Direct Lake
Direct Lake 模式是一项语义模型功能,用于在 Power BI 中分析超大数据量。 Direct Lake 基于直接从数据湖加载 parquet 格式文件,无需查询湖屋或仓库端点,也无需将数据导入或复制到 Power BI 模型。 通过 Direct Lake 可快速地将数据湖中的数据直接加载到 Power BI 引擎,将其准备好进行分析。 下图显示了经典导入模式和 DirectQuery 模式与 Direct Lake 模式的比较情况。
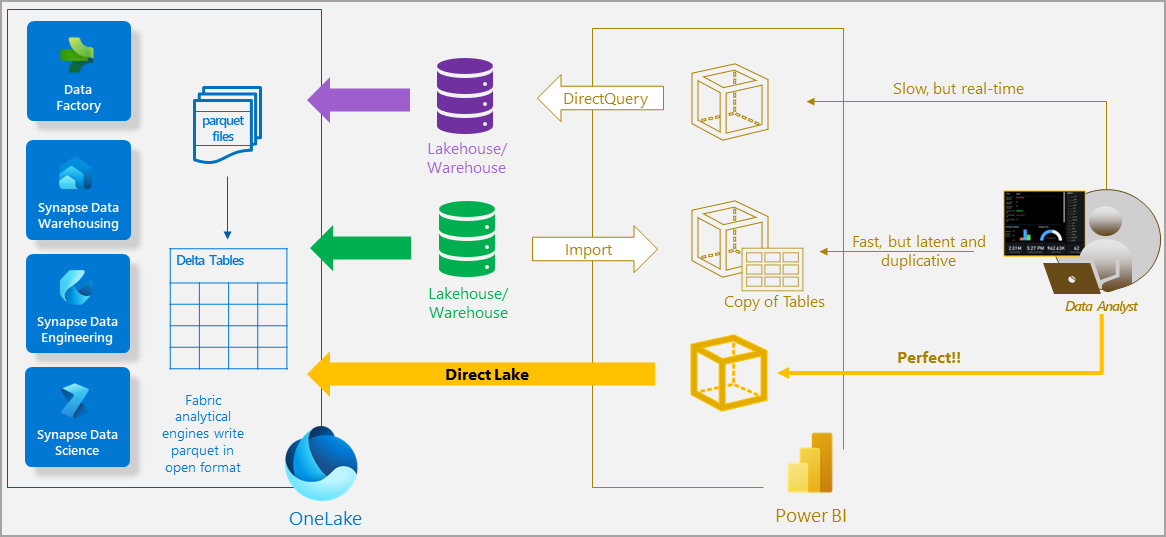
在 DirectQuery 模式下,Power BI 引擎查询源中的数据,虽然速度可能很慢,但不必像导入模式一样复制数据。 数据源上的任何更改都会立即反映在查询结果中。
另一方面,使用导入模式时,性能会更好,因为会缓存数据并针对 DAX 和 MDX 报表查询对其进行优化,而无需将 SQL 或其他类型的查询转换为数据源。 但是,Power BI 引擎必须先在刷新期间将任何新数据复制到模型中。 只有在下次刷新模型时才会选取源中的任何更改。
Direct Lake 模式直接从 OneLake 加载数据,消除了导入需求。 与 DirectQuery 不同,不会将 DAX 或 MDX 转换为其他查询语言,也不会在其他数据库系统上执行查询,从而得到与导入模式类似的性能。 由于没有显式导入过程,因此可在发生任何更改时在数据源中选取这些更改,从而既结合了 DirectQuery 模式和导入模式的优点,又避免了它们的缺点。 Direct Lake 模式是分析超大模型和在数据源中频繁更新的模型的理想选择。
Direct Lake 还支持 行级安全性和对象级安全性,因此用户只能看到他们有权查看的数据。
先决条件
只有 Microsoft Premium (P) SKU 和 Microsoft Fabric (F) SKU 支持 Direct Lake。
重要
对于新客户,Direct Lake 仅在 Microsoft Fabric (F) SKU 上受支持。 现有客户可以继续使用 Direct Lake 和 Premium (P) SKU,但建议过渡到 Fabric 容量 SKU。 有关 Power BI Premium 许可的详细信息,请参阅许可公告。
Lakehouse
在使用 Direct Lake 之前,必须在受支持的 Microsoft Fabric 容量上托管的工作区中预配包含一个或多个增量表的湖屋(或仓库)。 湖屋是必需的,因为它为 OneLake 中的 parquet 格式文件提供存储位置。 湖屋还提供了一个接入点来启动 Web 建模功能,从而创建 Direct Lake 模型。
若要了解如何预配湖屋、在湖屋中创建增量表以及如何为湖屋创建基本模型,请参阅为 Direct Lake 创建湖屋。
SQL 终结点
在预配湖屋的过程中,会创建用于 SQL 查询的 SQL 端点和用于报告的默认模型,并使用添加到湖屋的任何表更新此端点和数据集。 虽然 Direct Lake 模式在直接从 OneLake 加载数据时不会查询 SQL 终结点,但当 Direct Lake 模型必须无缝回退到 DirectQuery 模式时,例如,当数据源使用特定功能(如高级安全性)或无法通过 Direct Lake 读取的视图时,需要查询此终结点。 Direct Lake 模式还会查询 SQL 终结点以获取架构和安全相关信息。
数据仓库
作为带有 SQL 端点的湖屋的替代方法,还可以使用 SQL 语句或数据管道预配仓库并添加表。 预配独立数据仓库的过程与预配湖屋的过程几乎完全相同。
XMLA 终结点的模型写入支持
Direct Lake 模型使用 SQL Server Management Studio(19.1 及更高版本)等工具以及最新版本的外部 BI 工具(如 Tabular Editor 和 DAX 工作室)通过 XMLA 终结点支持写入操作。 通过 XMLA 终结点的模型写入操作支持:
自定义、合并、脚本编写、调试和测试 Direct Lake 模型元数据。
使用 Azure DevOps 和 GitHub 进行源和版本控制、持续集成和持续部署 (CI/CD)。
自动化任务,例如使用 PowerShell 和 REST API 对 Direct Lake 模型刷新和应用更改。
请注意,使用 XMLA 应用程序创建的 Direct Lake 表最初将处于未处理状态,直到应用程序发出刷新命令。 未处理的表回退到 DirectQuery 模式。 在创建新的语义模型时,请确保刷新语义模型以处理表。
启用 XMLA 读写终结点
在通过 XMLA 终结点对 Direct Lake 模型执行写入操作之前,必须为容量启用 XMLA 读写。
对于 Fabric 试用容量,试用用户具有启用 XMLA 读写所需的管理员权限。
在管理门户中,选择“容量设置”。
单击“试用”选项卡。
选择“试用”容量,并在容量名称中选择你的用户名。
展开“Power BI 工作负载”,然后在“XMLA 终结点”设置中选择“读取写入”。
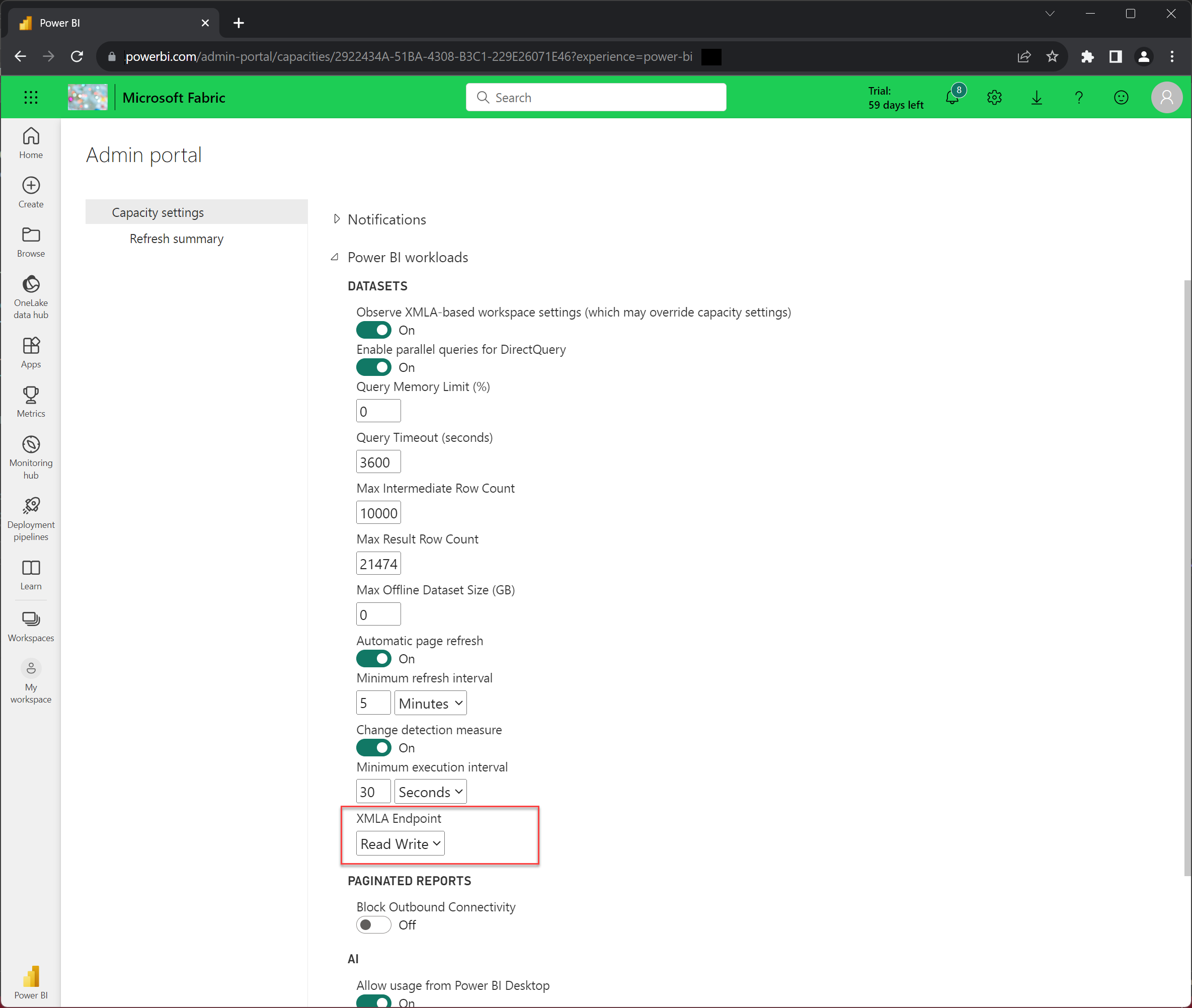
请记住,“XMLA 终结点”设置应用于分配给容量的所有工作区和模型。
Direct Lake 模型元数据
通过 XMLA 终结点连接到独立模型时,元数据看起来就和任何其他模型一样。 但是,Direct Lake 模型具有以下差异:
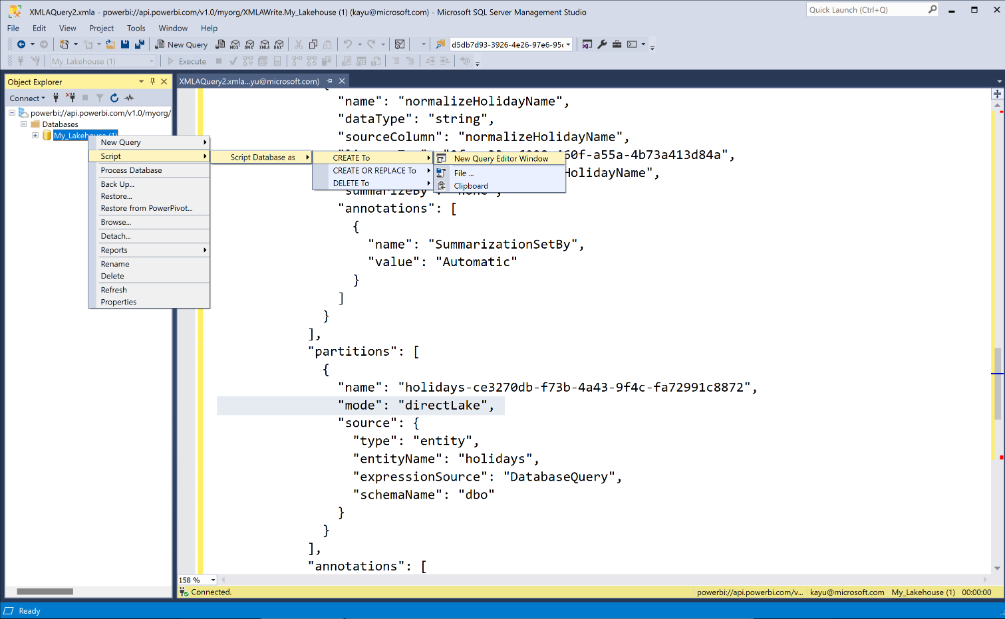
数据库对象的
compatibilityLevel属性为 1604 或更高。Direct Lake 分区的
Mode属性设置为directLake。Direct Lake 分区使用共享表达式来定义数据源。 该表达式指向湖屋或仓库的 SQL 端点。 Direct Lake 使用 SQL 终结点来发现架构和安全信息,但直接从增量表加载数据(除非 Direct Lake 出于任何原因必须回退到 DirectQuery 模式)。
下面是 SSMS 中的 XMLA 查询示例:
若要详细了解通过 XMLA 终结点的工具支持,请参阅语义模型与 XMLA 终结点的连接。
回退
Direct Lake 模式下的 Power BI 语义模型直接从 OneLake 读取增量表。 但是,如果 Direct Lake 模型中的 DAX 查询超出了 SKU 的限制,或者使用不支持 Direct Lake 模式的功能(如仓库中的 SQL 视图),则查询可以回退到 DirectQuery 模式。 在 DirectQuery 模式下,查询使用 SQL 从湖屋或仓库的 SQL 端点检索结果,这可能会影响查询性能。 如果只想在纯 Direct Lake 模式下处理 DAX 查询,则可以禁用回退到 DirectQuery 模式。 如果不需要回退到 DirectQuery,建议禁用回退。 在分析 Direct Lake 模型的查询处理以确定是否回退和回退的频率时,它还非常有用。 若要了解有关 DirectQuery 模式的详细信息,请参阅 Power BI 中的语义模型模式。
Guardrails 定义 Direct Lake 模式的资源限制,超出此限制需要回退到 DirectQuery 模式来处理 DAX 查询。 有关如何确定增量表的 parquet 文件和行组数的详细信息,请参阅增量表属性引用。
对于 Direct Lake 语义模型,最大内存表示可分页数据的内存上限资源限制。 实际上,它不是一个护栏,因为超过它不会导致 DirectQuery 回退;然而,如果数据量大到足以导致 OneLake 数据中模型数据的分页进出,则可能会对性能产生影响。
下表列出了资源防护栏和最大内存:
| Fabric SKU | 每个表的 Parquet 文件数 | 每个表的行组 | 每个表的行数(百万) | 磁盘/OneLake 上的最大模型大小1 (GB) | 最大内存 (GB) |
|---|---|---|---|---|---|
| F2 | 1,000 | 1,000 | 300 | 10 | 3 |
| F4 | 1,000 | 1,000 | 300 | 10 | 3 |
| F8 | 1,000 | 1,000 | 300 | 10 | 3 |
| F16 | 1,000 | 1,000 | 300 | 20 | 5 |
| F32 | 1,000 | 1,000 | 300 | 40 | 10 |
| F64/FT1/P1 | 5,000 | 5,000 | 1,500 | 无限制 | 25 |
| F128/P2 | 5,000 | 5,000 | 3,000 | 无限制 | 50 |
| F256/P3 | 5,000 | 5,000 | 6,000 | 无限制 | 100 |
| F512/P4 | 10,000 | 10,000 | 12,000 | 无限制 | 200 |
| F1024/P5 | 10,000 | 10,000 | 24,000 | 无限制 | 400 |
| F2048 | 10,000 | 10,000 | 24,000 | 无限制 | 400 |
1 - 如果超出,磁盘/Onelake 上的最大模型大小将导致模型的所有查询回退到 DirectQuery,这不同于针对每个查询评估的其他防护措施。
根据 Fabric SKU,其他“容量单位”和“每个查询的最大内存数”限制也适用于 Direct Lake 模型。 若要了解详细信息,请参阅容量和 SKU。
回退行为
Direct Lake 模型包括 DirectLakeBehavior 属性,该属性有三个选项:
自动 -(默认值)指定如果无法有效地将数据加载到内存中,则查询回退到 DirectQuery 模式。
DirectLakeOnly - 指定所有查询仅使用 Direct Lake 模式。 已禁用回退到 DirectQuery 模式。 如果无法将数据加载到内存中,则返回错误。 使用此设置可确定 DAX 查询是否无法将数据加载到内存中,从而强制返回错误。
DirectQueryOnly - 指定所有查询仅使用 DirectQuery 模式。 使用此设置测试回退性能。
可以使用表格对象模型 (TOM) 或表格模型脚本语言 (TMSL) 配置 DirectLakeBehavior 属性。
以下示例指定所有查询仅使用 Direct Lake 模式:
// Disable fallback to DirectQuery mode.
//
database.Model.DirectLakeBehavior = DirectLakeBehavior.DirectLakeOnly = 1;
database.Model.SaveChanges();
分析查询处理
若要确定报表视觉对象对数据源的 DAX 查询是通过使用 Direct Lake 模式还是回退到 DirectQuery 模式来提供最佳性能,可以使用 Power BI Desktop 中的性能分析器、SQL Server Profiler 或其他第三方工具来分析查询。 若要了解详细信息,请参阅如何分析 Direct Lake 模型的查询处理。
刷新
默认情况下,OneLake 中的数据更改会自动反映在 Direct Lake 模型中。 可以通过在模型的设置中禁用“使 Direct Lake 数据保持最新”来更改此行为。

例如,如果在向模型使用者公开任何新数据之前需要允许完成数据准备作业,则可能需要禁用。 禁用后,可以手动或使用刷新 API 调用刷新。 调用 Direct Lake 模型刷新是一种低成本操作,其中模型会分析最新版 Delta Lake 表的元数据,并更新为引用 OneLake 中的最新文件。
请注意,如果刷新期间遇到不可恢复的错误,则 Power BI 可以暂停 Direct Lake 表的自动更新,因此请确保语义模型可以成功刷新。 当后续用户调用的刷新无错完成时,Power BI 会自动恢复自动更新。
分层数据访问安全
在湖屋和仓库之上创建的 Direct Lake 模型遵循湖屋和仓库支持的分层安全模型:通过 T-SQL 端点执行权限检查,以确定尝试访问数据的标识是否具有所需的数据访问权限。 默认情况下,Direct Lake 模型使用单一登录 (SSO),因此交互式用户的有效权限决定了系统是允许还是拒绝用户访问数据。 如果 Direct Lake 模型配置为使用固定标识,则固定标识的有效权限决定了与语义模型交互的用户是否可以访问数据。 T-SQL 终结点根据 OneLake 安全性和 SQL 权限的组合向 Direct Lake 模型返回“允许”或“拒绝”。
例如,仓库管理员可以授予用户对表的 SELECT 权限,以便用户可以从该表中读取数据,即使该用户没有 OneLake 安全权限。 用户已在湖屋/仓库级别获得授权。 与之相反,仓库管理员也可以拒绝用户对表的读取访问权限。 这样一来,即使用户具有 OneLake 安全读取权限,用户也将无法从该表中读取数据。 DENY 语句会否决任何授予的 OneLake 安全权限或 SQL 权限。 请参阅下表,了解在以 OneLake 安全权限和 SQL 权限的任意组合向用户授权的情况下用户可以拥有的有效权限。
| OneLake 安全权限 | SQL 权限 | 有效权限 |
|---|---|---|
| Allow | 无 | Allow |
| 无 | 允许 | Allow |
| 允许 | 拒绝 | 拒绝 |
| 无 | 拒绝 | 拒绝 |
已知问题和限制
根据设计,只有从湖屋或仓库中的表派生的语义模型中的表才支持 Direct Lake 模式。 尽管模型中的表可以从湖屋或仓库中的 SQL 视图派生,但使用这些表的查询将回退到 DirectQuery 模式。
Direct Lake 语义模型表只能派生自单个湖屋或仓库的表和视图。
Direct Lake 表当前不能与同一模型中的其他表类型(如 Import、DirectQuery 或 Dual)混合使用。 当前不支持复合模型。
Direct Lake 模型不支持 DateTime 关系。
不支持计算列和计算表。
某些数据类型可能不受支持,例如高精度小数和付款类型。
Direct Lake 表不支持复杂的增量表列类型。 二进制和 Guid 语义类型也不受支持。 必须将这些数据类型转换为字符串或其他受支持的数据类型。
表关系要求其键列的数据类型一致。 主键列必须包含唯一值。 如果检测到重复的主键值,DAX 查询将失败。
字符串列值的长度限制为 32,764 个 Unicode 字符。
Direct Lake 模型不支持浮点值“NaN”(非数值)。
尚不支持依赖于嵌入实体的嵌入式应用场景。
Direct Lake 模型的验证是受限的。 用户选择被假定正确,并且任何查询不会验证关系或日期表中所选日期列的基数和交叉筛选器选择。
刷新历史记录中的 Direct Lake 选项卡仅列出与 Direct Lake 有关的刷新失败。 当前省略了成功的刷新。
开始使用
在组织中开始使用 Direct Lake 解决方案的最佳方式是创建湖屋、在其中创建增量,然后在 Microsoft Fabric 工作区中创建湖屋的基本语义模型。 若要了解详细信息,请参阅为 Direct Lake 创建湖屋。
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈