标量 UDF 内联
适用于:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x) ![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例
本文介绍了标量 UDF 内联,这是智能查询处理功能套件下的一项功能。 此功能提高了在 SQL Server(从 SQL Server 2019 [15.x] 开始)中调用标量 UDF 的查询性能。
T-SQL 标量用户定义函数
在 Transact-SQL 中实现并返回单个数据值的用户定义函数称为 T-SQL 标量用户定义函数 (UDF)。 T-SQL 的 UDF 是所有 Transact-SQL 查询实现代码重用和模块化的简洁方法。 某些计算(如复杂的业务规则)在命令性 UDF 窗体中更易表示。 UDF 有助于构建复杂的逻辑,而无需编写复杂 SQL 查询的专业知识。 有关 UDF 的详细信息,请参阅创建用户定义的函数(数据库引擎)。
标量 UDF 的性能
标量 UDF 通常会由于以下原因而最终导致性能欠佳:
迭代调用。 以迭代方式调用 UDF,每个符合条件的元组一次。 由于函数调用,这会导致重复上下文切换的额外成本。 尤其是在其定义中执行 Transact-SQL 查询的 UDF 会受到严重影响。
缺乏成本计算。 在优化期间,只有关系运算符会计算成本,标量运算符则不计算成本。 在引入标量 UDF 之前,其他标量运算符通常很便宜并且不需要成本计算。 为标量运算添加的小 CPU 成本就足够了。 有些情况下实际成本很高,但仍然没有得到充分代表。
解释型执行。 UDF 以一批语句的形式进行计算,并按逐个语句执行。 编译每个语句本身,并缓存编译的计划。 尽管此缓存策略能够通过避免重新编译节省一些时间,但每个语句仍需单独执行。 不执行跨语句优化。
串行执行。 SQL Server 不允许在调用 UDF 的查询中进行查询内并行操作。
标量 UDF 的自动内联
标量 UDF 内联功能的目标是提高调用 T-SQL 标量 UDF 的查询性能,其中 UDF 执行是主要瓶颈。
使用此新功能,标量 UDF 会自动转换为标量表达式或在调用查询中替换 UDF 运算符的标量子查询。 然后优化这些表达式和子查询。 因此,查询计划将不再具有用户定义的函数运算符,但其效果将在计划中观察到,如视图或内联 TVF。
示例 1 - 单语句标量 UDF
请考虑以下查询。
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (L_EXTENDEDPRICE *(1 - L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE;
此查询计算订单项的折扣价格总和,并显示按发货日期和发货优先级分组的结果。 表达式 L_EXTENDEDPRICE *(1 - L_DISCOUNT) 是给定行项的折扣价格的公式。 可以将这些公式提取到函数中以利用模块化和重用优势。
CREATE FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2) AS
BEGIN
RETURN @price * (1 - @discount);
END
现在可以修改查询以调用此 UDF。
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
由于之前所述的原因,在查询中使用 UDF 表现较差。 现在,使用标量 UDF 内联,UDF 主体中的标量表达式将直接替换为查询。 运行此查询的结果显示在下表:
| 查询: | 不使用 UDF 进行查询 | 使用 UDF 进行查询(不内联) | 使用标量 UDF 内联进行查询 |
|---|---|---|---|
| 执行时间: | 1.6 秒 | 29 分 11 秒 | 1.6 秒 |
这些数字基于 10 GB CCI 数据库(使用 TPC-H 架构),在具有双处理器(12 核)、96 GB RAM且由 SSD 支持的计算机上运行。 这些数字包括冷程序缓存和缓冲池的编译和执行时间。 使用了默认配置,且未创建其他索引。
示例 2 - 多语句标量 UDF
使用多个 T-SQL 语句(如变量赋值和条件分支)实现的标量 UDF 也可以进行内联。 考虑以下给定客户密钥并且确定该客户的服务类别的标量 UDF。 它首先使用 SQL 查询计算客户所下订单的总价来确定类别。 然后,使用 IF (...) ELSE 逻辑确定基于总价的类别。
CREATE OR ALTER FUNCTION dbo.customer_category(@ckey INT)
RETURNS CHAR(10) AS
BEGIN
DECLARE @total_price DECIMAL(18,2);
DECLARE @category CHAR(10);
SELECT @total_price = SUM(O_TOTALPRICE) FROM ORDERS WHERE O_CUSTKEY = @ckey;
IF @total_price < 500000
SET @category = 'REGULAR';
ELSE IF @total_price < 1000000
SET @category = 'GOLD';
ELSE
SET @category = 'PLATINUM';
RETURN @category;
END
现在,请考虑使用调用此 UDF 的查询。
SELECT C_NAME, dbo.customer_category(C_CUSTKEY) FROM CUSTOMER;
SQL Server 2017 (14.x)(兼容级别 140 及更早版本)中此查询的执行计划如下:

正如计划所示,SQL Server 在这里采用了一个简单的策略:对于 CUSTOMER 表中的每个元组,调用 UDF 并输出结果。 此策略既简单又低效。 通过内联,这些 UDF 被转换为等效的标量子查询,它们在调用查询中代替 UDF。
对于相同的查询,UDF 内联计划如下所示。
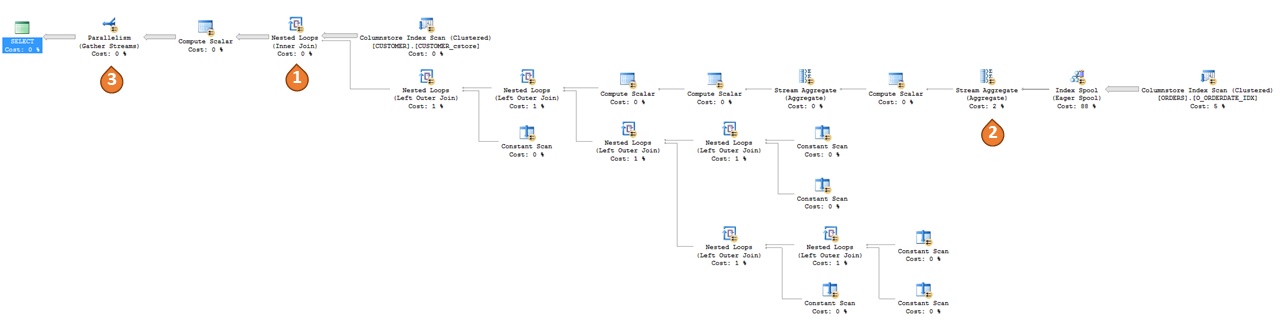
如同之前提到的,查询计划不再具有用户定义的函数运算符,但其效果能在计划中观察到,如视图或内联 TVF。 以下是一些来自上述计划的关键观测值:
- SQL Server 推断出了
CUSTOMER和ORDERS之间的隐式联接,并通过联接运算符将其显式化。 - SQL Server 也推断出了隐式
GROUP BY O_CUSTKEY on ORDERS并使用 IndexSpool + StreamAggregate 实现了它。 - SQL Server 现在在所有运算符中都使用并行。
根据 UDF 中逻辑的复杂性,所生成的查询计划也可能变得更大更复杂。 正如我们所看到的,UDF 内部的操作现在不再不透明,因此查询优化器能够对这些操作进行成本计算和优化。 此外,由于 UDF 不再在计划中,因此将用完全避免函数调用开销的计划来取代迭代 UDF 调用。
可内联标量 UDF 要求
如果满足所有以下条件,则标量 T-SQL UDF 可以内联:
- UDF 使用以下构造编写:
DECLARE,SET:变量声明和分配。SELECT:具有单个/多个变量赋值的 SQL 查询1。IF/ELSE:分支与任意级别的嵌套。RETURN:单个或多个返回语句。 从 SQL Server 2019 (15.x) CU5 开始,UDF 只能包含一个被视为用于内联的 RETURN 语句6。UDF:嵌套/递归函数调用2。- 其他:关系操作,例如
EXISTS,IS NULL。
- UDF 不会调用任何与时间相关的内部函数(例如
GETDATE())或具有副作用的函数3(例如NEWSEQUENTIALID())。 - UDF 使用
EXECUTE AS CALLER子句(如果未指定EXECUTE AS子句,则为默认行为)。 - UDF 不引用表变量或表值参数。
- 调用标量 UDF 的查询不会在其
GROUP BY子句中引用标量 UDF 调用。 - 使用
DISTINCT子句在其选择列表中调用标量 UDF 的查询没有ORDER BY子句。 ORDER BY子句中未使用 UDF。- UDF 不是本机编译的(支持互操作)。
- UDF 不用于计算列或检查约束定义。
- UDF 不引用用户定义类型。
- 没有签名添加到 UDF。
- UDF 不是配分函数。
- UDF 不包含对公用表表达式 (CTE) 的引用。
- UDF 不包含对内联后可能改变结果的内部函数(例如
@@ROWCOUNT)4。 - UDF 不包含作为参数传递给标量 UDF 的聚合函数4。
- UDF 不会引用内置视图(如
OBJECT_ID)4。 - UDF 不引用 XML 方法5。
- UDF 不包含 SELECT(带
ORDER BY,不带TOP 1子句)5。 - UDF 不包含与
ORDER BY子句(如SELECT @x = @x + 1 FROM table1 ORDER BY col1)一起用于执行赋值的 SELECT 查询5。 - UDF 不包含多个 RETURN 语句6。
- 不会从 RETURN 语句调用 UDF6。
- UDF 不引用
STRING_AGG函数6。 - UDF 不引用远程表 7。
- UDF 调用查询不使用
GROUPING SETS、CUBE或ROLLUP7。 - UDF 调用查询不包含用作赋值的 UDF 参数的变量(例如
SELECT @y = 2、@x = UDF(@y))7。 - UDF 不引用加密列8。
- UDF 不包含对
WITH XMLNAMESPACES的引用8。 - 调用 UDF 的查询没有公用表表达式 (CTE)8。
1 带变量累计/聚合的 SELECT 不支持内联(例如 SELECT @val += col1 FROM table1)。
2 递归 UDF 将仅内联到某个深度。
3 结果取决于当前系统时间的内部函数与时间相关。 举例来说,可以更新某些内部全局状态的内部函数就是具有副作用的函数。 每次调用此类函数都会根据内部状态返回不同的结果。
4 SQL Server 2019 (15.x) CU2 中增加的限制
5 SQL Server 2019 (15.x) CU4 中增加的限制
6 SQL Server 2019 (15.x) CU5 中增加的限制
7 SQL Server 2019 (15.x) CU6 中增加的限制
8 SQL Server 2019 (15.x) CU11 中增加的限制
有关针对内联资格方案的最新 T-SQL 标量 UDF 内联修复和更改,请参阅知识库文章:修复:SQL Server 2019 中的标量 UDF 内联问题。
检查 UDF 是否可以内联
对于每个 T-SQL 标量 UDF,sys.sql_modules 目录视图都包含一个名为 is_inlineable 的属性,指示 UDF 是否可内联。
is_inlineable 属性派生自 UDF 定义内的构造。 它不会在编译时检查 UDF 是否确实可内联。 有关详细信息,请参阅下面的内联条件。
值为 1 则表明可内联,0 则表示不可内联。 对于所有内联 TVF,此属性的值均为 1。 对于所有其他模块,此值都将为 0。
如果标量 UDF 可内联,这并不意味着它将始终进行内联。 SQL Server 将基于每个查询和每个 UDF 决定是否内联 UDF。 下面是几个可能不内联 UDF 的示例:
如果 UDF 定义包含数千行代码,SQL Server 可能会选择不内联它。
不会内联
GROUP BY子句中的 UDF 调用。 在编译引用标量 UDF 的查询时做出这种决定。如果 UDF 已使用证书签名,则不内联它。 由于签名可以在创建 UDF 后添加和删除,因此在编译引用标量 UDF 的查询时,将决定是否内联。 例如,通常使用证书对系统函数进行签名。 可以使用 sys.crypt_properties 来查找已签名的对象。
SELECT * FROM sys.crypt_properties AS cp INNER JOIN sys.objects AS o ON cp.major_id = o.object_id;
检查是否发生内联
如果满足所有前置条件,且 SQL Server 决定执行内联,则它会将 UDF 转换为关系表达式。 可以很容易从查询计划中弄清楚是否内联:
- 对于已成功内联的 UDF,计划 XML 将没有
<UserDefinedFunction>XML 节点。 - 发出某些 XEvent。
启用标量 UDF 内联
可以通过对数据库启用兼容性级别 150 使工作负荷自动符合标量 UDF 内联。 可使用 Transact-SQL 进行此设置。 例如:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
除此之外,不需要对 UDF 或查询进行其他更改即可利用此功能。
在不更改兼容级别的情况下禁用标量 UDF 内联
可在数据库、语句或 UDF 范围内禁用标量 UDF 内联,同时将数据库兼容性级别维持在 150 或更高。 要在数据库范围内禁用标量 UDF 内联,请在适用数据库的上下文中执行以下语句:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = OFF;
要对数据库重新启用标量 UDF 内联,请在适用数据库的上下文中执行以下语句:
ALTER DATABASE SCOPED CONFIGURATION SET TSQL_SCALAR_UDF_INLINING = ON;
启用此选项后,此设置将在 sys.database_scoped_configurations 中显示为已启用。
还可通过将 DISABLE_TSQL_SCALAR_UDF_INLINING 指定为 USE HINT 查询提示来禁用特定查询的标量 UDF 内联。
USE HINT 查询提示优先于数据库范围配置或兼容级别设置。
例如:
SELECT L_SHIPDATE, O_SHIPPRIORITY, SUM (dbo.discount_price(L_EXTENDEDPRICE, L_DISCOUNT))
FROM LINEITEM
INNER JOIN ORDERS
ON O_ORDERKEY = L_ORDERKEY
GROUP BY L_SHIPDATE, O_SHIPPRIORITY ORDER BY L_SHIPDATE
OPTION (USE HINT('DISABLE_TSQL_SCALAR_UDF_INLINING'));
也可使用 CREATE FUNCTION 或 ALTER FUNCTION 语句中的 INLINE 子句为特定 UDF 禁用标量 UDF 内联。
例如:
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2)
WITH INLINE = OFF
AS
BEGIN
RETURN @price * (1 - @discount);
END;
执行上述语句后,此 UDF 永远不会被内联到任何调用它的查询中。 要重新启用此 UDF 的内联,请执行以下语句:
CREATE OR ALTER FUNCTION dbo.discount_price(@price DECIMAL(12,2), @discount DECIMAL(12,2))
RETURNS DECIMAL (12,2)
WITH INLINE = ON
AS
BEGIN
RETURN @price * (1 - @discount);
END
INLINE 子句不是强制性的。 如果未指定 INLINE 子句,则会根据是否可以内联 UDF 将其自动设置为 ON/OFF。 如果指定了 INLINE = ON 但发现 UDF 不符合内联条件,则会引发错误。
重要事项
如本文所述,标量 UDF 内联将带有标量 UDF 的查询转换为具有等效标量子查询的查询。 由于此转换,用户可能会注意到以下情况中的某些行为差异:
内联将导致相同查询文本的不同查询哈希。
UDF 内部语句中某些可能已被隐藏的警告(例如除以零等),可能会因内联而显示出来。
查询级别联接提示可能不再有效,因为内联可能会引入新联接。 必须改为使用本地联接提示。
无法索引引用内联标量UDF的视图。 如果需要在此类视图上创建索引,请禁用对引用的 UDF 的内联。
动态数据屏蔽与 UDF 内联的行为可能存在一些差异。
在某些情况下(取决于 UDF 中的逻辑),内联可能对于屏蔽输出列更为保守。 如果 UDF 中引用的列不是输出列,则它们不会被屏蔽。
如果 UDF 引用内置函数(如
SCOPE_IDENTITY()、@@ROWCOUNT或@@ERROR),内置函数返回的值将随内联而变化。 这种行为上的更改是因为内联更改了 UDF 中语句的范围。 从 SQL Server 2019 (15.x) CU2 开始,如果 UDF 引用某些内部函数(例如@@ROWCOUNT),则将阻止内联。如果变量是使用内联 UDF 的结果分配的,并且它也用作 FORCESEEK 查询提示中的 index_column_name,则会导致错误消息 8622,指示由于查询中定义了提示,查询处理器无法生成查询计划。
另请参阅
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈