DBCC SHOW_STATISTICS (Transact-SQL)
适用于:![]() SQL Server
SQL Server![]() Azure SQL 数据库
Azure SQL 数据库![]() Azure SQL 托管实例
Azure SQL 托管实例![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Microsoft Fabric 中的 SQL 分析终结点
Microsoft Fabric 中的 SQL 分析终结点![]() Microsoft Fabric 中的仓库
Microsoft Fabric 中的仓库
显示表或索引视图的当前查询优化统计信息。 查询优化器使用统计信息来估计基数或查询结果中的行数,以便创建高质量的查询计划。 例如,查询优化器可以使用基数估计在查询计划中选择索引查找运算符而不是索引扫描运算符,从而通过避免消耗大量资源的索引扫描来提高查询性能。
查询优化器将表或索引视图的统计信息存储在统计信息对象中。 对于表,统计信息对象是根据索引或表列的列表创建的。 统计信息对象包含一个带有统计信息的相关元数据的标题、一个带有统计信息对象第一个键列中的值的分布的直方图,以及一个用于度量各列之间的相关性的密度矢量。 数据库引擎可以使用统计信息对象中的任何数据计算基数估计。 有关详细信息,请参阅统计信息和基数估计 (SQL Server)。
DBCC SHOW_STATISTICS 根据统计信息对象中存储的数据显示标题、直方图和密度向量。 使用以下语法,您可以指定表或索引视图以及目标索引名称、统计信息名称或列名。
SQL Server 早期版本中的重要更新:
从 SQL Server 2012 (11.x) Service Pack 1 开始,sys.dm_db_stats_properties 动态管理视图可用于以编程方式检索包含在统计信息对象中的标头信息,以获取非增量统计信息。
从 SQL Server 2014 (12.x) Service Pack 2 和 SQL Server 2012 (11.x) Service Pack 1 开始,sys.dm_db_incremental_stats_properties 动态管理视图可用于以编程方式检索包含在统计信息对象中的标头信息,以获取增量统计信息。
从 SQL Server 2016 (13.x) Service Pack 1 CU 2 开始,sys.dm_db_stats_histogram 动态管理视图可用于以编程方式检索包含在统计信息对象中的直方图信息。
-
Azure Synapse Analytics 中的无服务器 SQL 池不支持此语法。
有关 Microsoft Fabric 中的统计信息的详细信息,请参阅统计信息。
语法
SQL Server 和 Azure SQL 数据库的语法:
DBCC SHOW_STATISTICS ( table_or_indexed_view_name , target )
[ WITH [ NO_INFOMSGS ] < option > [ , ...n ] ]
< option > ::=
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM
[ ; ]
Azure Synapse Analytics、Analytics Platform System (PDW) 和 Microsoft Fabric 的语法:
DBCC SHOW_STATISTICS ( table_name , target )
[ WITH { STAT_HEADER | DENSITY_VECTOR | HISTOGRAM } [ , ...n ] ]
[ ; ]
注意
若要查看 SQL Server 2014 (12.x) 及更早版本的 Transact-SQL 语法,请参阅早期版本文档。
自变量
table_or_indexed_view_name
要显示其统计信息的表或索引视图的名称。
table_name
包含待显示统计信息的表的名称。 该表不能为外部表。
目标
要显示其统计信息的索引、统计信息或列的名称。 target 括在括号、单引号或双引号内,或不加引号。
- 如果 target 是表或索引视图的现有索引或统计信息的名称,则返回有关此目标的统计信息。
- 如果 target 是现有列的名称,且此列中存在自动创建的统计信息对象,则返回自动创建的该统计信息的相关信息。
如果列目标中不存在自动创建的统计信息,则返回错误消息 2767。
在 Azure Synapse Analytics 和 Analytics Platform System (PDW) 中,target 不能是列名。
在 Microsoft Fabric 中的仓库中,target 可以是单列直方图统计信息的名称或列名称。 如果将列名用于 target,则此命令将仅返回有关自动生成的直方图统计信息的分布信息。 若要查看有关手动创建的直方图统计信息的信息,请将统计信息名称指定为 target。
NO_INFOMSGS
取消严重级别从 0 到 10 的所有信息性消息。
STAT_HEADER | DENSITY_VECTOR | HISTOGRAM | STATS_STREAM [ , n ]
如果指定以上一个或多个选项,将根据指定的选项限制该语句返回的结果集。 如果没有指定任何选项,则返回所有统计信息。
STATS_STREAM 标识为仅供参考。 不支持。 不保证以后的兼容性。
结果集
下表对指定 STAT_HEADER 时结果集中所返回的列进行了说明。
| 列名称 | 说明 |
|---|---|
| 名称 | 统计信息对象的名称。 |
| Updated | 上一次更新统计信息的日期和时间。 STATS_DATE 函数是另一种检索此信息的方法。 有关详细信息,请参阅此页中的备注部分。 |
| “行” | 上次更新统计信息时表或索引视图中的总行数。 如果筛选统计信息或者统计信息与筛选索引对应,该行数可能小于表中的行数。 有关详细信息,请参阅统计信息。 |
| Rows Sampled | 用于统计信息计算的抽样总行数。 如果 Rows Sampled < Rows,显示的直方图和密度结果则是根据抽样行估计的。 |
| 步骤 | 直方图中的梯级数。 每个梯级都跨越一个列值范围,后跟上限列值。 直方图梯级是根据统计信息中的第一个键列定义的。 最大梯级数为 200。 |
| 密度 | 计算公式为 1/统计信息对象第一个键列中的所有值(不包括直方图边界值)的非重复值。 查询优化器不使用此 Density 值,显示此值的目的是为了与 SQL Server 2008 (10.0.x) 之前的版本实现向后兼容。 |
| Average Key Length | 统计信息对象中所有键列的每个值的平均字节数。 |
| String Index | Yes 指示统计信息对象包含字符串摘要统计信息,以改进对使用 LIKE 运算符的查询谓词的基数估计;例如 WHERE ProductName LIKE '%Bike'。 字符串摘要统计信息与直方图分开存储,如果统计信息对象为 char、varchar、nchar、nvarchar、varchar(max)、nvarchar(max)、text 或 ntext 类型,则基于其第一个键列创建字符串摘要统计信息。 |
| 筛选表达式 | 包含在统计信息对象中的表行子集的谓词。 NULL = 未筛选的统计信息。 有关筛选谓词的详细信息,请参阅创建筛选索引。 有关筛选统计信息的详细信息,请参阅统计信息。 |
| Unfiltered Rows | 应用筛选表达式前表中的总行数。 如果筛选表达式为 NULL,则 Unfiltered Rows 等于 Rows。 |
| 持久样本百分比 | 持久样本百分比用于未显式指定采样百分比的统计信息更新。 如果值为零,则不为此统计信息设置持久样本百分比。 适用于:SQL Server 2016 (13.x) Service Pack 1 CU 4 |
下表对指定 DENSITY_VECTOR 时结果集中所返回的列进行了说明。
| 列名称 | 说明 |
|---|---|
| All Density | 密度为 1/非重复值。 结果显示统计信息对象中各列的每个前缀的密度,每个密度显示一行。 非重复值是每个行前缀和列前缀的列值的非重复列表。 例如,如果统计信息对象包含键列 (A, B, C),结果将报告以下每个列前缀中非重复值列表的密度:(A)、(A,B) 和 (A, B, C)。 使用前缀 (A, B, C),以下每个列表都是一个非重复值列表:(3, 5, 6)、(4, 4, 6)、(4, 5, 6) 和 (4, 5, 7)。 使用前缀 (A, B),相同列值具有以下非重复值列表:(3, 5)、(4, 4) 和 (4, 5) |
| Average Length | 存储列前缀的列值列表的平均长度(以字节为单位)。 例如,如果列表 (3, 5, 6) 中的每个值都需要 4 个字节,则长度为 12 个字节。 |
| 列 | 为其显示 All density 和 Average length 的前缀中的列的名称。 |
下表对指定 HISTOGRAM 选项时结果集中所返回的列进行了说明。
| 列名称 | 说明 |
|---|---|
| RANGE_HI_KEY | 直方图梯级的上限列值。 列值也称为键值。 |
| RANGE_ROWS | 其列值位于直方图梯级内(不包括上限)的行的估算数目。 |
| EQ_ROWS | 其列值等于直方图梯级的上限的行的估算数目。 |
| DISTINCT_RANGE_ROWS | 非重复列值位于直方图梯级内(不包括上限)的行的估算数目。 |
| AVG_RANGE_ROWS | 直方图步骤中具有重复列值的平均行数,不包括上限。 当 DISTINCT_RANGE_ROWS 大于 0 时,通过将 RANGE_ROWS 除以 DISTINCT_RANGE_ROWS 来计算 AVG_RANGE_ROWS。 当 DISTINCT_RANGE_ROWS 为 0 时,AVG_RANGE_ROWS 为直方图步骤返回 1。 |
备注
统计信息更新日期连同直方图和密度矢量一起存储在统计信息 blob 对象中,而不是存储在元数据中。 如果未读取到任何数据,无法生成统计信息数据,则不会创建统计信息 Blob,该日期不可用,且 updated 列为 NULL。 针对谓词不返回任何行或新的空表,筛选的统计信息便是这种情况。
直方图
直方图度量数据集中每个非重复值的出现频率。 查询优化器根据统计信息对象第一个键列中的列值来计算直方图,它选择列值的方法是以统计方式对行进行抽样或对表或视图中的所有行执行完全扫描。 如果直方图是根据一组抽样行创建的,存储的总行数和非重复值总数则为估计值,且不必为整数。
若要创建直方图,查询优化器将对列值进行排序,计算与每个非重复列值匹配的值数,然后将列值聚合到最多 200 个连续直方图梯级中。 每个梯级都包含一个列值范围,后跟上限列值。 该范围包括介于两个边界值之间的所有可能列值,但不包括边界值自身。 最小排序列值是第一个直方图梯级的上限值。
下面的关系图显示包含六个梯级的直方图。 第一个上限值左侧的区域是第一个梯级。

对于每个直方图梯级:
- 粗线表示上限值 (RANGE_HI_KEY) 和上限值的出现次数 (EQ_ROWS)
- RANGE_HI_KEY 左侧的纯色区域表示列值范围和每个列值的平均出现次数 (AVG_RANGE_ROWS)。 第一个直方图梯级的 AVG_RANGE_ROWS 始终是 0。
- 点线表示用于估计范围中的非重复值总数 (DISTINCT_RANGE_ROWS) 和范围中的总值数 (RANGE_ROWS) 的抽样值。 查询优化器使用 RANGE_ROWS 和 DISTINCT_RANGE_ROWS 计算 AVG_RANGE_ROWS,且不存储抽样值。
查询优化器按照直方图梯级的统计重要性来定义直方图梯级。 它使用最大差异算法使直方图中的梯级减至最少,并同时最大化边界值之间的差异。 最大梯级数为 200。 直方图梯级数可以少于非重复值的数目,即使对于边界点少于 200 的列也是如此。 例如,具有 100 个非重复值的列所具有的直方图的边界点可以少于 100。
密度矢量
查询优化器使用密度提高根据相同表或索引视图返回多个列的查询的基数估计。 密度向量针对统计信息对象中的列的每个前缀包含一个密度。 例如,如果统计信息对象包含键列 CustomerId、ItemId 和 Price,则根据以下每个列前缀计算密度。
| 列前缀 | 计算密度所基于的对象 |
|---|---|
(CustomerId) |
具有 CustomerId 的匹配值的行 |
(CustomerId, ItemId) |
具有 CustomerId 和 ItemId 的匹配值的行 |
(CustomerId, ItemId, Price) |
具有 CustomerId、ItemId 和 Price 的匹配值的行 |
限制
DBCC SHOW_STATISTICS 不提供空间索引或内存优化的列存储索引的统计信息。
SQL Server 和 SQL 数据库的权限
为了查看统计信息对象,用户必须对表具有 SELECT 权限。
SELECT 权限必须满足以下要求才能运行此命令:
- 用户必须对统计对象中的所有列具有权限
- 用户必须对筛选条件(如果存在)中的所有列具有权限
- 表中不能有行级别安全策略。
- 如果使用动态数据掩码规则屏蔽了统计信息对象中的任何列,除
SELECT权限外,该用户还必须具有UNMASK权限,或者是 db_ddladmin 角色的成员。
在 SQL Server 2012 (11.x) Service Pack 1 之前的版本中,用户必须是表所有者,或者是 sysadmin 固定服务器角色、db_owner 固定数据库角色或 db_ddladmin 固定数据库角色的成员。
注意
若要将行为更改回 SQL Server 2012 (11.x) Service Pack 1 之前的行为,请使用跟踪标志 9485。
Azure Synapse Analytics 和 Analytics Platform System (PDW) 的权限
DBCC SHOW_STATISTICS 需要表中的 SELECT 权限或 sysadmin 固定服务器角色的成员身份、db_owner 固定数据库角色的成员身份或 db_ddladmin 固定数据库角色的成员身份。
Azure Synapse Analytics 和 Analytics Platform System (PDW) 的限制与局限
DBCC SHOW_STATISTICS 显示控制节点级别的 Shell 数据库中存储的统计信息。 它不显示由计算节点上的 SQL Server 自动创建的统计信息。
外部表不支持 DBCC SHOW_STATISTICS。
在 Microsoft Fabric 中,DBCC SHOW_STATISTICS 仅显示直方图统计信息的结果,而不显示 ACE-* 统计信息的结果。
示例:SQL Server 和 Azure SQL 数据库
A. 返回所有统计信息
以下示例显示 AdventureWorks2022 数据库中 Person.Address 表的 AK_Address_rowguid 索引的所有统计信息。
DBCC SHOW_STATISTICS ("Person.Address", AK_Address_rowguid);
GO
B. 指定 HISTOGRAM 选项
该示例将为 Customer_LastName 显示的统计信息限制为 HISTOGRAM 数据。
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName) WITH HISTOGRAM;
GO
示例:Azure Synapse Analytics 和 Analytics Platform System (PDW)
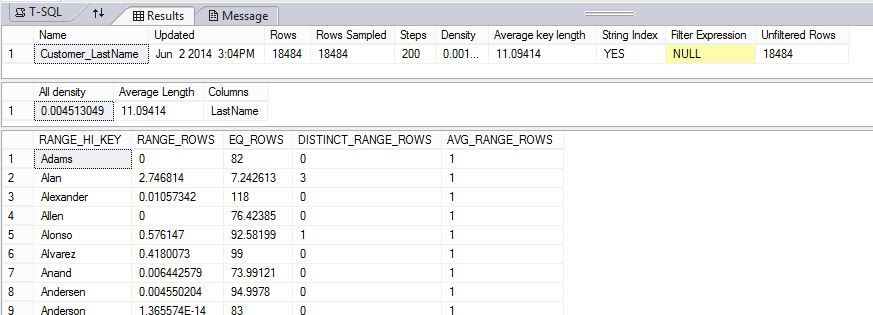
C. 显示一个统计信息对象的内容
以下示例创建一个统计信息对象,然后显示“AdventureWorksPDW2022”示例数据库中 DimCustomer 表中的 Customer_LastName 统计信息的内容。
-- Uses AdventureWorksPDW
--First, create a statistics object
CREATE STATISTICS Customer_LastName
ON AdventureWorksPDW2012.dbo.DimCustomer (LastName);
GO
DBCC SHOW_STATISTICS ("dbo.DimCustomer", Customer_LastName);
GO
结果显示标题、密度矢量和直方图的一部分。
另请参阅
- 统计信息
- Microsoft Fabric 中的统计信息
- sys.dm_db_stats_properties (Transact-SQL)
- sys.dm_db_stats_histogram (Transact-SQL)
- sys.dm_db_incremental_stats_properties (Transact-SQL)
后续步骤
反馈
即将发布:在整个 2024 年,我们将逐步淘汰作为内容反馈机制的“GitHub 问题”,并将其取代为新的反馈系统。 有关详细信息,请参阅:https://aka.ms/ContentUserFeedback。
提交和查看相关反馈