对数据进行分类
在线零售业务有不同类型的数据。 不同类型的数据可能从不同的存储解决方案中受益。
应用程序数据可以归为下述三种类型之一:结构化、半结构化和非结构化。 这里介绍如何将数据归类,以便根据数据类型选择适当的存储解决方案。
在云中存储数据的方法
以下视频介绍了在云中存储数据的选项:
结构化数据
在结构化数据(有时称为关系数据)中,所有数据具有相同的字段或属性。 所有数据具有相同的组织形式和形状或架构。 共享架构允许使用结构化查询语言 (SQL) 等查询语言轻松搜索此类数据。 此功能使这种数据样式非常适合 CRM 系统、预留和库存管理等应用程序。
结构化数据通常存储在包含行、列的数据库表中。 在表中,键列指示表中的一行如何与另一个表的另一行中的数据相关。 在下图中,包含成绩相关数据的表使用键列从学生姓名表和课堂数据表中获取数据。
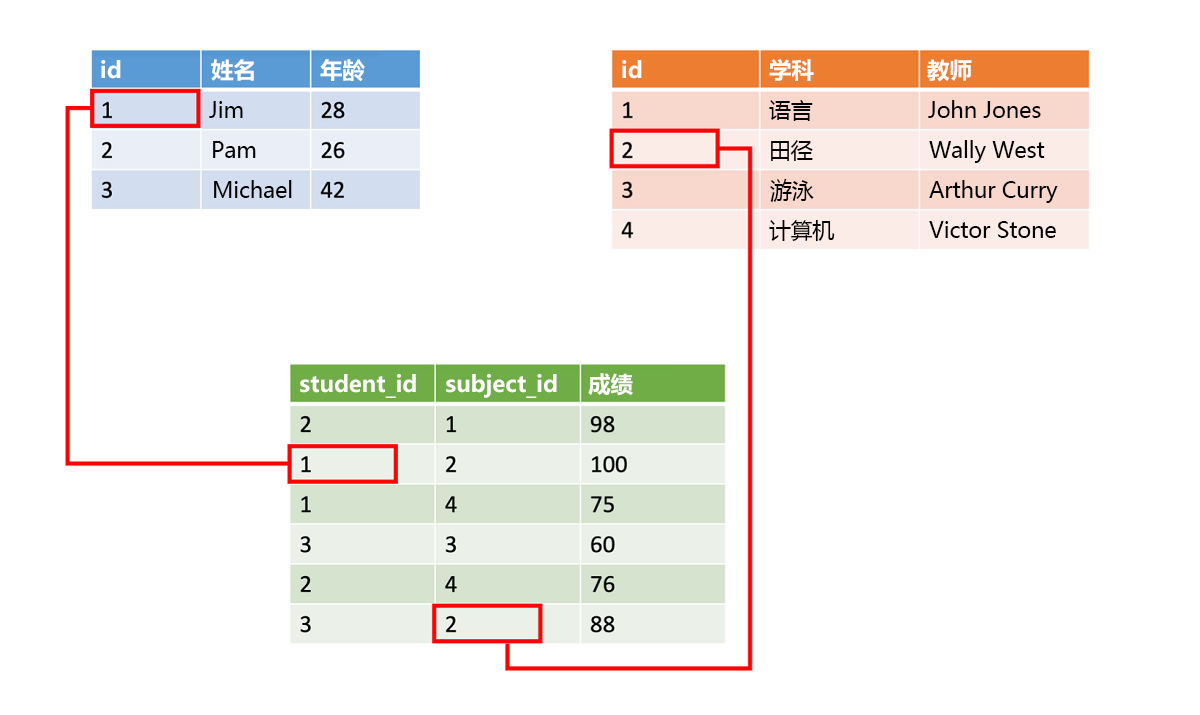
结构化数据很简单,易于输入、查询和分析。 所有数据采用相同格式。 但强制采用一致的结构也意味着数据演变会更加困难。 当添加或删除数据字段时,必须更新每个记录来符合新的结构。
半结构化数据
半结构化数据不及结构化数据有序。 半结构化数据不以关系格式存储,因为字段不太适合放入表格、行和列。 半结构化数据包含标记,这突显了数据的组织和层次结构。 例如键/值对。 半结构化数据也称为非关系数据或“不仅是 SQL”(NoSQL) 数据。
半结构数据由数据序列化语言定义。 在数据分类中,序列化是将数据转换为可传输或存储的格式的过程。
软件开发人员使用数据序列化语言将存储在内存中的数据写入文件,然后可将其发送到其他系统进行分析和读取。 发送方和接收方无需知道有关其他系统的详细信息。 只要使用同样的序列化语言,这两个系统便可以理解数据。
通用序列化语言
三种常见的序列化语言是 XML、JSON 和 YAML。
XML
可扩展标记语言 (XML) 是首批广泛使用的数据语言之一。 XML 基于文本,这使得它很容易被人和机器读取。 XML 分析器几乎适用于所有常用开发平台。
可以使用 XML 来表示关系。 XML 具有架构、转换甚至在 Web 上显示的标准。
以下示例用 XML 表示一个人的姓名、年龄和爱好:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML 通过使用在尖括号内定义的标记来表示数据的形状。 这些标记有两种形式:元素(如 <FirstName>)和属性(可以用类似 Age="23" 的文本表示)。 元素可以有子元素来表达关系。 例如,<Hobbies> 标记表示 Hobby 元素的集合。
XML 非常灵活,可以轻松表达复杂数据。 但是,它往往更加冗长,从而使存储、处理或通过网络传递的内容更多。 因此,其他格式变得更加热门。
JSON
JavaScript Object Notation (JSON) 具有轻型规范,并使用大括号来表示数据结构。 JSON 没有 XML 那么冗长,且更易于阅读。 Web 服务经常使用 JSON 返回数据。
以下示例使用 JSON 表示同一个人的姓名、年龄和爱好:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
JSON 格式与 XML 格式不一样。 它比正式的数据表达式更接近键/值对模型。 顾名思义,JavaScript 编程语言内置了对此格式的支持,这使得它在 Web 开发中非常受欢迎。 与 XML 一样,其他语言也有可用于处理此数据格式的分析程序。 JSON 的缺点是它更倾向于面向程序员,使得非技术人员更难以阅读和修改。
YAML
YAML Ain’t 标记语言 (YAML) 是最近开发的数据序列化语言。 比起其他语言,使用 YAML 的一个好处是更便于人类阅读。 数据结构由分行和缩进定义。 YAML 格式减少了对结构化字符(如圆括号、逗号和方括号)的依赖。
下面是以 YAML 表示的相同数据:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
这种格式比 JSON 更具可读性,通常用于需要由人编写但由程序分析的配置文件。 YAML 在这些数据格式中是最新的。
什么是半结构化数据或 NoSQL 数据?
以下视频介绍半结构化数据和 NoSQL 数据存储选项:
非结构化数据
非结构化数据的组织结构未定义。 非结构化数据通常以文件格式提供,例如照片文件或视频文件。 视频文件本身可能具有整体结构且包含半结构化元数据,但是构成视频本身的数据是非结构化数据。 因此,将照片、视频和其他类似文件归类为非结构化数据。
非结构化数据示例包括:
- 媒体文件(如照片、视频和音频文件)
- Microsoft 365 文件(如 Word 文档)
- 文本文件
- 日志文件
数据分类:评估数据类型
数据可以归为下述三种类型:结构化、半结构化和非结构化。 了解这些差异才能对数据分类,这样有助于选择正确的存储解决方案。
结构化数据有序整理,非常适合放入表或数据列。 半结构化数据也具有组织性且有明确的属性和值,但数据存在多样性。 半结构化数据不太适合放入表或列,它没有统一的架构。
让我们看看在线零售业务中使用的数据集并将其分类。
产品目录数据
在线零售业务的产品目录数据本质上是半结构化数据。 每个产品都有产品 SKU、说明、数量、价格、尺寸选项、颜色选项、图片并且可能还有视频。 因此,这些数据最初似乎具有相关性,因为它们都具有相同的结构。 但在推出新产品或不同类型的产品时,可能需要添加数据字段。 例如,推出的新网球鞋支持蓝牙,可以将传感器数据从鞋传送到用户手机上的健身应用。 这种趋势日益上升,你希望能够让客户筛选“支持蓝牙”的鞋子。 你不想更新所有现有的鞋子数据以添加支持蓝牙属性。 只想在新鞋中添加这个新属性。
添加支持蓝牙属性后,鞋类数据不再是同源数据。 在架构中引入了差异。 如果这个更改是你预计会遇到的唯一例外,则可将现有数据标准化,使所有产品都包含“支持蓝牙”字段,维持结构化的关系组织形式。 但是,如果这只是你预计未来需要提供支持的众多特性字段之一,则将数据归为半结构化类型。 数据按标记组织,但目录中的每个产品都可包含唯一字段。
产品目录数据的类型是半结构化。
照片和视频
产品页面上显示的照片和视频是非结构化数据。 尽管媒体文件可能包含元数据,但媒体文件的正文是非结构化的。
照片和视频的数据类型是非结构化。
业务数据
业务分析师希望实现商业智能,以计算库存管道和查看销售数据。 若要执行这些操作,需要将多个月的数据聚合在一起,然后进行查询。 由于需要聚合类似数据,因此必须对这些数据进行结构化处理,以便将一个月的数据与下个月的进行比较。
业务数据的类型是结构化。