教程:在 ML.NET 中使用 ONNX 检测对象
了解如何在 ML.NET 中使用预训练的 ONNX 模型来检测图像中的对象。
从头开始训练对象检测模型需要设置数百万个参数、大量已标记的训练数据和海量计算资源(数百个 GPU 小时)。 使用预训练的模型可让你快速完成训练过程。
在本教程中,你将了解:
- 了解问题
- 了解什么是 ONNX 以及它如何与 ML.NET 配合使用
- 了解模型
- 重用预训练的模型
- 使用已加载模型检测对象
先决条件
- Visual Studio 2022。
- Microsoft.ML Nuget 包
- Microsoft.ML.ImageAnalytics NuGet 包
- Microsoft.ML.OnnxTransformer NuGet 包
- Tiny YOLOv2 预训练的模型
- Netron(可选)
ONNX 对象检测示例概述
此示例创建一个 .NET 核心控制台应用程序,该应用程序使用预训练的深度学习 ONNX 模型检测图像中的对象。 此示例的代码可以在 GitHub 上的 dotnet/machinelearning-samples 存储库找到。
什么是对象检测?
对象检测是计算机视觉问题。 虽然与图像分类密切相关,但是对象检测以更精细的比例执行图像分类。 对象检测用于定位图像中的实体并对其进行分类。 物体检测模型通常使用深度学习和神经网络进行训练。 有关详细信息,请参阅深度学习与机器学习。
如果图像包含多个不同类型的对象,请使用对象检测。

对象检测的一些用例包括:
- 自动驾驶汽车
- 机器人
- 人脸检测
- 工作区安全性
- 对象计数
- 活动识别
选择深度学习模型
深度学习是机器学习的一部分。 若要训练深度学习模型,则需要大量的数据。 数据中的模式用一系列层表示。 数据中的关系被编码为包含权重的层之间的连接。 权重越大,关系越强。 总的来说,这一系列的层和连接被称为人工神经网络。 网络中的层越多,它就越“深”,使其成为一个深层的神经网络。
神经网络有多种类型,最常见的是多层感知器 (MLP)、卷积神经网络 (CNN) 和循环神经网络 (RNN)。 最基本的是 MLP,可将一组输入映射到一组输出。 如果数据没有空间或时间组件,建议使用这种神经网络。 CNN 利用卷积层来处理数据中包含的空间信息。 图像处理就是 CNN 的一个很好的用例,它检测图像区域中是否存在特征(例如,图像中心是否有鼻子?) 最后,RNN 允许将状态或内存的持久性用作输入。 RNN 用于时间序列分析,其中事件的顺序排序和上下文很重要。
了解模型
对象检测是图像处理任务。 因此,训练解决该问题的大多数深度学习模型都是 CNN。 本教程中使用的模型是 Tiny YOLOv2 模型,这是该文件中描述的 YOLOv2 模型的一个更紧凑版本:“YOLO9000:更好、更快、更强”,作者:Redmon 和 Farhadi。 Tiny YOLOv2 在 Pascal VOC 数据集上进行训练,共包含 15 层,可预测 20 种不同类别的对象。 由于 Tiny YOLOv2 是原始 YOLOv2 模型的精简版本,因此需要在速度和精度之间进行权衡。 构成模型的不同层可以使用 Neutron 等工具进行可视化。 检查模型将在构成神经网络的所有层之间生成连接映射,其中每个层都将包含层名称以及各自输入/输出的维度。 用于描述模型输入和输出的数据结构称为张量。 可以将张量视为以 N 维存储数据的容器。 对于 Tiny YOLOv2,输入层名称为 image,它需要一个维度为 3 x 416 x 416 的张量。 输出层名称为 grid,且生成维度为 125 x 13 x 13 的输出张量。
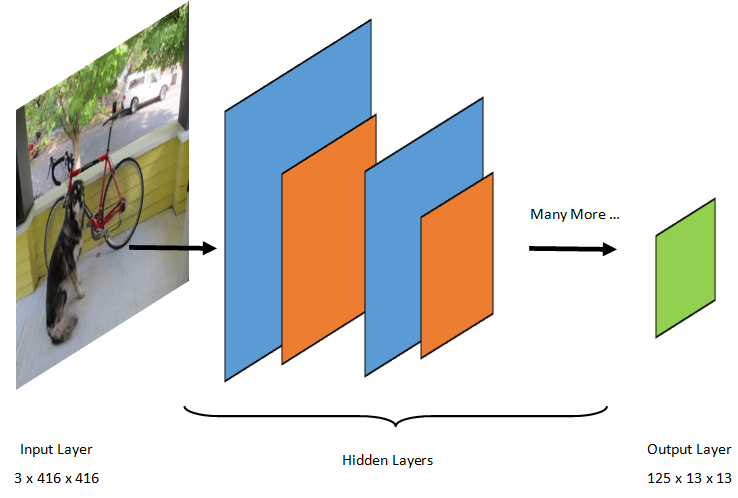
YOLO 模型采用图像 3(RGB) x 416px x 416px。 模型接受此输入,并将其传递到不同的层以生成输出。 输出将输入图像划分为一个 13 x 13 网格,网格中的每个单元格由 125 值组成。
什么是 ONNX 模型?
开放神经网络交换 (ONNX) 是 AI 模型的开放源代码格式。 ONNX 支持框架之间的互操作性。 这意味着,你可以在许多常见的机器学习框架(如 pytorch)中训练模型,将其转换为 ONNX 格式,并在其他框架(如 ML.NET)中使用 ONNX 模型。 有关详细信息,请参阅 ONNX 网站。

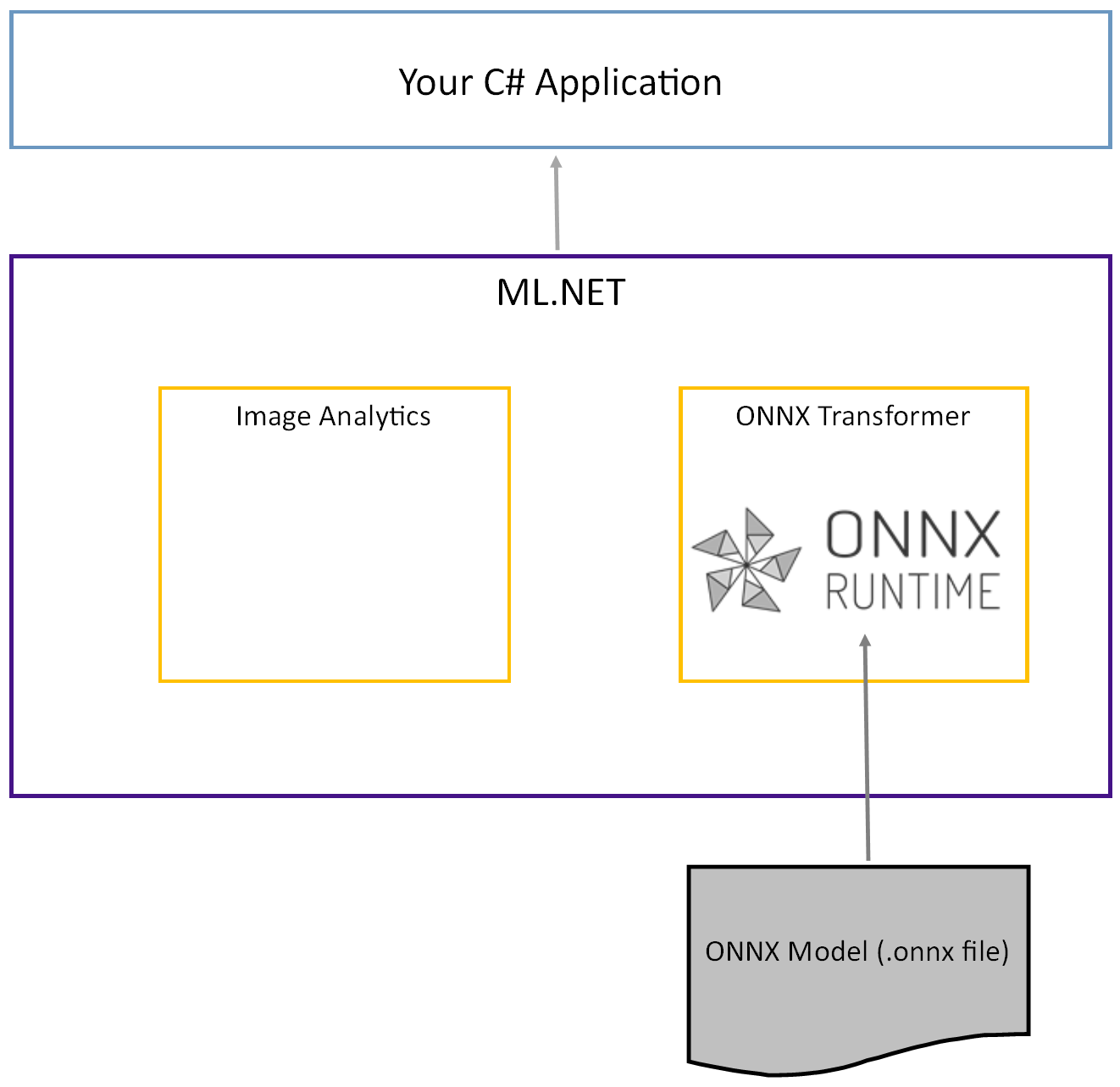
预训练的 Tiny YOLOv2 模型以 ONNX 格式存储,这是层的序列化表示形式,也是这些层的已知模式。 在 ML.NET 中,使用 ImageAnalytics 和 OnnxTransformer NuGet 包实现了与 ONNX 的互操作性。 ImageAnalytics 包包含一系列转换,这些转换采用图像并将其编码为可用作预测或训练管道输入的数值。 OnnxTransformer 包利用 ONNX 运行时加载 ONNX 模型并使用它根据提供的输入进行预测。
设置 .NET 控制台项目
对 ONNX 的涵义以及 Tiny YOLOv2 的工作原理有了大致了解之后,接下来了解如何生成应用程序。
创建控制台应用程序
创建名为“ObjectDetection”的 C# 控制台应用程序。 单击“下一步”按钮。
选择 .NET 6 作为要使用的框架。 单击“创建” 按钮。
安装“Microsoft.ML”NuGet 包:
注意
除非另有说明,否则本示例使用前面提到的 NuGet 包的最新稳定版本。
- 在“解决方案资源管理器”中,右键单击项目,然后选择“管理 NuGet 包” 。
- 选择“nuget.org”作为“包源”,选择“浏览”选项卡,再搜索“Microsoft.ML”。
- 选择“安装”按钮。
- 选择“预览更改” 对话框上的“确定” 按钮,如果你同意所列包的许可条款,则选择“接受许可” 对话框上的“我接受” 按钮。
- 对 Microsoft.Windows.Compatibility、Microsoft.ML.ImageAnalytics、Microsoft.ML.OnnxTransformer 和 Microsoft.ML.OnnxRuntime 重复这些步骤。
准备你的数据和预训练的模型
下载并解压缩项目资产目录 zip 文件。
将
assets目录复制到 ObjectDetection 项目目录中。 此目录及其子目录包含本教程所需的图像文件(Tiny YOLOv2 模型除外,将在下一步中下载并添加此模型)。从 ONNX Model Zoo 下载并解压缩 Tiny YOLOv2 模型。
将
model.onnx文件复制到 ObjectDetection 项目assets\Model目录中并将其重命名为TinyYolo2_model.onnx。 此目录包含本教程所需的模型。在“解决方案资源管理器”中,右键单击资产目录和子目录中的每个文件,再选择“属性”。 在“高级”下,将“复制到输出目录”的值更改为“如果较新则复制” 。
创建类和定义路径
打开 Program.cs 文件,并将以下附加的 using 语句添加到该文件顶部:
using System.Drawing;
using System.Drawing.Drawing2D;
using ObjectDetection.YoloParser;
using ObjectDetection.DataStructures;
using ObjectDetection;
using Microsoft.ML;
接下来,定义各种资产的路径。
首先,在 Program.cs 文件底部创建
GetAbsolutePath方法。string GetAbsolutePath(string relativePath) { FileInfo _dataRoot = new FileInfo(typeof(Program).Assembly.Location); string assemblyFolderPath = _dataRoot.Directory.FullName; string fullPath = Path.Combine(assemblyFolderPath, relativePath); return fullPath; }然后,在 using 语句下,创建字段以存储资产的位置。
var assetsRelativePath = @"../../../assets"; string assetsPath = GetAbsolutePath(assetsRelativePath); var modelFilePath = Path.Combine(assetsPath, "Model", "TinyYolo2_model.onnx"); var imagesFolder = Path.Combine(assetsPath, "images"); var outputFolder = Path.Combine(assetsPath, "images", "output");
向项目添加新目录以存储输入数据和预测类。
在“解决方案资源管理器”中,右键单击项目,然后选择“添加”>“新文件夹” 。 当新文件夹出现在解决方案资源管理器中时,将其命名为“DataStructures”。
在新创建的“DataStructures”目录中创建输入数据类。
在“解决方案资源管理器”中,右键单击“DataStructures”目录,然后选择“添加”>“新项” 。
在“添加新项”对话框中,选择“类”,并将“名称”字段更改为“ImageNetData.cs” 。 然后,选择“添加” 按钮。
此时,将在代码编辑器中打开 ImageNetData.cs 文件。 将下面的
using语句添加到 ImageNetData.cs 顶部:using System.Collections.Generic; using System.IO; using System.Linq; using Microsoft.ML.Data;删除现有类定义,并将
ImageNetData类的以下代码添加到 ImageNetData.cs 文件中:public class ImageNetData { [LoadColumn(0)] public string ImagePath; [LoadColumn(1)] public string Label; public static IEnumerable<ImageNetData> ReadFromFile(string imageFolder) { return Directory .GetFiles(imageFolder) .Where(filePath => Path.GetExtension(filePath) != ".md") .Select(filePath => new ImageNetData { ImagePath = filePath, Label = Path.GetFileName(filePath) }); } }ImageNetData是输入图像数据类,包含以下 String 字段:ImagePath包含存储图像的路径。Label包含文件的名称。
此外,
ImageNetData包含方法ReadFromFile,该方法加载存储在指定的imageFolder路径中的多个图像文件,并将它们作为ImageNetData对象的集合返回。
在“DataStructures”目录中创建预测类。
在“解决方案资源管理器”中,右键单击“DataStructures”目录,然后选择“添加”>“新项” 。
在“添加新项”对话框中,选择“类”,并将“名称”字段更改为“ImageNetPrediction.cs” 。 然后,选择“添加”按钮。
此时,将在代码编辑器中打开 ImageNetPrediction.cs 文件。 将下面的
using语句添加到 ImageNetPrediction.cs 顶部:using Microsoft.ML.Data;删除现有类定义,并将
ImageNetPrediction类的以下代码添加到 ImageNetPrediction.cs 文件中:public class ImageNetPrediction { [ColumnName("grid")] public float[] PredictedLabels; }ImageNetPrediction是预测数据类,包含以下float[]字段:PredictedLabels包含图像中检测到的每个边界框的尺寸、对象分数和类概率。
初始化变量
执行所有 ML.NET 操作都是从 MLContext 类开始,初始化 mlContext 可创建一个新的 ML.NET 环境,可在模型创建工作流对象之间共享该环境。 从概念上讲,它与实体框架中的 DBContext 类似。
通过将以下行添加到 outputFolder 字段,使用新的 MLContext 实例初始化 mlContext 变量。
MLContext mlContext = new MLContext();
创建分析器来处理模型输出
该模型将图像分割为 13 x 13 网格,其中每个网格单元格为 32px x 32px。 每个网格单元格包含 5 个潜在的对象边界框。 边界框有 25 个元素:
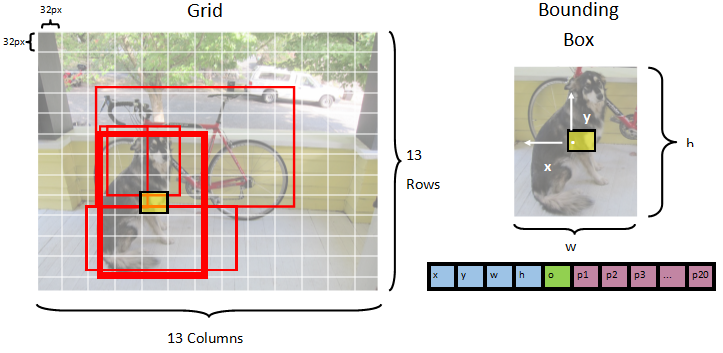
x:边界框中心相对于与其关联的网格单元格的 x 位置。y:边界框中心相对于与其关联的网格单元格格的 y 位置。w:边界框的宽度。h:边界框的高度。o:对象存在于边界框内的置信度值,也称为对象得分。- 模型预测的 20 个类中每个类的
p1-p20类概率。
总之,描述 5 个边界框中每个框的 25 个元素构成了每个网格单元格中包含的 125 个元素。
预训练的 ONNX 模型生成的输出是长度为 21125 的浮点数组,表示维度为 125 x 13 x 13 的张量元素。 为了将模型生成的预测转换为张量,需要进行一些后处理工作。 为此,请创建一组类以帮助分析输出。
向项目中添加一个新目录以组织分析器类集。
- 在“解决方案资源管理器”中,右键单击项目,然后选择“添加”>“新文件夹” 。 当新文件夹出现在解决方案资源管理器中时,将其命名为“YoloParser”。
创建边界框和维度
模型输出的数据包含图像中对象边界框的坐标和维度。 创建维度的基类。
在“解决方案资源管理器”中,右键单击“YoloParser”目录,然后选择“添加”>“新项” 。
在“添加新项”对话框中,选择“类”并将“名称”字段更改为“DimensionsBase.cs” 。 然后,选择“添加” 按钮。
此时,将在代码编辑器中打开 DimensionsBase.cs 文件。 删除所有
using语句和现有类定义。将
DimensionsBase类的以下代码添加到 DimensionsBase.cs 文件中:public class DimensionsBase { public float X { get; set; } public float Y { get; set; } public float Height { get; set; } public float Width { get; set; } }DimensionsBase具有以下float属性:X:包含对象沿 x 轴的位置。Y:包含对象沿 y 轴的位置。Height:包含对象的高度。Width:包含对象的宽度。
接下来,为边界框创建一个类。
在“解决方案资源管理器”中,右键单击“YoloParser”目录,然后选择“添加”>“新项” 。
在“添加新项”对话框中,选择“类”并将“名称”字段更改为“YoloBoundingBox.cs” 。 然后,选择“添加”按钮。
此时,将在代码编辑器中打开 YoloBoundingBox.cs 文件。 将下面的
using语句添加到 YoloBoundingBox.cs 顶部:using System.Drawing;在现有类定义的正上方,添加一个名为
BoundingBoxDimensions的新类定义,该定义继承自DimensionsBase类以包含相应边界框的维度。public class BoundingBoxDimensions : DimensionsBase { }删除现有
YoloBoundingBox类定义,并将YoloBoundingBox类的以下代码添加到 YoloBoundingBox.cs 文件中:public class YoloBoundingBox { public BoundingBoxDimensions Dimensions { get; set; } public string Label { get; set; } public float Confidence { get; set; } public RectangleF Rect { get { return new RectangleF(Dimensions.X, Dimensions.Y, Dimensions.Width, Dimensions.Height); } } public Color BoxColor { get; set; } }YoloBoundingBox具有以下属性:Dimensions:包含边界框的维度。Label:包含在边界框内检测到的对象类。Confidence:包含类的置信度。Rect:包含边界框维度的矩形表示形式。BoxColor:包含与用于在图像上绘制的相应类关联的颜色。
创建分析器
创建维度和边界框的类之后,接下来创建分析器。
在“解决方案资源管理器”中,右键单击“YoloParser”目录,然后选择“添加”>“新项” 。
在“添加新项”对话框中,选择“类”并将“名称”字段更改为“YoloOutputParser.cs” 。 然后,选择“添加” 按钮。
此时,将在代码编辑器中打开 YoloOutputParser.cs 文件。 将下面的
using语句添加到 YoloOutputParser.cs 顶部:using System; using System.Collections.Generic; using System.Drawing; using System.Linq;在现有
YoloOutputParser类定义中,添加一个嵌套类,其中包含图像中每个单元格的尺寸。 为CellDimensions类添加以下代码,该类继承自YoloOutputParser类定义顶部的DimensionsBase类。class CellDimensions : DimensionsBase { }在
YoloOutputParser类定义中,添加以下常量和字段。public const int ROW_COUNT = 13; public const int COL_COUNT = 13; public const int CHANNEL_COUNT = 125; public const int BOXES_PER_CELL = 5; public const int BOX_INFO_FEATURE_COUNT = 5; public const int CLASS_COUNT = 20; public const float CELL_WIDTH = 32; public const float CELL_HEIGHT = 32; private int channelStride = ROW_COUNT * COL_COUNT;ROW_COUNT是分割图像的网格中的行数。COL_COUNT是分割图像的网格中的列数。CHANNEL_COUNT是其中一个网格单元格中包含的值的总数。BOXES_PER_CELL是单元格中边界框的数量,BOX_INFO_FEATURE_COUNT是框中包含的特征数(x、y、高度、宽度、置信度)。CLASS_COUNT是每个边界框中包含的类预测数。CELL_WIDTH是图像网格中一个单元格的宽度。CELL_HEIGHT是图像网格中一个单元格的高度。channelStride是网格中当前单元格的起始位置。
当模型进行预测(也称为评分)时,它会将
416px x 416px输入图像划分为13 x 13大小的单元格网格。 每个单元格都包含32px x 32px。 在每个单元格内,有 5 个边界框,每个边框包含 5 个特征(x、y、宽度、高度、置信度)。 此外,每个边界框包含每个类的概率,在这种情况下为 20。 因此,每个单元包含 125 条信息(5 个特征 + 20 个类概率)。
为所有 5 个边界框在 channelStride 下创建的定位点列表:
private float[] anchors = new float[]
{
1.08F, 1.19F, 3.42F, 4.41F, 6.63F, 11.38F, 9.42F, 5.11F, 16.62F, 10.52F
};
定位点是边界框的预定义的高度和宽度比例。 模型检测到的大多数对象或类都具有相似的比例。 这在创建边界框时非常有用。 不是预测边界框,而是计算预定义维度的偏移量,因此减少了预测边界框所需的计算量。 通常,这些定位点比例是基于所使用的数据集计算的。 在这种情况下,由于数据集是已知的且值已预先计算,因此可以硬编码定位点。
接下来,定义模型将预测的标签或类。 该模型预测了 20 个类,它们是原始 YOLOv2 模型预测的类总数的子集。
在 anchors 下面添加标签列表。
private string[] labels = new string[]
{
"aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow",
"diningtable", "dog", "horse", "motorbike", "person",
"pottedplant", "sheep", "sofa", "train", "tvmonitor"
};
每个类都有相关联的颜色。 在 labels 下分配类的颜色:
private static Color[] classColors = new Color[]
{
Color.Khaki,
Color.Fuchsia,
Color.Silver,
Color.RoyalBlue,
Color.Green,
Color.DarkOrange,
Color.Purple,
Color.Gold,
Color.Red,
Color.Aquamarine,
Color.Lime,
Color.AliceBlue,
Color.Sienna,
Color.Orchid,
Color.Tan,
Color.LightPink,
Color.Yellow,
Color.HotPink,
Color.OliveDrab,
Color.SandyBrown,
Color.DarkTurquoise
};
创建帮助程序函数
后处理阶段涉及一系列步骤。 为此,可以使用几种帮助程序方法。
分析器使用的帮助程序方法是:
Sigmoid应用 sigmoid 函数,该函数输出介于 0 和 1 之间的数字。Softmax将输入向量规范化为概率分布。GetOffset将一维模型输出中的元素映射到125 x 13 x 13张量中的对应位置。ExtractBoundingBoxes使用模型输出中的GetOffset方法提取边界框维度。GetConfidence提取置信度值,该值表示模型是否检测到对象,并使用Sigmoid函数将其转换为百分比。MapBoundingBoxToCell使用边界框维度并将它们映射到图像中的相应单元格。ExtractClasses使用GetOffset方法从模型输出中提取边界框的类预测,并使用Softmax方法将它们转换为概率分布。GetTopResult从具有最高概率的预测类列表中选择类。IntersectionOverUnion筛选具有较低概率的重叠边界框。
在 classColors 列表下面添加所有帮助程序方法的代码。
private float Sigmoid(float value)
{
var k = (float)Math.Exp(value);
return k / (1.0f + k);
}
private float[] Softmax(float[] values)
{
var maxVal = values.Max();
var exp = values.Select(v => Math.Exp(v - maxVal));
var sumExp = exp.Sum();
return exp.Select(v => (float)(v / sumExp)).ToArray();
}
private int GetOffset(int x, int y, int channel)
{
// YOLO outputs a tensor that has a shape of 125x13x13, which
// WinML flattens into a 1D array. To access a specific channel
// for a given (x,y) cell position, we need to calculate an offset
// into the array
return (channel * this.channelStride) + (y * COL_COUNT) + x;
}
private BoundingBoxDimensions ExtractBoundingBoxDimensions(float[] modelOutput, int x, int y, int channel)
{
return new BoundingBoxDimensions
{
X = modelOutput[GetOffset(x, y, channel)],
Y = modelOutput[GetOffset(x, y, channel + 1)],
Width = modelOutput[GetOffset(x, y, channel + 2)],
Height = modelOutput[GetOffset(x, y, channel + 3)]
};
}
private float GetConfidence(float[] modelOutput, int x, int y, int channel)
{
return Sigmoid(modelOutput[GetOffset(x, y, channel + 4)]);
}
private CellDimensions MapBoundingBoxToCell(int x, int y, int box, BoundingBoxDimensions boxDimensions)
{
return new CellDimensions
{
X = ((float)x + Sigmoid(boxDimensions.X)) * CELL_WIDTH,
Y = ((float)y + Sigmoid(boxDimensions.Y)) * CELL_HEIGHT,
Width = (float)Math.Exp(boxDimensions.Width) * CELL_WIDTH * anchors[box * 2],
Height = (float)Math.Exp(boxDimensions.Height) * CELL_HEIGHT * anchors[box * 2 + 1],
};
}
public float[] ExtractClasses(float[] modelOutput, int x, int y, int channel)
{
float[] predictedClasses = new float[CLASS_COUNT];
int predictedClassOffset = channel + BOX_INFO_FEATURE_COUNT;
for (int predictedClass = 0; predictedClass < CLASS_COUNT; predictedClass++)
{
predictedClasses[predictedClass] = modelOutput[GetOffset(x, y, predictedClass + predictedClassOffset)];
}
return Softmax(predictedClasses);
}
private ValueTuple<int, float> GetTopResult(float[] predictedClasses)
{
return predictedClasses
.Select((predictedClass, index) => (Index: index, Value: predictedClass))
.OrderByDescending(result => result.Value)
.First();
}
private float IntersectionOverUnion(RectangleF boundingBoxA, RectangleF boundingBoxB)
{
var areaA = boundingBoxA.Width * boundingBoxA.Height;
if (areaA <= 0)
return 0;
var areaB = boundingBoxB.Width * boundingBoxB.Height;
if (areaB <= 0)
return 0;
var minX = Math.Max(boundingBoxA.Left, boundingBoxB.Left);
var minY = Math.Max(boundingBoxA.Top, boundingBoxB.Top);
var maxX = Math.Min(boundingBoxA.Right, boundingBoxB.Right);
var maxY = Math.Min(boundingBoxA.Bottom, boundingBoxB.Bottom);
var intersectionArea = Math.Max(maxY - minY, 0) * Math.Max(maxX - minX, 0);
return intersectionArea / (areaA + areaB - intersectionArea);
}
定义完所有帮助程序方法之后,即可使用它们来处理模型输出。
在 IntersectionOverUnion 方法下面,创建 ParseOutputs 方法以处理模型生成的输出。
public IList<YoloBoundingBox> ParseOutputs(float[] yoloModelOutputs, float threshold = .3F)
{
}
创建一个列表来存储边界框并在 ParseOutputs 方法中定义变量。
var boxes = new List<YoloBoundingBox>();
每个图像都被分成一个 13 x 13 单元格的网格。 每个单元格包含五个边界框。 在 boxes 变量下方,添加代码以处理每个单元格中的所有框。
for (int row = 0; row < ROW_COUNT; row++)
{
for (int column = 0; column < COL_COUNT; column++)
{
for (int box = 0; box < BOXES_PER_CELL; box++)
{
}
}
}
在最内层循环内,计算一维模型输出中当前框的起始位置。
var channel = (box * (CLASS_COUNT + BOX_INFO_FEATURE_COUNT));
在其下方,使用 ExtractBoundingBoxDimensions 方法获取当前边界框的维度。
BoundingBoxDimensions boundingBoxDimensions = ExtractBoundingBoxDimensions(yoloModelOutputs, row, column, channel);
然后,使用 GetConfidence 方法获取当前边界框的置信度。
float confidence = GetConfidence(yoloModelOutputs, row, column, channel);
之后,使用 MapBoundingBoxToCell 方法将当前边界框映射到正在处理的当前单元格。
CellDimensions mappedBoundingBox = MapBoundingBoxToCell(row, column, box, boundingBoxDimensions);
在进行任何进一步的处理之前,请检查置信值是否大于提供的阈值。 如果没有,请处理下一个边界框。
if (confidence < threshold)
continue;
否则,继续处理输出。 下一步是使用 ExtractClasses 方法获取当前边界框的预测类的概率分布。
float[] predictedClasses = ExtractClasses(yoloModelOutputs, row, column, channel);
然后,使用 GetTopResult 方法获取当前框概率最高的类的值和索引,并计算其得分。
var (topResultIndex, topResultScore) = GetTopResult(predictedClasses);
var topScore = topResultScore * confidence;
再次使用 topScore 只保留那些超过指定阈值的边界框。
if (topScore < threshold)
continue;
最后,如果当前边界框超过阈值,请创建一个新的 BoundingBox 对象并将其添加到 boxes 列表中。
boxes.Add(new YoloBoundingBox()
{
Dimensions = new BoundingBoxDimensions
{
X = (mappedBoundingBox.X - mappedBoundingBox.Width / 2),
Y = (mappedBoundingBox.Y - mappedBoundingBox.Height / 2),
Width = mappedBoundingBox.Width,
Height = mappedBoundingBox.Height,
},
Confidence = topScore,
Label = labels[topResultIndex],
BoxColor = classColors[topResultIndex]
});
处理完图像中的所有单元格后,返回 boxes 列表。 在 ParseOutputs 方法的最外层 for 循环下面添加以下 return 语句。
return boxes;
筛选重叠框
从模型输出中提取所有高置信度的边界框之后,接下来需要进行额外的筛选以移除重叠的图像。 在 ParseOutputs 方法下添加一个名为 FilterBoundingBoxes 的方法:
public IList<YoloBoundingBox> FilterBoundingBoxes(IList<YoloBoundingBox> boxes, int limit, float threshold)
{
}
在 FilterBoundingBoxes 方法中,首先创建一个等于检测到的框大小的数组,并将所有插槽标记为“活动”或“待处理”。
var activeCount = boxes.Count;
var isActiveBoxes = new bool[boxes.Count];
for (int i = 0; i < isActiveBoxes.Length; i++)
isActiveBoxes[i] = true;
然后,根据置信度按降序对包含边界框的列表进行排序。
var sortedBoxes = boxes.Select((b, i) => new { Box = b, Index = i })
.OrderByDescending(b => b.Box.Confidence)
.ToList();
之后,创建一个列表来保存筛选的结果。
var results = new List<YoloBoundingBox>();
通过遍历每个边界框,开始处理每个边界框。
for (int i = 0; i < boxes.Count; i++)
{
}
在此 for 循环内部,检查是否可以处理当前边界框。
if (isActiveBoxes[i])
{
}
如果可以,请将边界框添加到结果列表中。 如果结果超出了要提取的框的指定限制,则中断循环。 在 if 语句中添加以下代码。
var boxA = sortedBoxes[i].Box;
results.Add(boxA);
if (results.Count >= limit)
break;
否则,请查看相邻的边界框。 在框限制检查下面添加以下代码。
for (var j = i + 1; j < boxes.Count; j++)
{
}
与第一个框一样,如果相邻框处于活动或待处理状态,请使用 IntersectionOverUnion 方法检查第一个框和第二个框是否超出指定的阈值。 将以下代码添加到最内层的 for 循环中。
if (isActiveBoxes[j])
{
var boxB = sortedBoxes[j].Box;
if (IntersectionOverUnion(boxA.Rect, boxB.Rect) > threshold)
{
isActiveBoxes[j] = false;
activeCount--;
if (activeCount <= 0)
break;
}
}
在检查相邻边界框的最内部 for 循环之外,查看是否有任何剩余的边界框要处理。 如果没有,则中断外部 for 循环。
if (activeCount <= 0)
break;
最后,在 FilterBoundingBoxes 方法的初始 for 循环之外,返回结果:
return results;
很棒! 现在可以将此代码与模型配合使用,以进行评分。
使用该模型进行评分
就像后处理一样,评分步骤也有几个步骤。 为此,请向项目添加包含评分逻辑的类。
在“解决方案资源管理器” 中,右键单击项目,然后选择“添加” >“新项” 。
在“添加新项”对话框中,选择“类”并将“名称”字段更改为“OnnxModelScorer.cs” 。 然后,选择“添加”按钮。
此时,将在代码编辑器中打开 OnnxModelScorer.cs 文件。 将下面的
using语句添加到 OnnxModelScorer.cs 顶部:using System; using System.Collections.Generic; using System.Linq; using Microsoft.ML; using Microsoft.ML.Data; using ObjectDetection.DataStructures; using ObjectDetection.YoloParser;在
OnnxModelScorer类定义中,添加以下变量。private readonly string imagesFolder; private readonly string modelLocation; private readonly MLContext mlContext; private IList<YoloBoundingBox> _boundingBoxes = new List<YoloBoundingBox>();在其下方,为
OnnxModelScorer类创建一个构造函数,用于初始化先前定义的变量。public OnnxModelScorer(string imagesFolder, string modelLocation, MLContext mlContext) { this.imagesFolder = imagesFolder; this.modelLocation = modelLocation; this.mlContext = mlContext; }创建构造函数之后,定义两个结构,其中包含与图像和模型设置相关的变量。 创建一个名为
ImageNetSettings的结构,以包含预期作为模型输入的高度和宽度。public struct ImageNetSettings { public const int imageHeight = 416; public const int imageWidth = 416; }然后,创建另一个名为
TinyYoloModelSettings的结构,其中包含模型的输入层和输出层名称。 若要可视化模型的输入层和输出层名称,可以使用 Netron 之类的工具。public struct TinyYoloModelSettings { // for checking Tiny yolo2 Model input and output parameter names, //you can use tools like Netron, // which is installed by Visual Studio AI Tools // input tensor name public const string ModelInput = "image"; // output tensor name public const string ModelOutput = "grid"; }接下来,创建用于评分的第一组方法。 在
OnnxModelScorer类中创建LoadModel方法。private ITransformer LoadModel(string modelLocation) { }在
LoadModel方法中,添加以下代码以进行日志记录。Console.WriteLine("Read model"); Console.WriteLine($"Model location: {modelLocation}"); Console.WriteLine($"Default parameters: image size=({ImageNetSettings.imageWidth},{ImageNetSettings.imageHeight})");ML.NET 管道需要知道在调用
Fit方法时要操作的数据架构。 在这种情况下,将使用类似于训练的过程。 但是,由于没有进行实际训练,因此可以使用空的IDataView。 使用空列表为管道创建新的IDataView。var data = mlContext.Data.LoadFromEnumerable(new List<ImageNetData>());在此之后,定义管道。 管道将包含四个转换。
LoadImages将图片作为位图加载。ResizeImages将图片重新调整为指定的大小(在本例中为416 x 416)。ExtractPixels将图像的像素表示形式从位图更改为数字向量。ApplyOnnxModel加载 ONNX 模型并使用它对提供的数据进行评分。
在
data变量下面的LoadModel方法中定义管道。var pipeline = mlContext.Transforms.LoadImages(outputColumnName: "image", imageFolder: "", inputColumnName: nameof(ImageNetData.ImagePath)) .Append(mlContext.Transforms.ResizeImages(outputColumnName: "image", imageWidth: ImageNetSettings.imageWidth, imageHeight: ImageNetSettings.imageHeight, inputColumnName: "image")) .Append(mlContext.Transforms.ExtractPixels(outputColumnName: "image")) .Append(mlContext.Transforms.ApplyOnnxModel(modelFile: modelLocation, outputColumnNames: new[] { TinyYoloModelSettings.ModelOutput }, inputColumnNames: new[] { TinyYoloModelSettings.ModelInput }));现在,可以实例化模型以进行评分。 调用管道上的
Fit方法并将其返回以进行进一步处理。var model = pipeline.Fit(data); return model;
加载模型后,可将其用来进行预测。 若要简化该过程,请在 LoadModel 方法下创建一个名为 PredictDataUsingModel 的方法。
private IEnumerable<float[]> PredictDataUsingModel(IDataView testData, ITransformer model)
{
}
在 PredictDataUsingModel 中,添加以下代码以进行日志记录。
Console.WriteLine($"Images location: {imagesFolder}");
Console.WriteLine("");
Console.WriteLine("=====Identify the objects in the images=====");
Console.WriteLine("");
然后,使用 Transform 方法对数据进行评分。
IDataView scoredData = model.Transform(testData);
提取预测的概率并将其返回以进行其他处理。
IEnumerable<float[]> probabilities = scoredData.GetColumn<float[]>(TinyYoloModelSettings.ModelOutput);
return probabilities;
现在已经设置了两个步骤,将它们合并为一个方法。 在 PredictDataUsingModel 方法下面,添加一个名为 Score 的新方法。
public IEnumerable<float[]> Score(IDataView data)
{
var model = LoadModel(modelLocation);
return PredictDataUsingModel(data, model);
}
马上就大功告成了! 现在可以将其全部投入使用。
检测对象
现在所有设置都已完成,可以检测一些对象。
对模型输出进行评分和分析
在创建 mlContext 变量的下面,添加一个 try-catch 语句。
try
{
}
catch (Exception ex)
{
Console.WriteLine(ex.ToString());
}
在 try 块内部,开始实现对象检测逻辑。 首先,将数据加载到 IDataView 中。
IEnumerable<ImageNetData> images = ImageNetData.ReadFromFile(imagesFolder);
IDataView imageDataView = mlContext.Data.LoadFromEnumerable(images);
然后,创建 OnnxModelScorer 的实例,并使用它对加载的数据进行评分。
// Create instance of model scorer
var modelScorer = new OnnxModelScorer(imagesFolder, modelFilePath, mlContext);
// Use model to score data
IEnumerable<float[]> probabilities = modelScorer.Score(imageDataView);
现在执行后处理步骤。 创建 YoloOutputParser 的实例并使用它来处理模型输出。
YoloOutputParser parser = new YoloOutputParser();
var boundingBoxes =
probabilities
.Select(probability => parser.ParseOutputs(probability))
.Select(boxes => parser.FilterBoundingBoxes(boxes, 5, .5F));
处理完模型输出后,便可以在图像上绘制边界框。
将预测结果可视化
在模型对图像进行评分并处理好输出后,必须在图像上绘制边界框。 为此,请在 Program.cs 内的 GetAbsolutePath 方法下添加名为 DrawBoundingBox 的方法。
void DrawBoundingBox(string inputImageLocation, string outputImageLocation, string imageName, IList<YoloBoundingBox> filteredBoundingBoxes)
{
}
首先,加载图像并使用 DrawBoundingBox 方法获取高度和宽度尺寸。
Image image = Image.FromFile(Path.Combine(inputImageLocation, imageName));
var originalImageHeight = image.Height;
var originalImageWidth = image.Width;
然后,创建 for-each 循环以遍历模型检测到的每个边界框。
foreach (var box in filteredBoundingBoxes)
{
}
在 for each 循环的内部,获取边界框的维度。
var x = (uint)Math.Max(box.Dimensions.X, 0);
var y = (uint)Math.Max(box.Dimensions.Y, 0);
var width = (uint)Math.Min(originalImageWidth - x, box.Dimensions.Width);
var height = (uint)Math.Min(originalImageHeight - y, box.Dimensions.Height);
由于边界框的维度对应于 416 x 416 的模型输入,因此缩放边界框维度以匹配图像的实际尺寸。
x = (uint)originalImageWidth * x / OnnxModelScorer.ImageNetSettings.imageWidth;
y = (uint)originalImageHeight * y / OnnxModelScorer.ImageNetSettings.imageHeight;
width = (uint)originalImageWidth * width / OnnxModelScorer.ImageNetSettings.imageWidth;
height = (uint)originalImageHeight * height / OnnxModelScorer.ImageNetSettings.imageHeight;
然后,为将出现在每个边界框上方的文本定义模板。 文本将包含相应边界框内的对象类以及置信度。
string text = $"{box.Label} ({(box.Confidence * 100).ToString("0")}%)";
若要在图像上绘制,请将其转换为 Graphics 对象。
using (Graphics thumbnailGraphic = Graphics.FromImage(image))
{
}
在 using 代码块内,调整图形的 Graphics 对象设置。
thumbnailGraphic.CompositingQuality = CompositingQuality.HighQuality;
thumbnailGraphic.SmoothingMode = SmoothingMode.HighQuality;
thumbnailGraphic.InterpolationMode = InterpolationMode.HighQualityBicubic;
在下面,设置文本和边界框的字体和颜色选项。
// Define Text Options
Font drawFont = new Font("Arial", 12, FontStyle.Bold);
SizeF size = thumbnailGraphic.MeasureString(text, drawFont);
SolidBrush fontBrush = new SolidBrush(Color.Black);
Point atPoint = new Point((int)x, (int)y - (int)size.Height - 1);
// Define BoundingBox options
Pen pen = new Pen(box.BoxColor, 3.2f);
SolidBrush colorBrush = new SolidBrush(box.BoxColor);
使用 FillRectangle 方法创建并填充边界框上方的矩形以包含文本。 这将有助于对比文本,提高可读性。
thumbnailGraphic.FillRectangle(colorBrush, (int)x, (int)(y - size.Height - 1), (int)size.Width, (int)size.Height);
然后,使用 DrawString 和 DrawRectangle 方法在图像上绘制文本和边界框。
thumbnailGraphic.DrawString(text, drawFont, fontBrush, atPoint);
// Draw bounding box on image
thumbnailGraphic.DrawRectangle(pen, x, y, width, height);
在 for-each 循环之外,添加代码以保存 outputFolder 中的图像。
if (!Directory.Exists(outputImageLocation))
{
Directory.CreateDirectory(outputImageLocation);
}
image.Save(Path.Combine(outputImageLocation, imageName));
要获得应用程序在运行时按预期进行预测的其他反馈,请在 Program.cs 文件中的 DrawBoundingBox 方法下添加名为 LogDetectedObjects 的方法,以将检测到的对象输出到控制台。
void LogDetectedObjects(string imageName, IList<YoloBoundingBox> boundingBoxes)
{
Console.WriteLine($".....The objects in the image {imageName} are detected as below....");
foreach (var box in boundingBoxes)
{
Console.WriteLine($"{box.Label} and its Confidence score: {box.Confidence}");
}
Console.WriteLine("");
}
你已经有了帮助器方法,现在可以根据预测创建视觉反馈,并可添加 for 循环来循环访问每个已评分的图像。
for (var i = 0; i < images.Count(); i++)
{
}
在 for 循环内部,获取图像文件的名称以及与之关联的边界框。
string imageFileName = images.ElementAt(i).Label;
IList<YoloBoundingBox> detectedObjects = boundingBoxes.ElementAt(i);
在此之后,使用 DrawBoundingBox 方法在图像上绘制边界框。
DrawBoundingBox(imagesFolder, outputFolder, imageFileName, detectedObjects);
最后,使用 LogDetectedObjects 方法将预测输出到控制台。
LogDetectedObjects(imageFileName, detectedObjects);
在 try-catch 语句之后,添加其他逻辑以指示进程已完成运行。
Console.WriteLine("========= End of Process..Hit any Key ========");
就这么简单!
结果
按照上述步骤操作后,运行控制台应用 (Ctrl + F5)。 结果应如以下输出所示。 你可能会看到警告或处理消息,为清楚起见,这些消息已从以下结果中删除。
=====Identify the objects in the images=====
.....The objects in the image image1.jpg are detected as below....
car and its Confidence score: 0.9697262
car and its Confidence score: 0.6674225
person and its Confidence score: 0.5226039
car and its Confidence score: 0.5224892
car and its Confidence score: 0.4675332
.....The objects in the image image2.jpg are detected as below....
cat and its Confidence score: 0.6461141
cat and its Confidence score: 0.6400049
.....The objects in the image image3.jpg are detected as below....
chair and its Confidence score: 0.840578
chair and its Confidence score: 0.796363
diningtable and its Confidence score: 0.6056048
diningtable and its Confidence score: 0.3737402
.....The objects in the image image4.jpg are detected as below....
dog and its Confidence score: 0.7608147
person and its Confidence score: 0.6321323
dog and its Confidence score: 0.5967442
person and its Confidence score: 0.5730394
person and its Confidence score: 0.5551759
========= End of Process..Hit any Key ========
若要查看带有边界框的图像,请导航到 assets/images/output/ 目录。 以下是其中一个已处理的图像示例。

祝贺你! 现已通过重用 ML.NET 中的预训练 ONNX 模型,成功生成了对象检测机器学习模型。
可以在 dotnet/machinelearning-samples 存储库中找到本教程的源代码。
在本教程中,你将了解:
- 了解问题
- 了解什么是 ONNX 以及它如何与 ML.NET 配合使用
- 了解模型
- 重用预训练的模型
- 使用已加载模型检测对象
请查看机器学习示例 GitHub 存储库,以探索扩展的对象检测示例。
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈