Python 教程:构建一个模型以通过 SQL 机器学习对客户进行聚类分析
适用于:![]() SQL Server 2017 (14.x) 及更高版本
SQL Server 2017 (14.x) 及更高版本 ![]() Azure SQL 托管实例
Azure SQL 托管实例
在这个由四部分组成的教程系列的第三部分中,你将在 Python 中创建一个 K-Means 模型来执行聚类分析。 在本系列的下一部分中,你将在 SQL Server 机器学习服务中或大数据群集上将此模型部署到数据库中。
在这个由四部分组成的教程系列的第三部分中,你将在 Python 中创建一个 K-Means 模型来执行聚类分析。 在本系列的下一部分中,你将使用 SQL Server 机器学习服务将此模型部署到数据库中。
在这个由四部分组成的教程系列的第三部分中,你将在 Python 中创建一个 K-Means 模型来执行聚类分析。 在本系列的下一部分中,你将使用 Azure SQL 托管实例机器学习服务在数据库中部署此模型。
本文将指导如何进行以下操作:
- 定义 K-Means 算法的群集数
- 执行聚类分析
- 分析结果
在第一部分中,你安装了必备条件并还原了示例数据库。
在第二部分中,你了解了如何从数据库准备数据以执行聚类分析。
在第四部分中,你将了解如何在数据库中创建存储过程,以便基于新数据在 Python 中执行聚类分析。
先决条件
定义群集数
若要对客户数据进行聚类分析,需要使用 K-Means 聚类分析算法,这是最简单、最常见的数据分组方法之一。 有关 K-Means 的详细信息,请参阅 K-means 聚类分析算法的完整指南。
该算法接受两个输入:数据本身,以及代表要生成的群集数的预定义数字“k”。 输出是 K 个群集,输入数据在群集之间进行分区。
K-Means 的目标是将项目分组为 K 个群集,以使同一群集中的所有项目彼此相似,并且与其他群集中的项目尽可能不同。
要确定要使用的算法的群集数,请使用组内平方和的图,并按提取的群集数进行绘制。 要使用的适当群集数是在曲线的折弯处或“肘形”处。
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
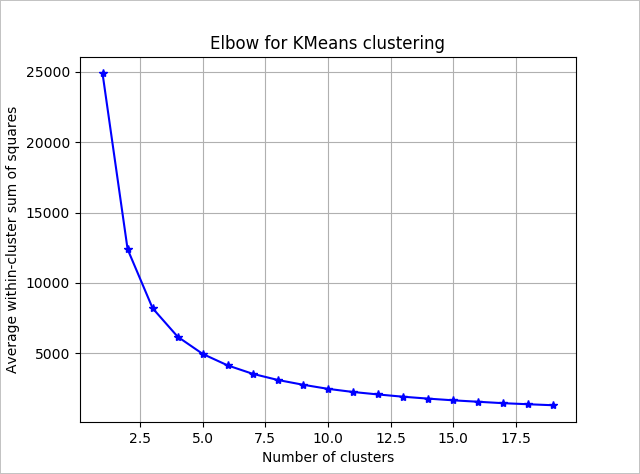
根据该图,看起来 k = 4 将是一个不错的尝试值。 该 ķ 值将客户分组为四个群集。
执行聚类分析
在以下 Python 脚本中,将使用 sklearn 包中的 KMeans 函数。
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
分析结果
使用 K-Means 进行聚类分析后,接下来就是分析结果,了解是否可以找到任何可操作的信息。
查看从上一个脚本打印的群集平均值和群集大小。
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
使用第一部分中定义的变量给出四种群集平均值:
- orderRatio = 退单率(部分或全部退货的订单总数与订单总数的比率)
- itemsRatio = 退货率(退货总数与购买商品数量的比率)
- monetaryRatio = 退款率(退货的总货币金额与购买总金额的比率)
- frequency = 退货频率
使用 K-Means 进行数据挖掘通常需要对结果进行进一步的分析,并采取进一步的步骤以更好地理解每个群集,但是它可以提供一些优秀的潜在顾客。 下面通过以下几种方法来解释这些结果:
- 群集 0 似乎是一组不活动的客户(所有值均为零)。
- 群集 3 似乎是一个在返回行为方面出现的组。
群集 0 显然是一组不活跃的客户。 也许你可以针对该群体进行营销活动,以激发购买兴趣。 在下一步中,你将在数据库中查询群集 0 中客户的电子邮件地址,以便向他们发送市场营销电子邮件。
清理资源
如果不打算继续学习本教程,请删除 tpcxbb_1gb 数据库。
后续步骤
在本系列教程的第三部分中,你已完成以下步骤:
- 定义 K-Means 算法的群集数
- 执行聚类分析
- 分析结果
若要部署已创建的机器学习模型,请按照本系列教程的第四部分进行操作:
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈