分析数据流的存储结构是什么?
分析数据流可在 Azure Data Lake Storage 中存储数据和元数据。 数据流利用标准结构来存储和描述在湖中创建的数据,而这被称为“通用数据模型”文件夹。 在本文中,你将详细了解数据流在后台使用的存储标准。
存储需为分析数据流设置一个结构
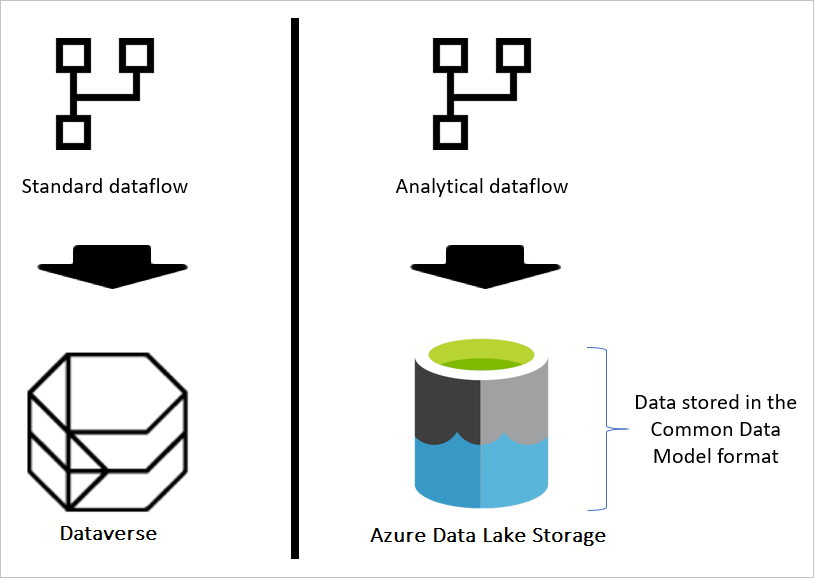
如果数据流为标准数据流,则数据存储在 Dataverse 中。 Dataverse 类似于数据库系统,它具有表、视图等概念。 Dataverse 是标准数据流使用的结构化数据存储选项。
但是,当数据流为分析数据流时,数据则存储在 Azure Data Lake Storage 中。 数据流的数据和元数据存储在 Common Data Model 文件夹中。 由于存储帐户中可能存储多个数据流,因此引入文件夹和子文件夹层次结构来帮助组织数据。 根据数据流创建的产品,文件夹和子文件夹可表示工作区(或环境),然后是数据流的 Common Data Model 文件夹。 在 Common Data Model 文件夹中,存储有数据流表的架构和数据。 此结构遵循为 Common Data Model 定义的标准。
什么是 Common Data Model 存储结构?
Common Data Model 是一种元数据结构,它旨在实现跨多个平台使用数据的合规性和一致性。 Common Data Model 不是数据存储,而是存储和定义数据的方式。
Common Data Model 文件夹定义了表的架构及其数据的存储方式。 在 Azure Data Lake Storage 中,数据以文件夹进行组织。 文件夹可表示工作区或环境。 在这些文件夹中,会为每个数据流创建子文件夹。
数据流文件夹中有哪些内容?
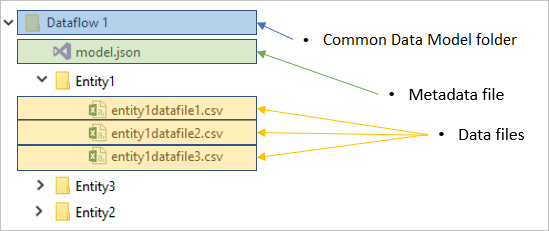
每个数据流文件夹均包含每个表的子文件夹和一个名为 model.json 的元数据文件。
元数据文件:model.json
model.json 文件是数据流的元数据定义。 这是一个包含所有数据流元数据的文件。 它包括表、列及其在每个表中的数据类型、表间关系等内容的列表。 即使无权访问 Common Data Model 文件夹结构,也可轻松从数据流导出此文件。
可使用此 JSON 文件将数据流迁移(或导入)到其他工作区或环境。
若要确切了解 model.json 元数据文件包含的内容,请转到 Common Data Model 的元数据文件 (model.json)。
数据文件
除了元数据文件,数据流文件夹还包括其他子文件夹。 数据流将每个表的数据存储在附带表名称的子文件夹中。 表的数据可能会拆分为多个数据分区,并以 CSV 格式存储。
如何查看或访问 Common Data Model 文件夹
如果所用数据流使用的是其创建位置所在产品提供的存储,则无法直接访问这些文件夹。 在此类情况下,从数据流获取数据需使用 Power BI 服务、Power Apps 和 Dynamics 35 Customer Insights 产品或 Power BI Desktop 中 Get data 体验所提供的 Microsoft Power Platform 数据流连接器。
若要了解数据流和内部 Data Lake Storage 集成的工作原理,请转到数据流和 Azure Data Lake 集成(预览版)。
如果组织启用了数据流来利用其 Data Lake Storage 帐户且被选为数据流的负载目标,则仍可使用上述 Power Platform 数据流连接器从数据流中获取数据。 但是,也可直接通过湖访问数据流的 Common Data Model 文件夹,即使在 Power Platform 工具和服务之外也是如此。 可通过 Azure 门户、Microsoft Azure 存储资源管理器或任何其他支持 Azure Data Lake Storage 的服务或体验来访问湖。 详细信息:连接 Azure Data Lake Storage Gen2 以存储数据流
后续步骤
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈