Azure Stack HCI 與 Windows Server 叢集的容錯和儲存效率
適用于:Azure Stack HCI 版本 22H2 和 21H2;Windows Server 2022、Windows Server 2019
本文將說明可用的復原選項,並概述其規模需求、儲存效率,以及這每一項的一般優點和取捨。
概觀
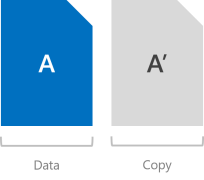
儲存空間直接存取可以為資料提供「容錯」,通常稱為「復原」。 其實作類似 RAID,但差在會分散於伺服器,並實作於軟體中。
和 RAID 一樣,儲存空間有幾個不同方式可執行此操作,這些方式會在容錯、儲存效率與計算複雜度之間做出不同取捨。 這些廣泛分為兩類:「鏡像」和「同位」,後者有時稱為「抹除碼」。
鏡像
鏡像可為所有資料保存多個複本,以提供容錯能力。 其行為最像 RAID-1。 這類資料的等量化和放置方式並非一般人所能了解 (若要深入了解請參閱此部落格),但可確定的是,任何使用鏡像進行儲存的資料,都會以整體的方式寫入多次。 每個複本會寫入至不同的硬體 (不同伺服器中的不同磁碟機),而理論上其故障只會單獨發生。
您可以在兩種鏡像 (「雙向」和「三向」) 之間進行選擇。
雙向鏡像
雙向鏡像會為所有內容寫入兩個複本。 其儲存效率為 50% (若要寫入 1 TB 的資料,您至少需要 2 TB 的實體儲存體容量)。 同樣地,您至少需要兩個硬體「容錯網域」(若使用儲存空間直接存取,這表示需要兩部伺服器)。
警告
如果您有兩部以上的伺服器,建議您改用三向鏡像。
三向鏡像
三向鏡像會為所有內容寫入三個複本。 其儲存效率為 33.3% (若要寫入 1 TB 的資料,您至少需要 3 TB 的實體儲存體容量)。 同樣地,您也需要至少三個硬體「容錯網域」,在使用儲存空間直接存取時,這表示需要三部伺服器。
三向鏡像在同一時間可容許至少兩個硬體問題 (磁碟機或伺服器),而安全無虞。 例如,如果您在一個磁碟機或伺服器突然故障時重新啟動另一部伺服器,所有資料都將保有安全性,且持續可供存取。

Parity
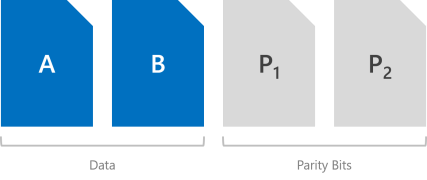
同位編碼 (通常稱為「抹除碼」) 提供使用位元運算的容錯功能,這非常複雜。 相較於鏡像,同位的運作方式較不容易理解,但有許多絕佳的線上資源 (例如,這個由第三方提供的清除編碼傻瓜指南) 可協助您了解。 可以這麼說,它提供更好的儲存效率,卻又不會犧牲容錯能力。
儲存空間提供兩種同位,即「單一」同位和「雙」同位,後者會在大規模上採用稱為「區域重建碼 (local reconstruction codes)」的先進技術。
重要
我們建議使用鏡像處理大部分易受效能影響的工作負載。 若要深入了解如何根據您的工作負載來平衡效能與產能,請參閱規劃磁碟區。
單同位
單同位只會保留一個位元同位符號,因此一次只能對一個故障提供容錯。 其行為最像 RAID-5。 若要使用單同位,您需要至少三個硬體「容錯網域」,在使用儲存空間直接存取時,這表示需要三部伺服器。 因為三向鏡像可在相同規模提供更多容錯能力,我們不建議您使用單同位。 但如果您堅持要使用也沒問題,而且會受到完全支援。
警告
我們不建議使用單同位,因為它一次只能安全地容許一個硬體故障:如果您重新開機一部伺服器,同時突然另一部磁碟機或伺服器故障,就會發生停機。 如果您只有三部伺服器,建議您使用三向鏡像。 如果您有四部以上,請參閱下一節。
雙同位
雙同位會實作 Reed-Solomon 錯誤修正程式碼以保留兩個位元同位符號,進而提供和三向鏡像相同的容錯能力 (也就是一次最多兩個故障),但此方式擁有更好的儲存效率。 其行為最像 RAID-6。 若要使用雙同位,您需要至少四個硬體「容錯網域」,在使用儲存空間直接存取時,這表示需要四部伺服器。 在此規模下,其儲存效率是 50%,因此若要儲存 2 TB 的資料,您需要至少 4 TB 的實體儲存容量。
您擁有愈多硬體容錯網域數目,雙同位的儲存效率就會愈高,從 50% 提高到 80%。 例如,七個網域 (若使用儲存空間直接存取,這表示有七部伺服器) 的效率會跳到 66.7% (若要儲存 4 TB 的資料,您只需要 6 TB 的實體儲存體容量)。

如需各種規模的雙同位效率和本機重建程式碼,請參閱摘要一節。
本機重建程式碼
儲存空間引進由 Microsoft Research 所開發的先進技術,稱為「區域重建碼 (local reconstruction codes)」或 LRC。 在大規模的環境中,雙同位會使用 LRC 將其編碼/解碼分割為幾個較小的群組,以降低進行寫入或從故障中復原所需的負荷。
使用硬碟 (HDD) 時,群組大小是四個符號;使用固態硬碟 (SSD) 時,群組大小是六個符號。 例如,以下是具有硬碟和 12 個硬體容錯網域 (亦即 12 部伺服器) 之配置的可能樣貌,其中有兩組四個一群的資料符號。 其可達到 72.7% 的儲存效率。

我們建議您參閱此深入但十分易讀的逐步解說:區域重建碼如何處理各種不同的失敗案例,以及其為何如此吸引人,其作者是 Claus Joergensen。
鏡像加速的同位
儲存空間直接存取磁碟區可以是部分鏡像和部分同位。 寫入首先登陸鏡像部分,稍後逐漸移動至同位部分。 實際上,這是使用鏡像加速清除編碼。
若要混合使用三向鏡像與雙同位,您需要至少四個容錯網域,亦即四部伺服器。
鏡像加速同位的儲存效率介於全部使用鏡像與全部使用同位之間,並取決於您選擇的混合比例。 例如,此簡報在第 37 分鐘時示範了使用 12 部伺服器時,效率達到 46%、54% 和 65% 的各種混合模式。
重要
我們建議使用鏡像處理大部分易受效能影響的工作負載。 若要深入了解如何根據您的工作負載來平衡效能與產能,請參閱規劃磁碟區。
總結
本節摘要說明儲存空間直接存取中可用的復原類型、使用各種類型的最小規模需求、每種類型可容許多少故障,以及對應的儲存效率。
復原類型
| 災害復原 | 容錯 | 儲存效率 |
|---|---|---|
| 雙向鏡像 | 1 | 50.0% |
| 三向鏡像 | 2 | 33.3% |
| 雙同位 | 2 | 50.0% - 80.0% |
| Mixed | 2 | 33.3% - 80.0% |
最小規模需求
| 災害復原 | 最小必要容錯網域 |
|---|---|
| 雙向鏡像 | 2 |
| 三向鏡像 | 3 |
| 雙同位 | 4 |
| Mixed | 4 |
提示
除非您使用底座或機架容錯,否則容錯網域的數目就是指伺服器數目。 只要您符合儲存空間直接存取的最小需求,每部伺服器中的磁碟機數目就不會影響您所能使用的復原類型。
混合式部署的雙同位效率
下表顯示同時包含硬碟 (HDD) 和固態硬碟 (SSD) 的混合式部署中,雙同位和本機重建程式碼在各種規模的儲存效率。
| 容錯網域 | Layout | 效率 |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50.0% |
| 5 | RS 2+2 | 50.0% |
| 6 | RS 2+2 | 50.0% |
| 7 | RS 4+2 | 66.7% |
| 8 | RS 4+2 | 66.7% |
| 9 | RS 4+2 | 66.7% |
| 10 | RS 4+2 | 66.7% |
| 11 | RS 4+2 | 66.7% |
| 12 | LRC (8, 2, 1) | 72.7% |
| 13 | LRC (8, 2, 1) | 72.7% |
| 14 | LRC (8, 2, 1) | 72.7% |
| 15 | LRC (8, 2, 1) | 72.7% |
| 16 | LRC (8, 2, 1) | 72.7% |
全快閃部署的雙同位效率
下表顯示只包含固態硬碟 (SSD) 的全快閃部署中,雙同位和本機重建程式碼在各種規模的儲存效率。 在全快閃組態中,同位配置可使用較大的群組大小,並達到更好的儲存效率。
| 容錯網域 | Layout | 效率 |
|---|---|---|
| 2 | – | – |
| 3 | – | – |
| 4 | RS 2+2 | 50.0% |
| 5 | RS 2+2 | 50.0% |
| 6 | RS 2+2 | 50.0% |
| 7 | RS 4+2 | 66.7% |
| 8 | RS 4+2 | 66.7% |
| 9 | RS 6+2 | 75.0% |
| 10 | RS 6+2 | 75.0% |
| 11 | RS 6+2 | 75.0% |
| 12 | RS 6+2 | 75.0% |
| 13 | RS 6+2 | 75.0% |
| 14 | RS 6+2 | 75.0% |
| 15 | RS 6+2 | 75.0% |
| 16 | LRC (12, 2, 1) | 80.0% |
範例
除非您只有兩部伺服器,否則建議您使用三向鏡像和/或雙同位,因為它們提供較好的容錯能力。 具體而言,它們可確保即使兩個錯誤網域 (在使用儲存空間直接存取時,這表示兩部伺服器) 都受到同時故障的影響,所有資料仍可保持安全並持續可供存取。
全都保持上線的範例
這六個範例示範三向鏡像和/或雙同位可以容許的情形。
- 1. 失去一個磁碟機 (包括快取磁碟機)
- 2. 失去一部伺服器
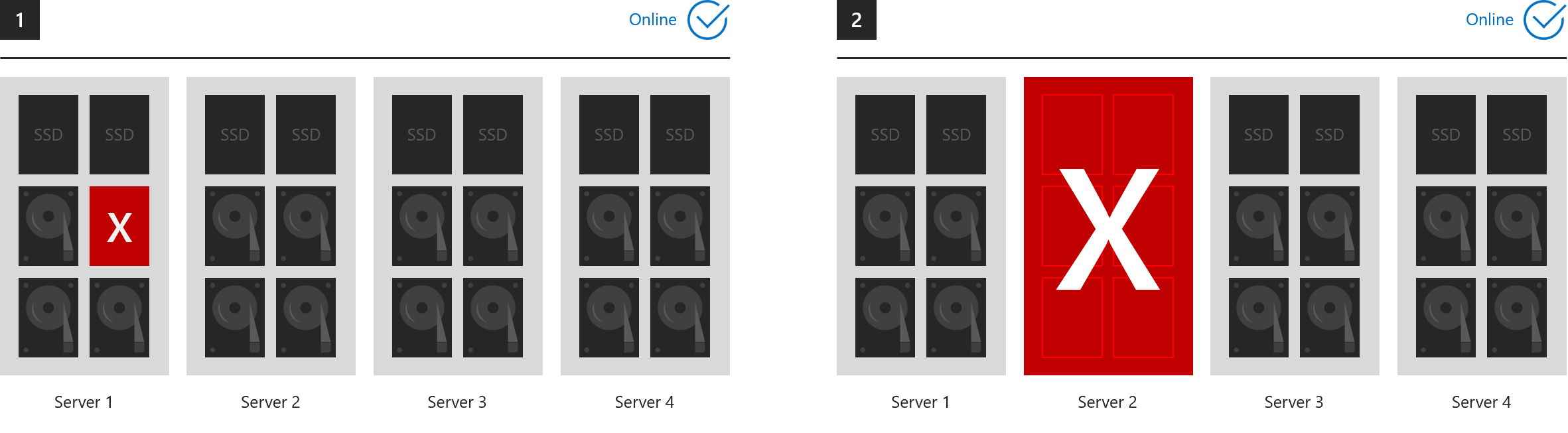
- 3. 失去一部伺服器和一個磁碟機
- 4. 失去不同伺服器中的兩個磁碟機

- 5. 只要最多兩部伺服器受到影響,就會失去兩個以上的磁碟機
- 6. 失去兩部伺服器
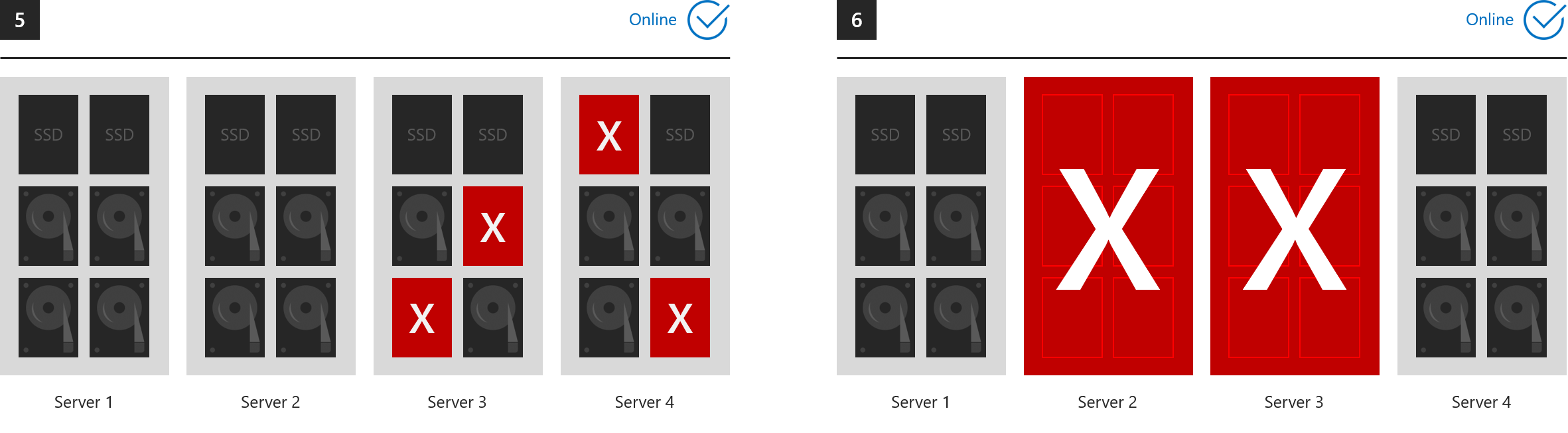
...在每個案例中,所有磁碟區都會保持上線。 (請確定您的叢集會保持仲裁)。
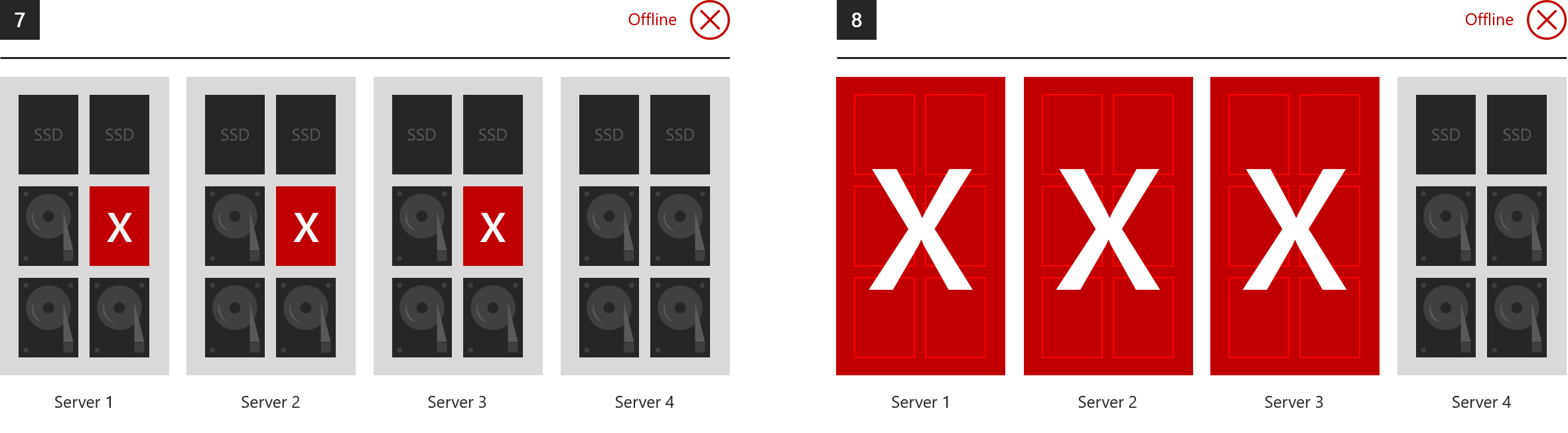
全都離線的範例
儲存空間在其存留期內可容許任何數目的故障,因為只要時間足夠,它就會在每次故障後還原成完整復原能力。 不過,任何特定時刻最多只會有兩個錯誤網域可安全地受到故障影響。 因此,下列是三向鏡像和/或雙同位無法容許之情形的範例。
- 7. 一次失去三部以上伺服器中的磁碟機
- 8. 一次失去三部以上的伺服器
使用方式
查看建立磁碟區。
後續步驟
如需進一步了解本文中所述的主旨,請參閱下列主題:
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應