教學課程:使用 ML.NET 偵測產品銷售中的異常狀況
了解如何建置產品銷售資料的異常偵測應用程式。 此教學課程會示範如何在 Visual Studio 中使用 C# 建立 .NET Core 主控台應用程式。
在本教學課程中,您會了解如何:
- 載入資料
- 建立用於尖峰異常偵測的轉換
- 使用轉換偵測尖峰異常
- 建立用於變更點異常偵測的轉換
- 使用轉換偵測變更點異常
您可以在 dotnet/samples 存放庫中找到本教學課程的原始程式碼。
必要條件
已安裝 「.NET Desktop Development」 工作負載的Visual Studio 2022。
注意
product-sales.csv 中的資料格式是以 “Shampoo Sales Over a Three Year Period” (洗髮精三年銷售資料) 資料集為基礎,此資料集最初源自 DataMarket,由時間序列資料程式庫 (TSDL) 提供,建立者為 Rob Hyndman。
“Shampoo Sales Over a Three Year Period” (洗髮精三年銷售資料) 資料集已獲 DataMarket 的預設 Open License 授權。
建立主控台應用程式
建立名為 "ProductSalesAnomalyDetection" 的 C# 主控台應用程式。 按 [下一步] 按鈕。
選擇 .NET 6 作為要使用的架構。 按一下 [ 建立 ] 按鈕。
在專案中建立一個名為 Data 的目錄以儲存資料集檔案。
安裝「Microsoft.ML NuGet 套件」:
注意
除非另有說明,否則此樣本會使用所提及 NuGet 封裝的最新穩定版本。
在 [方案總管] 中,於您的專案上按一下滑鼠右鍵,然後選取 [管理 NuGet 套件]。 選擇 "nuget.org" 作為 [套件來源]、選取 [瀏覽] 索引標籤、搜尋 Microsoft.ML、並選取 [安裝] 按鈕。 在 [預覽變更] 對話方塊上,選取 [確定] 按鈕,然後在 [授權接受] 對話方塊上,如果您同意所列套件的授權條款,請選取 [我接受]。 針對 Microsoft.ML.TimeSeries 重複這些步驟。
在您的 Program.cs 檔案最上方新增下列
using陳述式:using Microsoft.ML; using ProductSalesAnomalyDetection;
下載您的資料
下載資料集,並儲存至您先前建立的 Data 資料夾:
以滑鼠右鍵按一下 product-sales.csv,然後選取 [另存連結] 或 [另存目標]
請務必將 *.csv 檔案儲存至 Data 資料夾,或儲存在其他位置之後將 *.csv 檔案移至 Data 資料夾。
在 [方案總管] 中,以滑鼠右鍵按一下 *.csv 檔案,並選取 [內容]。 在 [進階] 底下,將 [複製到輸出目錄] 的值變更為 [有更新時才複製]。
下表是 *.csv 檔案的資料預覽:
| 月 | ProductSales |
|---|---|
| 1 月 1 日 | 271 |
| 1 月 2 日 | 150.9 |
| ..... | ..... |
| 2 月 1 日 | 199.3 |
| ..... | ..... |
建立類別及定義路徑
接下來,定義您的輸入和預測類別資料結構。
將新類別新增至專案:
在 [方案總管] 中,以滑鼠右鍵按一下專案,然後選取 [新增] > [新項目]。
在 [新增項目] 對話方塊中,選取 [類別],然後將 [名稱] 欄位變更為 ProductSalesData.cs。 接著,選取 [新增] 按鈕。
隨即在程式碼編輯器中開啟 ProductSalesData.cs 檔案。
將下列
using陳述式新增至 ProductSalesData.cs 的上方:using Microsoft.ML.Data;移除現有類別定義,然後將下列具有
ProductSalesData和ProductSalesPrediction兩個類別的程式碼新增至 ProductSalesData.cs 檔案:public class ProductSalesData { [LoadColumn(0)] public string? Month; [LoadColumn(1)] public float numSales; } public class ProductSalesPrediction { //vector to hold alert,score,p-value values [VectorType(3)] public double[]? Prediction { get; set; } }ProductSalesData會指定輸入資料類別。 LoadColumn 屬性會指定應該載入資料集內的哪些資料行 (依資料行索引)。ProductSalesPrediction指定預測資料類別。 對於異常偵測,預測包含警示,用來指出是否有異常、原始分數及 P 值。 P 值越接近 0,就越可能發生異常。建立兩個全域欄位,以保存最近所下載資料集檔案路徑與儲存的模型檔案路徑:
_dataPath包含用來將模型定型的資料集路徑。_docsize有資料集檔案的記錄數目。 您會使用_docSize來計算pvalueHistoryLength。
將下列程式碼新增至緊接在使用陳述式下方的一行,以指定這些路徑:
string _dataPath = Path.Combine(Environment.CurrentDirectory, "Data", "product-sales.csv"); //assign the Number of records in dataset file to constant variable const int _docsize = 36;
將變數初始化
將
Console.WriteLine("Hello World!")行替換成下列程式碼,宣告並初始化mlContext變數:MLContext mlContext = new MLContext();MLContext 類別是所有 ML.NET 作業的起點,且初始化
mlContext會建立新的 ML.NET 環境,其可在模型建立工作流程物件之間共用。 就概念而言,類似於 Entity Framework 中的DBContext。
載入資料
ML.NET 中的資料會以 IDataView 介面表示。 IDataView 是彈性且有效率的表格式資料描述方式 (數值和文字)。 資料可以從文字檔或其他來源 (例如 SQL 資料庫或記錄檔) 載入至 IDataView 物件。
在建立
mlContext變數之後新增下列程式碼:IDataView dataView = mlContext.Data.LoadFromTextFile<ProductSalesData>(path: _dataPath, hasHeader: true, separatorChar: ',');LoadFromTextFile() 會定義資料結構描述並讀入檔案中。 會接受資料路徑變數然後傳回
IDataView。
時間序列異常偵測
異常偵測會標記未預期或異常的事件或行為。 它可提供尋找問題的線索,協助您回答「這奇不奇怪?」的問題。

異常偵測是偵測時間序列資料極端值的程序,它們是指定輸入時間序列中非預期或「奇怪」行為的資料點。
異常偵測適用於許多方面。 例如:
如果您有汽車,您可能想要知道:此油表的讀數是否正常,或是否有漏油? 如果要監視耗電量,您可能想知道:是否有停電?
可偵測到的時間序列異常有兩種:
尖峰表示系統中異常行為的暫時高載。
變更點表示系統開頭的持續性隨著時間變更。
在 ML.NET 中,IID 尖峰偵測或 IID 變更點偵測演算法都很適合獨立同分布資料集。 其假設輸入資料是一連串的資料點,會從一個固定分佈獨立取樣。
不同於其他教學課程中的模型,時間序列異常偵測器轉換會直接對輸入資料進行操作。 IEstimator.Fit() 方法不需要定型資料來產生轉換。 不過,它需要資料結構描述,這是由 ProductSalesData 空白清單所產生的資料檢視所提供。
您要分析相同的產品銷售資料,偵測尖峰和變更點。 尖峰偵測和變更點偵測的建置與定型模型程序相同,主要差異在於使用的特定偵測演算法。
尖峰偵測
尖峰偵測目標是找出明顯有別於大部分時間序列資料值的突然卻短暫暴增。 請務必及時偵測這些可疑的罕見項目、事件或觀測,將影響降至最低。 下列方法可用來偵測各種異常,例如:中斷、網路攻擊或病毒式 Web 內容。 下圖是時間序列資料集的尖峰範例:
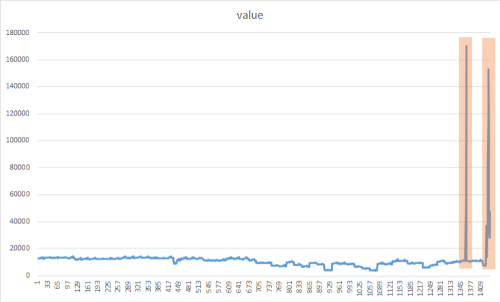
新增 CreateEmptyDataView() 方法
將下列方法新增至 Program.cs:
IDataView CreateEmptyDataView(MLContext mlContext) {
// Create empty DataView. We just need the schema to call Fit() for the time series transforms
IEnumerable<ProductSalesData> enumerableData = new List<ProductSalesData>();
return mlContext.Data.LoadFromEnumerable(enumerableData);
}
CreateEmptyDataView() 會產生空白資料檢視物件,其包含將作為 IEstimator.Fit() 方法輸入的正確結構描述。
建立 DetectSpike() 方法
DetectSpike() 方法:
- 從估算工具建立轉換。
- 根據歷史銷售資料偵測尖峰。
- 顯示結果。
使用下列程式碼,在 Program.cs 檔案底部建立
DetectSpike()方法:DetectSpike(MLContext mlContext, int docSize, IDataView productSales) { }使用 IidSpikeEstimator 定型偵測尖峰的模型。 使用下列程式碼將它新增至
DetectSpike()方法:var iidSpikeEstimator = mlContext.Transforms.DetectIidSpike(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, pvalueHistoryLength: docSize / 4);將下列內容新增為
DetectSpike()方法的下一行程式碼來建立尖峰偵測轉換:提示
confidence和pvalueHistoryLength參數會影響尖峰的偵測方式。confidence會決定模型對尖峰的敏感度。 信賴度越低,演算法越有可能偵測「較小的」尖峰。pvalueHistoryLength參數會定義滑動視窗中的資料點數目。 此參數的值通常是整個資料集的百分比。pvalueHistoryLength越低,模型忘記先前大型尖峰的速度就越快。ITransformer iidSpikeTransform = iidSpikeEstimator.Fit(CreateEmptyDataView(mlContext));新增下列程式碼將
productSales資料轉換成DetectSpike()方法中的下一行程式碼:IDataView transformedData = iidSpikeTransform.Transform(productSales);上述程式碼使用 Transform() 方法對多個資料集輸入資料列進行預測。
使用 CreateEnumerable() 方法和下列程式碼,將
transformedData轉換成強型別的IEnumerable以更輕鬆顯示:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);使用下列 Console.WriteLine() 程式碼建立顯示標頭行:
Console.WriteLine("Alert\tScore\tP-Value");您會在尖峰偵測結果中顯示下列資訊:
Alert表示指定資料點的尖峰警示。Score是資料集中指定資料點的ProductSales值。P-Value"P" 表示機率。 P 值越接近 0,資料點就越可能有異常。
使用下列程式碼逐一查看
predictionsIEnumerable,並顯示結果:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}"; if (p.Prediction[0] == 1) { results += " <-- Spike detected"; } Console.WriteLine(results); } } Console.WriteLine("");將呼叫新增至
LoadFromTextFile()方法呼叫下方的DetectSpike()方法:DetectSpike(mlContext, _docsize, dataView);
尖峰偵測結果
您的結果應該與以下類似。 處理期間會顯示訊息。 您可能會看到警告或處理訊息。 為了讓結果變得清楚,部分訊息已從下列結果中移除。
Detect temporary changes in pattern
=============== Training the model ===============
=============== End of training process ===============
Alert Score P-Value
0 271.00 0.50
0 150.90 0.00
0 188.10 0.41
0 124.30 0.13
0 185.30 0.47
0 173.50 0.47
0 236.80 0.19
0 229.50 0.27
0 197.80 0.48
0 127.90 0.13
1 341.50 0.00 <-- Spike detected
0 190.90 0.48
0 199.30 0.48
0 154.50 0.24
0 215.10 0.42
0 278.30 0.19
0 196.40 0.43
0 292.00 0.17
0 231.00 0.45
0 308.60 0.18
0 294.90 0.19
1 426.60 0.00 <-- Spike detected
0 269.50 0.47
0 347.30 0.21
0 344.70 0.27
0 445.40 0.06
0 320.90 0.49
0 444.30 0.12
0 406.30 0.29
0 442.40 0.21
1 580.50 0.00 <-- Spike detected
0 412.60 0.45
1 687.00 0.01 <-- Spike detected
0 480.30 0.40
0 586.30 0.20
0 651.90 0.14
變更點偵測
Change points 是值之時間序列事件資料流分佈的持續變更,例如層級變更和趨勢。 這些持續變更延續的時間比 spikes 長,可能表示災難性事件。 Change points 通常無法為肉眼所見,但可以使用下列方法,在您的資料中偵測到。 下圖是變更點偵測的範例:
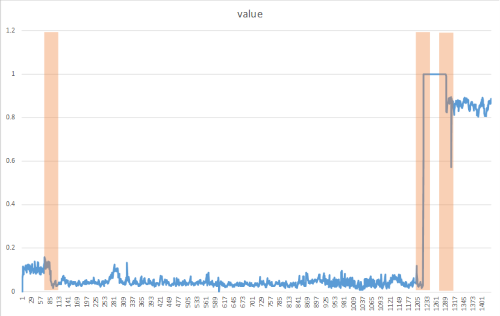
建立 DetectChangepoint() 方法
DetectChangepoint() 方法會執行下列工作:
- 從估算工具建立轉換。
- 根據歷史銷售資料偵測變更點。
- 顯示結果。
請使用下列程式碼,在緊接著
DetectSpike()方法宣告之後,建立DetectChangepoint()方法:void DetectChangepoint(MLContext mlContext, int docSize, IDataView productSales) { }使用下列程式碼在
DetectChangepoint()方法中建立 iidChangePointEstimator:var iidChangePointEstimator = mlContext.Transforms.DetectIidChangePoint(outputColumnName: nameof(ProductSalesPrediction.Prediction), inputColumnName: nameof(ProductSalesData.numSales), confidence: 95d, changeHistoryLength: docSize / 4);如同您先前進行的操作,請在
DetectChangePoint()方法中新增下列程式碼行,以從估算工具建立轉換:提示
變更點的偵測會稍有延遲,因為模型需要確定目前的偏差是持續性變更,而不只是在建立警示之前的一些隨機尖峰。 此延遲的數量等於
changeHistoryLength參數。 藉由增加此參數的值,變更偵測對更持續的變更發出警示,但取捨會是較長的延遲。var iidChangePointTransform = iidChangePointEstimator.Fit(CreateEmptyDataView(mlContext));將下列程式碼新增至
DetectChangePoint(),以使用Transform()方法來轉換資料:IDataView transformedData = iidChangePointTransform.Transform(productSales);如之前的操作,使用
CreateEnumerable()方法和下列程式碼,將transformedData轉換成強型別的IEnumerable,以更輕鬆顯示:var predictions = mlContext.Data.CreateEnumerable<ProductSalesPrediction>(transformedData, reuseRowObject: false);下列列程式碼作為
DetectChangePoint()方法中的下一行,建立顯示標頭:Console.WriteLine("Alert\tScore\tP-Value\tMartingale value");您會在變更點偵測結果中顯示下列資訊:
Alert表示指定資料點的變更點警示。Score是資料集中指定資料點的ProductSales值。P-Value"P" 表示機率。 P 值越接近 0,資料點就越可能有異常。Martingale value根據一系列的 P 值,用來識別資料點的「怪異」程度。
使用下列程式碼逐一查看
predictionsIEnumerable,並顯示結果:foreach (var p in predictions) { if (p.Prediction is not null) { var results = $"{p.Prediction[0]}\t{p.Prediction[1]:f2}\t{p.Prediction[2]:F2}\t{p.Prediction[3]:F2}"; if (p.Prediction[0] == 1) { results += " <-- alert is on, predicted changepoint"; } Console.WriteLine(results); } } Console.WriteLine("");在
DetectSpike()方法的呼叫後新增DetectChangepoint()方法的下列呼叫:DetectChangepoint(mlContext, _docsize, dataView);
變更點偵測結果
您的結果應該與以下類似。 處理期間會顯示訊息。 您可能會看到警告或處理訊息。 為了讓結果變得清楚,部分訊息已從下列結果中移除。
Detect Persistent changes in pattern
=============== Training the model Using Change Point Detection Algorithm===============
=============== End of training process ===============
Alert Score P-Value Martingale value
0 271.00 0.50 0.00
0 150.90 0.00 2.33
0 188.10 0.41 2.80
0 124.30 0.13 9.16
0 185.30 0.47 9.77
0 173.50 0.47 10.41
0 236.80 0.19 24.46
0 229.50 0.27 42.38
1 197.80 0.48 44.23 <-- alert is on, predicted changepoint
0 127.90 0.13 145.25
0 341.50 0.00 0.01
0 190.90 0.48 0.01
0 199.30 0.48 0.00
0 154.50 0.24 0.00
0 215.10 0.42 0.00
0 278.30 0.19 0.00
0 196.40 0.43 0.00
0 292.00 0.17 0.01
0 231.00 0.45 0.00
0 308.60 0.18 0.00
0 294.90 0.19 0.00
0 426.60 0.00 0.00
0 269.50 0.47 0.00
0 347.30 0.21 0.00
0 344.70 0.27 0.00
0 445.40 0.06 0.02
0 320.90 0.49 0.01
0 444.30 0.12 0.02
0 406.30 0.29 0.01
0 442.40 0.21 0.01
0 580.50 0.00 0.01
0 412.60 0.45 0.01
0 687.00 0.01 0.12
0 480.30 0.40 0.08
0 586.30 0.20 0.03
0 651.90 0.14 0.09
恭喜! 您現已成功建置偵測銷售資料中尖峰和變更點異常的機器學習模型。
您可以在 dotnet/samples 存放庫中找到本教學課程的原始程式碼。
在本教學課程中,您已了解如何:
- 載入資料
- 定型尖峰異常偵測的模型
- 使用定型的模型偵測尖峰異常
- 定型變更點異常偵測的模型
- 使用定型的模式偵測變更點異常
下一步
請查看機器學習範例 GitHub 存放庫,以深入瞭解季節性資料異常偵測範例。
意見反映
即將推出:我們會在 2024 年淘汰 GitHub 問題,並以全新的意見反應系統取代並作為內容意見反應的渠道。 如需更多資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交及檢視以下的意見反映: