什么是 ML.NET 以及它如何工作?
ML.NET 使你能够在联机或脱机场景中将机器学习添加到 .NET 应用程序中。 借助此功能,可以使用应用程序的可用数据进行自动预测。 机器学习应用程序利用数据中的模式来进行预测,而不需要进行显式编程。
ML.NET 的核心是机器学习模型 。 该模型指定将输入数据转换为预测所需的步骤。 借助 ML.NET,可以通过指定算法来训练自定义模型,也可以导入预训练的 TensorFlow 和 ONNX 模型。
拥有模型后,可以将其添加到应用程序中进行预测。
ML.NET 在使用 .NET 的 Windows、Linux 和 macOS 上或在使用 .NET Framework 的 Windows 上运行。 所有平台均支持 64 位。 Windows 支持 32 位,TensorFlow、LightGBM 和 ONNX 相关功能除外。
下表显示了可使用 ML.NET 进行的预测类型示例。
| 预测类型 | 示例 |
|---|---|
| 分类/类别 | 自动将客户反馈划分为正面和负面类别。 |
| 回归/预测连续值 | 根据面积和位置预测房屋价格。 |
| 异常检测 | 检测欺诈性银行交易。 |
| 建议 | 根据在线购物者之前的购买情况向其建议可能想要购买的产品。 |
| 时序/顺序数据 | 预测天气或产品销售额。 |
| 图像分类 | 对医学影像中的病状进行分类。 |
| 文本分类 | 根据文档内容对文档进行分类。 |
| 句子相似性 | 测量两个句子的相似程度。 |
Hello ML.NET World
以下代码片段中的代码演示了最简单的 ML.NET 应用程序。 此示例构造线性回归模型,使用房屋大小和价格数据预测房屋价格。
using System;
using Microsoft.ML;
using Microsoft.ML.Data;
class Program
{
public class HouseData
{
public float Size { get; set; }
public float Price { get; set; }
}
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
static void Main(string[] args)
{
MLContext mlContext = new MLContext();
// 1. Import or create training data
HouseData[] houseData = {
new HouseData() { Size = 1.1F, Price = 1.2F },
new HouseData() { Size = 1.9F, Price = 2.3F },
new HouseData() { Size = 2.8F, Price = 3.0F },
new HouseData() { Size = 3.4F, Price = 3.7F } };
IDataView trainingData = mlContext.Data.LoadFromEnumerable(houseData);
// 2. Specify data preparation and model training pipeline
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
// 3. Train model
var model = pipeline.Fit(trainingData);
// 4. Make a prediction
var size = new HouseData() { Size = 2.5F };
var price = mlContext.Model.CreatePredictionEngine<HouseData, Prediction>(model).Predict(size);
Console.WriteLine($"Predicted price for size: {size.Size*1000} sq ft= {price.Price*100:C}k");
// Predicted price for size: 2500 sq ft= $261.98k
}
}
代码工作流
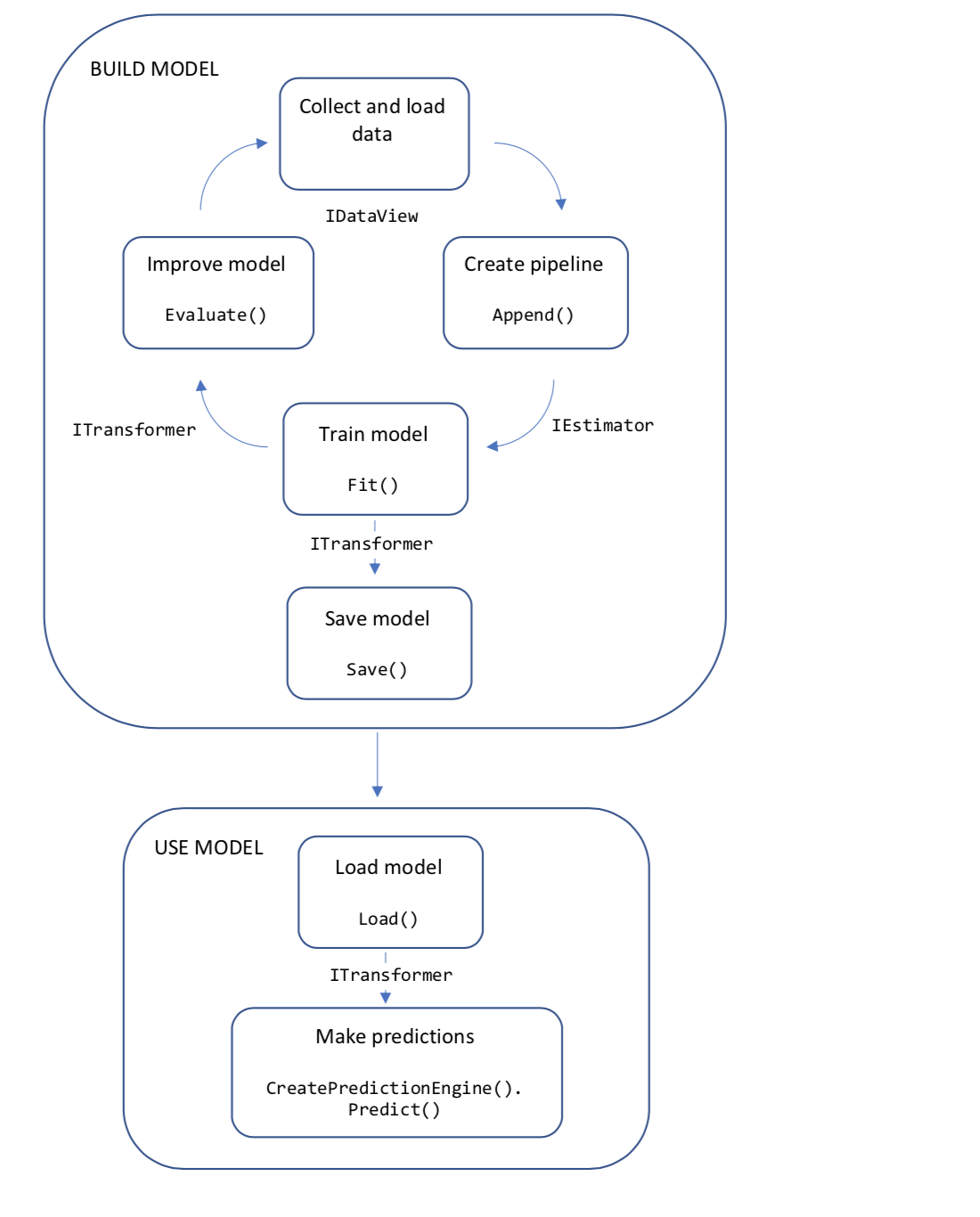
以下关系图表示应用程序代码结构,以及模型开发的迭代过程:
- 将训练数据收集并加载到 IDataView 对象中
- 指定操作的管道,以提取特征并应用机器学习算法
- 通过在管道上调用 Fit() 来训练模型
- 评估模型并通过迭代进行改进
- 将模型保存为二进制格式,以便在应用程序中使用
- 将模型加载回 ITransformer 对象
- 通过调用 CreatePredictionEngine.Predict() 进行预测
让我们更深入地探讨这些概念。
机器学习模型
ML.NET 模型是一个对象,它包含为了获得预测输出而要对输入数据执行的转换。
Basic
最基本的模型是二维线性回归,其中一个连续数量与另一个连续数量成比例关系,如上述房价示例所示。

模型很简单:$Price = b + Size * w$。 参数 $b$ 和 $w$ 通过根据一组 (size, price) 对拟合一根直线来进行估算。 用于查找模型参数的数据称为训练数据。 机器学习模型的输入称为特征。 在此示例中,$Size$ 是唯一的特征。 用于训练机器学习模型的真值称为标签。 此处训练数据集中的 $Price$ 值是标签。
更复杂
更复杂的模型使用事务文本描述将金融事务分类为类别。
通过删除冗余的字词和字符,以及对字词和字符组合进行计数,每个事务描述都被分解为一组特征。 该特征集用于基于训练数据中的类别集训练线性模型。 新描述与训练集中的描述越相似,它就越有可能被分配到同一类别。

房屋价格模型和文本分类模型均为线性模型。 根据数据的性质和要解决的问题,还可以使用决策树模型、广义加性模型和其他模型。 可以在任务中找到有关模型的详细信息。
数据准备
在大多数情况下,可用的数据不适合直接用于训练机器学习模型。 需要准备或预处理原始数据,然后才能将其用于查找模型的参数。 数据可能需要从字符串值转换为数字表示形式。 输入数据中可能会包含冗余信息。 可能需要缩小或放大输入数据的维度。 数据可能需要进行规范化或缩放。
ML.NET 教程讲解用于特定机器学习任务的文本、图像、数字和时序数据的不同数据处理管道。
如何准备数据展示了如何更广泛地应用数据准备。
可以在“资源”部分找到所有可用转换的附录。
模型评估
训练模型后,如何了解其进行未来预测的表现如何? 借助 ML.NET,可以根据一些新的测试数据评估模型。
每种类型的机器学习任务都具有用于根据测试数据集评估模型的准确性和精确性的指标。
对于我们的房屋价格示例,我们使用了回归任务。 若要评估模型,请将以下代码添加到原始示例中。
HouseData[] testHouseData =
{
new HouseData() { Size = 1.1F, Price = 0.98F },
new HouseData() { Size = 1.9F, Price = 2.1F },
new HouseData() { Size = 2.8F, Price = 2.9F },
new HouseData() { Size = 3.4F, Price = 3.6F }
};
var testHouseDataView = mlContext.Data.LoadFromEnumerable(testHouseData);
var testPriceDataView = model.Transform(testHouseDataView);
var metrics = mlContext.Regression.Evaluate(testPriceDataView, labelColumnName: "Price");
Console.WriteLine($"R^2: {metrics.RSquared:0.##}");
Console.WriteLine($"RMS error: {metrics.RootMeanSquaredError:0.##}");
// R^2: 0.96
// RMS error: 0.19
通过评估指标可得知错误率相当低,且预测输出和测试输出之间的相关性很高。 这很简单! 在实际示例中,需要进行更多调整才能获得良好的模型指标。
ML.NET 体系结构
本部分介绍 ML.NET 的体系结构模式。 如果你是一位经验丰富的 .NET 开发人员,则你对其中一些模式可能已经很熟悉,但对有些模式则不那么熟悉。
ML.NET 应用程序从 MLContext 对象开始。 此单一实例对象包含目录。 目录是用于数据加载和保存、转换、训练程序和模型操作组件的工厂。 每个目录对象都具有创建不同类型的组件的方法。
| 任务 | 目录 |
|---|---|
| 数据加载和保存 | DataOperationsCatalog |
| 数据准备 | TransformsCatalog |
| 二元分类 | BinaryClassificationCatalog |
| 多类分类 | MulticlassClassificationCatalog |
| 异常情况检测 | AnomalyDetectionCatalog |
| 聚类分析 | ClusteringCatalog |
| 预测 | ForecastingCatalog |
| 排名 | RankingCatalog |
| 回归测试 | RegressionCatalog |
| 建议 | RecommendationCatalog |
| 时序 | TimeSeriesCatalog |
| 模型使用 | ModelOperationsCatalog |
可以导航到上述各个类别的创建方法。 使用 Visual Studio 时,目录通过 IntelliSense 显示。
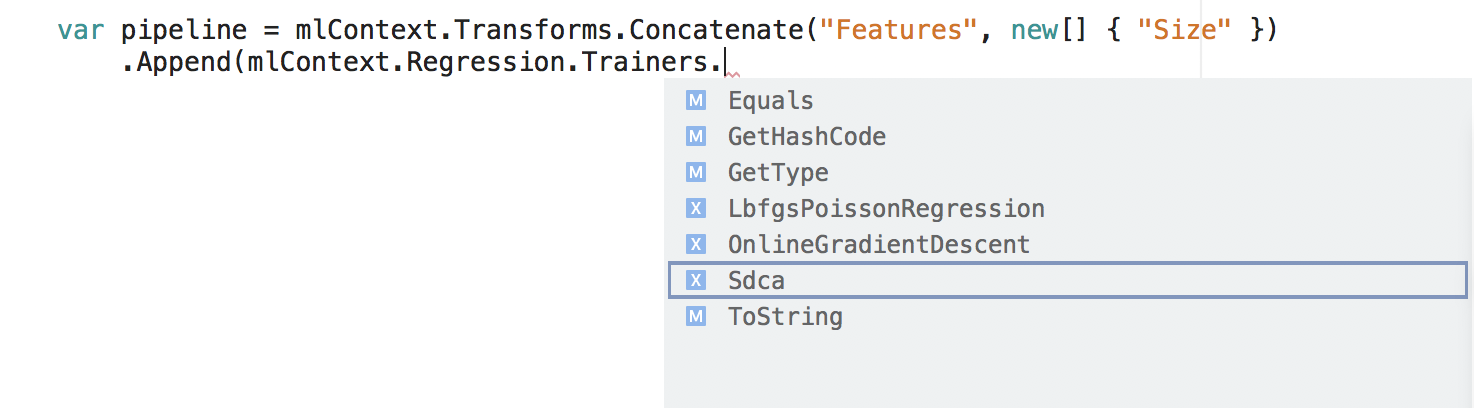
生成管道
每个目录中都有一组可用于创建训练管道的扩展方法。
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
.Append(mlContext.Regression.Trainers.Sdca(labelColumnName: "Price", maximumNumberOfIterations: 100));
在代码片段中,Concatenate 和 Sdca 均为目录中的方法。 它们各创建一个追加到管道的 IEstimator 对象。
此时,对象已经创建,但是还没有执行。
定型模型
在管道中创建对象后,即可使用数据来训练模型。
var model = pipeline.Fit(trainingData);
调用 Fit() 使用输入训练数据来估算模型的参数。 这称为训练模型。 请记住,上述线性回归模型有两个模型参数:偏差和权重。 在 Fit() 调用后,参数的值是已知的。 (大部分模型拥有的参数比这多得多。)
可以在如何训练模型中了解有关模型训练的详细信息。
生成的模型对象实现 ITransformer 接口。 也就是说,模型将输入数据转换为预测。
IDataView predictions = model.Transform(inputData);
使用模型
可以将输入数据批量转换为预测,也可以一次转换一个输入。 房屋价格示例执行了这两种操作:为了评估模型执行了批量转换,为了进行新预测执行了单次转换。 让我们进行单个预测。
var size = new HouseData() { Size = 2.5F };
var predEngine = mlContext.CreatePredictionEngine<HouseData, Prediction>(model);
var price = predEngine.Predict(size);
CreatePredictionEngine() 方法接受一个输入类和一个输出类。 字段名称或代码属性确定模型训练和预测期间使用的数据列的名称。 有关详细信息,请参阅使用经过训练的模型进行预测。
数据模型和架构
ML.NET 机器学习管道的核心是 DataView 对象。
管道中的每个转换都有一个输入架构(转换期望在其输入中看到的数据名称、类型和大小);以及一个输出架构(转换在转换后生成的数据名称、类型和大小)。
如果管道中一个转换的输出架构与下一个转换的输入架构不匹配,ML.NET 将引发异常。
数据视图对象具有列和行。 每个列都有名称、类型和长度。 例如,房屋价格示例中的输入列为“大小” 和“价格” 。 它们都是类型,且它们是标量数量而不是向量数量。

所有 ML.NET 算法都在寻找属于向量的输入列。 默认情况下,此向量列称为特征。 这就是为什么房屋价格示例将“面积”列连接到名为“特征”的新列。
var pipeline = mlContext.Transforms.Concatenate("Features", new[] { "Size" })
所有算法在执行预测后还会创建新列。 这些新列的固定名称取决于机器学习算法的类型。 对于回归任务,其中一个新列称为“分数”,如价格属性属性中所示。
public class Prediction
{
[ColumnName("Score")]
public float Price { get; set; }
}
可以在机器学习任务指南中找到有关不同机器学习任务的输出列的详细信息。
DataView 对象的一个重要属性是它们被惰性求值。 数据视图仅在模型训练和评估以及数据预测期间加载及运行。 在编写和测试 ML.NET 应用程序时,可以使用 Visual Studio 调试程序通过调用 Preview 方法来浏览任何数据视图对象。
var debug = testPriceDataView.Preview();
可以在调试程序中查看 debug 变量并检查其内容。 不要在生产代码中使用 Preview 方法,因为它会大幅降低性能。
模型部署
在实际应用程序中,模型训练和评估代码将与预测分离。 事实上,这两项活动通常由单独的团队执行。 模型开发团队可以保存模型以便用于预测应用程序。
mlContext.Model.Save(model, trainingData.Schema,"model.zip");
后续步骤
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈