在多個 Azure Stack Hub 區域中執行多層式架構 (N-Tier) 應用程式以獲得高可用性
此參考架構顯示一組經過證實的作法,可跨多個 Azure Stack Hub 區域執行多層式架構應用程式,以實現可用性和穩固的災害復原基礎結構。 在此文件中,「流量管理員」是用來達成高可用性,不過若「流量管理員」不是您環境中的優先選擇,您可以使用一組高可用性負載平衡器來取代。
注意
請注意,下面架構中使用的「流量管理員」必須在 Azure 中設定,且用於設定「流量管理員」設定檔的端點必須是可在公開網路上路由的 IP。
架構
此架構係根據具有 SQL Server 的多層式架構 (N-tier) 應用程式中顯示的架構而建置的。
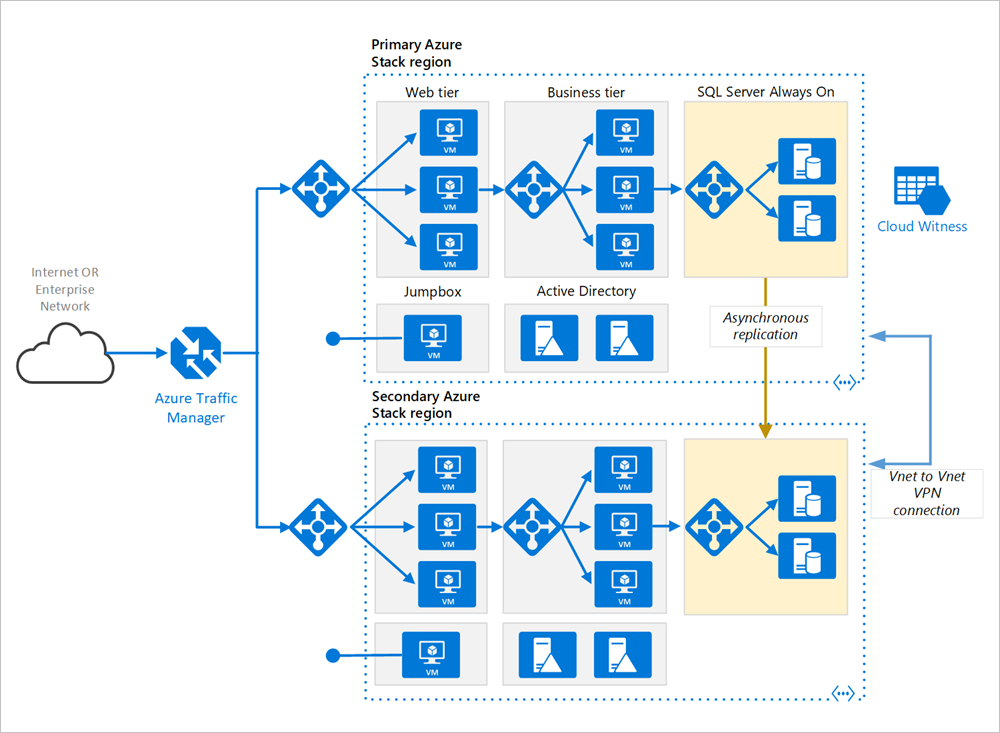
主要和次要區域。 使用兩個區域以實現更高的可用性。 其中一個是主要區域。 另一個則用於容錯移轉。
Azure 流量管理員。 流量管理員會將連入要求路由傳送到其中一個區域。 正常作業期間,它會將要求路由傳送到主要區域。 如果該區域變得無法使用,流量管理員就會容錯移轉到次要區域。 如需詳細資訊,請參閱流量管理員設定。
資源群組。 分別針對主要區域與次要區域建立資源群組。 這可讓您彈性地將每個區域當作單一資源集合來管理。 例如,您可以重新部署某一個區域,而不需拿掉另一個區域。 連結資源群組,如此一來,您就能執行查詢,以列出應用程式的所有資源。
虛擬網路。 針對每個區域建立不同的虛擬網路。 確定位址空間並未重疊。
SQL Server Always On 可用性群組。 如果您使用 SQL Server,我們建議使用 SQL Always On 可用性群組來獲得高可用性。 建立單一可用性群組,以包含這兩個區域中的 SQL Server 執行個體。
VNET 對 VNET VPN 連線。 由於 Azure Stack Hub 上尚未提供 VNET 對等互連,請使用 VNET 對 VNET VPN 連線來連接兩個 VNET。 如需詳細資訊,請參閱 Azure Stack Hub 中的 VNET 對 VNET。
建議
多區域架構可以提供比部署到單一區域更高的可用性。 如果區域中斷會影響主要區域,您可以使用流量管理員容錯移轉到次要區域。 如果應用程式的個別子系統失敗,此架構也可以提供協助。
有數種一般方法可用來跨區域實現高可用性:
搭配熱待命的主動/被動。 流量會傳送到其中一個區域,而另一個區域會以熱待命模式等候。 熱待命表示次要區域中隨時都已配置 VM 且正在執行中。
搭配冷待命的主動/被動。 流量會傳送到其中一個區域,而另一個區域會以冷待命模式等候。 冷待命表示在需要容錯移轉之前,不會在次要區域中配置 VM。 此方式的執行成本較小,但在失敗發生時通常需要較久的時間才能上線。
主動/主動。 兩個區域均為主動,而且要求會在它們之間負載平衡。 如果其中一個區域變成無法使用,就會將它從輪替中剔除。
此參考架構著重於搭配熱待命的主動/被動,使用流量管理員進行容錯移轉。 您可以部署少量的 VM 來進行熱待命,然後視需要相應放大。
流量管理員設定
設定流量管理員時,請考慮下列各點:
路由。 流量管理員支援數個路由演算法。 針對本文所述的案例,請使用「優先順序」路由 (先前稱為「容錯移轉」路由)。 使用此設定,流量管理員會將所有要求傳送到主要區域,除非主要地區變成無法連線。 那時,就會自動容錯移轉到次要區域。 請參閱設定容錯移轉路由方法。
健康情況探查。 流量管理員會使用 HTTP (或 HTTPS) 探查來監視每個區域的可用性。 探查會針對指定的 URL 路徑檢查 HTTP 200 回應。 最佳作法是,建立端點來報告應用程式的整體健康情況,並使用此端點進行健康情況探查。 否則,探查可能會在應用程式的關鍵組件真的失敗時報告端點狀況良好。 如需詳細資訊,請參閱健康情況端點監視模式 \(部分機器翻譯\)。
當流量管理員容錯移轉時,用戶端會有一段時間無法連線到應用程式。 持續時間受到下列因素影響:
健康情況探查必須偵測到主要區域已變成無法連線。
DNS 伺服器必須針對 IP 位址更新快取的 DNS 記錄,這取決於 DNS 存留時間 (TTL)。 預設的 TTL 是 300 秒 (5 分鐘),但是當您建立流量管理員設定檔時,您可以設定此值。
如需詳細資料,請參閱關於流量管理員監視。
如果流量管理員容錯移轉,我們建議執行手動容錯回復,而不是實作自動容錯回復。 或者,您可以建立應用程式會在區域之間來回翻轉的情況。 請確認所有的應用程式子系統狀況良好,然後再進行容錯回復。
請注意,流量管理員預設會自動容錯回復。 若要避免這個問題,請在容錯移轉事件之後,手動降低主要區域的優先順序。 例如,假設主要區域是優先順序 1,而次要為優先順序 2。 在容錯移轉之後,將主要區域設定為優先順序 3,以防止自動容錯回復。 當您準備好切換回來時,請將優先順序更新為 1。
下列 Azure CLI 命令會更新優先順序:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --priority 3
另一種方法是暫時停用端點,直到您準備好進行容錯回復為止:
az network traffic-manager endpoint update --resource-group <resource-group> --profile-name <profile>
--name <endpoint-name> --type externalEndpoints --endpoint-status Disabled
依據容錯移轉的原因而定,您可能需要重新部署區域內的資源。 容錯回復之前,請執行操作性整備測試。 測試應該確認如下的事項:
VM 已正確設定 (已安裝所有必要的軟體,IIS 正在執行等設定)。
應用程式子系統均狀況良好。
功能測試 (例如,資料庫層可從 Web 層連線)。
設定 SQL Server Always On 可用性群組
在 Windows Server 2016 之前,SQL Server Always On 可用性群組需要一個網域控制站,而且可用性群組中的所有節點都必須位於相同的 Active Directory (AD) 網域。
設定可用性群組:
在每個區域中至少放置兩個網域控制站。
為每個網域控制站提供一個靜態 IP 位址。
建立 VPN,以啟用兩個虛擬網路之間的通訊。
針對每個虛擬網路,將網域控制站的 IP 位址 (從這兩個區域) 新增到 DNS 伺服器清單。 您可以使用下列 CLI 命令。 如需詳細資訊,請參閱變更 DNS 伺服器。
az network vnet update --resource-group <resource-group> --name <vnet-name> --dns-servers "10.0.0.4,10.0.0.6,172.16.0.4,172.16.0.6"建立 Windows Server 容錯移轉叢集 (WSFC) 叢集,其中包含這兩個區域中的 SQL Server 執行個體。
建立 SQL Server Always On 可用性群組,其中包含主要和次要區域中的 SQL Server 執行個體。 如需相關步驟,請參閱將 Always On 可用性群組擴充到遠端 Azure 資料中心 (PowerShell) \(英文\)。
將主要複本放置於主要區域。
將一或多個次要複本放置於主要區域。 設定這些來使用具有自動容錯移轉的同步認可。
將一或多個次要複本放置於次要區域。 基於效能考量,設定這些來使用「非同步」認可 (否則,所有的 T-SQL 交易都必須等候透過網路到次要區域的來回行程)。
注意
非同步認可複本不支援自動容錯移轉。
可用性考量
使用複雜的多層式架構應用程式,您可能不需要在次要區域中複寫整個應用程式, 而是可能只需複寫支援商務持續性所需的關鍵子系統。
流量管理員可能是此系統中的失敗點。 如果流量管理員服務失敗,用戶端就無法在當機期間存取您的應用程式。 檢閱流量管理員 SLA,並判斷單獨使用流量管理員是否符合您獲得高可用性的業務需求。 如果沒有,請考慮新增另一個流量管理解決方案作為容錯回復。 如果 Azure 流量管理員服務失敗,在 DNS 中變更您的 CNAME 記錄,以指向其他流量管理服務。 (此步驟必須手動執行,而且在傳播 DNS 變更之前,將無法使用您的應用程式)。
對於 SQL Server 叢集,有兩個要考慮的容錯移轉案例:
主要區域中的所有 SQL Server 資料庫複本都失敗。 例如,這可能會在區域中斷期間發生。 在該情況下,您必須手動容錯移轉可用性群組,即使流量管理員會在前端自動容錯移轉。 請依照執行 SQL Server 可用性群組的強制手動容錯移轉,其中描述如何使用 SQL Server 2016 中的 SQL Server Management Studio、Transact-SQL 或 PowerShell 執行強制容錯移轉。
警告
使用強制容錯移轉,會有資料遺失的風險。 當主要區域再次上線之後,請取得資料庫的快照集,然後使用 tablediff 來找出差異。
流量管理員會容錯移轉到次要區域,但仍然可以使用主要的 SQL Server 資料庫複本。 例如,前端層可能失敗,但不會影響 SQL Server VM。 在該情況下,會將網際網路流量路由傳送到次要區域,而且該區域仍然可以連線到主要複本。 不過,將會增加延遲,因為 SQL Server 連線會跨區域進行。 在此情況下,您應該執行手動容錯移轉,如下所示:
將次要區域中的 SQL Server 資料庫複本暫時切換到「同步」認可。 這確保在容錯移轉期間將不會遺失資料。
容錯移轉到該複本。
當您容錯回復到主要區域時,還原非同步認可設定。
管理性考量
當您更新部署時,請一次更新一個區域,以減少因為應用程式中的不正確設定或錯誤而導致全域失敗的機會。
測試系統對於失敗的復原能力。 以下是一些要測試的常見失敗案例:
關閉 VM 執行個體。
壓力資源,例如 CPU 和記憶體。
中斷連線/延遲網路。
毀損程序。
憑證到期。
模擬硬體故障。
關閉網域控制站上的 DNS 服務。
測量復原時間,並確認它們符合您的業務需求。 此外,也需測試失敗模式組合。
後續步驟
- 若要深入了解 Azure 雲端模式,請參閱雲端設計模式。
意見反應
即將登場:在 2024 年,我們將逐步淘汰 GitHub 問題作為內容的意見反應機制,並將它取代為新的意見反應系統。 如需詳細資訊,請參閱:https://aka.ms/ContentUserFeedback。
提交並檢視相關的意見反應