在边缘模式中训练机器学习模型
从仅存在于本地的数据生成可移植机器学习 (ML) 模型。
上下文和问题
许多组织希望使用其数据科学家了解的工具从其本地或旧数据中获得见解。 Azure 机器学习提供云原生工具来训练、调整和部署 ML 和深度学习模型。
但是,有些数据由于过大或出于监管原因,无法发送到云。 使用此模式,数据科学家可以使用 Azure 机器学习通过本地数据和计算来训练模型。
解决方案
在边缘模式下,训练使用在 Azure Stack Hub 上运行的虚拟机 (VM)。 VM 在 Azure ML 中注册为计算目标,使其能够访问仅在本地可用的数据。 在这种情况下,数据存储在 Azure Stack Hub 的 blob 存储中。
模型经过训练后,将在 Azure ML 中注册、进行容器化并添加到 Azure 容器注册表以进行部署。 对于此模式迭代,Azure Stack Hub 训练 VM 必须可通过公共 Internet 访问。
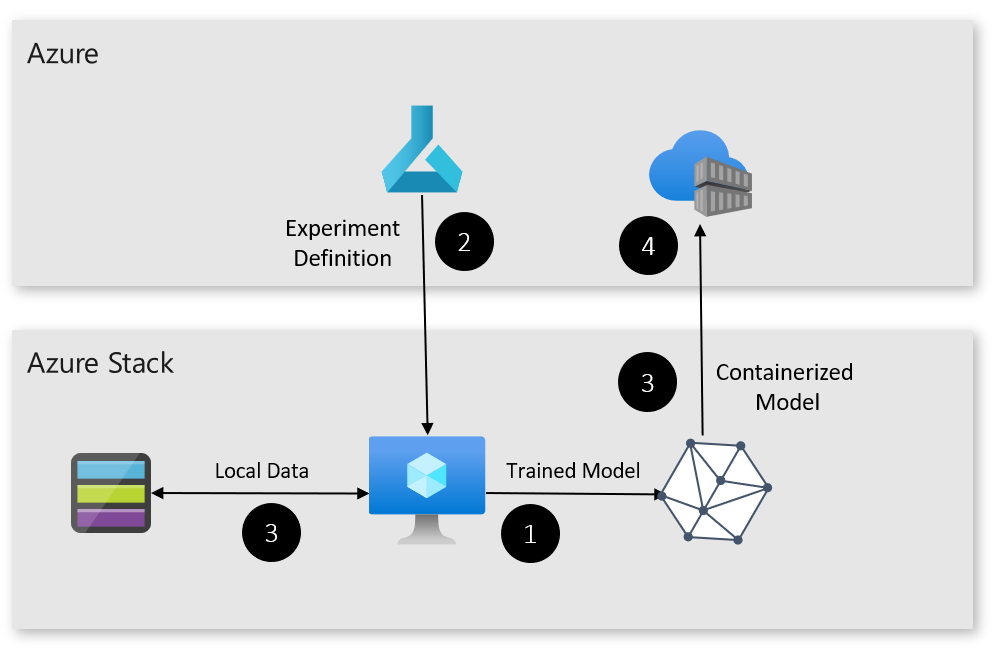
下面是该模式的工作原理:
- Azure Stack Hub VM 已部署并注册为 Azure ML 中的计算目标。
- 在 Azure ML 中创建了一个试验,该试验使用 Azure Stack Hub VM 作为计算目标。
- 模型经过训练后,它会进行注册和容器化。
- 现在可以将该模型部署到本地或云中的相应位置。
组件
此解决方案使用以下组件:
| 层 | 组件 | 说明 |
|---|---|---|
| Azure | Azure 机器学习 | Azure 机器学习可以协调 ML 模型的训练。 |
| Azure 容器注册表 | Azure ML 将模型打包到容器中,并将其存储在 Azure 容器注册表中以进行部署。 | |
| Azure Stack Hub | 应用服务 | 使用应用服务的 Azure Stack Hub 为边缘的组件提供基础映像。 |
| 计算 | 运行 Ubuntu 和 Docker 的 Azure Stack Hub VM 用于训练 ML 模型。 | |
| 存储 | 专用数据可以托管在 Azure Stack Hub blob 存储中。 |
问题和注意事项
在决定如何实现此解决方案时,请考虑以下几点:
可伸缩性
为使此解决方案能够进行缩放,你需要在 Azure Stack Hub 上创建一个适当大小的 VM 以进行训练。
可用性
确保训练脚本和 Azure Stack Hub VM 可以访问用于训练的本地数据。
可管理性
确保模型和试验进行了适当的注册、版本控制和标记,以避免在模型部署过程中产生混淆。
安全
此模式允许 Azure ML 访问本地可能的敏感数据。 确保用于通过 SSH 连接到 Azure Stack Hub VM 的帐户具有强密码,并且训练脚本不会将数据保存或上传到云。
后续步骤
若要详细了解本文中介绍的主题:
- 有关 ML 和相关主题的概述,请参阅 Azure 机器学习文档。
- 若要了解如何为容器部署构建、存储和管理映像,请参阅 Azure 容器注册表。
- 若要了解有关资源提供程序以及如何部署的详细信息,请参阅 Azure Stack Hub 上的应用服务。
- 若要了解有关最佳做法以及解答任何其他问题的详细信息,请参阅混合应用程序设计注意事项。
- 请参阅 Azure Stack 产品和解决方案系列,详细了解产品和解决方案的整个阵容。
准备好测试解决方案示例后,请继续查看 在边缘训练 ML 模型部署指南。 该部署指南逐步说明了如何部署和测试 Azure Stack 的组件。