使用 .NET 中的缓冲区
本文概述了有助于读取跨多个缓冲区运行的数据的类型。 它们主要用于支持 PipeReader 对象。
IBufferWriter<T>
System.Buffers.IBufferWriter<T> 是同步缓冲写入的协定。 在最低级别上,接口:
void WriteHello(IBufferWriter<byte> writer)
{
// Request at least 5 bytes.
Span<byte> span = writer.GetSpan(5);
ReadOnlySpan<char> helloSpan = "Hello".AsSpan();
int written = Encoding.ASCII.GetBytes(helloSpan, span);
// Tell the writer how many bytes were written.
writer.Advance(written);
}
前面的方法:
- 使用
GetSpan(5)从IBufferWriter<byte>请求至少 5 个字节的缓冲区。 - 将 ASCII 字符串“Hello”的字节写入返回的
Span<byte>。 - 调用 IBufferWriter<T> 以指示写入缓冲区的字节数。
此写入方法使用 IBufferWriter<T> 提供的 Memory<T>/Span<T> 缓冲区。 或者,可以使用 Write 扩展方法将现有缓冲区复制到 IBufferWriter<T>。 Write 根据需要调用 GetSpan/Advance,因此在写入后无需调用 Advance:
void WriteHello(IBufferWriter<byte> writer)
{
byte[] helloBytes = Encoding.ASCII.GetBytes("Hello");
// Write helloBytes to the writer. There's no need to call Advance here
// since Write calls Advance.
writer.Write(helloBytes);
}
ArrayBufferWriter<T> 是 IBufferWriter<T> 的实现,其后备存储是单个连续数组。
IBufferWriter 常见问题
GetSpan和GetMemory返回至少具有请求内存量的缓冲区。 请勿假设确切的缓冲区大小 。- 无法保证连续的调用将返回相同的缓冲区或相同大小的缓冲区。
- 在调用
Advance之后,必须请求一个新的缓冲区来继续写入更多数据。 调用Advance后无法写入先前获取的缓冲区。
ReadOnlySequence<T>
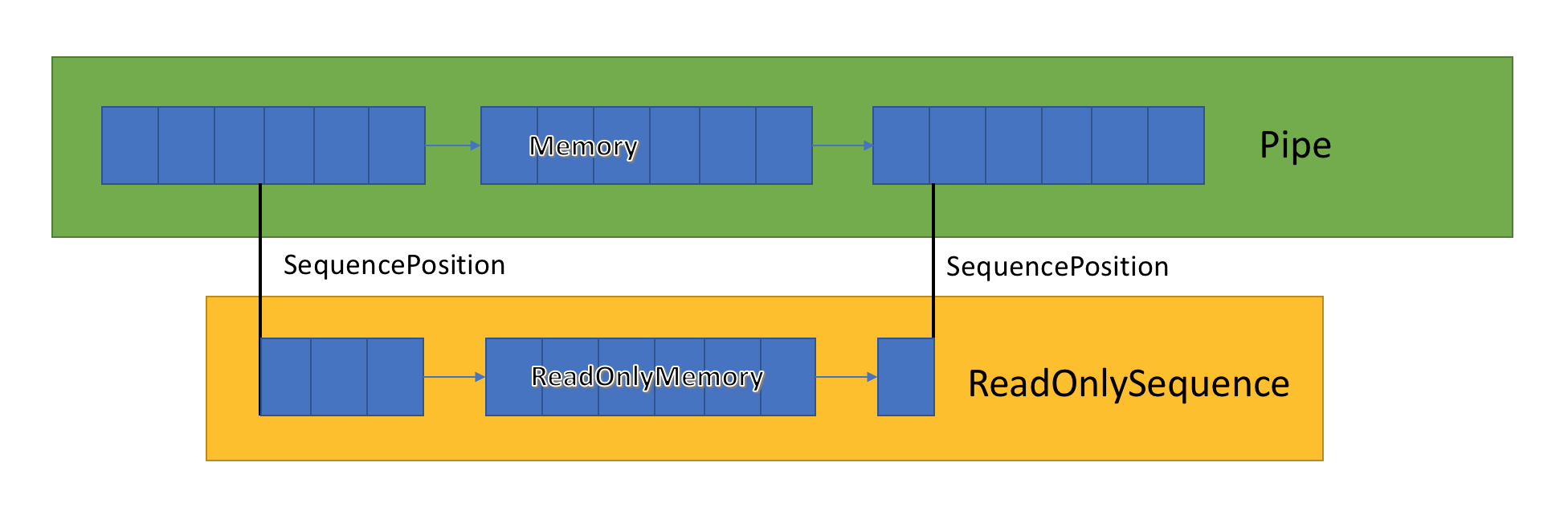
ReadOnlySequence<T> 是一个可以表示 T 的连续或非连续序列的结构。 它通过以下方法进行构造:
- 一个
T[] - 一个
ReadOnlyMemory<T> - 一对链接列表节点 ReadOnlySequenceSegment<T> 和索引,用于表示序列的开始位置和结束位置。
第三种表示形式最值得关注,因为它对 ReadOnlySequence<T> 上的各种操作有性能影响:
| 表示形式 | 操作 | 复杂性 |
|---|---|---|
T[]/ReadOnlyMemory<T> |
Length |
O(1) |
T[]/ReadOnlyMemory<T> |
GetPosition(long) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(int, int) |
O(1) |
T[]/ReadOnlyMemory<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
ReadOnlySequenceSegment<T> |
Length |
O(1) |
ReadOnlySequenceSegment<T> |
GetPosition(long) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(int, int) |
O(number of segments) |
ReadOnlySequenceSegment<T> |
Slice(SequencePosition, SequencePosition) |
O(1) |
由于这种混合表示形式,ReadOnlySequence<T> 将索引作为 SequencePosition(而不是整数)公开。 SequencePosition:
- 是一个不透明的值,该值将索引表示为其起源的
ReadOnlySequence<T>。 - 由两个部分组成:整数和对象。 这两个值的含义与
ReadOnlySequence<T>的实现相关联。
访问数据
ReadOnlySequence<T> 将数据作为 ReadOnlyMemory<T> 的枚举公开。 可以使用基本 foreach 来枚举每个段:
long FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
long position = 0;
foreach (ReadOnlyMemory<byte> segment in buffer)
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return position + index;
}
position += span.Length;
}
return -1;
}
前面的方法搜索特定字节的每个段。 如果需要跟踪每个段的 SequencePosition,则 ReadOnlySequence<T>.TryGet 更为合适。 下一个示例更改前面的代码,以返回 SequencePosition 而不是整数。 返回 SequencePosition 的好处是使调用方能够避免第二次扫描以获取特定索引处的数据。
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
SequencePosition position = buffer.Start;
SequencePosition result = position;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
var index = span.IndexOf(data);
if (index != -1)
{
return buffer.GetPosition(index, result);
}
result = position;
}
return null;
}
SequencePosition 和 TryGet 的组合类似于枚举器。 将在每次迭代开始时修改位置字段,使其为 ReadOnlySequence<T> 中的每个段的开头。
前面的方法作为 ReadOnlySequence<T> 的扩展方法存在。 PositionOf 可用于简化前面的代码:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data) => buffer.PositionOf(data);
处理 ReadOnlySequence<T>
处理 ReadOnlySequence<T> 可能比较困难,因为数据可能会拆分到序列中的多个段。 为了获得最佳性能,请将代码拆分为两个路径:
- 处理单段情况的快速路径。
- 处理拆分到各个段中的数据的慢速路径。
可以使用多种方法来处理多段序列中的数据:
- 使用
SequenceReader<T>。 - 逐段分析数据,同时跟踪已分析的段内的
SequencePosition和索引。 这样可以避免不必要的分配,但可能效率会很低,尤其是对于小型缓冲区。 - 将
ReadOnlySequence<T>复制到连续数组,并将其视为单个缓冲区:- 如果
ReadOnlySequence<T>的大小较小,则可以使用 stackalloc 运算符将数据复制到堆栈分配的缓冲区。 - 使用 ArrayPool<T>.Shared 将
ReadOnlySequence<T>复制到共用的数组。 - 使用
ReadOnlySequence<T>.ToArray()。 不建议在热路径中使用这种方法,因为它会在堆上分配新的T[]。
- 如果
以下示例演示了处理 ReadOnlySequence<byte> 的一些常见情况:
处理二进制数据
以下示例从 ReadOnlySequence<byte> 的开头分析 4 字节的大端整数长度。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
// If there's not enough space, the length can't be obtained.
if (buffer.Length < 4)
{
length = 0;
return false;
}
// Grab the first 4 bytes of the buffer.
var lengthSlice = buffer.Slice(buffer.Start, 4);
if (lengthSlice.IsSingleSegment)
{
// Fast path since it's a single segment.
length = BinaryPrimitives.ReadInt32BigEndian(lengthSlice.First.Span);
}
else
{
// There are 4 bytes split across multiple segments. Since it's so small, it
// can be copied to a stack allocated buffer. This avoids a heap allocation.
Span<byte> stackBuffer = stackalloc byte[4];
lengthSlice.CopyTo(stackBuffer);
length = BinaryPrimitives.ReadInt32BigEndian(stackBuffer);
}
// Move the buffer 4 bytes ahead.
buffer = buffer.Slice(lengthSlice.End);
return true;
}
处理文本数据
如下示例中:
- 查找
ReadOnlySequence<byte>中的第一个换行符 (\r\n),并通过 out 'line' 参数返回该符号。 - 剪裁该行,从输入缓冲区中排除
\r\n。
static bool TryParseLine(ref ReadOnlySequence<byte> buffer, out ReadOnlySequence<byte> line)
{
SequencePosition position = buffer.Start;
SequencePosition previous = position;
var index = -1;
line = default;
while (buffer.TryGet(ref position, out ReadOnlyMemory<byte> segment))
{
ReadOnlySpan<byte> span = segment.Span;
// Look for \r in the current segment.
index = span.IndexOf((byte)'\r');
if (index != -1)
{
// Check next segment for \n.
if (index + 1 >= span.Length)
{
var next = position;
if (!buffer.TryGet(ref next, out ReadOnlyMemory<byte> nextSegment))
{
// You're at the end of the sequence.
return false;
}
else if (nextSegment.Span[0] == (byte)'\n')
{
// A match was found.
break;
}
}
// Check the current segment of \n.
else if (span[index + 1] == (byte)'\n')
{
// It was found.
break;
}
}
previous = position;
}
if (index != -1)
{
// Get the position just before the \r\n.
var delimeter = buffer.GetPosition(index, previous);
// Slice the line (excluding \r\n).
line = buffer.Slice(buffer.Start, delimeter);
// Slice the buffer to get the remaining data after the line.
buffer = buffer.Slice(buffer.GetPosition(2, delimeter));
return true;
}
return false;
}
空段
将空段存储在 ReadOnlySequence<T> 中是有效的。 显式枚举段时,可能会出现空段:
static void EmptySegments()
{
// This logic creates a ReadOnlySequence<byte> with 4 segments,
// two of which are empty.
var first = new BufferSegment(new byte[0]);
var last = first.Append(new byte[] { 97 })
.Append(new byte[0]).Append(new byte[] { 98 });
// Construct the ReadOnlySequence<byte> from the linked list segments.
var data = new ReadOnlySequence<byte>(first, 0, last, 1);
// Slice using numbers.
var sequence1 = data.Slice(0, 2);
// Slice using SequencePosition pointing at the empty segment.
var sequence2 = data.Slice(data.Start, 2);
Console.WriteLine($"sequence1.Length={sequence1.Length}"); // sequence1.Length=2
Console.WriteLine($"sequence2.Length={sequence2.Length}"); // sequence2.Length=2
// sequence1.FirstSpan.Length=1
Console.WriteLine($"sequence1.FirstSpan.Length={sequence1.FirstSpan.Length}");
// Slicing using SequencePosition will Slice the ReadOnlySequence<byte> directly
// on the empty segment!
// sequence2.FirstSpan.Length=0
Console.WriteLine($"sequence2.FirstSpan.Length={sequence2.FirstSpan.Length}");
// The following code prints 0, 1, 0, 1.
SequencePosition position = data.Start;
while (data.TryGet(ref position, out ReadOnlyMemory<byte> memory))
{
Console.WriteLine(memory.Length);
}
}
class BufferSegment : ReadOnlySequenceSegment<byte>
{
public BufferSegment(Memory<byte> memory)
{
Memory = memory;
}
public BufferSegment Append(Memory<byte> memory)
{
var segment = new BufferSegment(memory)
{
RunningIndex = RunningIndex + Memory.Length
};
Next = segment;
return segment;
}
}
前面的代码将创建一个包含空段的 ReadOnlySequence<byte>,并显示这些空段对各种 API 的影响:
- 包含指向空段的
SequencePosition的ReadOnlySequence<T>.Slice会保留该段。 - 包含 int 的
ReadOnlySequence<T>.Slice会跳过空段。 - 枚举
ReadOnlySequence<T>会枚举空段。
ReadOnlySequence<T> 和 SequencePosition 的潜在问题
处理 ReadOnlySequence<T>/SequencePosition 与常规 ReadOnlySpan<T>/ReadOnlyMemory<T>/T[]/int 时,有几个异常的结果:
SequencePosition是特定ReadOnlySequence<T>的位置标记,而不是绝对位置。 由于它是相对于特定ReadOnlySequence<T>的,因此如果在其起源的ReadOnlySequence<T>之外使用,则没有意义。- 不能对没有
ReadOnlySequence<T>的SequencePosition执行算术运算。 这意味着,执行position++等基本操作将以position = ReadOnlySequence<T>.GetPosition(1, position)的形式写入。 GetPosition(long)不支持负索引。 这意味着,如果没有遍历所有段,就无法获取倒数第二个字符。- 无法比较两个
SequencePosition,这使得难以:- 了解一个位置是否大于或小于另一个位置。
- 编写一些分析算法。
ReadOnlySequence<T>大于对象引用,并且应尽可能通过 in 或 ref 进行传递。 通过in或ref传递ReadOnlySequence<T>可减少结构的复制。- 空段:
- 在
ReadOnlySequence<T>中有效。 - 可能会在使用
ReadOnlySequence<T>.TryGet方法进行循环访问时出现。 - 可能会在结合使用
ReadOnlySequence<T>.Slice()方法与SequencePosition对象来对序列进行切片时出现。
- 在
SequenceReader<T>
- 是 .NET Core 3.0 中引入的一种新类型,用于简化
ReadOnlySequence<T>的处理。 - 统一了单段
ReadOnlySequence<T>和多段ReadOnlySequence<T>之间的差异。 - 提供用于读取二进制数据和文本数据(
byte和char,不一定拆分到各个段)的帮助程序。
提供用于处理二进制数据和带分隔符的数据的内置方法。 以下部分演示了与 SequenceReader<T> 相同的方法:
访问数据
SequenceReader<T> 具有用于直接枚举 ReadOnlySequence<T> 内的数据的方法。 以下代码是一次处理 ReadOnlySequence<byte> 和 byte 的示例:
while (reader.TryRead(out byte b))
{
Process(b);
}
CurrentSpan 公开了当前段的 Span,这类似于在方法中手动完成的操作。
使用位置
以下代码是使用 SequenceReader<T> 实现 FindIndexOf 的示例:
SequencePosition? FindIndexOf(in ReadOnlySequence<byte> buffer, byte data)
{
var reader = new SequenceReader<byte>(buffer);
while (!reader.End)
{
// Search for the byte in the current span.
var index = reader.CurrentSpan.IndexOf(data);
if (index != -1)
{
// It was found, so advance to the position.
reader.Advance(index);
return reader.Position;
}
// Skip the current segment since there's nothing in it.
reader.Advance(reader.CurrentSpan.Length);
}
return null;
}
处理二进制数据
以下示例从 ReadOnlySequence<byte> 的开头分析 4 字节的大端整数长度。
bool TryParseHeaderLength(ref ReadOnlySequence<byte> buffer, out int length)
{
var reader = new SequenceReader<byte>(buffer);
return reader.TryReadBigEndian(out length);
}
处理文本数据
static ReadOnlySpan<byte> NewLine => new byte[] { (byte)'\r', (byte)'\n' };
static bool TryParseLine(ref ReadOnlySequence<byte> buffer,
out ReadOnlySequence<byte> line)
{
var reader = new SequenceReader<byte>(buffer);
if (reader.TryReadTo(out line, NewLine))
{
buffer = buffer.Slice(reader.Position);
return true;
}
line = default;
return false;
}
SequenceReader<T> 常见问题
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈