自动聚合
自动聚合使用最先进的机器学习 (ML) 来持续优化 DirectQuery 语义模型,以获得最佳报表查询性能。 自动聚合建立在现有用户定义的聚合基础架构之上,该架构最初是随 Power BI 的复合模型一起引入的。 与用户定义的聚合不同,自动聚合不需要大量数据建模和查询优化技能就能进行配置和维护。 自动聚合既能自行训练,又能自行优化。 它们使得任何技能水平的模型所有者都能提高查询性能,大型模型也能更快直观呈现报表。
自动聚合有以下优点:
- 更快提供报表可视化效果 - 由自动维护的内存中聚合缓存(而不是后端数据源系统)返回最佳百分比的报表查询。 不能由内存中缓存返回的离群值查询通过 DirectQuery 直接传递到数据源。
- 均衡体系结构 - 与纯 DirectQuery 模式相比,大多数查询结果由 Power BI 查询引擎和内存中聚合缓存返回。 在报告高峰时段,可大幅降低数据源系统上的查询处理负载,这意味着增加数据源后端的可伸缩性。
- 设置简单 - 模型所有者可启用自动聚合训练,并计划一次或多次模型刷新。 第一次训练和刷新后,自动聚合将开始创建聚合框架和最佳聚合。 系统会随时间自动优化。
- 微调 - 通过模型设置中简单直观的用户界面,可以估计从内存中聚合缓存返回的不同百分比的查询的性能增益,并进行调整以获得更大的提升。 使用单个滑动条控件就可根据环境轻松微调。
要求
支持的计划
Power BI Premium Per Capacity、Premium Per User 和 Power BI Embedded 模型支持自动聚合。
支持的数据源
下列数据源支持自动聚合:
- Azure SQL Database
- Azure Synapse 专用 SQL 池
- SQL Server 2019 或更高版本
- Google BigQuery
- Snowflake
- Databricks
- Amazon Redshift
支持的模式
DirectQuery 模式模型支持自动聚合。 同时支持导入表和 DirectQuery 连接的复合模型。 仅 DirectQuery 连接支持自动聚合。
权限
只有模型所有者才能启用和配置自动聚合。 工作区管理员可以以所有者身份进行接管来配置自动聚合设置。
配置自动聚合
自动聚合是在模型的“设置”中配置的。 配置非常简单 - 启用自动聚合训练并计划一次或多次刷新即可。 在为模型配置自动聚合之前,请务必通读本文。 它充分介绍了自动聚合的工作原理,可帮助你确定自动聚合是否适合你的环境。 有分步说明讲解如何启用自动聚合训练、配置刷新计划和根据环境进行微调。如果你已准备好按照说明操作,请参阅配置自动聚合。
好处
使用 DirectQuery 时,每当模型用户打开报表或与报表可视化效果交互时,数据分析表达式 (DAX) 查询都会传递到查询引擎,然后作为 SQL 查询传递到后端数据源。 数据源必须计算并返回每个查询的结果。 与存储在内存中的导入模式模型相比,DirectQuery 数据源往返过程可能会耗费大量时间且使用大量进程,这通常会拖慢报表可视化效果中的查询响应。
为 DirectQuery 模型启用后,自动聚合可通过避免数据源查询往返来提高报表查询性能。 内存中聚合缓存会自动返回预先聚合的查询结果,而不是将结果发送到数据源,再由数据源返回。 内存中聚合缓存中预先聚合的数据量只是数据源处事实数据表和详细信息表中保存的数据量的一小部分。 结果不仅能提升报表查询性能,还减少了后端数据源系统上的负载。 使用自动聚合时,只有需要内存中缓存未包含的聚合的一小部分报表和即席查询会传递到后端数据源,就像使用纯 DirectQuery 模式一样。

自动查询和聚合管理
尽管自动聚合使得无需创建用户定义的聚合表,极大地简化了实现预聚合数据解决方案的过程,但更深入地了解基础进程和依赖关系有助于理解自动聚合的工作原理。 Power BI 依赖以下项来创建和管理自动聚合。
查询日志
Power BI 在查询日志中跟踪模型和用户报表查询。 对于每个模型,Power BI 都会维护 7 天的查询日志数据。 查询日志数据每天都会前滚。 查询日志受到保护,并对用户不可见或不可通过 XMLA 终结点查看。
训练操作
在所选频率(日或周)的第一个计划模型刷新操作中,Power BI 首先会启动一个训练操作,对查询日志进行评估以确保内存中聚合缓存中的聚合适应不断更改的查询模式。 将创建、更新或删除内存中聚合表,并向数据源发送特殊查询以确定缓存中要包括的聚合。 但在训练期间,计算的聚合数据不会加载到内存中缓存内,而是在后续的刷新操作过程中加载。
例如,如果选择的频率为每日并计划在凌晨 4:00、上午 9:00、下午 2:00 和晚上 7:00 刷新,则只有每天凌晨 4:00 的刷新将同时包含训练操作和刷新操作。 当天随后的上午 9:00、下午 2:00 和晚上 7:00 的计划刷新只会进行刷新,用于更新缓存中的现有聚合。
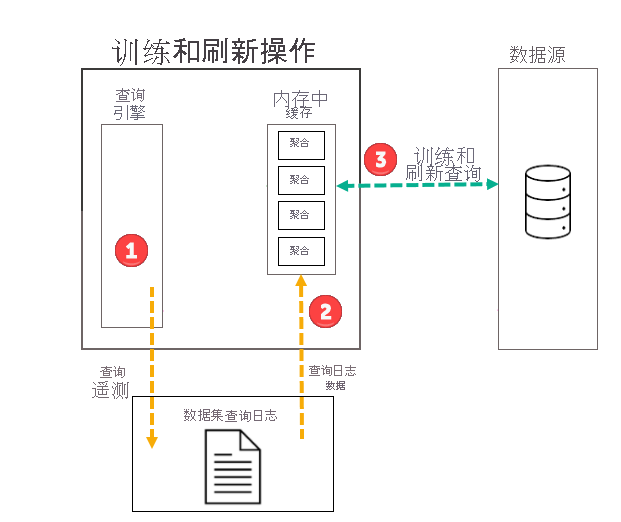
虽然训练操作通过查询日志评估过去的查询,但结果足够准确可确保涵盖未来的查询。 但是,不能保证将来的查询将由内存中聚合缓存返回,因为这些新查询可能与从查询日志派生的查询不同。 内存中聚合缓存未返回的查询会使用 DirectQuery 传递到数据源。 根据这些新查询的频率和排名,查询的聚合可能会在下一次训练操作中包括在内存中聚合缓存内。
训练操作的时间限制为 60 分钟。 如果训练无法在时间限制内处理整个查询日志,则会在模型刷新历史记录中记录一条通知,并在下次启动时恢复训练。 训练周期完成,并在处理整个查询日志时替换现有的自动聚合。
刷新操作
如前所述,在所选频率的首次计划刷新期间完成训练操作后,Power BI 会执行刷新操作,来查询新的和更新的聚合数据和将它们加载到内存中聚合缓存内,并删除任何排名不再靠前的聚合(由训练算法决定)。 选择的日或周频率的所有后续刷新都只会刷新,用于查询数据源以更新缓存中现有的聚合数据。 通过使用前面的示例,当天上午 9:00、下午 2:00 和晚上 7:00 的计划刷新仅为刷新操作。
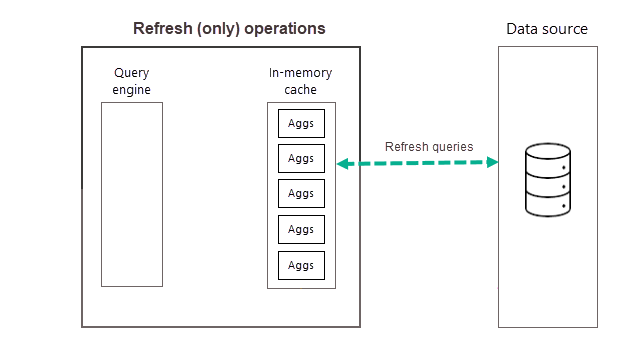
全天(或整周)定期计划刷新可确保缓存中的聚合数据与后端数据源中的数据更加一致。 在模型的“设置”中,可计划每天最多 48 次刷新,以确保聚合缓存返回的报表查询基于后端数据源中的最新刷新数据获得结果。
注意
对于 Power BI 服务和数据源系统来说,训练和刷新操作会使用大量进程和资源。 增加使用聚合的查询百分比意味着在训练和刷新操作期间必须从数据源查询和计算更多的聚合,从而增加了过度使用系统资源的可能性并可能导致超时。 要了解详细信息,请参阅微调。
按需训练
如前所述,训练周期可能无法在单个数据刷新周期的时间限制内完成。 如果不想等到下一个计划刷新周期(包括训练),还可以通过选择模型“设置”中的“立即训练和刷新”来按需触发自动聚合训练。 使用“立即训练和刷新”时,会同时触发训练操作和刷新操作。 检查模型刷新历史记录,如有必要,在运行其他按需训练和刷新操作之前,查看当前操作是否已完成。
刷新历史记录
每次刷新操作都记录在模型刷新历史记录中。 此处会显示有关每次刷新的重要信息,其中包括缓存中为配置的查询百分比消耗的内存聚合量。 若要查看刷新历史记录,请在模型的“设置”页中,选择“刷新历史记录”。 如果要进一步向下钻取,请选择“显示”以显示详细信息。

通过定期检查刷新历史记录,可以确保计划的刷新操作在可接受的时间段内完成。 请确保在下一次计划的刷新开始之前成功完成刷新操作。
训练和刷新失败
尽管 Power BI 在所选日或周频率的第一次计划刷新期间执行训练和刷新操作,但这些操作都是作为单独的事务实现的。 如果训练操作在其时间限制内无法完全处理查询日志,Power BI 将使用以前的训练状态继续刷新现有聚合(以及复合模型中的常规表)。 在这种情况下,刷新历史记录将指示刷新成功,训练将在下次启动训练时继续处理查询日志。 如果客户端报告查询模式发生了变化,并且聚合还没有调整,查询性能可能不是最佳的,但达到的性能水平仍应远远优于不包含任何聚合的纯 DirectQuery 模型。

如果训练操作完成查询日志处理所需的周期过多,请考虑在模型的“设置”中减少使用内存中聚合缓存的查询百分比。 这会减少在缓存中创建的聚合数量,但可以有更多的时间来完成训练和刷新操作。 要了解详细信息,请参阅微调。
如果训练成功但刷新失败,则整个刷新都会标记为“失败”,因为结果是不可用的内存中聚合缓存。
计划刷新时,可以指定在刷新失败时发送电子邮件通知。
用户定义的聚合和自动聚合
Power BI 中用户定义的聚合可以基于模型中隐藏的聚合表进行手动配置。 配置用户定义的聚合通常很复杂,需要具备更高水平的数据建模和查询优化技能。 而作为 AI 驱动系统一部分的自动聚合消除了这一复杂性。 不同于保持静态的用户定义的聚合,Power BI 会持续维护查询日志,并通过这些日志基于机器学习 (ML) 预测建模算法确定查询模式。 根据查询模式分析计算预聚合数据并将其存储在内存中。 通过自动聚合,模型既能自行训练,又能自行优化。 客户端报表查询模式更改时,自动聚合会进行调整,对最常使用的聚合进行优先级设置和缓存。
自动聚合建立在用户定义的现有聚合基础架构之上,因此可以在同一模型中同时使用用户定义的聚合和自动聚合。 有经验的数据建模人员可以使用 DirectQuery、Import(附带或不附带增量刷新)或 Dual 存储模式定义表的聚合,同时还可以通过(不命中用户定义的聚合表的)DirectQuery 连接对查询进行更自动的聚合。 这种灵活性可实现均衡的体系结构,从而减少查询负载,避免出现瓶颈。
通过自动聚合训练算法在内存中缓存内创建的聚合标识为 System 聚合。 在分析报告查询并进行调整以维护模型的最佳聚合时,此训练算法仅创建和删除 System 聚合。 用户定义的聚合和自动聚合均通过模型刷新进行刷新。 自动聚合处理中仅包括由自动聚合创建并标记为系统生成的聚合。
查询缓存和自动聚合
Power BI Premium 还支持在 Power BI Premium/Embedded 中查询缓存来维护查询结果。 查询缓存功能不同于自动聚合。 通过查询缓存,Power BI Premium 可使用其本地缓存服务来实现缓存,而自动聚合是在模型级别实现的。 使用查询缓存时,该服务仅缓存初始报表页面加载的查询,因此用户与报表交互时查询性能不会提高。 相比之下,自动聚合通过预先缓存的聚合查询结果来优化大多数报表查询,包括那些在用户与报表交互时生成的查询。 可以同时为模型启用查询缓存和自动聚合,但可能没有必要。
使用 Azure Log Analytics 进行监视
Azure Log Analytics (LA) 是 Azure Monitor 中的一项服务,Power BI 可用它来保存活动日志。 借助 Azure Monitor 套件,可以从 Azure 和本地环境收集、分析和处理遥测数据。 它提供长期存储、即席查询界面和 API 访问,允许执行数据导出和与其他系统的集成。 要了解详细信息,请参阅在 Power BI 中使用 Azure Log Analytics。
如果 Power BI 配置了 Azure LA 帐户,如在 Power BI 中配置 Azure Log Analytics 中所述,则可以分析自动聚合的成功率。 除此之外,还可以确定是否从内存中缓存响应了报表查询。
若要使用此功能,请下载 PBIT 模板,并将其连接到 Log Analytics 帐户,如此篇 Power BI 博客文章中所述。 在报表中,可以在三个不同的级别查看数据:摘要视图、DAX 查询级别视图和 SQL 查询级别视图。
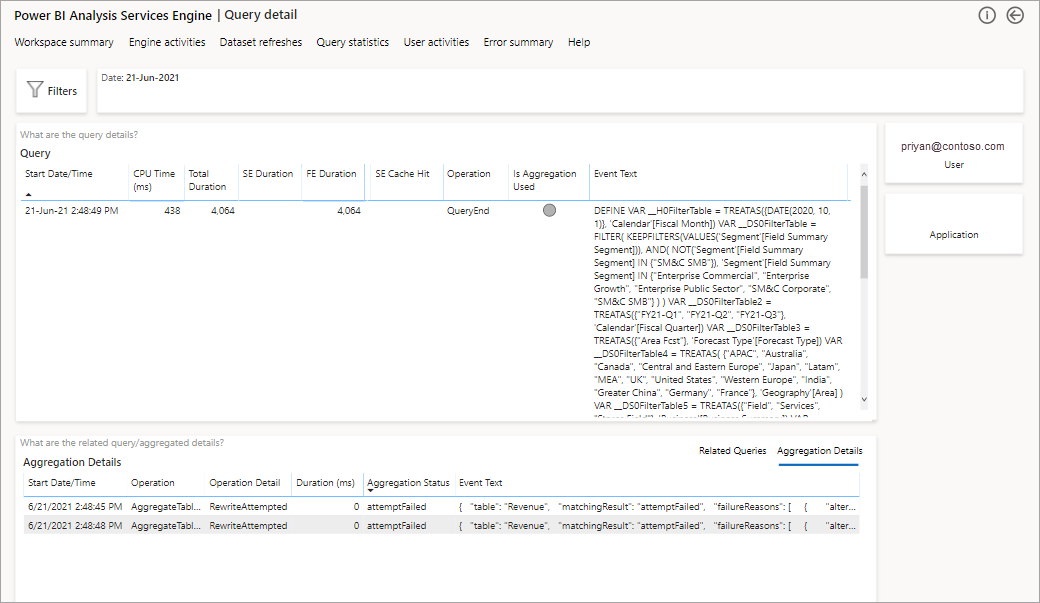
下图显示了所有查询的摘要页。 如图所示,标记的图表显示了聚合满足的查询总数与必须使用数据源的查询数的百分比。
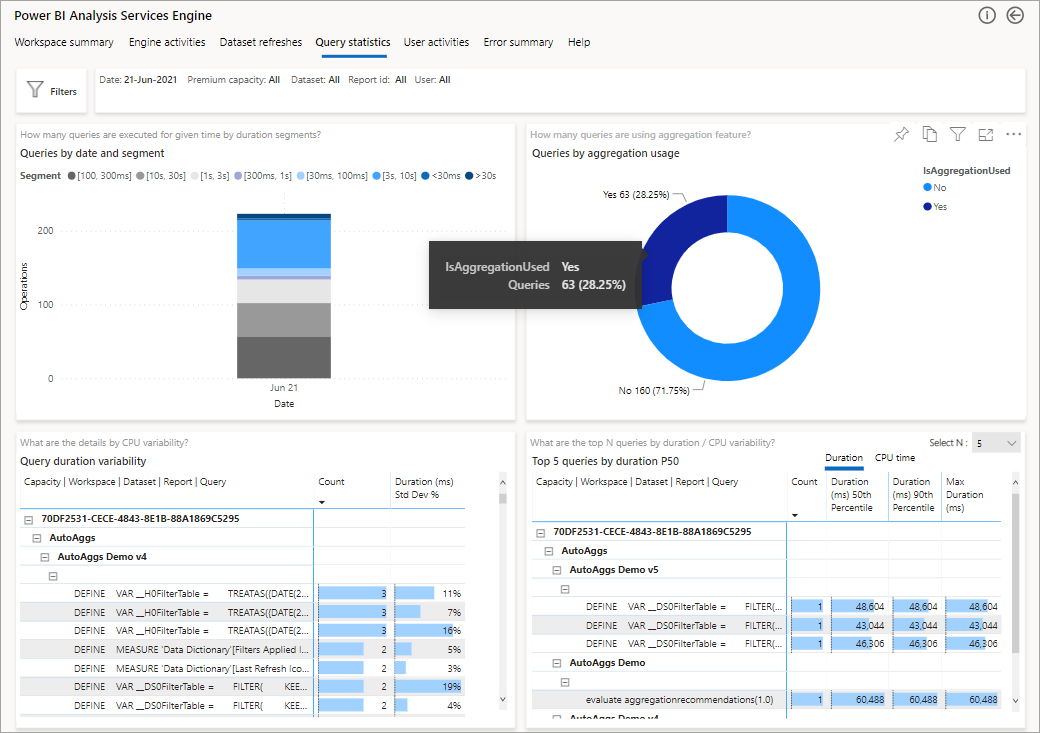
下一步要深入了解的是在 DAX 查询级别查看聚合的使用情况。 右键单击列表(左下方)中的 DAX 查询“钻取”>“查询历史记录”>。
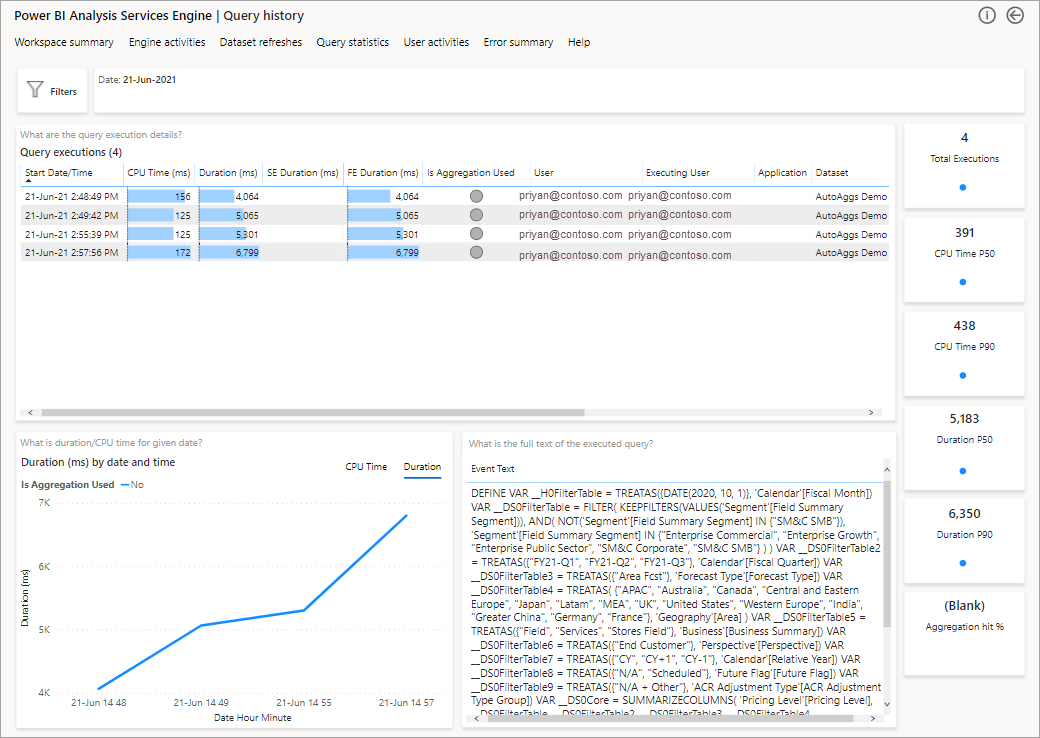
这将提供所有相关查询的列表。 钻取到下一级别以显示更多聚合详细信息。
应用程序生命周期管理
从开发到测试,从测试到生产,启用了自动聚合的模型对 ALM 解决方案有特殊要求。
部署管道
使用部署管道,Power BI 可以将模型及其模型配置从当前阶段复制到目标阶段。 但是,必须在目标阶段重置自动聚合,因为设置不会从当前阶段转移到目标阶段。 也可使用部署管道 REST API 以编程方式部署内容。 若要详细了解此过程,请参阅使用 API 和 DevOps 自动化部署管道。
自定义 ALM 解决方案
如果使用基于 XMLA 终结点的自定义 ALM 解决方案,请注意,解决方案可能能够将系统生成的聚合表和用户创建的聚合表复制为模型元数据的一部分。 但是,必须在目标阶段的每个部署步骤后手动启用自动聚合。 如果覆盖现有模型,Power BI 将保留配置。
注意
如果将模型作为 Power BI Desktop (.pbix) 文件的一部分上传或重新发布,系统创建的聚合表将丢失,因为 Power BI 会在目标工作区替换现有模型及其所有元数据和数据。
更改模型
通过 XMLA 终结点更改已启用自动聚合的模型后(例如添加或移除表),Power BI 将保留所有现有聚合,并移除不再需要或不再相关的聚合。 在触发下一训练阶段之前,查询性能可能会受到影响。
元数据元素
已启用自动聚合的模型包含系统生成的唯一聚合表。 用户在报告工具中看不到聚合表。 将工具与 Analysis Services 客户端库 19.22.5 及更高版本结合使用,可以通过 XMLA 终结点看到这些表。 使用已启用自动聚合的模型时,请务必将数据建模和管理工具升级到客户端库的最新版本。 对于 SQL Server Management Studio (SSMS),请升级到 SSMS 18.9.2 或更高版本。 早期版本的 SSMS 无法枚举表或编写这些模型的脚本。
自动聚合表由 SystemManaged 表属性标识,这是 Analysis Services 客户端库 19.22.5 及更高版本中表格对象模型 (TOM) 的新增属性。 以下代码片段显示自动聚合表的 SystemManaged 属性设置为 true,而常规表设置为 false。
using System;
using System.Collections.Generic;
using System.Linq;
using Microsoft.AnalysisServices.Tabular;
namespace AutoAggs
{
class Program
{
static void Main(string[] args)
{
string workspaceUri = "<Specify the URL of the workspace where your model resides>";
string datasetName = "<Specify the name of your dataset>";
Server sourceWorkspace = new Server();
sourceWorkspace.Connect(workspaceUri);
Database dataset = sourceWorkspace.Databases.GetByName(datasetName);
// Enumerate system-managed tables.
IEnumerable<Table> aggregationsTables = dataset.Model.Tables.Where(tbl => tbl.SystemManaged == true);
if (aggregationsTables.Any())
{
Console.WriteLine("The following auto aggs tables exist in this dataset:");
foreach (Table table in aggregationsTables)
{
Console.WriteLine($"\t{table.Name}");
}
}
else
{
Console.WriteLine($"This dataset has no auto aggs tables.");
}
Console.WriteLine("\n\rPress [Enter] to exit the sample app...");
Console.ReadLine();
}
}
}
执行此代码片段会在控制台中输出模型中当前包含的自动聚合表。
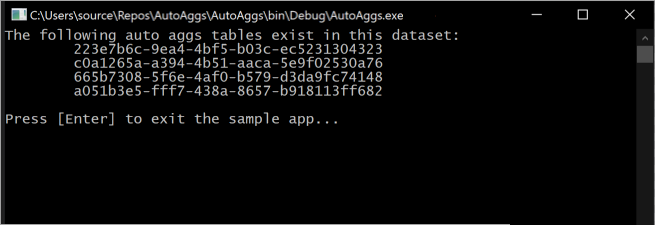
请注意,随着训练操作确定要包括在内存中聚合缓存中的最佳聚合,聚合表会持续变化。
重要
Power BI 会全面管理自动聚合系统生成的表对象。 请不要自行删除或修改这些表。 这样做可能会导致性能下降。
Power BI 会维护模型外部的模型配置。 模型中存在系统管理的聚合表并不一定意味着模型实际上已启用自动聚合训练。 换句话说,如果为启用了自动聚合的模型编写完整的模型定义脚本,并(使用不同的名称/工作区/容量)创建该模型的新副本,则新生成的模型还未启用自动聚合训练。 仍需在模型的“设置”中为新模型启用自动聚合训练。
注意事项和限制
使用自动聚合时,请注意下列问题:
- 聚合不支持动态 M 查询参数。
- 在初始训练阶段生成的 SQL 查询可为数据仓库生成大量负载。 如果训练一直以未完成状态结束,并且你可以在数据仓库端验证查询是否遇到超时,请考虑暂时纵向扩展数据仓库以满足训练需求。
- 存储在内存中聚合缓存内的聚合可能无法根据数据源中的最新数据进行计算。 数据源中的更新与内存中聚合缓存内存储的聚合数据之间存在延迟,这一点与纯 DirectQuery 不同,而是更类似于常规导入表。 尽管始终会有一定程度的延迟,但可以通过有效的刷新计划来缓解这一情况。
- 若要进一步优化性能,请将所有维度表设置为 Dual 模式,并在 DirectQuery 模式下保留事实数据表。
- 自动聚合不适用于 Power BI Pro、Azure Analysis Services 和 SQL Server Analysis Services。
- Power BI 不支持下载已启用自动聚合的模型。 如果将 Power BI Desktop (.pbix) 文件上传或发布到 Power BI,然后启用自动聚合,将无法再下载此 PBIX 文件。 请确保在本地保存 PBIX 文件的副本。
- 不支持使用 Azure Synapse Analytics 中的外部表进行自动聚合。 可以使用以下 SQL 查询来枚举 Synapse 中的外部表:
SELECT SCHEMA_NAME(schema_id) AS schema_name, name AS table_name FROM sys.external_tables。 - 自动聚合仅适用于使用增强型元数据的模型。 如果要对较旧的模型启用自动聚合,请首先将模型升级到增强型元数据。 要了解详细信息,请参阅使用增强型模型元数据。
- 如果 DirectQuery 数据源配置为单一登录并使用动态数据视图或安全控件来限制允许用户访问的数据,请勿启用自动聚合。 自动聚合不能识别这些数据源级别的控件,因此无法确保按用户提供正确的数据。 训练将在刷新历史记录中记录一条警告,指出它检测到为单一登录配置的数据源,并已跳过使用此数据源的表。 如有可能,请禁用这些数据源的 SSO,从而充分利用自动聚合可提供的优化查询性能。
- 如果模型仅包含混合表,请不要启用自动聚合,以避免不必要的处理开销。 混合表同时使用导入分区和 DirectQuery 分区。 一个常见的场景是使用实时数据进行增量刷新,其中 DirectQuery 分区从数据源中提取上次数据刷新后发生的事务。 但是,Power BI 会在刷新期间导入聚合。 自动聚合不能包含上次数据刷新后发生的事务。 训练将在刷新历史记录中记录一条警告,指出它检测到并跳过了混合表。
- 自动聚合不考虑计算列。 如果在 DirectQuery 模式下使用计算列,例如使用
COMBINEVALUESDAX 函数基于两个 DirectQuery 表的多个列创建关系,相应的报表查询将不会命中内存中聚合缓存。 - 自动聚合仅在 Power BI 服务中可用。 Power BI Desktop 不会创建系统生成的聚合表。
- 如果修改已启用自动聚合的模型的元数据,那么在触发下一训练过程之前,查询性能可能会降低。 最佳做法是,应删除自动聚合,进行更改,然后重新训练。
- 请不要修改或删除系统生成的聚合表,除非禁用了自动聚合并且要清理模型。 系统负责管理这些对象。
社区
Power BI 有一个充满活力的社区,在此社区中,MVP、BI 专业人员和同行在讨论组、视频、博客中分享专业知识。 在了解自动聚合时,请务必查看下列其他资源:
相关内容
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈