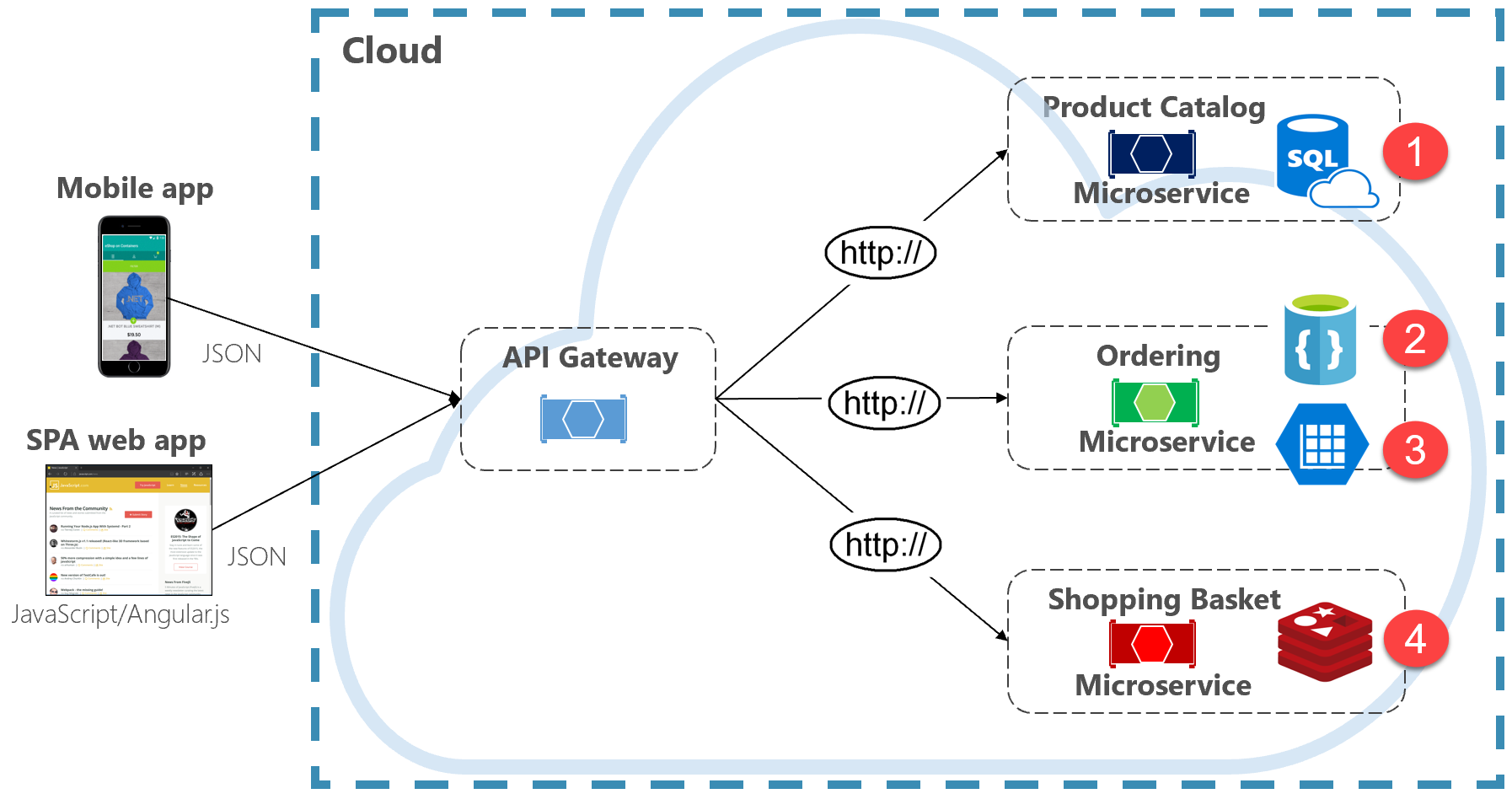
图 5-2。 Polyglot 数据持久性
请注意上图中每个微服务如何支持不同类型的数据存储。
- 产品目录微服务使用关系数据库来容纳其基础数据的丰富关系结构。
- 购物车微服务使用支持其简单键值数据存储的分布式缓存。
- 排序微服务使用 NoSql 文档数据库进行写入操作,同时使用高度非规范化的键/值存储来容纳大量读取操作。
尽管关系数据库仍与具有复杂数据的微服务相关,但 NoSQL 数据库已相当受欢迎。 它们提供大规模缩放和高可用性。 它们的无架构特性使开发人员能够离开类型化数据类和 ORM 的体系结构,这些体系结构使更改成本高昂且耗时。 本章稍后将介绍 NoSQL 数据库。
虽然将数据封装到单独的微服务可以提高敏捷性、性能和可伸缩性,但它也带来了难题。 下一部分将讨论这些难题以及可帮助克服这些难题的模式和做法。
跨服务查询
虽然微服务是独立的,并且专注于特定的功能能力(如库存、发货或订购),但它们通常需要与其他微服务集成。 集成通常涉及到一个微服务查询另一个微服务的数据。 图 5-3 显示了方案。
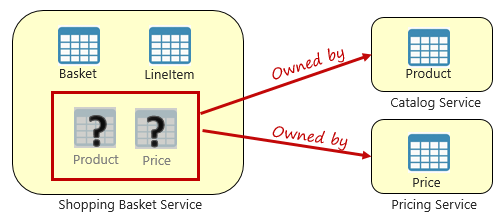
图 5-3。 跨微服务查询
在上图中,我们看到了将一个项添加到用户的购物篮中的购物篮微服务。 虽然该微服务的数据存储包含购物篮和行项数据,但它不会维护产品或定价数据。 而这些数据项归目录和定价微服务所有。 这一方面存在一个问题。 当购物篮微服务数据库中没有产品或定价数据时,如何向用户的购物篮添加产品?
第 4 章中讨论的一个选项是直接将 HTTP 从购物篮调用到目录和定价微服务。 但是,在第 4 章中,我们称同步 HTTP 调用将微服务耦合在一起,从而降低微服务的自主性并降低其体系结构优势。
还可以为每个服务实现具有单独的入站和出站队列的请求-答复模式。 但是,此模式很复杂,需要管道来关联请求和响应消息。 尽管它确实分离了后端微服务调用,但调用服务仍必须同步等待调用完成。 网络拥塞、暂时性故障或过载的微服务可能会导致长时间运行甚至失败的操作。
而删除跨服务依赖项的一种广为接受的模式是具体化视图模式,如图 5-4 所示。
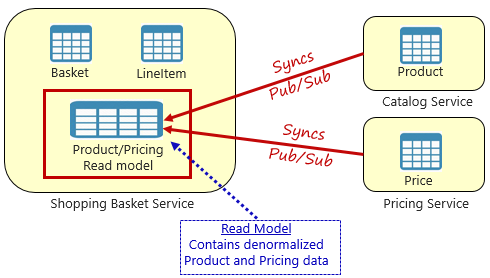
图 5-4。 具体化视图模式
使用此模式,可以在购物篮服务中放置一个本地数据表(称为“读取模型”)。 此表包含产品和定价微服务所需的数据的非规范化副本。 将数据直接复制到购物篮微服务中,无需进行昂贵的跨服务调用。 使用服务的本地数据,可以减少服务的响应时间并提高可靠性。 此外,拥有自己的数据副本可增强购物篮服务的复原能力。 如果目录服务不可用,它不会直接影响购物篮服务。 购物篮可以继续使用自己的商店的数据。
该方法的问题是,现在系统中有重复数据。 但是,从战略上复制云原生系统中的数据是一种惯例,不被视为反模式或错误做法。 请记住,只有一个服务可以拥有数据集并对其拥有权限。 更新记录系统时,需要同步读取模型。 同步通常使用发布/订阅模式通过异步消息传送实现,如图 5.4 所示。
分布式事务
虽然跨微服务查询数据很困难,但跨多个微服务实现事务甚至更复杂。 不要轻视在不同微服务中跨独立数据源保持数据一致性的内在挑战。 云原生应用程序中缺少分布式事务意味着必须以编程方式管理分布式事务。 从即时一致性进入最终一致性。
图 5-5 展示了该问题。
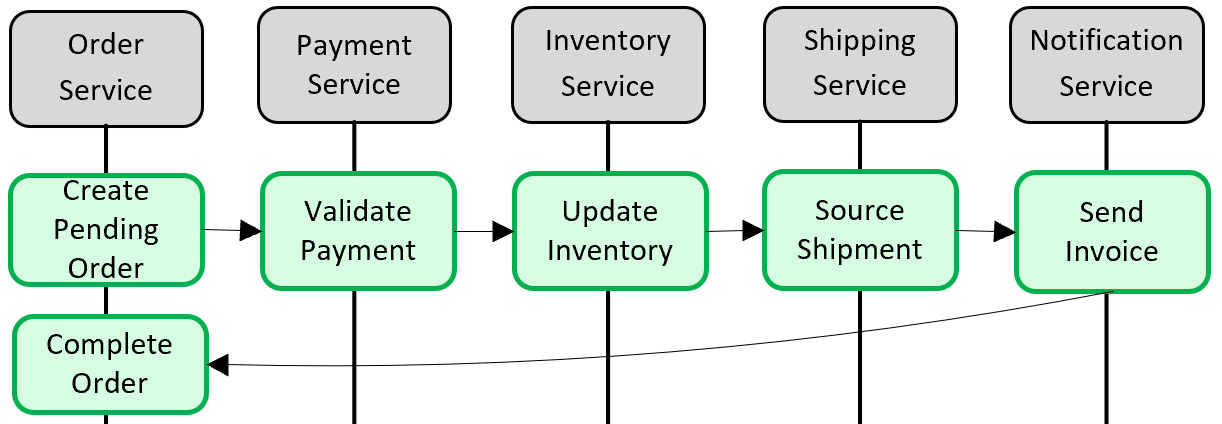
图 5-5。 跨微服务实现事务
在上图中,五个独立的微服务参与创建订单的分布式事务。 每个微服务维护自己的数据存储,并针对其存储实现本地事务。 若要创建订单,每个单独的微服务的本地事务必须成功,否则所有微服务都必须中止并回退操作。 尽管每个微服务中都提供内置事务支持,但不支持跨所有五个服务以保持数据一致的分布式事务。
而必须以编程方式构造此分布式事务。
Saga 模式是添加分布式事务支持的常用模式。 通过以编程方式将本地事务组合在一起并按顺序调用每个本地事务来实现它。 如果任何本地事务失败,Saga 将中止操作并调用一组补偿事务。 补偿事务撤消上述本地事务所做的更改并还原数据一致性。 图 5-6 显示了具有 Saga 模式的失败事务。
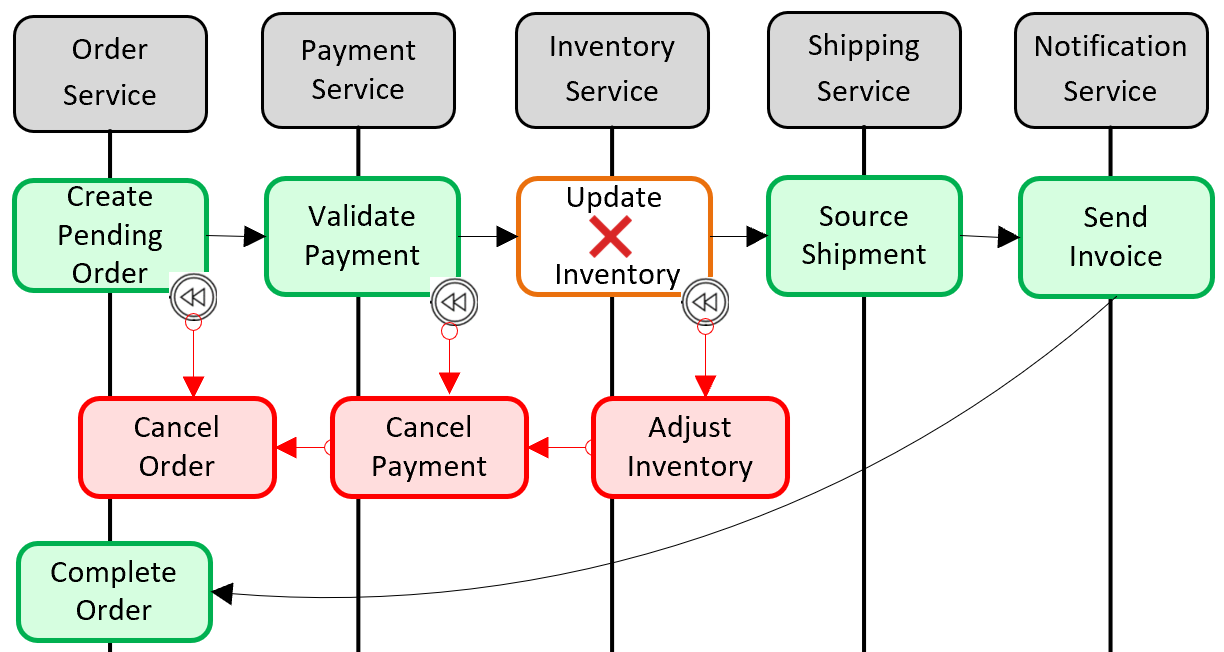
图 5-6。 回滚事务
在上图中,更新库存操作已在库存微服务中失败。 Saga 调用一组补偿事务(红色)以调整库存计数、取消付款和订单,并将每个微服务的数据返回到一致状态。
Saga 模式通常被序列化为一系列相关事件,或安排为一组相关命令。 在第 4 章中,我们讨论了服务聚合器模式,该模式是协调 saga 实现的基础。 我们还讨论了事件以及 Azure 服务总线和 Azure 事件网格主题,它们将成为精心设计的 saga 实现的基础。
大容量数据
大型云原生应用程序通常支持大容量数据要求。 在这些方案中,传统的数据存储技术可能会导致瓶颈。 对于大规模部署的复杂系统,命令和查询责任分离 (CQRS) 以及事件溯源可以提升应用程序性能。
CQRS
CQRS 是一种体系结构模式,可帮助最大程度地提高性能、可伸缩性和安全性。 该模式将读取数据的操作与写入数据的操作分开。
对于普通方案,读取操作和写入操作都使用相同的实体模型和数据存储库对象。
但是,大容量数据方案可以从用于读取和写入的单独模型和数据表中受益。 为了提高性能,读取操作可以针对高度非规范化表示的数据进行查询,以避免成本高昂的重复表联接和表锁定。 写入操作被称为命令,它会根据完全规范化表示的数据进行更新,以保证一致性。 然后,你需要实现一种机制来使这两种表示形式保持同步。通常,每当修改写入表时,它都会发布一个将修改复制到读取表的事件。
图 5-7 显示了 CQRS 模式的实现。
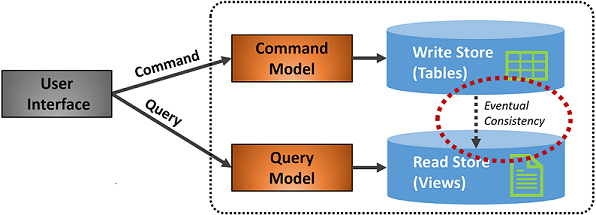
图 5-7。 CQRS 实现
在上图中,实现了单独的命令和查询模型。 将每个数据写入操作保存到写入存储,然后传播到读取存储。 请密切注意数据传播过程如何在最终一致性原则下运行。 读取模型最终会与写入模型同步,但该过程可能有一些延迟。 我们将在下一部分讨论最终一致性。
这种分隔使读取和写入能够独立缩放。 读取操作使用针对查询进行优化的架构,而写入操作使用针对更新进行优化的架构。 读取查询针对非规范化数据,而复杂的业务逻辑可以应用于写入模型。 可能会对写入操作施加比公开读取操作更严格的安全性。
实现 CQRS 可以提高云原生服务的应用程序性能。 但是,它确实会导致更复杂的设计。 谨慎而有策略地将该原则应用到云原生应用程序将从中受益的部分。 有关 CQRS 的详细信息,请参阅 Microsoft 书籍 .NET 微服务:容器化 .NET 应用程序的体系结构。
事件溯源
优化大容量数据方案的另一种方法涉及事件溯源。
系统通常会存储数据实体的当前状态。 例如,如果用户更改其电话号码,则会使用新号码更新客户记录。 我们始终知道数据实体的当前状态,但每次更新都会覆盖以前的状态。
在大多数情况下,该模型可以正常工作。 但是,在大容量系统中,事务锁定和频繁更新操作中的开销可能会影响数据库性能、响应能力并限制可伸缩性。
事件溯源采用另一种方法来捕获数据。 影响数据的每个操作都会持久保存在事件存储中。 我们不会更新数据记录的状态,而是将每个更改追加到过去事件的顺序列表(类似于会计账本)。 事件存储成为数据的记录系统。 它用于传播微服务边界上下文中的各种具体化视图。 图 5.8 展示了该模式。
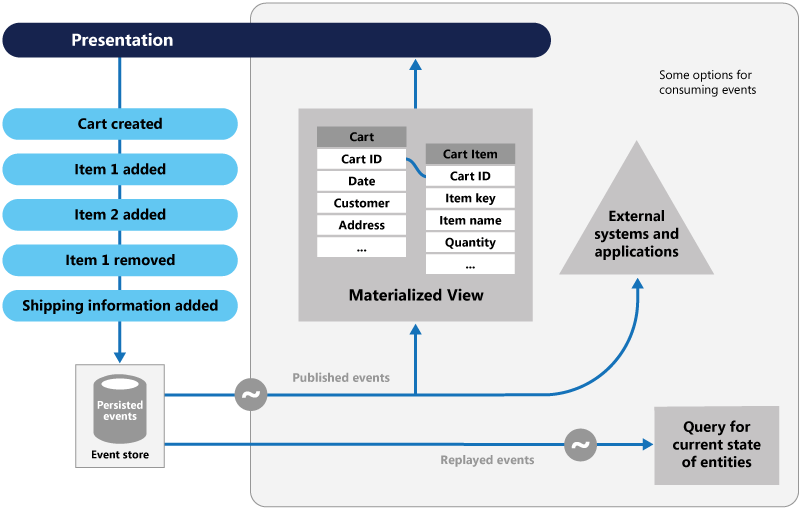
图 5-8。 事件溯源
在上图中,请注意将用户购物车的每个条目(蓝色)添加到基础事件存储中。 在相邻的具体化视图中,系统通过重播所有与每个购物车关联的事件来预测当前状态。 然后,此视图或读取模型将重新公开到 UI。 事件还可以与外部系统和应用程序集成或查询,以确定实体的当前状态。 使用这种方法可以维护历史记录。 不仅知道实体的当前状态,还知道如何达到此状态。
从机械的角度来讲,事件溯源简化了写入模型。 没有更新或删除。 将每个数据条目追加为不可变事件可最大程度地减少与关系数据库关联的争用、锁定和并发冲突。 使用具体化视图模式生成读取模型,使你能够将视图与写入模型分离,并选择最佳数据存储以优化应用程序 UI 的需求。
对于此模式,请考虑直接支持事件溯源的数据存储。 Azure Cosmos DB、MongoDB、Cassandra、CouchDB 和 RavenDB 是不错的候选项。
与所有模式和技术一样,在需要时有战略地进行实现。 虽然事件溯源可以提高性能和可伸缩性,但代价是复杂性和学习曲线。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈