在 Power BI 中应用见解来发现分布的不同之处
适用范围:![]() Power BI Desktop
Power BI Desktop ![]() Power BI 服务
Power BI 服务
在视觉对象中,你通常会看到一个数据点,并想知道不同类别的分布是否相同。 借助“Power BI”中的“见解”,只需单击几下即可了解。
以下面的视觉对象为例,它显示了按国家/地区名称划分的总销售额。 大部分销售额来自美国,占所有销售额的 57%,余下的销售额则来自其他国家/地区。 在这种情况下,探索是否会在不同的亚群中看到与之相同的分布通常很有趣。 例如,所有年份、所有销售渠道和所有产品类别的分布是否与之相同? 虽然可以应用不同的筛选器并直观地比较结果,但这样做可能非常耗时且容易出错。
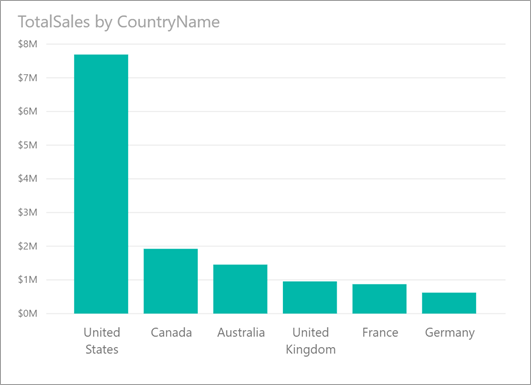
可以使用 Power BI 找出分布的不同之处,并获得有关数据的快速、自动化且深入的分析。 右键单击数据点,然后依次选择“分析”>“发现分布的不同之处”,可以在易用窗口中收到见解。
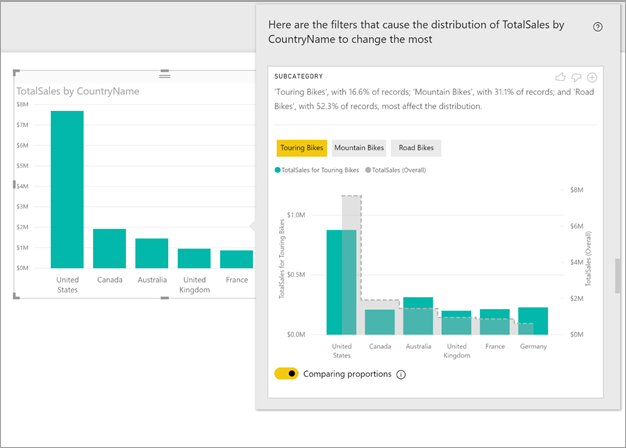
在此示例中,自动化分析显示,美国和加拿大的旅行车销售额比例低于其他国家/地区的比例。
使用见解
若要使用见解来发现图表中显示的分布不同之处,只需右键单击任意数据点或整个视觉对象。 然后依次选择“分析”>“发现此分布的不同之处”。
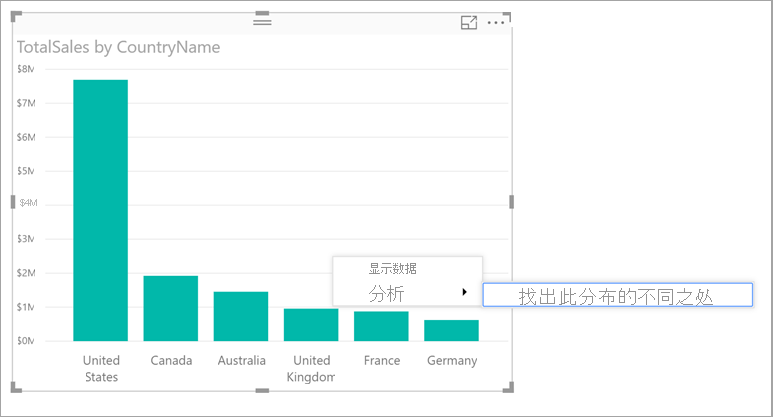
Power BI 对数据运行其机器学习算法。 然后,Power BI 使用视觉对象和说明填充窗口,描述哪些类别(列)以及这些类别的哪些值导致差异最明显的分布。 见解以柱形图形式提供,如下图所示:
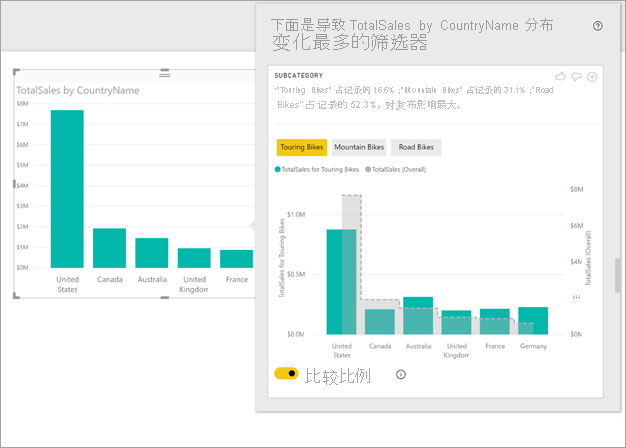
应用了选定筛选器的值具有默认颜色。 原始起始视觉对象上所示的总体值以灰色显示,以便进行比较。 最多可包含三个不同的筛选器(此示例中为“旅行车”、“山地车”、“公路车”),可通过选择数据点来选择不同的筛选器(或按下 Ctrl 并单击来选择多个筛选器)。
对于简单的累加性度量值,例如此示例中的总销售额,将根据相对值而非绝对值进行比较。 虽然旅行车的销售额低于所有类别的总销售额,但默认情况下,视觉对象使用双轴来比较不同国家/地区的销售额比例。 这适用于旅行车与所有类别的自行车的比较。 通过切换视觉对象下方的切换按钮,可在同一轴上显示两个值,从而可以轻松地比较绝对值,如下图所示:
通过给定与筛选器匹配的记录数,描述性文本还指示了可能附加到筛选器值的重要性级别。 在此示例中可以看到,虽然旅行车的分布可能不同,但它们只占记录数的 16.6%。
页面顶部有“很棒”和“很差”图标,你可以提供关于视觉对象和功能的反馈。 不过,这样做目前不会训练算法来影响下次使用该功能时返回的结果。
请注意,视觉对象顶部的 + 按钮可让你将选定的视觉对象添加到报表中,就像你手动创建视觉对象一样。 然后,可以格式化或调整添加的视觉对象,类似于在报表上对任何其他视觉对象执行的操作。 在 Power BI 中编辑报表时,只能添加选定的见解视觉对象。
如果报表处于阅读或编辑模式,则可以使用见解。 这可以将它用于分析数据和创建可添加到报表中的视觉对象。
返回结果的详细信息
可以将算法设想为采用模型中的所有其他列,将这些列的所有值作为筛选器应用于原始视觉对象。 然后,算法会找出其中哪个筛选器值生成的结果与原始视觉对象的差异最大。
你可能想知道差异 表示的意义。 例如,假设美国与加拿大的销售额总体分配如下:
| 国家/地区 | 销售额(百万美元) |
|---|---|
| 美国 | 15 |
| 加拿大 | 5 |
而对于特定类别的产品“公路车”,销售额分配可能为:
| 国家/地区 | 销售额(百万美元) |
|---|---|
| 美国 | 3 |
| 加拿大 | 1 |
虽然各个表中的数字不同,但美国与加拿大的相对值是相同的:总体为 75% 和 25%,公路车也为 75% 和 25%。 因此,并不将它们视为不同。 对于这种简单的累加性度量值,算法会查找相对值的差异。
与此相反,考虑利润率这样的度量值,计算公式为利润/成本。 如果美国和加拿大的总利润率如下:
| 国家/地区 | 利润率 (%) |
|---|---|
| 美国 | 15 |
| 加拿大 | 5 |
而对于特定类别的产品“公路车”,销售额分配可能为:
| 国家/地区 | 利润率 (%) |
|---|---|
| 美国 | 3 |
| 加拿大 | 1 |
鉴于此类度量值的性质,这些数字是不同且有趣的。 对于非累加性度量值,比如此利润率示例,算法会查找绝对值的差异。
因此,所显示的视觉对象旨在显示在整体分布(如原始视觉对象中所示)与应用了特定筛选器的值之间找到的差异。
对于累加性度量值,如上一示例中的“销售额”,应使用行列图。 图中采用双轴和适当的缩放比例,以便比较相对值。 列显示应用了筛选器的值,行显示总体值。 正常情况下,列轴位于左侧,行轴位于右侧。 行以阶梯 样式显示,虚线用灰色填充。 对于上一个示例,如果列轴最大值为 4,行轴最大值为 20,那么它将允许轻松比较美国与加拿大的筛选值和总体值的相对值。
同样,对于非累加性度量值,如上一示例中的利润率,应使用行列图,图中采用单轴,这意味着可以轻松地比较绝对值。 行(用灰色填充)显示总体值。 无论是比较实际数字还是相对数字,确定两种分布的差异程度不仅仅是计算值之间的差异的问题。 例如:
将群体规模考虑在内时,因为占总群体的比例越小,差异在统计上就越不显著,也越无意义。 例如,对于某个特定产品,不同国家/地区的销售额分布可能有所不同。 如果有数千种产品,而该特定产品仅占总销售额的一小部分,那么其销售额分布差异就毫无意义。
原始值很高或很接近于零的那些类别的差异的权重高于其他类别。 例如,如果某个国家或地区的总体贡献仅占销售额的 1%,但对某个特定类型的产品的贡献率为 6%,那么,相比贡献率从 50% 变为 55% 的国家或地区,其差异在统计上更显著,因此更有趣。
各种启发法选择最有意义的结果,例如通过考虑数据之间的其他关系。
在检查完各个列以及这些列的值之后,选择提供最大差异的值集。 为了便于理解,随后按列输出这些列/值,其值提供最大差异的列最先列出。 每列最多显示三个值,但如果具有较大影响的值少于三个,或者某些值的影响力远高于其他值,则可能会显示更少的值。
不一定会在可用时间内检查模型中的所有列,因此不保证显示影响最大的列和值。 但是,各种启发法可以确保首先检查最有可能的列。 例如,假设在检查完所有列之后,确定以下列/值对分布的影响最大(影响力从大到小):
Subcategory = Touring Bikes
Channel = Direct
Subcategory = Mountain Bikes
Subcategory = Road Bikes
Subcategory = Kids Bikes
Channel = Store
将按列顺序输出这些列/值,如下所示:
子类别:Touring Bikes、Mountain Bikes、Road Bikes(仅列出三个,包含“...amongst others”的文本表示三个以上的列/值具有重大影响力)
Channel = Direct(仅列出 Direct,如果其影响程度大于 Store)
注意事项和限制
以下列表列出了见解目前不受支持的所有情形:
- 前 n 个筛选器
- 度量值筛选器
- 非数值度量值
- 使用“值显示为”
- 筛选后的度量值:筛选后的度量值是指应用了特定筛选器的视觉对象级计算(例如法国总销售额),用于见解功能创建的某些视觉对象
此外,目前不支持见解的以下模型类型和数据源:
- 直接连接
- 实时连接
- 本地 Reporting Services
- 嵌入
相关内容
有关详细信息,请参阅: